MapReduce原理
本文主要的参考资料
MapReduce论文: https://link.zhihu.com/?target=https%3A//pdos.csail.mit.edu/6.824/papers/mapreduce.pdf
MIT6.824课程: https://link.zhihu.com/?target=https%3A//www.youtube.com/watch%3Fv%3DWtZ7pcRSkOA
wiki: https://zh.wikipedia.org/wiki/MapReduce
简介
MapReduce是由Google提出的一种软件架构,用于大规模数据的并行计算。MapReduce运用了一种并行分治的思想:将一个大规模的任务交予一个分布式集群完成,主要分为映射(map)和规约(reduce)两个部分,具体流程后面会详细介绍。
细节
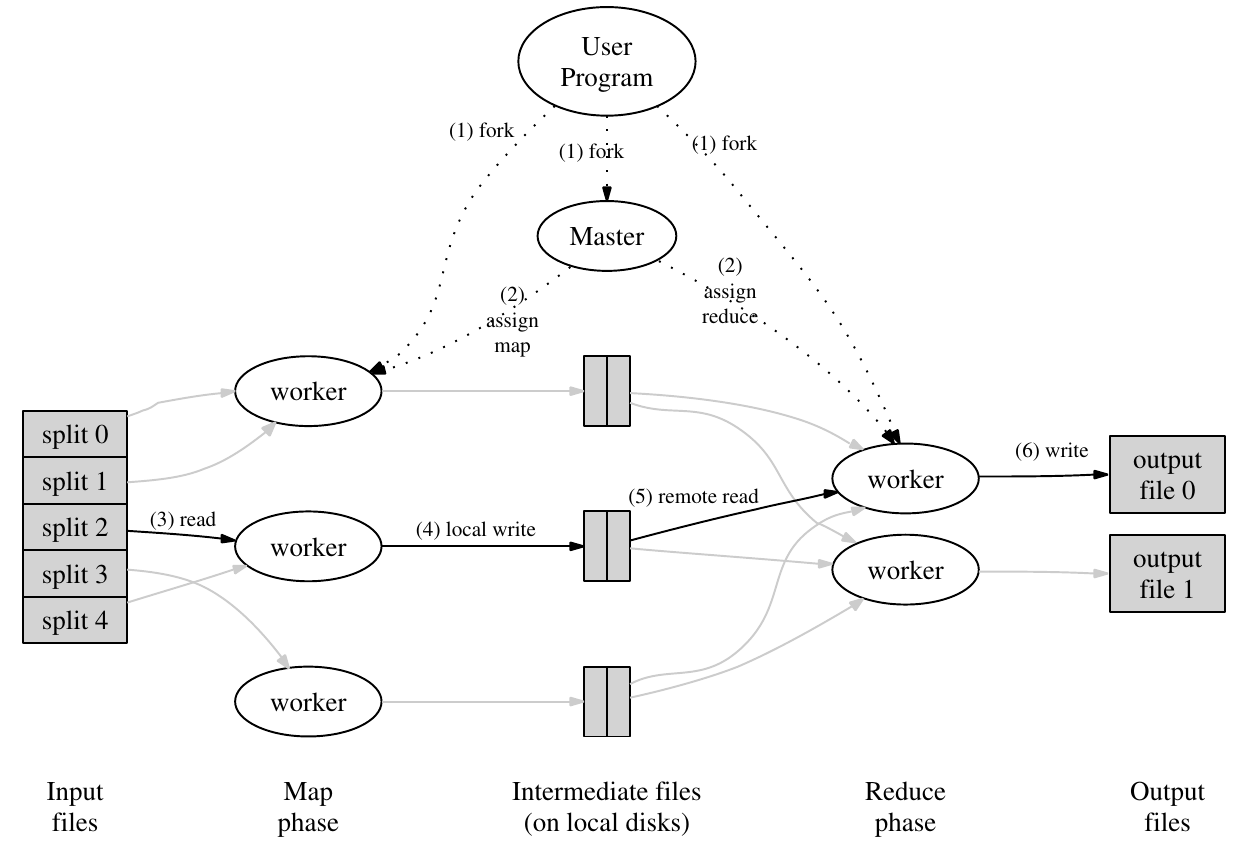
概念和流程
引用论文中的架构图,介绍一下MapReduce涉及到的概念和流程。
MapReduce的程序分为两类:Master和worker。均由用户程序fork而来。它们各自的功能为:
Master: 分配worker和响应用户worker: 负责处理工作
而worker根据工作类型的不同,具体分为两种:
- map,工作流程为:
读取并切分文件-->执行用户自定义的Map函数-->将结果用KV对保存-->将地址返回Master并传给
Q1:执行函数的结果为什么/一定会为KV对吗?
A1: 必须用KV对的形式,因为后面Reduce需要对key排序然后聚合相同key的结果;能够将结果输出为KV对,证明任务是可被分解的,这样的任务才适用于MapReduce框架。
- reduce,工作流程为:
通过RPC从磁盘中读取数据-->对key进行排序-->将分组后的值送给用户自定义的Reduce函数-->结果由master返回客户
Q1:什么是RPC?
A1:简单来就是客户端调用远程API,就和调用本地API一样。
Q2:什么需要对Key进行排序?
A2:可以归并相同key值的结果;二期自带归并排序,数据的有序性可能会减轻Reduse函数的负担,可以参考后面单词统计的例子。
Q3:排序排不开怎么办?
A3:如果内存中无法完全排序可以通过外部排序实现
实例
使用MapReduce实现统计文本单词个数的程序。输入:一段文本;输出为一组<word, num>,需要实现Map函数和Reduce函数
- Map函数:将单词进行切分,输出结果比如<A:1><B:2><A:2><C:1>...
- 对key进行排序:对key进行排序,结果为<A:1><A:2><B:2><C:1>...
- Reduce函数:合并结果<A:3><B:2><C:1>
容错
在实际使用中,可能会出现故障情况:
- worker挂了怎么办?Master定期ping worker,ping不通时进行标记,不会将任务分配给ping不同的worker。
- Master挂了怎么办?终止程序
性能影响
存在局部对整体的影响。
比如几个Map或Reduce任务故障(比如硬件故障)会拖累整体的任务进度。解决方案是使用备用任务,最终无论是备用任务还是原先任务完成都标记为全部任务完成。
优化点
通过Combiner实现节省带宽。
在Map完成后,Reduce执行前,有一次通过网络将Map结果发送给Reduce的过程,存在一个优化点:在中间实现一个Combiner函数,在本地将结果进行一次归并,再进行发送。
解语
MapReduce抽象了分布式处理任务的细节,使用人员无需分布式经验,只需要编写Map函数和Reduce函数便能进行大规模的并行计算。但是因为一些原因,Google最终放弃了MapReduce。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号