数据采集与融合实践作业三
数据采集与融合技术实践作业三
scrapy项目gitee链接:https://gitee.com/jsjdjjdjajsd/getinformation/tree/master/作业三
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
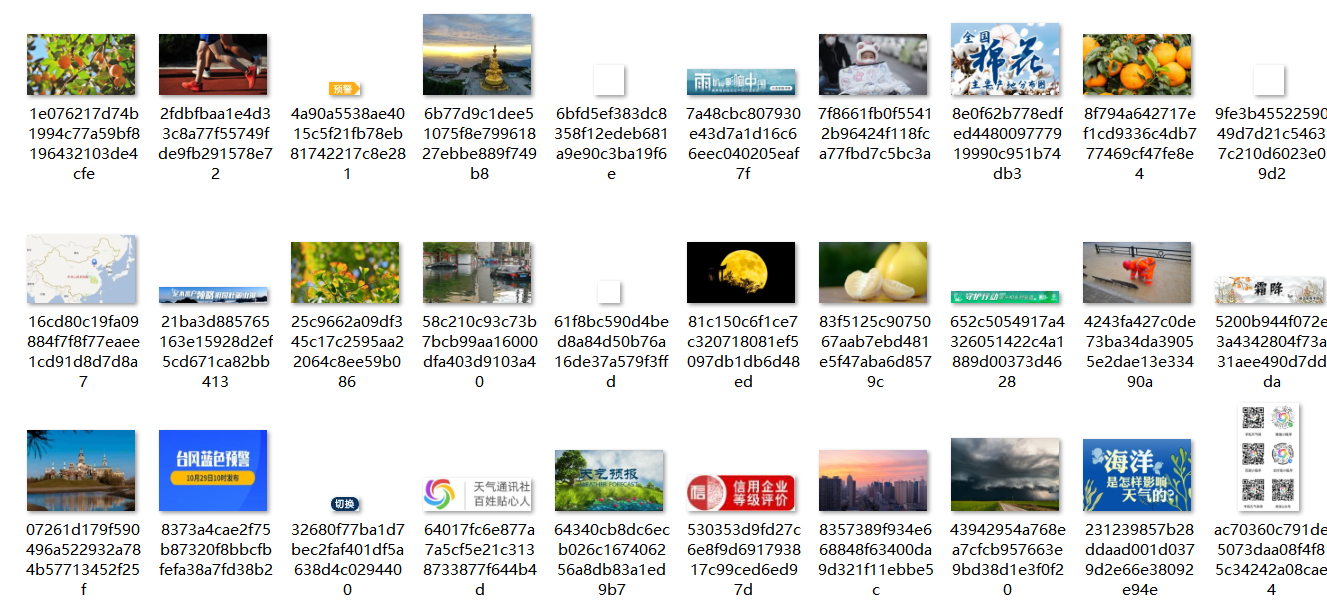
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
Gitee文件夹链接
创建完工程后,编写weather_spider.py
点击查看代码
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class WeatherSpider(scrapy.Spider):
name = 'weather_spider'
page_limit = 19
image_limit = 119
start_urls = [f'http://www.weather.com.cn/']
def parse(self, response):
images = response.css('img::attr(src)').getall()
for img in images:
if img.startswith('//'):
img = 'http:' + img
yield {'image_urls': [img]}
if self.page_limit > 0:
next_page = response.css('a.next::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
def close(self, reason):
self.log(f'Scrapy finished with reason: {reason}')
其中
page_limit = 19 image_limit = 119 start_urls = [f'http://www.weather.com.cn/']表示爬取最大页数只能到19页,最大图片数只能为119.
编写piplines.py文件
点击查看代码
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class CustomImagesPipeline(ImagesPipeline):
def __init__(self, *args, **kwargs):
super(CustomImagesPipeline, self).__init__(*args, **kwargs)
self.images_count = 0
def item_completed(self, results, item, info):
self.images_count += len(results[0][1])
if self.images_count > 119:
raise DropItem(f'Too many images downloaded: {self.images_count}')
return item
接下来配置setting.py文件
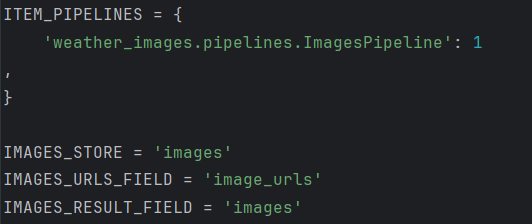
此时运行在终端运行爬虫是单线程模式
加上这段代码CONCURRENT_REQUESTS = 16后面的数字可填任意数字,用于控制并发请求的数量,当大于1时既是多线程。
运行的最终结果
心得体会
通过本次实验,我深入了解了Scrapy框架的强大功能及其灵活性。首先,Scrapy提供了强大的数据提取和存储机制,使得爬取数据变得相对简单。其次,使用单线程和多线程的比较,让我意识到并发请求在提升爬取效率方面的显著效果。然而,控制总页数和图片数量的设置让我明白了爬虫设计中的重要性,以避免对目标网站造成过大压力。此外,调试和错误处理的过程增强了我对Python编程的理解。总的来说,本次实验不仅提升了我的编程能力,也让我对网络爬虫的实用性有了更深刻的认识。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
创建完工程后编写stock_spider.py代码
点击查看代码
import re
import scrapy
import requests
from..items import SecondbloodPipeline
class SecondSpider(scrapy.Spider):
name = "second"
start_url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
def start_requests(self):
url = SecondSpider.start_url
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
try:
stocks = []
url = "https://68.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124009413428787683675_1696660278138&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18&_=1696660278155"
r = requests.get(url=url)
data = re.compile("\"f2\":.*").findall(r.text)
data1 = data[0].split("},{")
data1[-1] = data1[-1].split("}")[0]
for i in range(len(data1)):
stock0 = data1[i].replace('"', "").split(",")
list_ = [6, 7, 0, 1, 2, 3, 4, 5, 8, 9, 10, 11]
stock = []
for j in list_:
stock.append(stock0[j].split(":")[1])
stocks.append(stock)
for i in range(len(stocks)):
item = SecondbloodPipeline()
item["stockname"] = stocks[i][0]
item["name"] = stocks[i][1]
item["newprice"] = float(stocks[i][2])
item["zhangdiefu"] = float(stocks[i][3])
item["zhangdieer"] = float(stocks[i][4])
item["chengjiaoliang"] = float(stocks[i][5])
item["chengjiaoer"] = float(stocks[i][6])
item["zhenfu"] = float(stocks[i][7])
item["zuigao"] = float(stocks[i][8])
item["zuidi"] = float(stocks[i][9])
item["jinkai"] = float(stocks[i][10])
item["zuoshou"] = float(stocks[i][11])
yield item
except Exception as err:
print(f"Error in parse method: {err}")
配置piplines.py文件
点击查看代码
import pymysql
class SecondbloodPipeline:
def __init__(self):
self.mydb = pymysql.connect(
host="127.0.0.1",
port=3306,
user='root',
password='Wjh040619@',
database="stock",
charset='utf8'
)
self.cursor = self.mydb.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS stocks(
stockname VARCHAR(256),
name VARCHAR(256),
newprice DECIMAL(10, 2),
zhangdiefu DECIMAL(5, 2),
zhangdieer DECIMAL(5, 2),
chengjiaoliang DECIMAL(10, 2),
chengjiaoer DECIMAL(10, 2),
zhenfu DECIMAL(5, 2),
zuigao DECIMAL(10, 2),
zuidi DECIMAL(10, 2),
jinkai DECIMAL(10, 2),
zuoshou DECIMAL(10, 2)
)''')
self.mydb.commit()
def process_item(self, item, spider):
try:
sql = "INSERT INTO stocks VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
self.cursor.execute(sql, (
item.get("stockname"), item.get("name"), item.get("newprice"),
item.get("zhangdiefu"), item.get("zhangdieer"),
item.get("chengjiaoliang"), item.get("chengjiaoer"),
item.get("zhenfu"), item.get("zuigao"),
item.get("zuidi"), item.get("jinkai"),
item.get("zuoshou")))
self.mydb.commit()
print("Successfully inserted:", item)
except Exception as e:
print(f"Error inserting item: {e}")
self.mydb.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.mydb.close()
其中self.mydb = pymysql.connect( host="127.0.0.1", port=3306, user='root', password='Wjh040619@', database="stock", charset='utf8' )用于连接自己本地的mysql数据库
配置items.py文件
点击查看代码
import scrapy
class SecondbloodPipeline(scrapy.Item):
stockname = scrapy.Field()
name = scrapy.Field()
newprice = scrapy.Field()
zhangdiefu = scrapy.Field()
zhangdieer = scrapy.Field()
chengjiaoliang = scrapy.Field()
chengjiaoer = scrapy.Field()
zhenfu = scrapy.Field()
zuigao = scrapy.Field()
zuidi = scrapy.Field()
jinkai = scrapy.Field()
zuoshou = scrapy.Field()
确保数据库里的数据储存格式
添加settings.py的一条内容

确保piplines.py能够正常启用
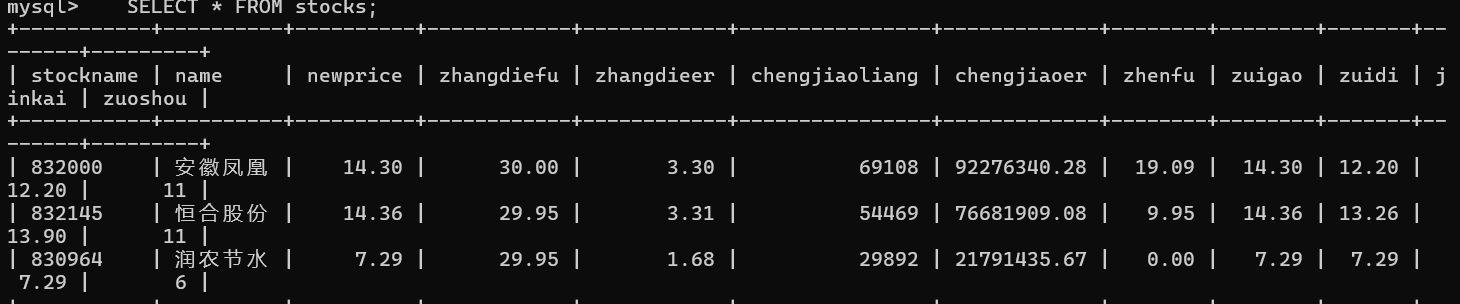
在终端打开mysql创建名为stock的数据库后运行爬虫代码,即可得到输出的结果
心得体会
通过本次作业,我对Scrapy框架在数据提取和存储方面的强大功能有了更深入的理解。使用Item和Pipeline的组合,我能够有效地定义和处理爬取的数据。通过创建Item类,我清晰地规定了要提取的字段,并在Pipeline中对数据进行进一步处理,比如清洗和存储。
在实现数据序列化输出时,我选择了将股票信息存储到MySQL数据库中。这一过程让我意识到,将数据存储与爬取逻辑分离的必要性,使得代码更具可维护性。此外,通过XPath选择器提取信息,我能灵活地定位网页元素,从而高效地获取所需的数据。
在操作MySQL的过程中,我也提升了对数据库基本操作的理解,比如连接、插入和查询等。遇到的一些问题,比如数据重复和连接异常,使我学会了如何调试和优化代码,提升了我的问题解决能力。
总体而言,本次作业不仅增强了我的爬虫技术和数据库管理能力,还让我认识到数据提取过程中系统性思维的重要性。这对我未来的编程实践和项目开发具有积极的推动作用。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
创建完工程后编写爬虫代码work3.py
点击查看代码
import scrapy
from Practical_work3.items import work3_Item
class Work3Spider(scrapy.Spider):
name = 'work3'
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
data_lists = response.xpath('//table[@align="left"]/tr')
for data_list in data_lists:
datas = data_list.xpath('.//td/text()').getall()
if len(datas) >= 7:
item = work3_Item()
item['name'] = datas[0].strip()
item['price1'] = datas[1].strip()
item['price2'] = datas[2].strip()
item['price3'] = datas[3].strip()
item['price4'] = datas[4].strip()
item['price5'] = datas[5].strip()
item['date'] = datas[6].strip()
yield item
编写管道文件pipelines.py
点击查看代码
import pymysql
from Practical_work3.items import work3_Item
class work3_Pipeline:
def open_spider(self, spider):
try:
self.db = pymysql.connect(host='127.0.0.1', user='root', passwd='Wjh040619@', port=3306, charset='utf8',
database='scrapy')
self.cursor = self.db.cursor()
self.cursor.execute('DROP TABLE IF EXISTS bank')
sql = """CREATE TABLE bank(Currency varchar(32), p1 varchar(17), p2 varchar(17), p3 varchar(17), p4 varchar(17), p5 varchar(17), Time varchar(32))"""
self.cursor.execute(sql)
except Exception as e:
print(f"打开爬虫时出错: {e}")
def process_item(self, item, spider):
if isinstance(item, work3_Item):
try:
sql = 'INSERT INTO bank VALUES (%s, %s, %s, %s, %s, %s, %s)'
self.cursor.execute(sql, (
item['name'], item['price1'], item['price2'], item['price3'], item['price4'], item['price5'],
item['date']))
self.db.commit()
except Exception as e:
print(f"处理项时出错: {e}")
return item
def close_spider(self, spider):
self.cursor.close()
self.db.close()
点击查看代码
import scrapy
class work3_Item(scrapy.Item):
name = scrapy.Field()
price1 = scrapy.Field()
price2 = scrapy.Field()
price3 = scrapy.Field()
price4 = scrapy.Field()
price5 = scrapy.Field()
date = scrapy.Field()
在settings.py文件下增加以下配置

确保管道文件的正确运行
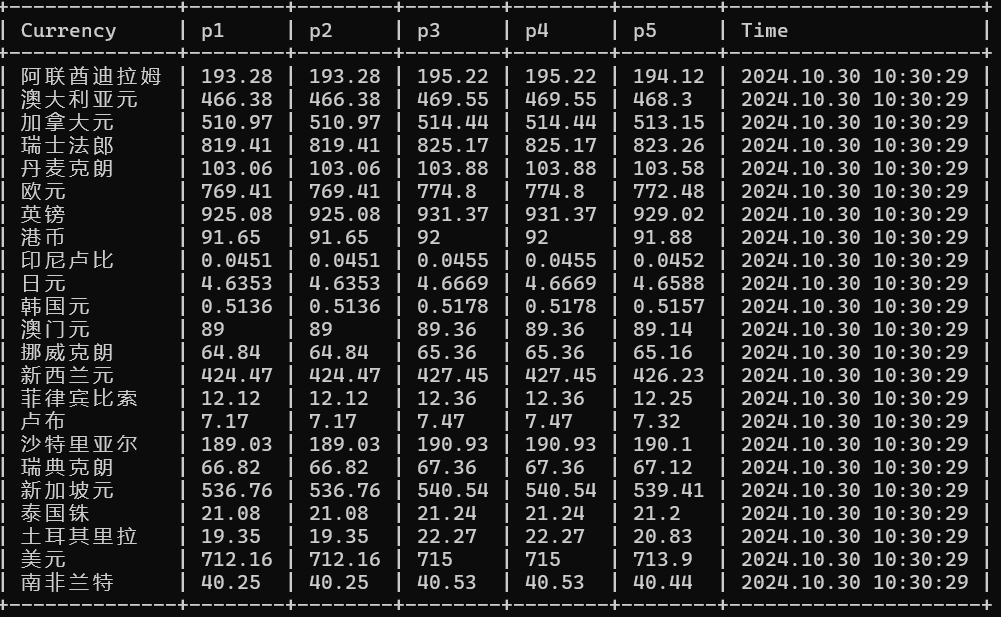
运行结果:
心得体会
在本次实验中,我深入学习了如何使用Scrapy框架爬取中国银行网的外汇数据,掌握了Item、Pipeline以及MySQL数据库的结合使用。这一过程让我体会到数据爬取的系统性和复杂性。
首先,通过定义Item类,我能够清晰地表示要爬取的数据结构,例如外汇名称、汇率和时间等字段。这种结构化的定义使得数据处理更加有序,并提高了数据的一致性。接着,我在Pipeline中实现了数据的清洗和存储,确保了只将有效数据存入数据库中。
使用XPath选择器提取数据的过程非常直观,我能够灵活地获取网页中所需的具体信息。通过分析网页结构,我迅速定位到外汇信息,提升了我的数据抓取效率。
在将数据存储到MySQL数据库的过程中,我学习了如何建立数据库连接、执行插入操作,以及处理可能出现的异常。这让我对数据库操作有了更深入的理解,并提高了我的实际应用能力。
总之,本次实验不仅让我掌握了Scrapy框架的基本用法,还提升了我对数据爬取和存储流程的整体理解。这些经验将为我未来在数据分析和处理方面的项目奠定坚实的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号