数据采集作业二
数据采集作业二
作业1
1.数据采集实验
要求:在中国气象网(http://www.weather.com.cn)给定城市集的 7日天气预报,并保存在数据库。
点击查看代码
from bs4 import BeautifulSoup
from bs4.dammit import UnicodeDammit
import urllib.request
import mysql.connector
class WeatherDB:
def __init__(self):
self.cursor = None
self.con = None
def openDB(self):
self.con = mysql.connector.connect(
host="localhost",
user="root",
password="123456",
database="weather_db"
)
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"CREATE TABLE IF NOT EXISTS weathers (wCity VARCHAR(16), wDate VARCHAR(16), wWeather VARCHAR(64), wTemp VARCHAR(32), PRIMARY KEY (wCity, wDate))"
)
except Exception as err:
print(err)
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute(
"INSERT INTO weathers (wCity, wDate, wWeather, wTemp) VALUES (%s, %s, %s, %s)",
(city, date, weather, temp)
)
except Exception as err:
print(err)
def show(self):
self.cursor.execute("SELECT * FROM weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
self.cityCode = {"郑州": "101180101", "银川": "101170101", "福州": "101230101", "北京": "101010100"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " 找不到代码")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
x = 0
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
if x == 0:
x += 1
temp = li.select('p[class="tem"] i')[0].text
else:
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.closeDB()
ws = WeatherForecast()
ws.process(["郑州", "银川", "福州", "北京"])
print("completed")
运行结果在mysql数据库查看
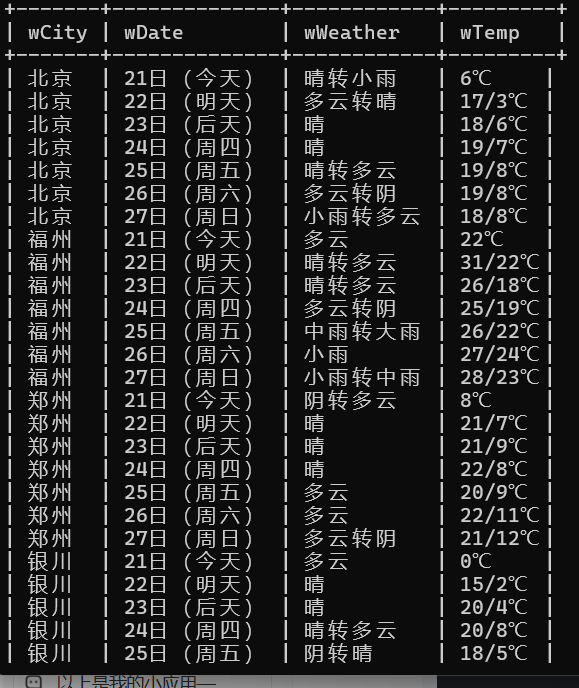
心得体会
在编写这段天气预报程序的过程中,我对Python在网络爬虫和数据库交互方面的应用有了更深的理解。通过使用BeautifulSoup库解析HTML文档,我掌握了如何提取网页中的特定信息,比如天气、日期和温度。这让我意识到,虽然获取信息的过程可能会受到页面结构变化的影响,但灵活运用选择器和异常处理可以有效提高代码的鲁棒性。
此外,使用mysql.connector与MySQL数据库进行交互让我体会到数据持久化的重要性。在这段代码中,我创建了一个数据库来存储天气信息,这样不仅可以方便后续查询,也为数据分析打下了基础。通过封装成WeatherDB类,我能够更好地管理数据库的连接和操作,体现了面向对象编程的优势。
在异常处理方面,代码中通过try-except结构来捕获可能出现的错误,这增强了程序的稳定性,避免了因意外情况导致的程序崩溃。此外,使用用户代理字符串来模拟浏览器请求,有效地避免了因爬虫检测而导致的访问限制。
总的来说,这段代码不仅是对技术的实践,也是对编程思维的培养。让我在实际项目中学习到了如何将不同模块结合在一起,从而实现复杂的功能。通过这次实践,我对爬虫技术和数据库操作的理解更加深入,也激发了我对数据分析和应用开发的兴趣。
作业二
1.数据采集实验
要求:用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/ 新浪股票:http://finance.sina.com.cn/stock/
点击查看代码
import requests
import mysql.connector
import json
db_config = {
'user': 'root',
'password': '123456',
'host': 'localhost',
'database': 'stock_db'
}
conn = mysql.connector.connect(**db_config)
c = conn.cursor()
c.execute('''
CREATE TABLE IF NOT EXISTS stock_data (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_code VARCHAR(10),
stock_name VARCHAR(50),
current_price DECIMAL(10, 2),
change_percent DECIMAL(5, 2),
change_amount DECIMAL(10, 2)
)
''')
url = "http://push2.eastmoney.com/api/qt/clist/get"
params = {
"pn": "1",
"pz": "20",
"po": "1",
"np": "1",
"ut": "bd1d9ddb04089700cf9c27f6f7426281",
"fltt": "2",
"invt": "2",
"fid": "f3",
"fs": "m:0+t:6",
"fields": "f1,f2,f3,f4,f12,f14"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
response = requests.get(url, params=params, headers=headers)
data = response.json()
if data and data['data']:
stock_list = data['data']['diff']
stock_data = []
for stock in stock_list:
stock_code = stock['f12']
stock_name = stock['f14']
current_price = stock['f2']
change_percent = stock['f3']
change_amount = stock['f4']
stock_data.append((stock_code, stock_name, current_price, change_percent, change_amount))
c.executemany('''
INSERT INTO stock_data (stock_code, stock_name, current_price, change_percent, change_amount)
VALUES (%s, %s, %s, %s, %s)
''', stock_data)
conn.commit()
print("股票数据已成功保存到数据库。")
c.close()
conn.close()
心得体会
在编写这段股票数据爬取并存储到数据库的代码过程中,我对Python的网络请求和数据库操作有了更深的理解。首先,通过使用requests库发起HTTP请求,我成功地从东方财富网获取了实时的股票数据。这个过程让我认识到,网络数据爬取的核心在于正确构造请求参数以及处理返回的JSON格式数据。
数据的解析和存储是我学习的另一个重点。利用json库将响应数据转换为Python对象后,我通过遍历获取的股票列表,提取了所需的信息。这一过程中,掌握了如何从复杂的数据结构中筛选出关键信息。
在数据库操作方面,我使用mysql.connector库连接MySQL数据库,并创建了一个存储股票数据的表。通过封装插入操作的SQL语句,使用executemany方法批量插入数据,这不仅提高了插入效率,也确保了数据的一致性。
此外,我认识到异常处理的重要性,尽管在这段代码中没有加入异常处理,但在实际开发中,考虑网络请求失败、数据库连接问题等情况是非常必要的。整体来看,这段代码不仅让我掌握了数据获取与存储的基本流程,还激发了我对数据分析和应用开发的浓厚兴趣。通过实践,我更加坚定了在数据科学领域深入探索的决心。
作业三
1.数据采集实验
要求:爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
点击查看代码
import requests
import re
import mysql.connector
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
class DB:
def open(self):
try:
self.connection = mysql.connector.connect(
host='localhost',
user='root',
password='123456',
database='school_db'
)
self.cursor = self.connection.cursor()
self.cursor.execute(
'CREATE TABLE IF NOT EXISTS schoolrank ('
'排行 INT AUTO_INCREMENT PRIMARY KEY, '
'学校 VARCHAR(16), '
'省市 VARCHAR(16), '
'类型 VARCHAR(16), '
'总分 FLOAT)'
)
except mysql.connector.Error as e:
logging.error(f"Error connecting to database: {e}")
def close(self):
try:
self.connection.commit()
self.cursor.close()
self.connection.close()
except Exception as e:
logging.error(f"Error closing database connection: {e}")
def insert(self, name, province, cata, score):
try:
score = float(score)
self.cursor.execute(
'INSERT INTO schoolrank (学校, 省市, 类型, 总分) VALUES (%s, %s, %s, %s)',
(name, province, cata, score)
)
logging.info(f"Inserted: {name}, {province}, {cata}, {score}")
except ValueError as ve:
logging.warning(f"ValueError: {ve} - Invalid score value for {name}. Skipping this entry.")
except Exception as e:
logging.error(f"Error inserting data: {e}")
url = r'https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js'
req = requests.get(url)
req.raise_for_status()
req.encoding = req.apparent_encoding
data = req.text
univerCnlist = re.findall('univNameCn:"(.*?)",', data)
provincelist = re.findall('province:(.*?),', data)
univerCategorylist = re.findall('univCategory:(.*?),', data)
scorelist = re.findall('score:(.*?),', data)
logging.info(f"University Count: {len(univerCnlist)}")
func_data_key = data[len('__NUXT_JSONP__("/rankings/bcur/2021", (function('):data.find(')')].split(',')
func_data_value = data[data.rfind('(') + 1:-4].split(',')
mydict = {key: value for key, value in zip(func_data_key, func_data_value)}
name = univerCnlist
province = [mydict[item] for item in provincelist]
cate = [mydict[item] for item in univerCategorylist]
db = DB()
db.open()
for i in range(len(name)):
db.insert(name[i], province[i], cate[i], scorelist[i])
db.close()
心得体会
在实现这段代码的过程中,我对数据抓取和数据库操作的整体流程有了更深入的理解。首先,通过requests库向目标URL发起请求,成功获取了包含大学排名信息的JavaScript数据。这一部分让我认识到,HTTP请求和响应的处理是网络数据获取的基础。
接着,我使用正则表达式从返回的文本中提取了有用的数据,如大学名称、省市、类型和分数。这一过程让我体会到,数据清洗和提取在实际应用中是多么重要,尤其是在处理不规则的数据格式时。
在数据库操作方面,我创建了一个数据库连接并构建了表结构,使用mysql.connector库进行数据插入。这让我认识到,数据库的设计和操作需要与数据的结构紧密结合。在插入数据时,注意到数据类型的转换,如将分数转为浮点数,以确保数据的准确性。
此外,设置日志记录功能使我能够实时监控程序的运行状态,及时捕捉并处理可能出现的异常。这一点对于维护代码的稳定性和可调试性至关重要。
总的来说,这段代码的实现不仅提升了我的编程技能,还增强了我对数据处理和存储流程的理解,使我更加期待在数据分析和工程领域的进一步探索。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号