python中常用模块之re模块以及正则表达式
一,正则表达式:
正则表达式不仅仅用在python中,而是所有语言都可使用。只是调用方法各不相同。
#在python中纯代码校验手机号码:
while True: phone_number = input('please input your phone number :') if len(phone_number) == 11 \ and phone_number.isdigit()\ and (phone_number.startswith('13') \ or phone_number.startswith('14') \ or phone_number.startswith('15') \ or phone_number.startswith('16')\ or phone_number.startswith('17')\ or phone_number.startswith('18')): print('合法手机号码') else: print('不是合法手机号码')
#在python中调用re模块使用正则表达式校验手机号码:
import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|16|17|18)[0-9]{9}$',phone_number): print('是合法手机号码') else: print('不是合法手机号码')
结论:在python中调用re模块使用正则表达式会简便很多。
正则表达式的语法如下:
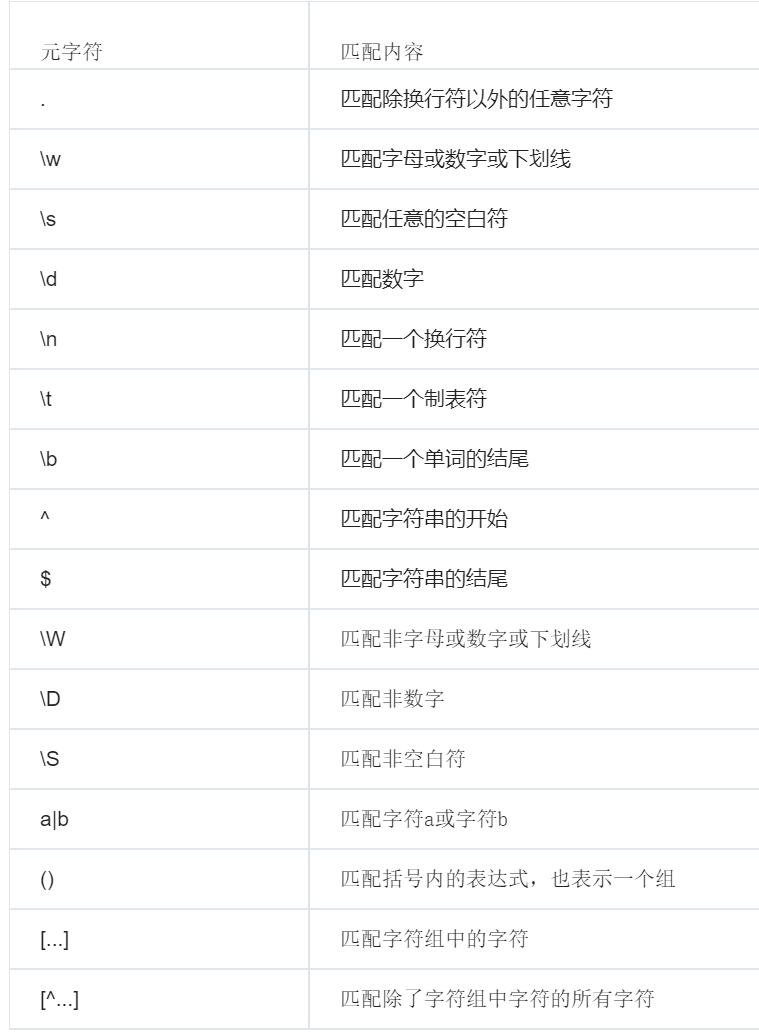
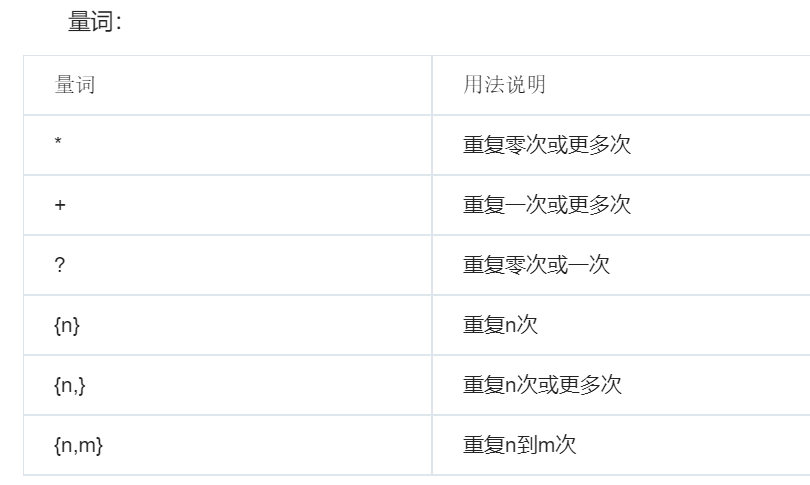
其中量词‘*’,‘+’,‘?’都是贪婪匹配,就是往更多次匹配字符,如果量词后面加了 ‘?’ 这个符号,就表示惰性匹配,换句话说就是尽量往少的匹配。
在匹配实列中的体现如下:
1. ‘.’ ,‘^’,‘$’ 三个的具体表现
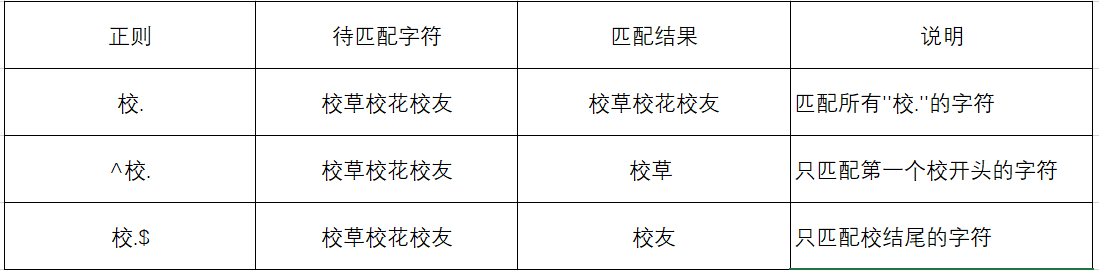
2.‘?’,‘+’,‘*’,‘{}’ 具体表现
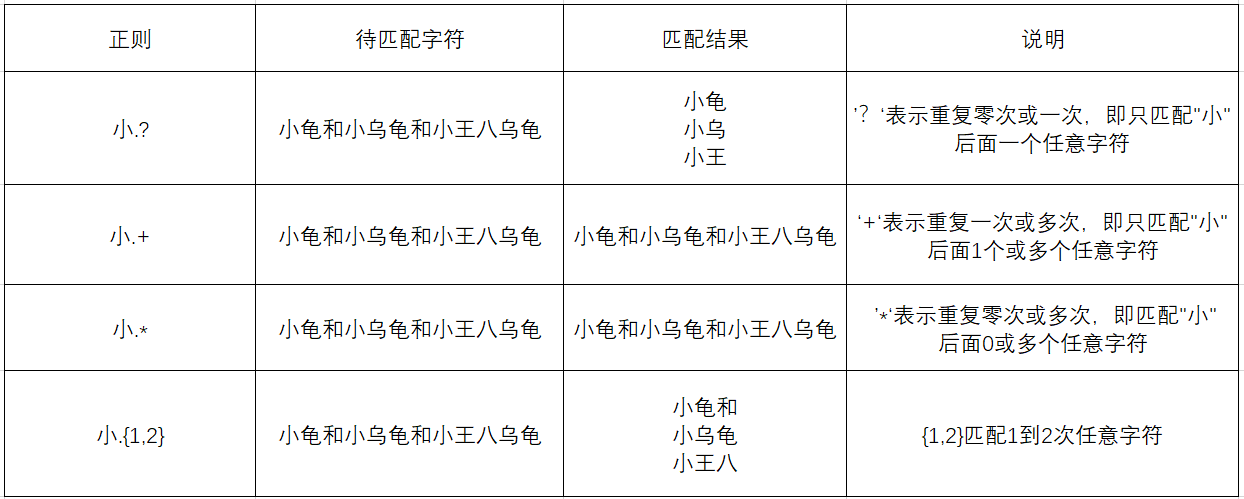
当量词后加上‘?’发生了变化。

3.‘[^]*’ 的用法:

二,总结几个常用的贪婪匹配的组合
![]()

三,贪婪匹配和非贪婪匹配
1.
re模块的使用:
三个必须掌握的方法有如下
1.findall
import re
res = re.findall('c','andy cody jcason') #查找字符串中所有‘c’字符
print(res)#返回所有的满足匹配条件的放在列表里, ['c','c']
findall 查找所有字符,只要是能匹配到的字符,全部放在一个列表里,不需要调用group方法。
2.search
import re
res = re.search('c','ancdy cody jcason') print(res.group()) #用group方法
search 查找所有字符,只要找到第一个匹配到的字符后会停止查找,并返回匹配的字符。
全部字符中如果没有要找的字符,就会返回None,如果用group方法调用就会报错。
3.match
import re
res = re.match('c','cncdy cody jcason')
print(res.group()) #‘c’
match 只会找字符中的开头字符是否含有所匹配的字符,有就会返回匹配的字符
如果字符开头不是要找的字符,就会返回None, 如果用group方法调用就会报错
其他涉及到的使用方法:
1.split
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd']
2.sub
ret = re.sub('\d', 'W', '3andy4cody4', 1) # 将数字替换成'W',参数1表示只替换1个 print(ret) # Wandy4cody4
3.subn
ret = re.subn('\d', 'W', '3andy4cody4', 1) # 将数字替换成'W' print(ret) # WandyWcodyW 返回元组(替换的结果,替换了多少次)
4.compile
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123


 浙公网安备 33010602011771号
浙公网安备 33010602011771号