
微信小程序实现博客园文章阅读功能
在微信小程序开发中,我们可以根据不同的业务场景,开发不同的业务应用,可以基于自身域名服务接口,也可以基于第三方的域名接口进行处理(如果被禁用除外),本篇随笔介绍使用小程序来实现我博客(http://wuhuacong.cnblogs.com)的文章阅读功能,这个小程序主要用来介绍使用介绍基于Javascript的正则表达式的处理应用,和常规在C#里面使用正则表达式有一些差异,因此可以作为后续使用正则表达式处理业务数据的一个练兵吧。
1、Request接口合法域名配置
一般情况下,我们知道微信的Request请求是需要配置合法的域名的,这种安全性可以是微信拦截有潜在危险的或者不喜欢的域名接口,Request合法域名配置界面如下所示。
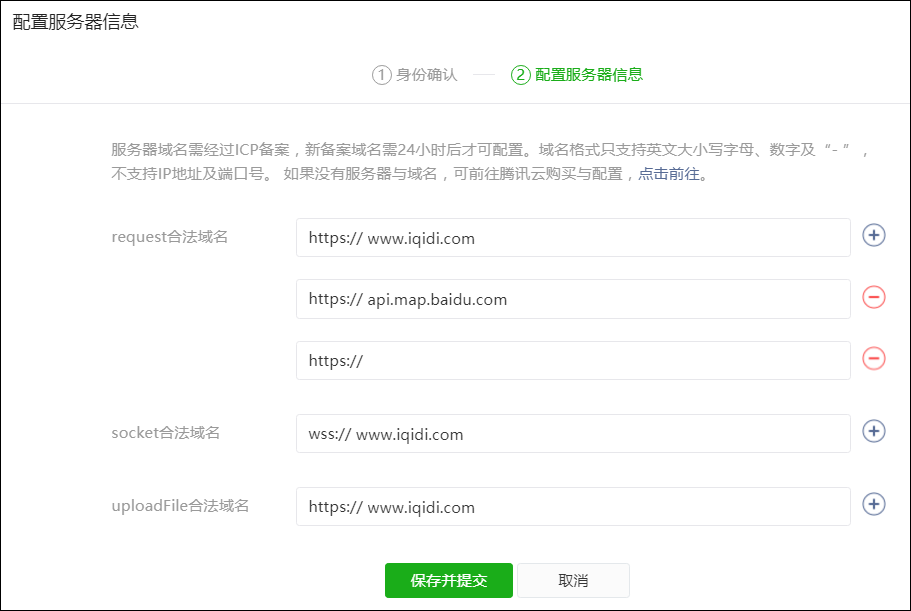
一般情况下,我们在上面增加合法域名即可,这样小程序发布后,就可以顺利通过检查并获取数据了,本篇随笔由于想读取博客园个人博客园的文章,因此需要配置博客园的域名,不过很不幸,博客园的域名上了黑名单被禁用了。
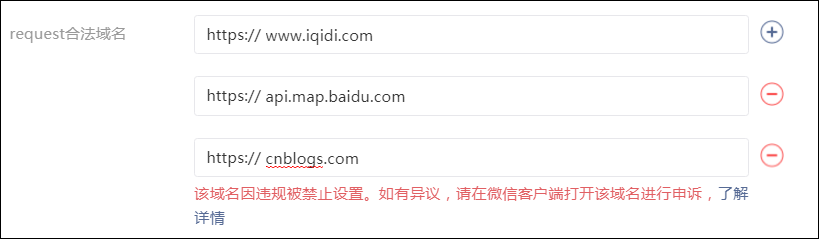
如果我们在开发环境,我们可以通过不包含对合法域名的检验处理,不过在开发环境必须取消勾选“不校验”。

2、小程序功能设计
首先我们来看看主体界面的效果图,然后在进行分析具体的功能实现,具体界面效果如下所示。
博客文章列表内容如下所示:
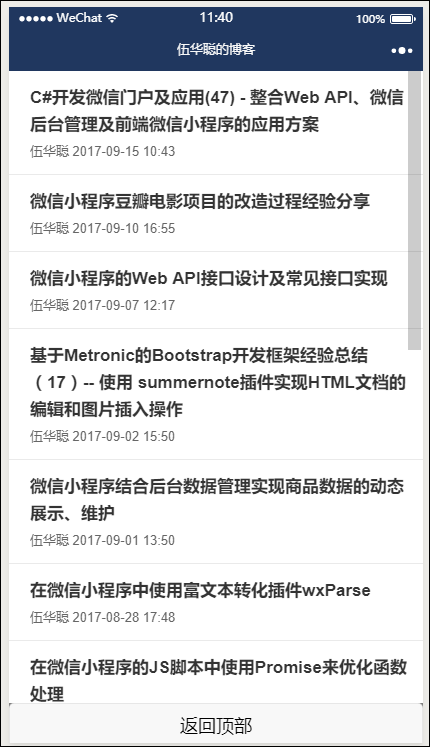
文章详细界面效果如下所示:

这些文章直接都是从博客园页面中获取,并通过Javascript的正则表达式进行提取,然后展示在小程序上的,对于HTML内容的展示我们还是使用了WxParse的这个HTML解析组件,具体功能和使用过程可以参考我之前的随笔《在微信小程序中使用富文本转化插件wxParse 》进行详细了解。对于Javascript函数的封装,我们还是使用比较方便的Promise进行封装处理,具体知识可以参考我随笔《在微信小程序的JS脚本中使用Promise来优化函数处理 》进行详细了解。
一般我们也准备把公用方法提取出来,放到工具类Utils/util.js里面,配置统一放到utils/config.js里面,这样方便小程序的模块化处理。
项目的文件目录如下所示。

在Utils/util.js里面,我们封装了wx.request的获取内容方法如下所示。
//封装Request请求方法 function request(url,method,data = {},type='application/json'){ wx.showNavigationBarLoading(); return new Promise((resove,reject) => { wx.request({ url: url, data: data, header: {'Content-Type': type}, method: method.toUpperCase(), // OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE, CONNECT success: function(res){ wx.hideNavigationBarLoading() resove(res.data) }, fail: function(msg) { console.log('reqest error',msg) wx.hideNavigationBarLoading() reject('fail') } }) }) }
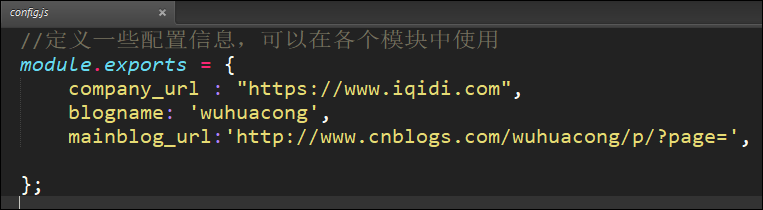
而在Config.js里面,我们主要定义好一些常用的参数,如URL等
在列表页面,我们主要是展示文字标题和日期等信息,而列表是需要滚动翻页的,因此我们使用微信界面组件 scroll-view 来展示,具体界面代码如下所示。
<block wx:if="{{showLoading}}"> <view class="loading">玩命加载中…</view> </block> <block wx:else> <scroll-view scroll-y="true" style="height: {{windowHeight}}rpx" scroll-top="{{scrollTop}}" bindscroll="scroll" bindscrolltolower="scrolltolower"> <view class="blog"> <block wx:for="{{blogs}}" wx:for-index="blogIndex" wx:for-item="blogItem" wx:key="blog"> <view data-id="{{blogItem.id}}" catchtap="viewBlogDetail" class="flex box box-lr item"> <view class="flex item_left"> <view><text class="title">{{blogItem.title}}</text></view> <view><text class="sub_title">{{blogItem.date}}</text></view> </view> </view> </block> <block wx:if="{{hasMore}}"> <view class="loading-tip">拼命加载中…</view> </block> <block wx:else> <view class="loading-tip">没有更多内容了</view> </block> </view> </scroll-view> </block>
通过绑定向下滑动的事件 bindscrolltolower="scrolltolower" 我们可以实现列表内容的滚动刷新。
我们通过前面介绍的封装Request方法,可以获取到HTML内容,如下函数所示。
//获取博客文章列表 getList:function(start =1) { return new Promise((resolve, reject) => { var that = this; var data = {}; var type = "text/html"; var url = config.mainblog_url + start; if (that.data.hasMore) { app.utils.get(url, data, type).then(res => {
通过指定type = "text/html",并且传入对应的起始位置,可以获取到对应页面的内容。
在博客园里面,【我的随笔】里面的标准URL地址为:http://www.cnblogs.com/wuhuacong/p/?page=n,其中 n 是当前的页码。
页面上的页码效果如下所示:

分析页面源码,可以看到页码标签的源码如下所示。

因此我们对HTML源码进行正则表达式的匹配即可获取对应的内容(关键是获取多少页,为后面循环获取文章列表做准备)。
关于正则表达式的测试,建议使用RegExBuilder(http://www.jb51.net/softs/389196.html)进行测试,其实我之前倾向于使用The Regulator 2.0这个很好的程序测试正则表达式,不过这个软件经常性的不能启动使用。
不过后来测试使用RegExBuilder,也觉得非常不错,其中勾选ECMAScript是为了我们在Javascript使用正则表达式的选项,毕竟和在C#里面使用正则标识还是有一些差异,如不支持单行选择,以及一些微小差异。
对于在Javascript中使用正则标识,建议大家温习下下面几篇随笔,有所帮助:
《使用javascript正则表达式实现遍历html字符串》
以及一个常见的坑,在HTML内容匹配的时候,不支持.*这种很普通的模式,这种由于不能选择单行模式导致的,变通的方式是使用[\s\S]来实现匹配所有字符处理。
可以参考文章:https://stackoverflow.com/questions/1068280/javascript-regex-multiline-flag-doesnt-work 了解下。
另外对于Javascript的正则书写,经常看到i,g,m的结束符
修饰符 描述
i (ignore case)
执行对大小写不敏感的匹配。
g (global search)
执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)。
m (multiline)
执行多行匹配。
它的意思你参考文章了解:
https://zhidao.baidu.com/question/620656820875333772.html
Javascript的正则匹配处理,支持正则表达式的String对象的方法可以使用search()方法、match()方法、replace()方法、split()方法、
而RegExp对象方法包括:test()方法、exec()方法。
具体Javascript的正则表达式使用,可以好好学习下《深入浅出的javascript的正则表达式学习教程》,就很清晰了。
例如对于我们这篇小程序,我们获取页码的js代码如下所示。
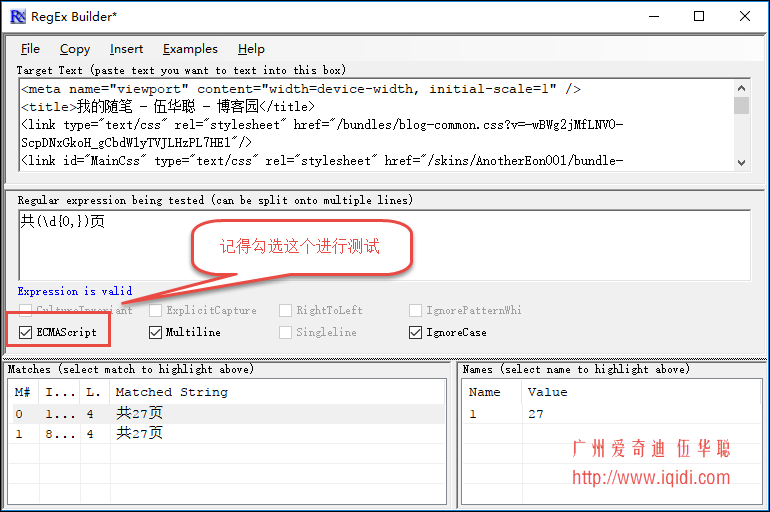
var reg = /共(\d{0,})页/g; var pageNum = reg.exec(html)[1]; //console.log(pageNum); that.setData({ end:pageNum, //设置最大页码 });
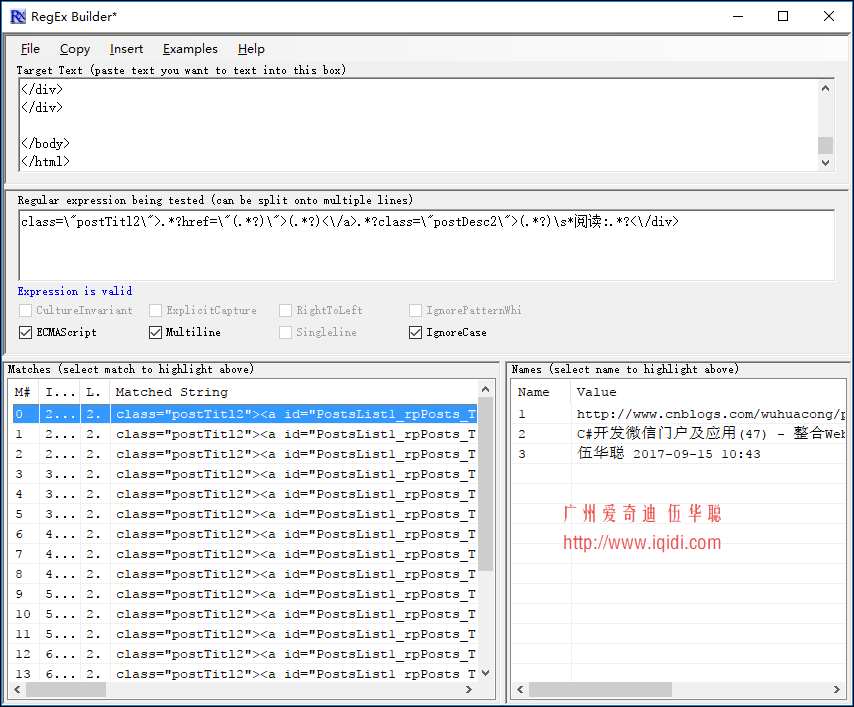
在获取每篇随笔文章的标题、URL、日期等信息,我编写了一个正则表达式来匹配,如下所示。
var regContent=/class=\"postTitl2\">.*?href=\"(.*?)\">(.*?)<\/a>.*?class=\"postDesc2\">(.*?)\s*阅读:.*?<\/div>/igm;
正则表达式的内容,在使用前,一定需要在这个工具上测试,测试通过了我们再在代码上使用,减少调试错误的时间。
下面的测试结果如下所示。
获取文章列表信息的小程序js代码如下所示。

在之前介绍的列表展示界面代码里面,我们绑定了单击连接的事件,如下界面所示标注所示。

这个事件就是触发导航到详细界面,如下所示,我们把URL作为id传入到详细的界面里面。
viewBlogDetail: function(e) { var data = e.currentTarget.dataset; var url = data.id; // console.log(url); wx.navigateTo({ url: "../details/details?id=" + data.id }) },
在文章详细界面展示里面,界面的代码如下所示。
<import src="../../utils/wxParse/wxParse.wxml" /> <view class="flex box box-lr item"> <view class="flex item_left"> <view> <text class="title">{{detail.title}}</text> </view> </view> </view> <view class="page"> <view class="page__bd"> <view class="weui-article"> <view class="weui-article__p"> <template is="wxParse" data="{{wxParseData:article.nodes}}"/> </view> </view> </view> </view>
这里引入了WxParse作为HTML内容解析的组件,我们在页面代码顶部引入组件代码
<import src="../../utils/wxParse/wxParse.wxml" />
具体处理的内容在JS代码里面,我们的JS代码如下所示。
//获取文章详细内容 getDetail(url) { var that = this; var type = "text/html"; app.utils.get(url, {}, type).then(res => { // console.log(res); var html = res; var regContent = /id=\"cb_post_title_url\".*?>([\s\S]*?)<\/a>[\s\S]*?id=\"cnblogs_post_body\">([\s\S]*?)<\/div><div\s*id=\"MySignature\">/igm var matchArr; if ((matchArr = regContent.exec(html))) { var detail = { id: url, title : matchArr[1], //titile content : matchArr[2], //content }; that.setData({ detail:detail }); WxParse.wxParse('article', 'html', detail.content, that, 5); }; }); },
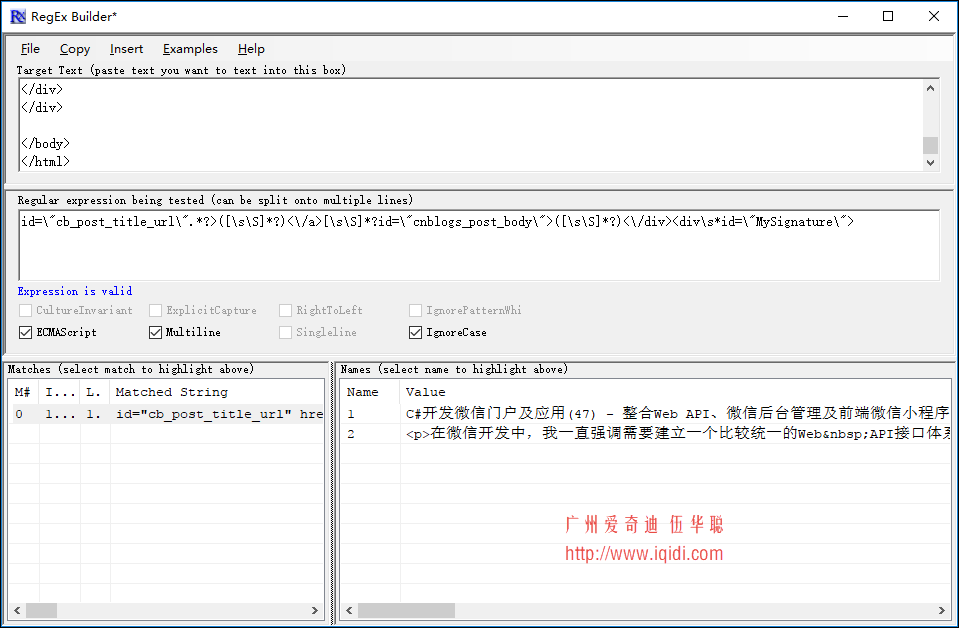
其中的Javascript的正则表达式如下:
var regContent = /id=\"cb_post_title_url\".*?>([\s\S]*?)<\/a>[\s\S]*?id=\"cnblogs_post_body\">([\s\S]*?)<\/div><div\s*id=\"MySignature\">/igm
我们在工具上测试,得到相关的效果后再在代码上使用。
最后就可以获得详细的展示效果了,文章详细界面效果如下所示:
 专注于代码生成工具、.Net/.NetCore 框架架构及软件开发,以及各种Vue.js的前端技术应用。著有Winform开发框架/混合式开发框架、微信开发框架、Bootstrap开发框架、ABP开发框架、SqlSugar开发框架等框架产品。
专注于代码生成工具、.Net/.NetCore 框架架构及软件开发,以及各种Vue.js的前端技术应用。著有Winform开发框架/混合式开发框架、微信开发框架、Bootstrap开发框架、ABP开发框架、SqlSugar开发框架等框架产品。
转载请注明出处:撰写人:伍华聪 http://www.iqidi.com


