Python 开发环境的准备以及一些常用类库模块的安装
在学习和开发Python的时候,第一步的工作就是先准备好开发环境,包括相关常用的插件,以及一些辅助工具,这样我们在后续的开发工作中,才能做到事半功倍。下面介绍一些Python 开发环境的准备以及一些常用类库模块的安装和使用的经验总结,供大家参考了解。
1、开发VScode的安装及相关准备
在 Python 开发环境的准备中,有几个步骤是关键的。以下是一个详细的指南,涵盖了开发环境的准备以及一些常用插件的安装:
1)安装 VS Code
VS Code: 这是一个轻量级但功能强大的代码编辑器,支持丰富的扩展。你可以从 Visual Studio Code 官方网站 下载。打开官网 https://code.visualstudio.com/,下载软件包。或者你也可以使用其他的如 PyCharm,可以从 JetBrains 官方网站 下载。
Python AI 编程助手:Fitten Code:
它是由非十大模型驱动的 AI 编程助手,它可以自动生成代码,提升开发效率,帮您调试 Bug,节省您的时间,另外还可以对话聊天,解决您编程碰到的问题。
Fitten Code是由非十大模型驱动的AI编程助手,它可以自动生成代码,提升开发效率,帮您调试Bug,节省您的时间。还可以对话聊天,解决您编程碰到的问题。免费且支持80多种语言:Python、C++、Javascript、Typescript、Java等。
强烈推荐使用,自动补齐代码功能,可以节省很多手工键入代码的时间,减少错误。
2)安装 VS Code Python 扩展
在VSCode中安装 Python 扩展,在扩展市场搜索 Python 并安装。
3)安装 Python
首先,确保你已经安装了 Python。你可以从 Python 官方网站 下载最新版本安装包并安装。
Window 平台安装 Python: https://www.python.org/downloads/windows/
Mac 平台安装 Python: https://www.python.org/downloads/mac-osx/
4)配置 Python 环境变量
打开系统环境变量,在 PATH 变量中添加 Python 目录,这样可以在命令行中直接使用 Python。
5)测试 Python 环境
在命令行中输入 python,如果出现 Python 解释器版本信息,则表示 Python 环境配置成功。
6)安装 pip
打开命令行,输入 pip install --upgrade pip,升级 pip 到最新版本。
7)安装 virtualenv
打开命令行,输入 pip install virtualenv,安装 virtualenv。
2、Python一些常用类库模块的安装
Python开发常用类库模块非常多,看你侧重于那个方面,基本上都时列出来一大串,我以常规后端Web API开发为侧重点进行一些重点的推介,供参考学习。
1) requests
requests 是一个简单易用的 Python 库,地址:https://github.com/psf/requests,用于发送 HTTP 请求。它的设计目标是使得与 Web 服务的交互更加方便和人性化。requests 是基于 urllib3 之上的一个封装层,提供了简洁的 API 来处理常见的 HTTP 请求操作,如 GET、POST、PUT、DELETE 等。
requests 的主要特性
- 简洁的 API:相比原生的
urllib,requests提供了更直观、更容易理解的接口。 - 自动处理编码:
requests自动处理响应的内容编码,并自动解码gzip和deflate压缩。 - 支持保持会话:通过
Session对象,requests可以在多个请求之间保持会话,处理 cookies。 - 简化的错误处理:
requests会根据 HTTP 响应状态码抛出相应的异常,从而简化错误处理流程。 - 丰富的功能:支持 HTTP 认证、代理、SSL 证书验证、文件上传、多部分编码表单、会话对象、cookie 持久化、连接池管理等功能。
如果需要考虑异步处理,可以使用 aiohttp :aiohttp 是一个异步 HTTP 客户端和服务器框架,它使用 Python 的 asyncio 库来处理大量并发的请求。aiohttp 适合那些需要高性能网络通信的应用,如 Web 服务、WebSocket 和实时数据处理。
2) Uvicorn
Uvicorn 是一个基于 ASGI(Asynchronous Server Gateway Interface)的高性能、轻量级的 Python Web 服务器,专为运行异步 Web 框架(如 FastAPI、Starlette)而设计。它利用了 Python 的异步功能,能够处理大量并发连接,适合构建现代的异步 Web 应用程序。
Uvicorn 的主要特性
- 高性能: 使用
uvloop和httptools提供极高的性能,适合在高并发场景下使用。 - 异步支持: 支持异步编程模型,能够与 Python 的
asyncio和trio无缝集成。 - ASGI 兼容: 完全兼容 ASGI 标准,适用于现代异步 Web 框架,如 FastAPI 和 Starlette。
- WebSocket 支持: 通过 ASGI,
Uvicorn原生支持 WebSocket 协议。 - 灵活的部署: 既可以作为独立的开发服务器使用,也可以与
Gunicorn等 WSGI 服务器结合部署生产环境。
Uvicorn 通常用于运行 FastAPI 或 Starlette 应用。以下是一个简单的 FastAPI 应用并使用 Uvicorn 运行:
from fastapi import FastAPI app = FastAPI() @app.get("/") async def read_root(): return {"Hello": "World"} if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8000)
3)FastAPI
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API。它基于 Python 3.7+ 的类型提示,并且依赖于 Starlette(用于 web 服务器和路由)和 Pydantic(用于数据验证和序列化)。FastAPI 的设计目标是提供与 Flask 和 Django 类似的开发体验,但在性能、类型安全和开发者友好性方面做出更大的提升。GitHub地址:https://github.com/fastapi/fastapi
FastAPI 的主要特性
- 极高的性能: 基于 ASGI 的异步支持,使得
FastAPI在性能上接近 Node.js 和 Go 的水平,适合处理高并发。 - 自动生成 API 文档: 使用 OpenAPI 和 JSON Schema 自动生成交互式的 API 文档(如 Swagger UI 和 ReDoc)。
- 基于类型提示的自动验证: 利用 Python 的类型提示和
Pydantic,自动进行数据验证和解析。 - 异步支持: 原生支持
async和await,能够处理异步任务,适合与数据库、第三方 API、WebSocket 等交互。 - 内置依赖注入系统: 使得依赖的声明和管理变得简洁而强大,便于模块化设计。
- 开发者友好: 提供了详细的错误信息和文档,支持自动补全,极大提升了开发效率。
以下是一个简单的 FastAPI 应用:
from fastapi import FastAPI app = FastAPI() @app.get("/") async def read_root(): return {"message": "Hello, World"} @app.get("/items/{item_id}") async def read_item(item_id: int, q: str = None): return {"item_id": item_id, "q": q}
当你运行 FastAPI 应用时,它会自动生成交互式文档:
- Swagger UI: 访问
http://127.0.0.1:8000/docs - ReDoc: 访问
http://127.0.0.1:8000/redoc
这两个文档界面可以让你查看 API 的结构,甚至可以直接在界面中进行 API 调用。如我在上篇随笔进行介绍的《Python中FastAPI项目使用 Annotated的参数设计》。
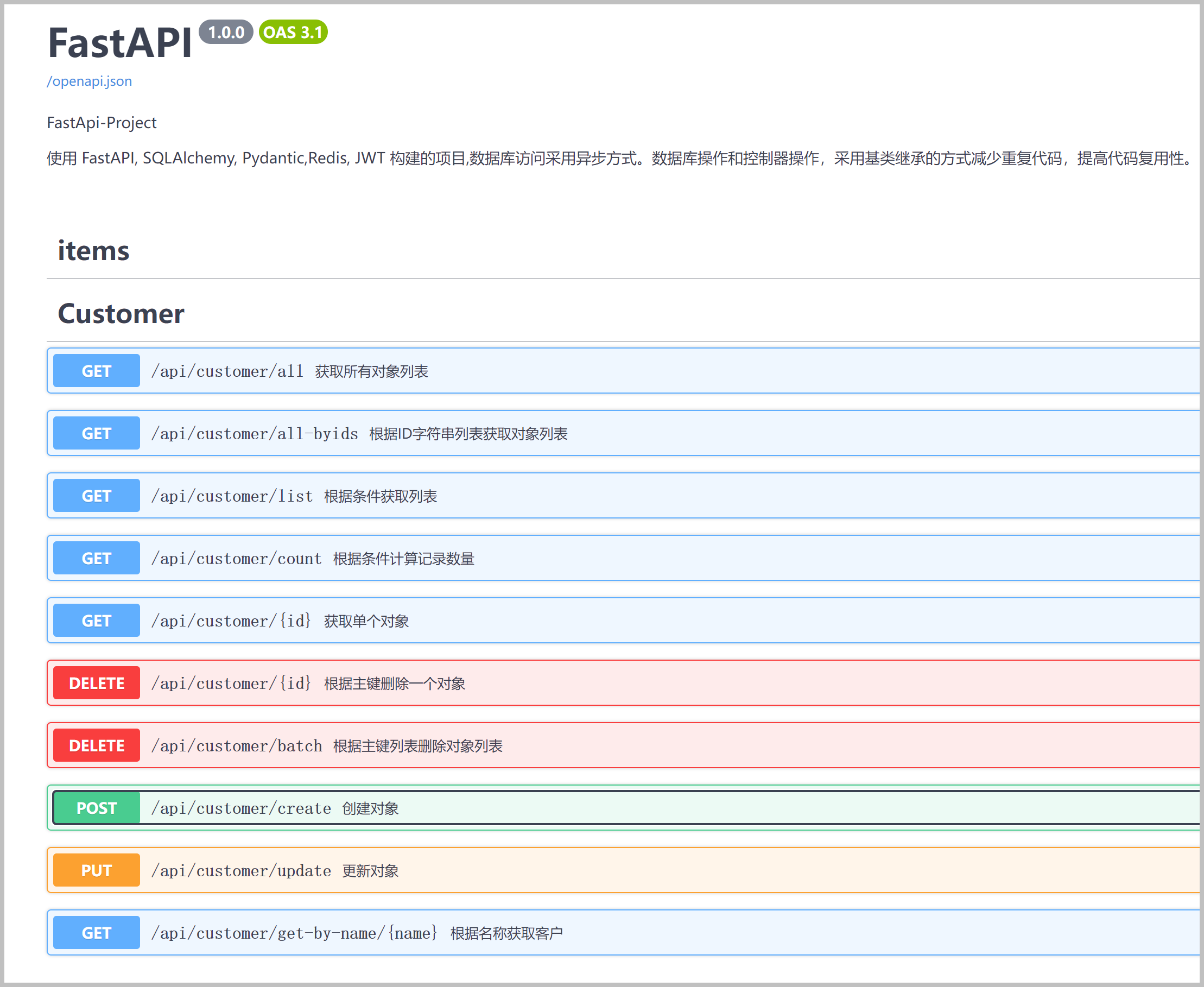
FastAPI 是一个非常现代化和高效的框架,非常适合用于构建高性能的 API。其自动文档生成、数据验证和依赖注入等特性,使得开发者能够更快、更安全地编写代码,并提供出色的用户体验。
FastAPI项目的参数设计,这些您可以在路径操作函数参数或使用Annotated的依赖函数中使用的特殊函数,用于从请求中获取数据。
我们引入配置文件,可以对FastAPI 中服务启动的参数进行统一的管理,如下main.py 代码所示。
if __name__ == "__main__": import uvicorn # log_level:'critical', 'error', 'warning', 'info', 'debug', 'trace'。默认值:'info'。 uvicorn.run( app, host=settings.SERVER_IP, port=settings.SERVER_PORT, log_config="app/uvicorn_config.json", # 日志配置 # log_level="info", # 日志级别 )
3)pymysql 、pymssql、和 SQLAlchemy
涉及后端的处理,肯定绕不过数据库的处理操作,如对于MySQL、MS SqlServer等数据库的处理和封装。
PyMySQL 是一个纯 Python 实现的 MySQL 客户端库,用于连接 MySQL 数据库并执行 SQL 查询。它是 Python 的 MySQLdb 库的替代品,尤其适合那些在使用 Python 3 并且不希望依赖 C 语言扩展的项目。PyMySQL 支持 MySQL 数据库的所有主要功能,包括事务、存储过程、连接池等。
PyMySQL 的主要特性
- 纯 Python 实现: 不依赖 C 扩展,易于安装和跨平台使用。
- 兼容性好: 与
MySQLdb的接口非常相似,便于从MySQLdb迁移到PyMySQL。 - 支持 MySQL 的所有主要功能: 包括事务处理、存储过程、BLOB 数据类型等。
- 简单易用: 提供了直观的 API 进行数据库连接、查询、插入、更新和删除操作。
安装 PyMySQL
你可以通过 pip 来安装 PyMySQL:
pip install pymysql
使用 PyMySQL 连接到 MySQL 数据库:
import pymysql connection = pymysql.connect( host='localhost', user='your_username', password='your_password', database='your_database' ) try: with connection.cursor() as cursor: # 执行 SQL 查询 cursor.execute("SELECT VERSION()") # 获取查询结果 result = cursor.fetchone() print(f"MySQL version: {result}") finally: connection.close()
如下是我实际表的一些操作例子代码。
sql = "select * from t_customer where name = '{0}' LIMIT 1 ".format(name) print(sql) cursor.execute(sql) myresult = cursor.fetchone() # fetchone() 获取一条记录 if myresult: print("该名称已存在,请更换名称.") else: print("该名称可用.") # 插入记录语句 sql = "INSERT INTO `t_customer` (`ID`, `Name`, `Age`, `Creator`, `CreateTime`) VALUES (%s, %s, %s, %s, %s);" val = (id, name, age, creator, createtime) cursor.execute(sql, val) db.commit() # 数据表内容有更新,必须使用到该语句 print(cursor.rowcount, " 行记录插入.") sql = "update t_customer Set age = %s where name =%s " val = (26, name) cursor.execute(sql, val) db.commit() # 数据表内容有更新,必须使用到该语句 print(cursor.rowcount, " 条记录被修改") sql = "select * from t_customer where name = '{0}' LIMIT 1 ".format(name) cursor.execute(sql) myresult = cursor.fetchone() # fetchone() 获取一条记录 if myresult: print("修改后的记录: ", myresult) sql = "SELECT * FROM t_customer" cursor.execute(sql) print("t_customer 结果集: ") for x in cursor: print(x) sql = "delete from t_customer where name =%s " try: cursor.execute(sql, (name,)) db.commit() # 数据表内容有更新,必须使用到该语句 print(cursor.rowcount, " 行记录删除.") except: db.rollback() # 发生错误时回滚 print("删除记录失败!") sql = "SELECT * FROM t_customer" cursor.execute(sql) myresult = cursor.fetchall() # fetchall() 获取所有记录 for x in myresult: print(x) # 关闭数据库连接 db.close()
输出的显示如下所示。
pymssql 是一个用于连接 Microsoft SQL Server 数据库的 Python 库,它是基于 FreeTDS 实现的轻量级数据库接口,旨在简化 Python 与 SQL Server 之间的交互。pymssql 提供了对 T-SQL 语句的支持,并且可以执行存储过程和处理大批量数据插入等任务。
pymssql 的主要特性
- 轻量级和易用性: 提供了简单的 API 接口,易于快速上手。
- 与 SQL Server 兼容: 支持 Microsoft SQL Server 2005 及以上版本。
- 跨平台支持: 支持在 Windows、Linux 和 macOS 系统上运行。
- 集成事务管理: 通过
commit和rollback方法进行事务管理。 - 支持存储过程: 能够执行和处理存储过程,适用于复杂的数据库操作。
- 批量插入支持: 通过
executemany方法高效地插入大量数据。
安装 pymssql
你可以通过 pip 安装 pymssql:
pip install pymssql
使用 pymssql 连接到 SQL Server 数据库,pymssql 支持事务,可以在执行多个操作时使用事务控制,以确保数据一致性:
import pymssql # Connect to the database conn = pymssql.connect( server="localhost", user="sa", password="123456", database="Winframework", tds_version="7.0", ) # Create a cursor object cursor = conn.cursor() # Execute a query cursor.execute("SELECT * FROM T_Customer") # Fetch all the rows rows = cursor.fetchall() # Print the rows for row in rows: print(row) # Close the cursor and connection cursor.close() conn.close()
SQLAlchemy 允许开发者通过 Python 代码与数据库进行交互,而无需直接编写 SQL 语句,同时也支持直接使用原生 SQL 进行复杂查询。SQLAlchemy 的主要特性
- 对象关系映射(ORM): 允许将 Python 类映射到数据库表,并且自动处理 SQL 的生成和执行。
- SQL 表达式语言: 提供了一个表达式语言层,允许构建和执行原生 SQL 查询,同时保留类型安全性和跨数据库兼容性。
- 数据库抽象层: 提供了跨数据库的兼容性,使得在不同数据库之间切换变得相对容易。
- 高性能: 通过细粒度的控制和缓存机制,优化了数据库访问的性能。
- 事务管理: 支持复杂的事务处理和上下文管理,使得数据库操作更加安全和一致。
- 支持多种数据库: 支持大多数主流的关系型数据库,如 SQLite、PostgreSQL、MySQL、Oracle、SQL Server 等。
安装 SQLAlchemy
你可以通过 pip 安装 SQLAlchemy:
pip install sqlalchemy
如果你要连接到特定的数据库,还需要安装相应的数据库驱动程序。例如,要连接到 MySQL 数据库,你还需要安装 pymysql 或 mysqlclient:
使用 SQLAlchemy 操作数据库,可以统一多种数据库的操作处理,如SQLITE、SqlServer、MySQL、PostgreSQL等。
使用 SQLAlchemy 创建与数据库的连接:
# mysql 数据库引擎 engine = create_engine( "mysql+pymysql://root:123456@127.0.0.1:3306/WinFramework", pool_recycle=3600, # echo=True, ) # Sqlite 数据库引擎 # engine = create_engine("sqlite:///testdir//test.db") # PostgreSQL 数据库引擎 # engine = create_engine( # "postgresql+psycopg2://postgres:123456@localhost:5432/winframework", # # echo=True, # ) # engine = create_engine( # "mssql+pymssql://sa:123456@localhost/WinFramework?tds_version=7.0", # # echo=True, # )
由于对应的是ORM处理方式,因此和数据库表关联需要定义一个类对象,如下所示。
from sqlalchemy import create_engine, Column, Integer, String, DateTime, TIMESTAMP from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker # 创建一个基类,用于定义数据库表的结构 Base = declarative_base() # 定义一个 Customer数据库表的模型 class Customer(Base): __tablename__ = "t_customer" id = Column(String, primary_key=True, comment="主键") name = Column(String, comment="姓名") age = Column(Integer, comment="年龄") creator = Column(String, comment="创建人") createtime = Column(DateTime, comment="创建时间")
CRUD的操作例子代码如下所示。
# 创建一个会话 Session = sessionmaker(bind=engine) session = Session() id = str(guid.uuid4()) # create a new customer customer = Customer( id=id, name="Alice", age=25, creator="admin", createtime=datetime.strptime("2021-01-01 12:00:00", "%Y-%m-%d %H:%M:%S"), ) # add the customer to the session session.add(customer) # commit the changes to the database session.commit() # query the customer from the session for item in session.scalars(select(Customer)): print(item.id, item.name, item.age, item.creator, item.createtime) print("\r\nquery all customers") customers = session.query(Customer).all() for customer in customers: print(customer.name, customer.age) print("\r\nquery all customers by condition:age > 20") customers = session.query(Customer).filter(Customer.age > 20).limit(30).offset(1).all() for customer in customers: print(customer.name, customer.age) print("\r\nquery customer by id") customer = session.query(Customer).filter(Customer.id == id).first() if customer: print(customer.name, customer.age) print("\r\n 复杂查询") customers = ( session.query(Customer) .filter( or_( and_(Customer.age > 20, Customer.age < 30), Customer.name.in_(["Alice", "伍华聪"]), ) ) .all() ) for customer in customers: print(customer.name, customer.age) print("\r\nselect customer by id") stmt = select(Customer).where(Customer.id == id) result = session.execute(stmt) print(result) stmt = select(Customer).where(Customer.name == "伍华聪") result = session.execute(stmt).scalar() if result: print("Customer exists in the database") print(result.id, result.name, result.age) else: print("Customer does not exist in the database") print("\r\nselect customer In") # query the customer from the session stmt = select(Customer).where(Customer.name.in_(["Alice", "伍华聪"])) for item in session.scalars(stmt): print(item.id, item.name, item.age, item.creator, item.createtime) print('\r\ndelete all customers by name = "Alice"') # delete the customer from the database delete_stmt = delete(Customer).where(Customer.name == "Alice") result = session.execute(delete_stmt) print(str(result.rowcount) + " rows deleted") session.commit() # close the session session.close()
由于篇幅限制,我们暂时介绍一些,其实就算是做后端WebAPI的处理,我们也需要了解很多不同的类库,Python类库非常丰富,而且同步、异步又有不同的类库差异,因此我们可以根据实际需要选用不同的类库来实现我们的框架目的。
如对于FastAPI的数据验证,我们一般引入 pydantic,可以对数据进行各种丰富的校验处理,类似于强类型和各种规则的校验。
class Person(BaseModel): name: str age: int @field_validator("age") def age_must_be_positive(cls, v): if v < 0: raise ValueError("Age must be a positive number") return v
如对于配置信息的处理,我们还可以引入 python-dotenv 和 pydantic_settings 来统一管理配置参数。
from pydantic_settings import BaseSettings, SettingsConfigDict class Settings(BaseSettings): model_config = SettingsConfigDict( env_file=".env", # 加载env文件 extra="ignore", # 加载env文件,如果没有在Settings中定义属性,也不抛出异常 env_file_encoding="utf-8", env_prefix="", case_sensitive=False, ) # Env Server SERVER_IP: str = "127.0.0.1" SERVER_PORT: int = 9000 # Env Database DB_NAME: str = "winframework" DB_USER: str = "root" DB_PASSWORD: str = "123456" DB_HOST: str = "localhost" DB_PORT: int = 3306 DB_URI: str = ( f"mysql+pymysql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}:{DB_PORT}/{DB_NAME}" )
.............
还有对于一些常规的文件格式,如json格式,txt格式的文件处理,以及PDF文件、Excel文件、图片操作、声音处理、二维码处理等,都有不同的类库提供辅助处理,我们可以从中择优选择即可。
Python的世界丰富多彩,让我们一起探索并应用在实践当中。
 专注于代码生成工具、.Net/Python 框架架构及软件开发,以及各种Vue.js的前端技术应用。著有Winform开发框架/混合式开发框架、微信开发框架、Bootstrap开发框架、ABP开发框架、SqlSugar开发框架、Python开发框架等框架产品。
专注于代码生成工具、.Net/Python 框架架构及软件开发,以及各种Vue.js的前端技术应用。著有Winform开发框架/混合式开发框架、微信开发框架、Bootstrap开发框架、ABP开发框架、SqlSugar开发框架、Python开发框架等框架产品。
转载请注明出处:撰写人:伍华聪 http://www.iqidi.com


 浙公网安备 33010602011771号
浙公网安备 33010602011771号