
如何使用正则表达式进行QQ校友的数据采集
QQ校友里面很多数据是按照学校进行归类的,因此,我们只要知道学校的名称,根据一些条件就可以查找您感兴趣的校友了。
QQ校友的数据查看或者查询,是需要登录才行的,QQ校友的登录,可以让用户通过输入验证码方式进行登录。博客已经有很多大牛找出很多解决方法,在此不说这块,我们这里介绍下,如何分析页面,合理使用正则表达式,获取所需要的数据。
通过抓包工具IE Http Analyzer 可以跟踪到QQ校友的资料查询URL地址类似下面的格式:
在Google浏览器上,你看到的中文地址信息是:
如果你登陆后,执行这个页面,你就可以看到的部分页面源码是如下所示(我截取了关心的那部分HTML代码):
<ul class="results_list">
<li class="request_one">
<div class="list_info">
<p class="user_info"><a href="/index.php?mod=profile&u=c265e4bd629300c500a439a57fc4b1c6d2458796fbfe9608" class="user_name xy_card">王***</a> </p> 西南交大
</div>
<ul>
<li><img src="http://imgcache.qq.com/campus_v2/ac/b.gif" alt="" class="icon_script" /><a href="javascript:is_sendscrip('c265e4bd629300c500a439a57fc4b1c6d2458796fbfe9608');">发小纸条</a></li>
<li><img src="http://imgcache.qq.com/campus_v2/ac/b.gif" alt="" class="icon_add" /><a href="javascript:void(0)" onclick="add_friends_frame('c265e4bd629300c500a439a57fc4b1c6d2458796fbfe9608')">加为好友</a></li>
</ul>
</li> <li class="request_one">
<a href="/index.php?mod=profile&u=c265e4bd629300c5202a08ff05052aadd58b7e634ad8d204" class="pic_user_m xy_card"><span class="skin_portrait_round"></span><img src="http://xy6.store.qq.com/c265e4bd629300c5202a08ff05052aadd58b7e634ad8d2040" alt="王*霞" /></a>
<div class="list_info">
<p class="user_info"><a href="/index.php?mod=profile&u=c265e4bd629300c5202a08ff05052aadd58b7e634ad8d204" class="user_name xy_card">王*霞</a> </p> 北京理工大学
</div>
其实我们需要把里面:用户编号、姓名、学校,然后我们根据用户编号就可以进一步获取该用户的信息了。
用户详细的介绍内容页面地址是:http://xiaoyou.qq.com/index.php?mod=profile&u=c265e4bd629300c500a439a57fc4b1c6d2458796fbfe9608
然后我们看到,这个页面的源码是:
<div class="fun_info_class">
<p><span class="c_tx2">生 日: </span><span>1978年12月27日</span></p>
<p><span class="c_tx2">星 座: </span><span>魔羯座</span></p>
<p><span class="c_tx2">上次登录:</span> <span>1天前(共10次)</span></p>
<div class="list_sch_wrap"><p><span class="c_tx2">就读学校:</span></p><ul class="list_sch"><li><a href="/index.php?mod=school&act=schoolportal&school_id=12229">西南交大</a></li></ul></div>
</div>
这个也页面里面有性别、生日、星座、上次登录时间等相关信息,这样基本上就构成了完整的用户信息了。
好了,大的方面我们知道了,看看具体如何把页面里面的信息提取出来。
第一步,把页面内容分离,获取感兴趣的部分,正则表达式是:<li\s+?class="request_one"\>\s*(.*?)\s*<ul\>
其中表达式\s的意思如下:
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。 |
\s+? 标识有一个到多个空白字符
(.*?) 标识非贪婪模式匹配任何字符
我们看到正则表达式工具中得到的结果是: 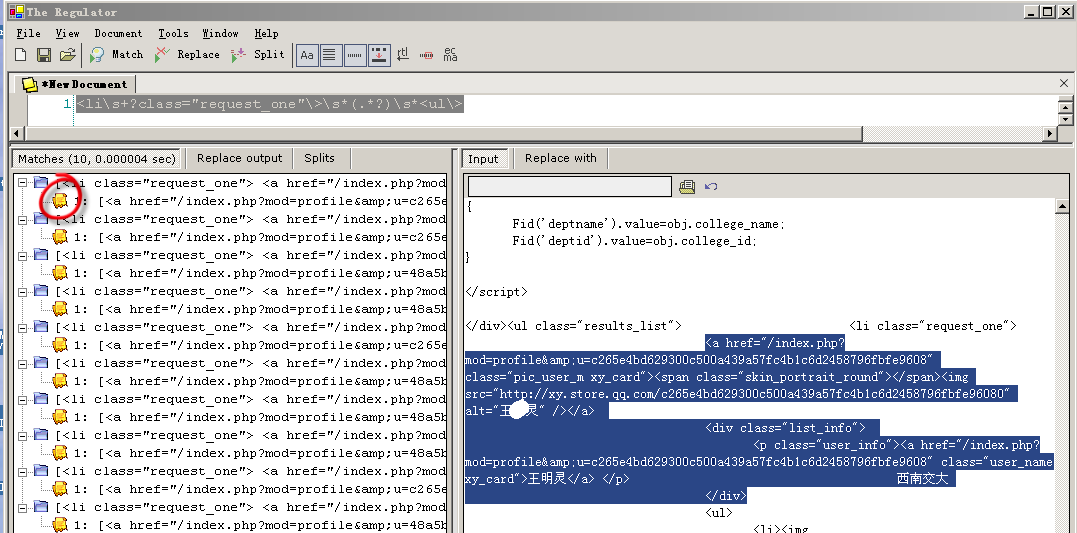
其中每项都列出来了,我们把它放到一个List集合中,然后每个项目再进行一次正则表达式的匹配,获取到具体的内容。
List<string> itemHtmlList = new List<string>();
string itemRegex = "刚才的正则表达式";//<li\s+?class="request_one"\>\s*(.*?)\s*<ul\>
Regex re = new Regex(itemRegex, RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
Match mc = re.Match(content);
if (mc.Success)
{
MatchCollection mcs = re.Matches(content);
foreach (Match me in mcs)
{
string strValue = me.Groups[1].Value;
itemHtmlList.Add(strValue);
}
}
#endregion
上图中黑色背景下面的部分,就是我们每项要解析的内容。
然后我们再使用正则表达式:<a\s+?href="(.*?)".*?src="(.*?)".*?alt="(.*?)".*?&u=(.*?)".*?</p\>\s*(.*?)\s*</div\>
就可以得到下面的效果
其中正则表达式部分字符的意思如下:
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。 |
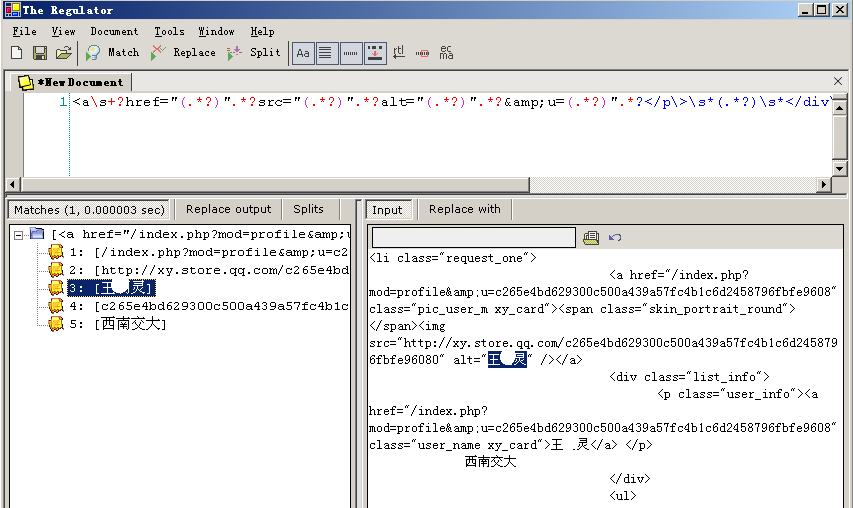
下面我们要根据用户信息页面,去获取其他的相关信息了,我们用正则表达式:<div\s+?class="fun_info_class"\>.*?</span\>\s*?<span\>(.*?)</span\>.*?</span\>\s*?<span\>(.*?)</span\>.*?</span\>\s*?<span\>(.*?)</span\>.*?</span\>\s*?<span\>(.*?)</span\>.*?</div\>
来过滤代码,就可以了。
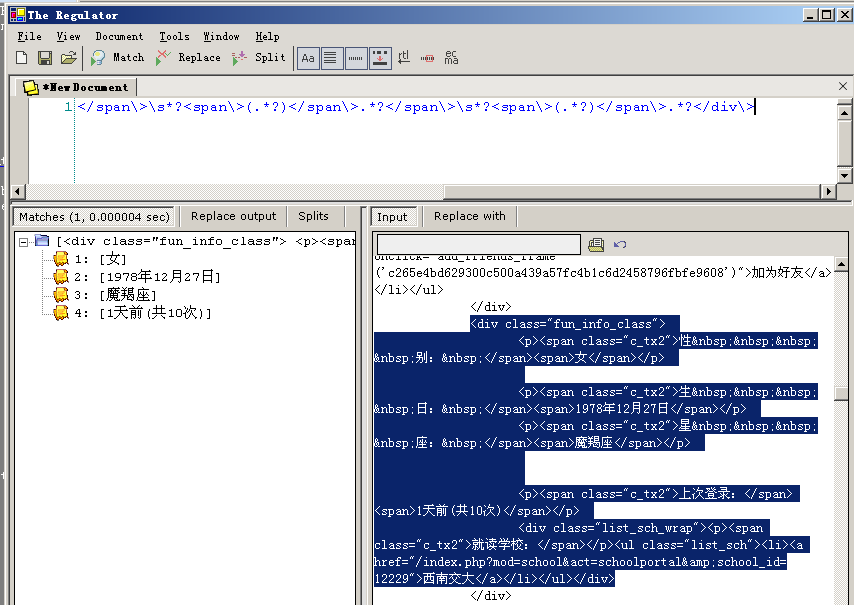
整个过程就是这样反复获取,解析,就可以实现对QQ校友数据的采集了。
不过有一点不好,就是QQ校友和用户ID不是QQ号码,并且你找不出和QQ号码有任何关联的地方,这或许就是隐私保护的举措吧。
如果阁下有好的方法,可以获取到关联关系,大家可以探讨一下。
 专注于代码生成工具、.Net/.NetCore 框架架构及软件开发,以及各种Vue.js的前端技术应用。著有Winform开发框架/混合式开发框架、微信开发框架、Bootstrap开发框架、ABP开发框架、SqlSugar开发框架等框架产品。
专注于代码生成工具、.Net/.NetCore 框架架构及软件开发,以及各种Vue.js的前端技术应用。著有Winform开发框架/混合式开发框架、微信开发框架、Bootstrap开发框架、ABP开发框架、SqlSugar开发框架等框架产品。
转载请注明出处:撰写人:伍华聪 http://www.iqidi.com


