计算机网络 网络层
ARP协议
ARP协议概述
ARP(Address Resolution Protocol)即地址解析协议 **, 用于实现从 ** IP 地址到 MAC 地址 的映射,即询问目标IP对应的MAC地址 。在以太网环境中,数据的传输所依懒的是MAC地址而非IP地址,而将已知IP地址转换为MAC地址的工作是由ARP协议来完成的。
简单来说,ARP协议 是将IP地址解析为以太网MAC地址(或称物理地址)的协议。在局域网中,当主机或其他网络设备有数据要发送给另—个主机或设备时,必须知道对方的IP地址和MAC地址。
ARP出现原因
-
在网络通信中,主机和主机通信的数据包需要依据OSI模型从上到下进行数据封装,当数据封装完整后,再向外发出。所以在局域网的通信中,不仅需要源目IP地址的封装,也需要源目MAC的封装。
-
一般情况下,上层应用程序更多关心IP地址而不关心MAC地址,所以需要通过ARP协议来获知目的主机的MAC地址,完成数据封装。
ARP工作实例
ARP地址解析协议是如何把目的地址的IP地址转化为MAC地址的?
- 首先,主机A向主机B发送消息,但它不知道主机B的MAC地址,只知道主机B的IP地址。此时,主机A会在当前局域网下以广播的形式 发送ARP请求数据报 ,表示主机A想知道主机B的MAC地址。
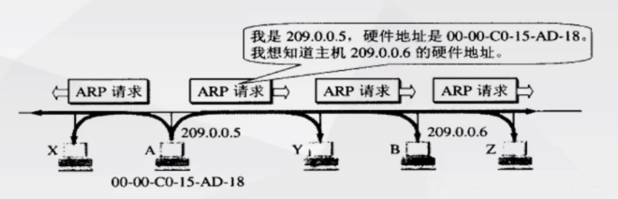
- 局域网中的毎一台主机都会接受并处理这个ARP请求报文,然后进行验证,查看接收方的IP地址是不是自己的地址,除了主机B外,在这个局域网内的其他主机都会丢弃数据报。验证成功的主机 会返回—个ARP响应报文 ,这个响应报文包含接收方的IP地址和物理地址 。这个报文以单播的方式 直接发送给ARP请求报文的请求方。
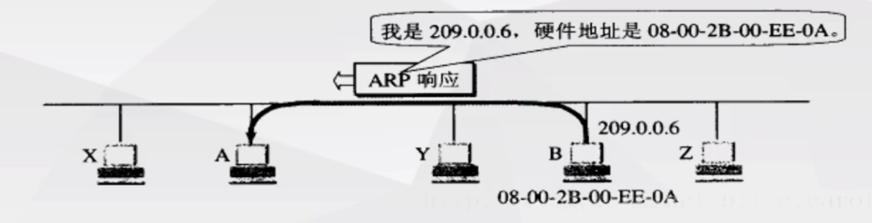
小结 : ARP协议通过"一问一答 "实现交互,但是"问"和"答"都有讲究,"问 "是通过广播 形式实现,"答 "是通过单播 形式。
ARP缓存表
-
为了实现IP地址与MAC地址的查询与转换,ARP协议引入了ARP缓存表的概念。
-
这个表包含IP地址到MAC地址的映射关系,表中记录了<P地址,MAC地址>对,称之为ARP表项。
-
当需要发送数据时,主机会根据数据报中的目标I地址信息,然后在ARP缓存表中查找对应的MAC地址,最后通过网卡将数据发送出去。
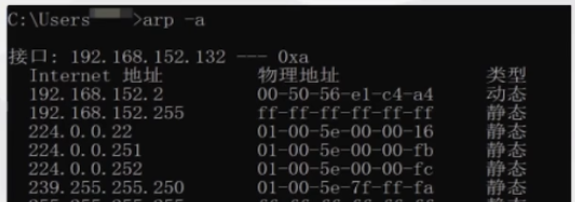
注意 :arp缓存表中每—项都被设置了生存时间,一般是20分钟,从被创建时开始计时,到时则清除。
在我们的windows/macos系统下,可以通过命令行"arp -a "查看具体信息 =>
ARP报文格式
ARP报文分为ARP请求和ARP应答报文两种,它们的报文格式可以统一为如下图

字段的说明 :
-
硬件类型 :占2字节,表示ARP报文可以在哪种类型的网络 上传输,值为1 时表示为以太网地址。
-
上层协议类型 :占2字节,表示硬件地址要映射的协议地址类型 。其中,0x0800 表示IP协议 。
-
MAC地址长度 :占1字节,标识MAC地址长度。
-
IP地址长度 :占1字节,标识IP地址长度。
-
操作类型 :占2字节,指定本次ARP报文类型。1 表示ARP请求 报文,2 表示ARP应答 报。
-
源MAC地址 :占6字节,表示发送方 设备的硬件地址。
-
源IP地址 :占4字节,表示发送方 设备的IP地址。
-
目的MAC地址 :占6字节,表示接收方 设备的硬件地址,在请求报文 中该字段值全为0 ,即00-00-00-00-00-00 表示任意地址 ,因为现在不知道这个MAC地址。
-
目的IP地址 :占4字节,表示接收方 设备的IP地址。
ARP数据包解读
为了让大家更好的理解ARP协议以及广播和单播的概念,我们来看一下用Wireshark抓取到的真实网络中的ARP过程,通过数据包的方式来呈现,地址信息如下,部分MAC信息隐去。(建议初学者用GNS3配合Wireshark来抓取协议包进行分析,相比真实网络更加干净,方便分析)
主机1 <----------> 主机2
主机1: IP1:10.1.20.64 MAC1:00:08:ca:xx:xx:xx
主机2: IP2:10.1.20.109 MAC2:44:6d:57:xx:xx:xx
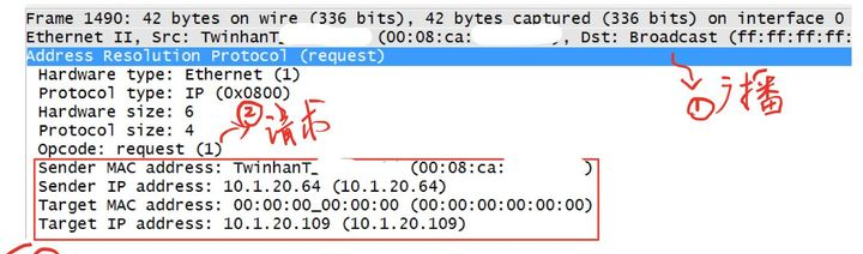
大家好,我是主机1 <IP1:10.1.20.64,MAC1:00:08:ca:xx:xx:xx>
广播 询问 主机2的MAC <IP2:10.1.20.109,你的MAC是多少?>
000000空位(留坑),表示询问者不知道,等待接收方回应(填坑)
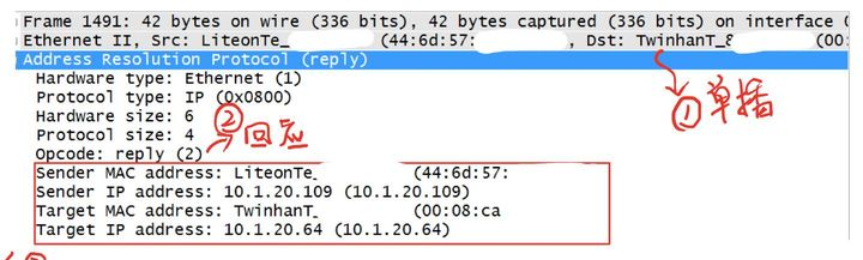
我是主机2 <IP2:10.1.20.109,MAC2:44:6d:57:xx:xx:xx>
单播 回复 你好主机1 <IP1:10.1.20.64,MAC1:00:08:ca:xx:xx:xx>
ARP数据包字段解读
| 字段名称 | 说明 |
|---|---|
| Hardware type | 硬件类型,标识链路层协议 |
| Protocol type | 协议类型,标识网络层协议 |
| Hardware size | 硬件地址大小,标识MAC地址长度,这里是6个字节(48bit) |
| Protocol size | 协议地址大小,标识IP地址长度,这里是4个字节(32bit) |
| Opcode | 操作代码,标识ARP数据包类型,1表示请求,2表示回应 |
| Sender MAC address | 发送者MAC |
| Sender IP address | 发送者IP |
| Target MAC address | 目标MAC,此处全0表示在请求 |
| Target IP address | 目标IP |
ARP欺骗
-
ARP地址解析协 议即是根据IP地址获取物理地址的TCP/IP协议。主机发送消息时会将包含目标IP地址的ARP请求发给广播地址,广播地址的MAC为ff:ff:ff:ff:ff:ff,广播在进行广播转发数据包到网段内所有主机,并接收返回的消息,以此来确定目标的物理地址。主机收到的返回的消息后将IP地址和物理地址存入本机ARP缓存中,并保留一定时间,默认是20分钟,保留一段时间是为了下次请求时直接査询ARP缓存表节约资源。ARP是建立在网络中各个主机互相信任的基础上,局域网的主机可以自主发送arp请求 ,其他主机收到应答报文时不会检测真实性就将其记入本机ARP缓存 。
-
针对这个特性有一种局域网常见的攻击手法:ARP欺骗,或者叫ARP毒化,针对这种攻击kali内的一款图形化工具可以很方便的做到 —— Ettercap, Ettercap可以用来做arp欺骗,dns欺骗,或者中间人攻击。这里先讲下ARP欺骗,刚才讲到主机在收到任何ARP应答报文不会检测其真实性就会记入本机ARP缓存表。
-
arp欺骗分为单向欺骗,双向欺骗。
-
单向欺骗 :A、B、C三个人,A与C正常通信,B想知道A给C发的内容,就伪造ARP响应包,更改A的ARP表,所以A发送给C的信息会先传送到B,B可以丢弃数据包,这样C就收不到A发的数据了,但是C还是可以正常给A发送数据的,这就是单向欺骗。
-
双向欺骗 :同样是A、B、C三个人,B同时给A、C发送响应包B告诉A它的IP是C的IP,Mac地址还是B的,告诉C它的IP是 A的IP,Mac地址还是是B的,这样A、C的通信就都会经过B,这就叫双向欺骗。
-
单向欺骗:欺骗网关;双向欺骗:欺骗网关和被攻击的机器。←
-
这类攻击可以任意截取局域网内的数据包,甚至篡改数据包 。针对此类攻击,可采用MAC地址绑定和ARP防火墙防止。
IP协议
IP协议原理
IP协议(Internet Protocol,互联网协议) ,是TCP/IP协议栈中最核心的协议之一,通过IP地址,保证了联网设备的唯一性,实现了网络通信的面向无连接和不可靠的传输功能。
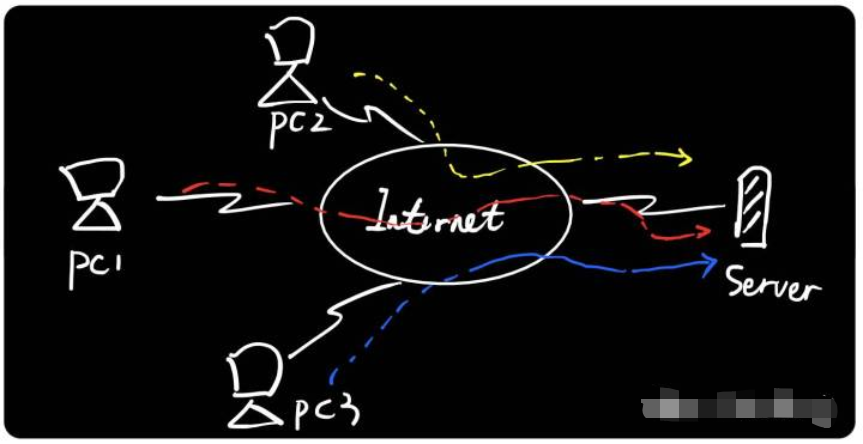
如上图所示,当多台接入互联网的电脑访问同一台服务器时,服务器如何区分不同电脑的请求,并准确的将资源返回?
只要给每个设备加上"身份证",并且在通信的时候,将"身份证"嵌入到数据包里面,则整个往返过程可以准确无误 。
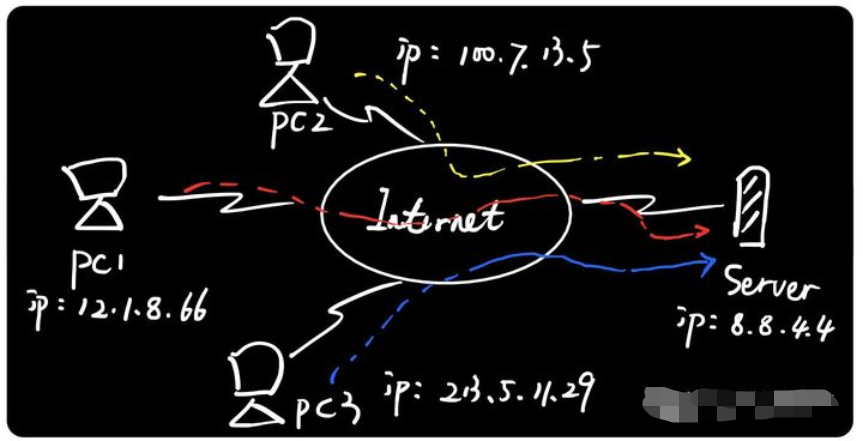
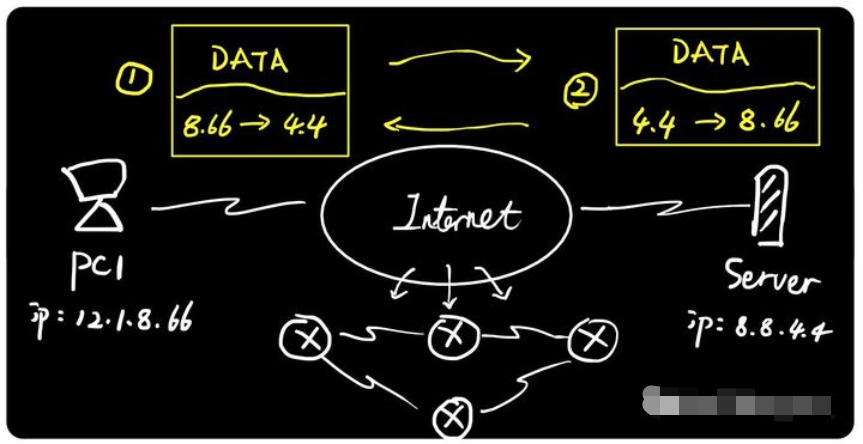
以PC1访问服务器为例,PC1的地址是12.1.8.66,Server的地址是8.8.4.4,整个通信过程是这样的:
-
PC1在请求数据包里面封装源目IP地址,并将带有IP地址的数据包 发送到互联网;
-
互联网有大量的网络通信设备(例如路由器),路由器根据数据包的IP地址查找路由表(地图) ,然后以接力棒的方式逐跳转发直到目标服务器;
-
服务器收到请求数据后,将源目IP地址翻转 ,并封装回应数据包发送到互联网。
上述这个IP通信过程,跟我们日常快递收寄件 的流程是几乎类似的:
-
寄快递的时候,需要先写快递单,快递单要求写入寄件方和收件方的姓名和联系信息 (电话号码、地址),写完之后,再将快递单贴在包裹上面 。
-
物流公司(或快递员)根据包裹的寄件地址,通过物流平台(飞机、长途货车、卡车)将包裹在省市中传输 ,直到收件方的城市。
-
收快递的时候,快递员根据包裹收件地址,找到对应的街道或小区,然后通过电话联系 并交付到我们手里。
在这里,快递单相当于IP地址、快递包裹相当于数据包,物流公司/快递员相当于路由器/交换机 。
经过上面这个案例,我们需要更明确这些知识点:
-
IP协议提供了IP地址,并将源目IP地址夹带在通信数据包里面,为路由器指明通信方向;
-
IP协议只能指明数据包的源目通信方即"这是谁的送给谁的",但不能保证数据包一定能到达对方,数据是否会被丢弃以及丢弃之后如何处理 。所以,上面才有这句:"IP协议提供面向无连接不可靠传输功能 "。那么,如果出现丢包且需要重传时,谁来解决呢?这就需要TCP/IP协议栈另外一个"半壁江山"来实现,大家肯定猜到了:TCP协议能解决以上这些IP协议不能实现的功能。
当然,IP协议不仅仅只有"快递单"功能,它还能防止数据包环路、为数据打上重要或不重要等标签实现流量控制、能验证数据包是否损坏、能实现数据包分片和组装功能 ;而要深入学习这些功能,必须掌握IP头部的封装格式。
IP协议结构
-
在TCP/IP协议中,使用IP协议传输数据的包被称为IP数据包,毎个数据包都包含IP协议规定的内容。
-
IP协议规定的这些内容被称为IP数据报文( IP Datagram)或者IP数据报。
-
IP数据报文由首部和数据两部分组成。首部的前一部分是固定长度,共20字节,是所有I数据报必须具有的。
-
在首部的固定部分的后面是一些可选字段,其长度是可变的。
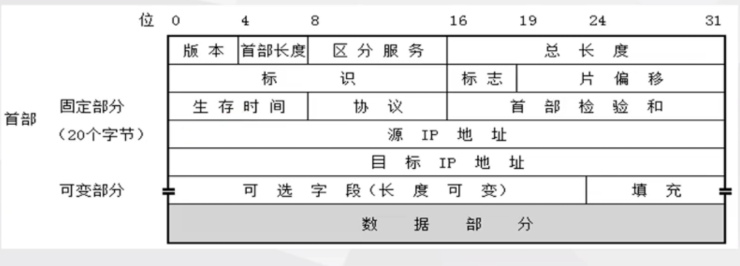
字段的说明 :
-
版本 :占4位 ,表示IP协议的版本,通信双方使用的IP协议版本必须一致 ,目前广泛使用的IP协议版本号为4,即IPV4。
-
首部长度 :占4位 ,指出数据报首部长度 。
-
区分服务 :占8位 ,在区分服务时这个字段才会起作用,实际上没有用过 。
-
总长度 :占16位 ,首部和数据之和 ,单位为字节。总长度字段为16位,因此数据报的最大长度为2^16-1=65535字节,但是受数据链路层协议的影响总长度不能超过最大传送单位MTU为1500字节 。
-
标识 :占16位 ,用来标识数据报每产生—个数据报,其值就加1。当数据报的长度超过网络的MTU,必须分片 时,这个标识字段的值就被复制到所有的数据报 的标识字段中。具有相同的标识字段值的分片报文会被重组成原来的数据报 。
-
标志 :占3位 ,目前只有后两位有意义。表示该IP数据报是否允许分片和是否是最后的一片。最低一位记为MF,如果MF=1 ,表示后面还有分段 ;如果MF=0 表示这已经是某个数据报的最后一个分段 。中间一位记为DF,当DF=1 时,表示不允许分段,DF=0 表示允许分段 。
-
片偏移 :占13位 ,标记该分片在原报文中的相对位置。以8个字节为偏移单位 ,除了最后一个分片,其他分片的偏移值都是8字节的整数倍。
-
生存时间(TTL) :占8位 ,表示数据报在网络中的寿命。每经过一个路由器,则TTL减1,当TTL值为0时,就丢弃这个数据报。设置TTL是为了防止数据报在网络中无限制地循环转发 。
-
协议 :占8位 ,标识此IP数据报在传输层所采用的协议类型。区分IP协议的上层协议。ICMP为1、TCP为6、UDP为17。
-
首部校验和:占16位 ,检验IP数据报的报头部分,保证首部数据的完整性。数据报毎经过一个路由器,路由器都要重新计算一下报头检验和,不检验数据部分可减少计算的工作量。
-
源地址 :占32位 ,表示数据报的源IP地址。数据报发送者 的IP地址。
-
目的地址 :占32位 ,表示数据报的目的IP地址。数据报接收者 的IP地址,用于校验发送是否正确
-
选项 :可变长的可选信息,最多包含40字节。支持各种选项,提供扩展余地,用来支持排错、测量以及安全措施。
IP数据报包解读
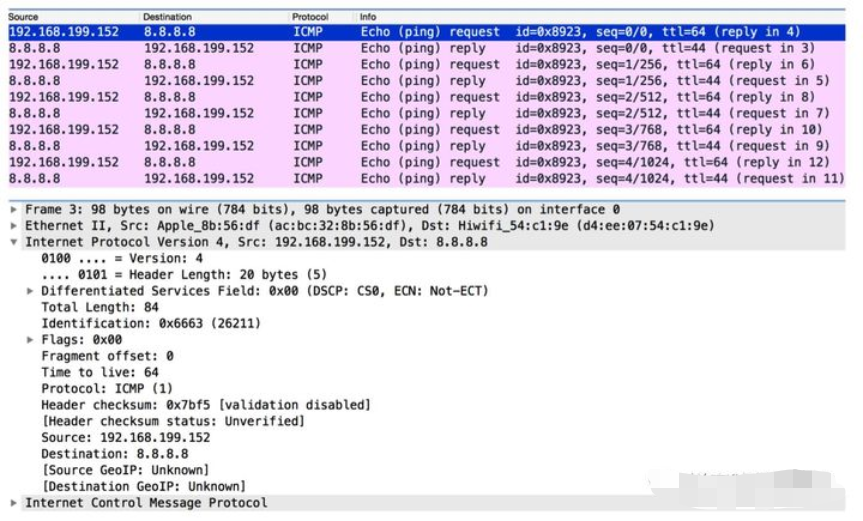
【IP协议字段解读】
| 字段名称 | 说明 |
|---|---|
| Version(版本号) | 标识IP协议的版本,目前V4版本地址已经枯竭,V6慢慢成为主流 |
| Header Length(头部长度) | 默认为20字节,最大为60字节 |
| Differentiated Services Field (服务区分符) | 用于为不同的IP数据包定义不同的服务质量,一般应用在QOS技术中 |
| Total Length (总长度) | 标识IP头部加上上层数据的数据包大小,IP包总长度最大为65535个字节 |
| Identification (标识符) | 用来实现IP分片的重组,标识分片属于哪个进程,不同进程通过不同ID区分 |
| Flags(标志符) | 用来确认是否还有IP分片或是否能执行分片 |
| Fragment offset (分片偏移量) | 用于标识IP分片的位置,实现IP分片的重组 |
| Time to live (生存时间) | 标识IP数据包还能生存多久,根据操作系统不同,TTL默认值不同,每经过一个三层设备如路由器的处理,则TTL减去1,当TTL=0时,则此数据包被丢弃 |
| Protocol (协议号) | 标识IP协议上层应用。当上层协议为ICMP时,协议号为1,TCP协议号为6,UDP的协议号为17 |
| Header checksum (头部校验) | 用于检验IP数据包是否完整或被修改,若校验失败则丢弃数据包 |
| Source(源IP地址) | 标识发送者IP地址,占用32bit |
| Destination (目的IP地址) | 标识接收者IP地址,占用32bit |
我们可以看到IP头部默认有12个字段,为了方便记忆,可以总结为7个核心知识点:
-
Source和Destination即IP源目地址字段,是IP协议最核心的字段;
-
Id+Flags+FO三个字段可以实现IP数据分片和重组;
-
Total Length和Header Length标记IP头部和上层数据的边界;
-
TTL生存时间字段可以实现通信防环;
-
DSCP服务区分符可以实现流量控制;
-
Checksum字段可以数据包完整性校验;
-
Protocol字段标记上层应用;
IP数据包字段解读
length长度字段
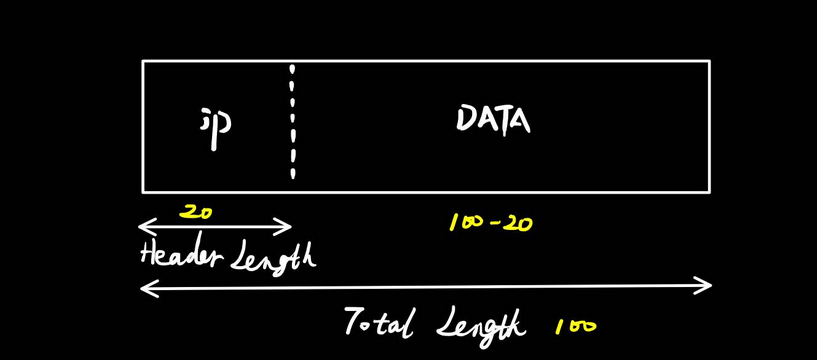
长度字段在大部分协议里面都会出现,例如IP、TCP、UDP协议,功能都是为了"划分界限":哪里是头部,哪里是数据。
如上图所示,通过Header Length我们知道IP协议的头部是20字节(默认是20字节,最长可以是60个字节),Total Length这里标明是100个字节,所以剩下的数据部分则是80字节。
划清了头部和数据的界限之后,又有什么用呢?
当收到数据包之后,无论是电脑/手机还是其他联网设备,网卡模块会对数据包进行拆分、修改IP头部信息、重新进行数据封装等操作,如果没有"这条线",那就可能会"越界",一旦"越界",则数据包内容可能损坏 。
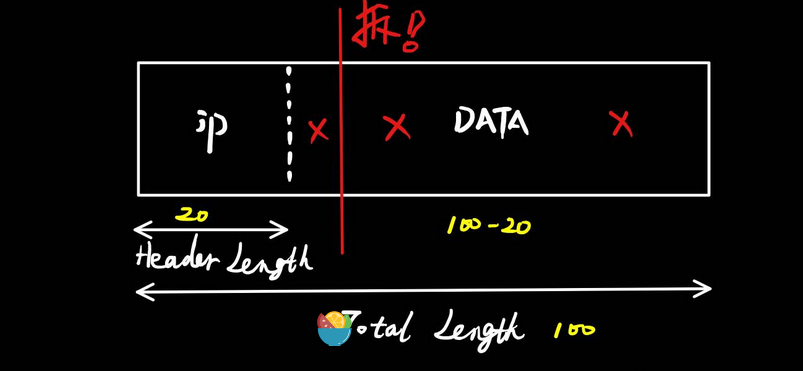
当没有长度字段或长度字段标识错误时,网卡在进行拆分的时候,错误的把数据部分划分到头部里面,这样的话,右边的数据部分就不完整,接收方最终收到的就是一个损坏的数据包。
好比大家用浏览器下载一个word文档,如果这个文档本来有80字节大小,现在word只能打开后面的60字节,那肯定是无法打开的。
FO片偏移字段解
例:一数据报的总长度为3820字节,其数据部分为3800字节长(使用固定首部),需要分片为长度不超过1420字节的数据报片。
因固定首部长度为20字节 ,因此每数据报片的数据部分长度不能超过1400字节 。于是分为3 个数据报片,其数据部分的长分别为1400,1400和1000字节 。原始数据报首部被复制为各数据报片的首部,但必须修有关字段的值。图414给出分片后得出的结果(请注意片偏移的数值)。

首先明确 偏移量以8个字节为偏移单位。
字节0~1399是第一个1400字节,该片首字节是字节0,0/8=0,故偏移量为0;
字节1400~2799是第二个1400字节,该片首字节是字节1400,1400/8=175,故偏移量为175;
字节2800~3799是最后的1000字节,该片首字节是字节2800,2800/8=350,故偏移量为350;
TTL生存时间字段
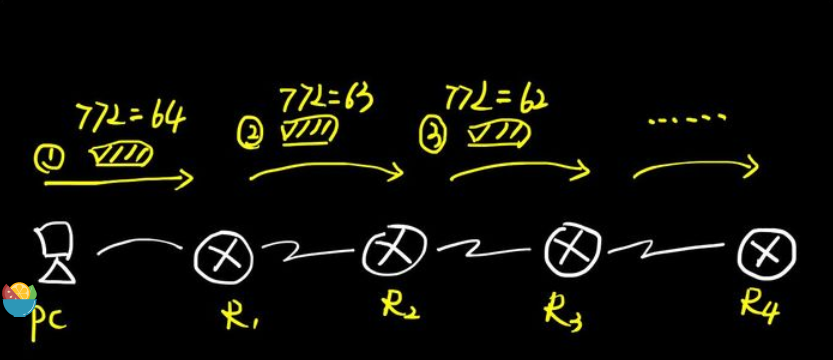
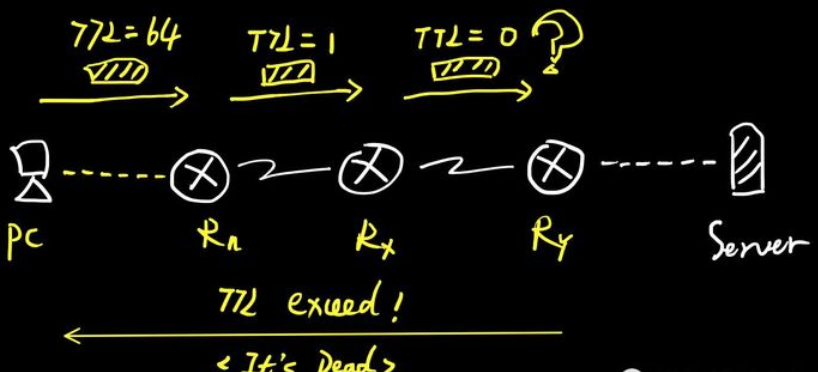
TTL(Time to live)即生存时间,用于标识IP数据包"还能存活多久",这个生存值在发送方发送数据时便设置好了。不同电脑/操作系统的初始TTL是不同的,例如上图,便是我的Mac电脑发出的,默认值是64,其他一些系统是128或255。由于TTL值占用8个bit位,所以最大值是255(二进制11111111)。
IP数据包每经过一个路由器或三层设备,TTL便会被减去1,而当TTL=0的时候,则代表此数据包"死亡",此时路由器便会向源发送者返回一个"TTL Exceed"的ICMP报错包 。
上图中,如果我的电脑到目标服务器超过了64跳,则这个数据包会中途被丢弃,无法到达目标地。
Checksum字段
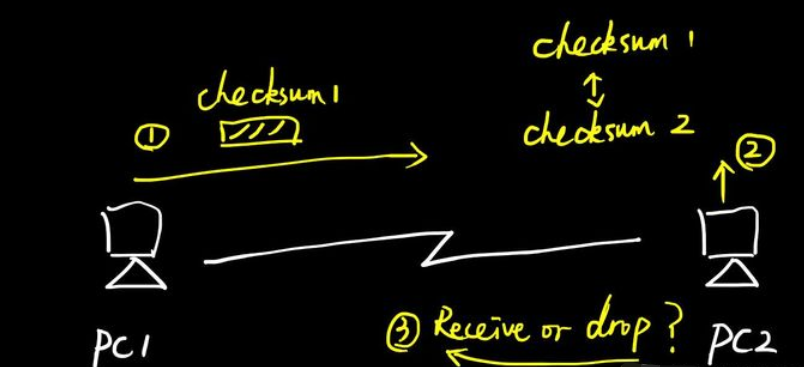
checksum校验字段跟长度字段类似,存在于很多协议里面,用于实现数据完整性校验。
不同协议采用的方法有差异,例如IP协议的checksum值只校验IP头部,不包括数据部分,而TCP和UDP的校验则包括数据部分。
上图中,PC1发送IP数据包(含checksum1)给PC2,PC2拆开IP头部,然后进行校验计算(checksum2),若校验没问题则接收并处理,若检验有问题则丢弃 。注意,这里采用的是校验算法,不是简单的相同对比。
Protocol字段
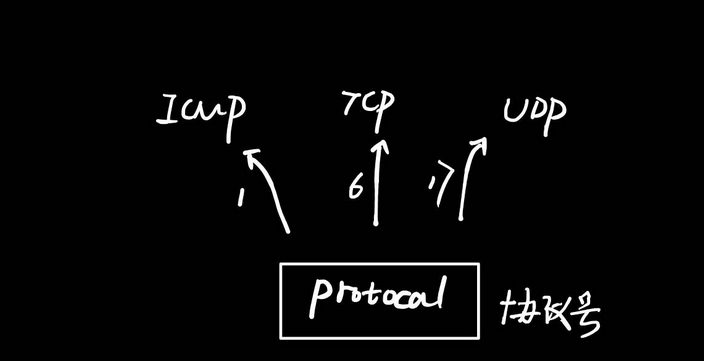
无论是IT协议的Protocol字段,还是Ethernet以太网协议里面的Type字段,又或者是TCP/UDP协议里面的Port字段,这些字段的功能都是用于标识上层协议或应用 。例如,ICMP协议号为1,TCP协议号为6,UDP的协议号为17 。
对于很多初学者来而,虽然知道了哪些协议号对应哪些上层应用,毕竟只要背熟了就好,但是我们还需要更深入的思考?例如,在IP协议里面加入协议号标识传输层协议,意义何在?'
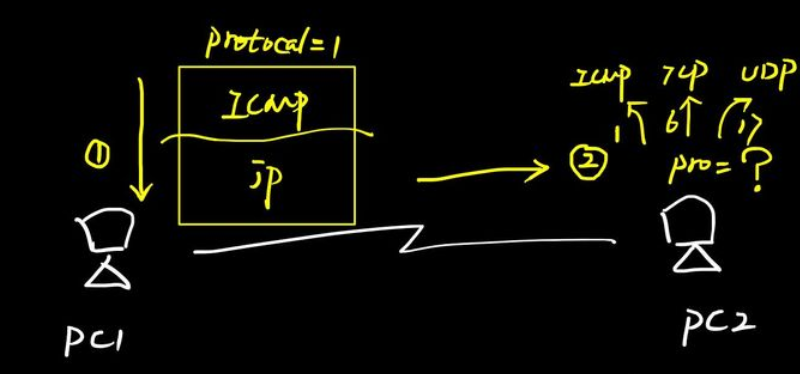
通过上面这张图我们可以看到,若PC1 PING PC2,则此时会采用ICMP协议,而ICMP协议对应的协议号是1。当PC2收到这个数据包时,拆开IP头部,则会看到协议号,根据协议号调用对应的上层协议或应用来进行上层数据处理。
以这里例子来看,若PC2采用TCP或UDP来解开ICMP数据包,则无法正常解析,好比用word程序要打开一部mp4电影,肯定会有故障 。而如果这里PC2根据协议号为1,调用ICMP协议来处理ICMP数据包,则可以正常解读并返回回应包。
所以,协议号(Protocol)、端口号(Port)、类型值(Type)这些的功能都是:标记上层协议/应用,告诉接收方,有正确的协议/应用来打开这个数据,功能相当于电脑文件的后缀名,告诉电脑用哪些应用程序来打开对应的文件。
参考博文:
https://zhuanlan.zhihu.com/p/29287795
ICMP协议
ICMP协议介绍
ICMP(Internet Control Message Protocol)Internet控制报文协议 。它是TCP/IP协议簇的一个子协议,用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。这些控制消息虽然并不传输用户数据,但是对于用户数据的传递起着重要的作用。
ICMP出现的原因
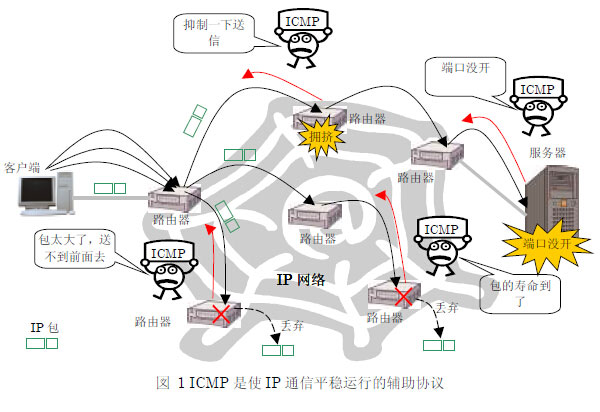
在IP通信中,经常有数据包到达不了对方的情况。原因是,在通信途中的某处的一个路由器由于不能处理所有的数据包,就将数据包一个一个丢弃了。或者,虽然到达了对方,但是由于搞错了端口号,服务器软件可能不能接受它。这时,在错误发生的现场,为了联络而飞过来的信鸽就是ICMP 报文。在IP 网络上,由于数据包被丢弃等原因,为了控制将必要的信息传递给发信方。ICMP 协议是为了辅助IP 协议,交换各种各样的控制信息而被制造出来的。
制定万维网规格的IETF 在1981 年将RFC7922作为ICMP 的基本规格整理出来了。那个RFC792 的开头部分里写着“ICMP 是IP 的不可缺少的部分,所有的IP 软件必须实现ICMP协议。也是,ICMP 是为了分担IP 一部分功能而被制定出来的。
ICMP的用途
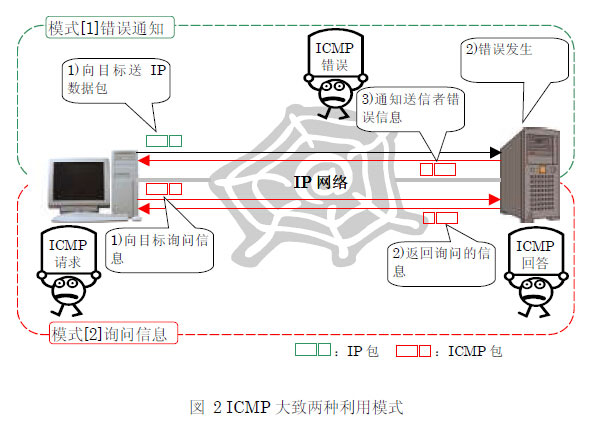
在RFC,将ICMP 大致分成两种功能:差错通知 和信息查询 。
-
给送信者的错误通知 :在IP 数据包被对方的计算机处理的过程中,发生了什么错误时被使用。不仅传送发生了错误这个事实,也传送错误原因等消息。
-
送信者的信息查询 :在送信方的计算机向对方计算机询问信息时被使用。被询问内容的种类非常丰富,他们有目标IP 地址的机器是否存在这种基本确认,调查自己网络的子网掩码,取得对方机器的时间信息等。
ICMP报头格式
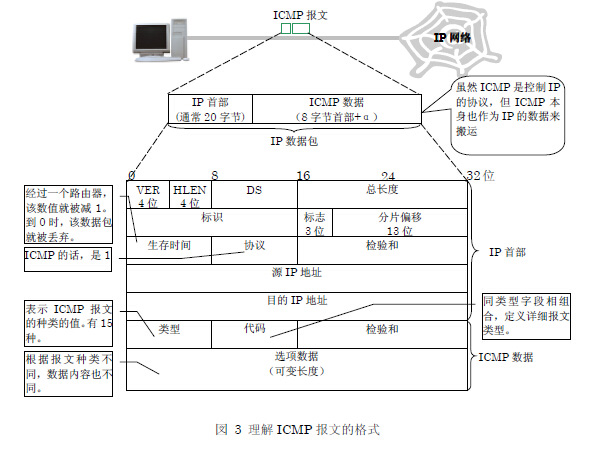
ICMP 的内容是放在IP 数据包的数据部分里来互相交流的。也就是,从ICMP的报文格式来说,ICMP 是IP 的上层协议。但是,正如RFC 所记载的,ICMP 是分担了IP 的一部分功能。所以,被认为是与IP 同层的协议。看一下RFC 规定的数据包格式和报文内容吧。
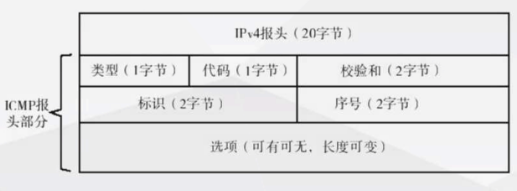
-
类型字段顾名思义是定义了ICMP报文的类型
-
代码字段表示的是发送这个ICMP报文的原因
-
校验和字段
-
标识:占2字节,用于标识本ICMP进程仅适用于回显请求和应答ICMP报文,对于目标不可达ICMP报文和超时ICMP报文等,该字段值全为0
-
首部的其余部分对于不同的ICMP是不同的
-
数据部分对于差错报告报文是用于找出引起差错的原始分组的信息, 对于查询报文是基于查询类型的额外的信息
可能的消息列表:

常见的ICMP报文
- 响应请求
常用的ping操作中就包括响应请求 (类型是8 ,代码是0)和应答 (类型是0 ,代码是0)ICMP报文
- 目标不可到达、源抑制和超时报文
这三种报文格式一样
-
目标不可到达报文 (类型值为3 )在路由器或者主机不能传递数据时使用。
-
源抑制报文 (类型字段值为4 ,代码字段值为0)则充当一个控制流量的角色,通知主机减少数据报流量。由于ICMP没有回复传输的报文,所以只要停止该报文,主机就逐渐恢复传输速率。
-
超时报文 (类型字段值为11 )的代码有两种取值:代码字段值为0表示传输超时,代码字段值为1表示重组分段超时。
- 时间戳请求
时间戳请求报文 (类型值字段13)和时间戳应答报文(类型值字段14)用于测试两台主机之间数据报来回一次的传输时间。
ICMP数据包解读

分析 :ping 操作的请求报文类型值是 8 ,代码值为0
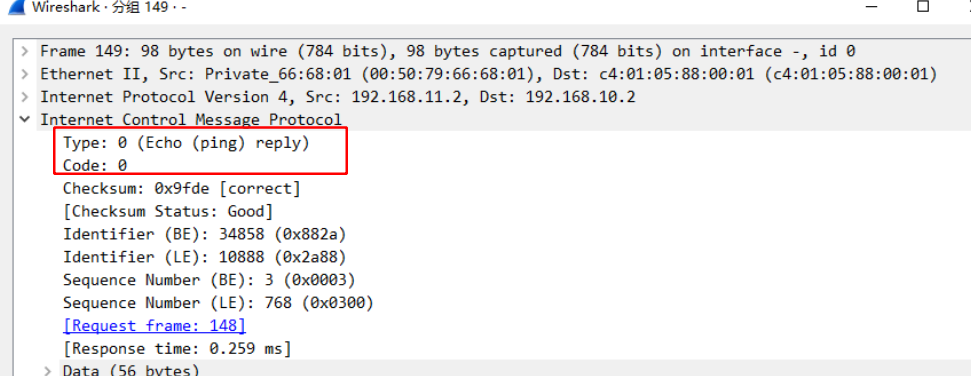
分析 :ping 操作的响应报文类型值是 0 ,代码值为0

分析 :设置 TTL =1 ,经过一个路由器时,TTL = 1-1 =0,超时丢弃, ICMP报文,类型值为11 ,代码值为0
Wireshark抓包对ping报文的解码显示(BE与LE)
我们非常熟悉ping报文的封装结构,但是,在这个报文解码里,我们发现wireshark的解码多了几个参数:Identifier(BE)、Identifier(LE)、Sequence number(BE)、Sequence number(LE),如下图所示:
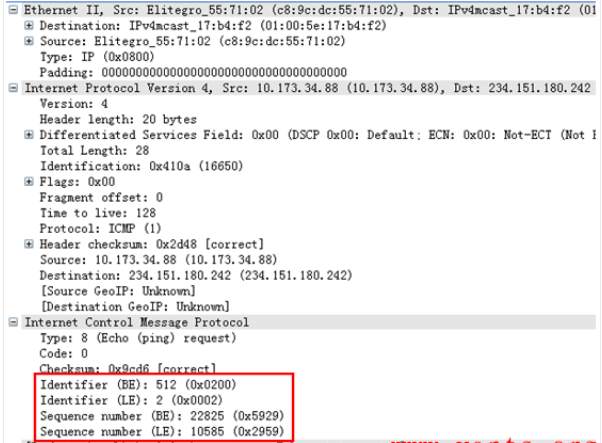
以前一直未注意wireshark是这样解码ping报文的,感觉非常奇怪,我们先来仔细的看一下wireshark对ping报文中这几个参数的解码情况:
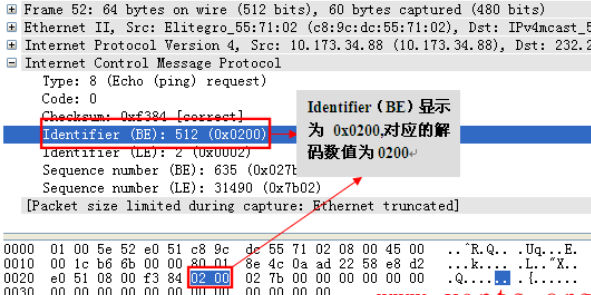
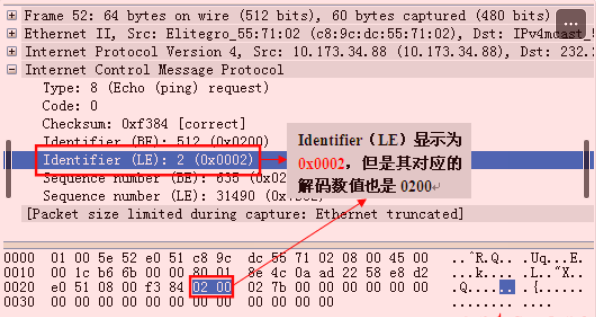
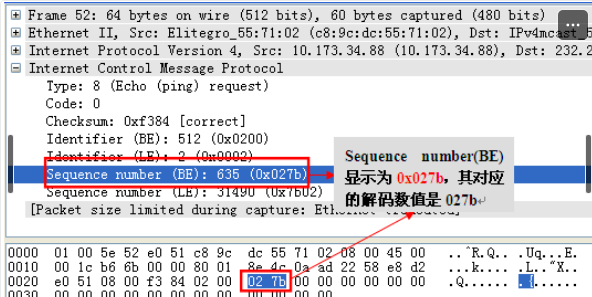
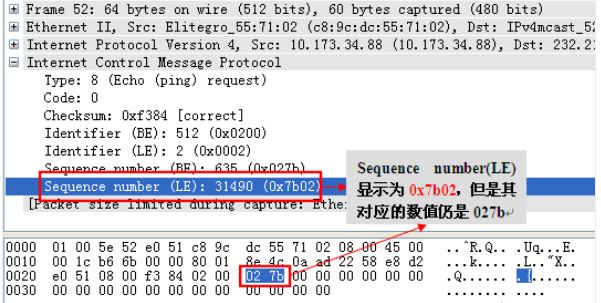
Wireshark解码显示,Identifier(BE)与Identifier(LE)都对应“hex 0200”,Sequence number(BE)与Sequence number(LE)都对应“hex 027b”,仔细看的话,我们能够发现BE值(0x0200)与LE值(0x0002)之间的差别就是顺序不一样。那到底BE、LE是指什么呢?搜遍百度无果,决定还是去wireshark官网看看,结果发现下面链接的内容:http://www.wireshark.org/lists/wireshark-bugs/200909/msg00439.html,其中有一段是这样描述的:
“After I discovered that the Windows ping sends ICMP echo request packets with the sequence number in little-endian byte order, but the Linux ping sends it in proper big-endian format, a discussion about it took place on the mailing list as to how to handle it (refer to http://www.wireshark.org/lists/wireshark-dev/200909/msg00216.html ). However,to keep things simple and avoid adding any new ICMP preferences and/or trying to guess at the byte order, I thought why not just display the sequence number in both formats, so that‘s what this patch does.”
我来做个总结:wireshark考虑到window系统与Linux系统发出的ping报文(主要指ping应用字段而非包含IP头的ping包)的字节顺序不一样(windows 为LE:little-endian byte order ,Linux 为BE :big-endian ),为了体现wireshark的易用性,开发者将其分别显示出来。
参考博文:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号