Uber发布史上最简单的深度学习框架Ludwig!

Ludwig是一个建立在TensorFlow之上的工具箱,它允许用户在不需要编写代码的情况下训练和测试深度学习模型!
简单到什么程度?令人发指!
用户只需要提供一个包含数据的CSV文件,一个列表作为输入,一个列表作为输出,Ludwig就将为你完成其余的工作:训练、测试、可视化、分布式训练等等。
安装Ludwig就这样简单:

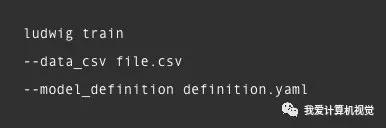
训练模型就一行命令:
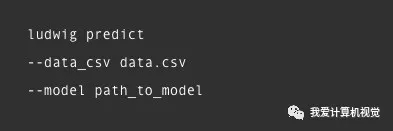
模型预测也就一个命令:
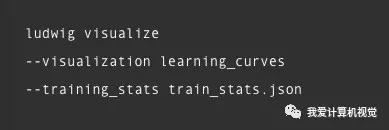
可视化也只需一行:
当然,对于熟悉Python的用户,Ludwig也提供了非常简单易用的API:

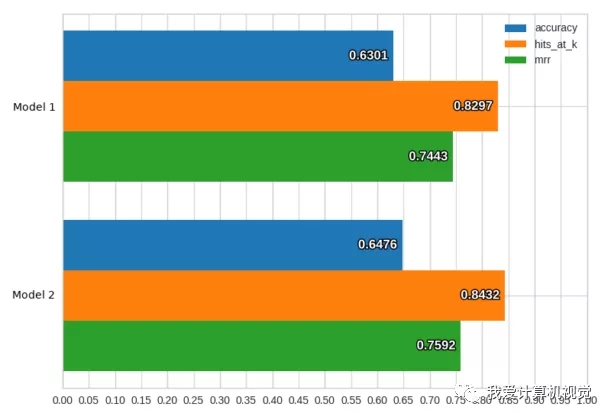
可视化工具允许你分析模型的训练和测试性能,并对它们进行比较。

Ludwig在构建时考虑了可扩展性原则,很容易添加对新数据类型和新模型体系结构的支持。
工程人员可以使用它快速训练和测试深度学习模型,研究人员也可以使用它来获得强有力的基线版本,并方便进行对比,并通过执行标准数据预处理和可视化来确保模型可比性。
打个比方!TensorFlow提供了建筑房屋的积木,Ludwig提供的则是一栋栋的房子,你来决定建造怎样的城市!!
该工具箱的核心设计原则是:
无需编码:不需要编码技能来训练模型也不需要编码用它进行预测。
通用性:一种新的基于数据类型的深度学习模型设计方法,使该工具可以跨许多不同的应用领域使用。这点无比强大!
灵活性:经验丰富的用户对模型构建和训练可进行有效的控制,而新手会容易上手。
可扩展性:易于添加新的模型体系结构和新的特征数据类型。
可理解性:深度学习模型内部通常被认为是黑匣子,但是该库提供标准的可视化来理解它们的性能并比较它们的预测。
开源: Apache许可证2.0
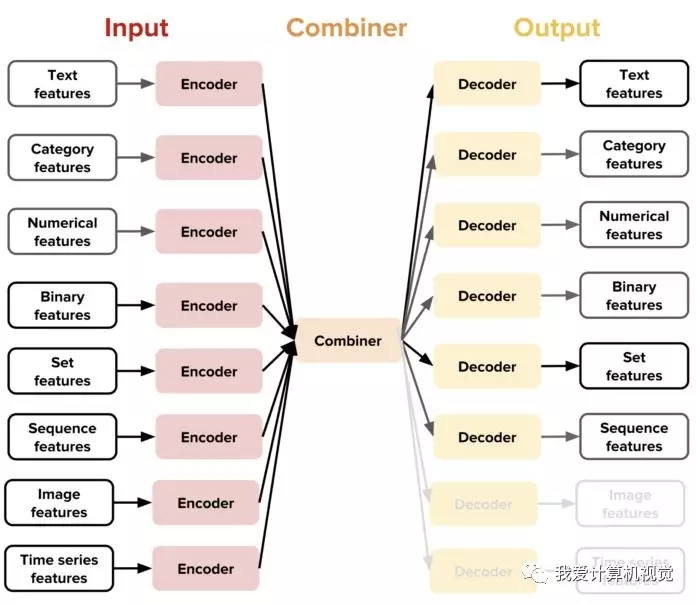
使用该库的简单独到之处在于,你只需要关注于数据CVS文件和配置文件YAML!
Ludwig提供了不少计算机视觉、自然语言处理、机器学习热门应用的例子,让我们一起来领略使用一行命令我们能做什么吧!下面图中表格即为CVS数据文件示例,表格下为调用例子实验的命令。
图像分类:

视觉问答:

孪生网络One-shot学习:

图像描述:

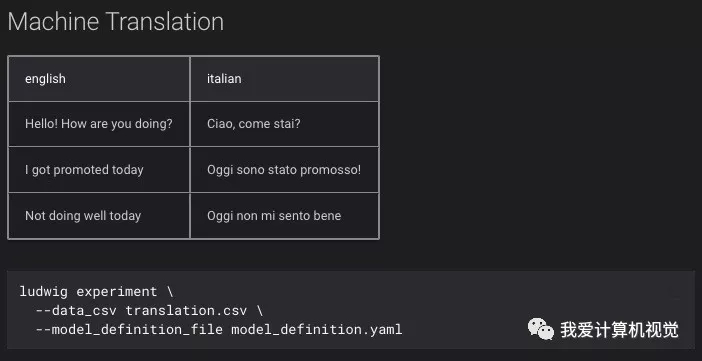
机器翻译:
自然语言理解:

命名实体识别:

文本分类:

多任务学习:

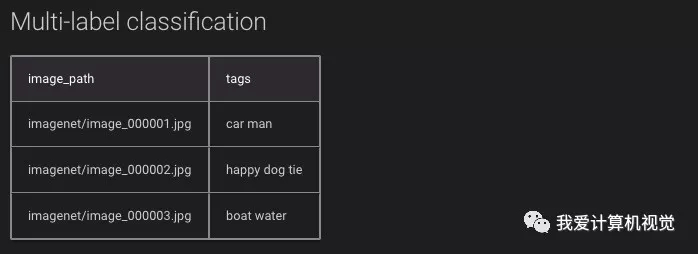
多标签分类:
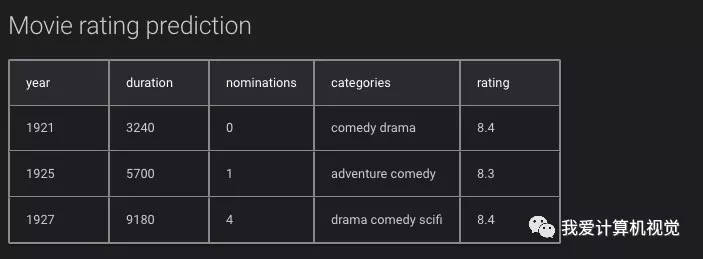
电影评分预测(机器学习回归预测):
时间序列预测:

Kaggle泰坦尼克入门:幸存者预测

语义分析:

对话机器人:

无需编程、一行命令使用深度学习解决实际问题!关键是还在Uber的生产环境经过工程验证!这样的好工具,你想不想试一下呢?
开源地址:
https://github.com/uber/ludwig
文档及示例:
https://uber.github.io/ludwig/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号