

学习k8s(三)
一、Kubernetes核心概念
1、Kubernetes介绍
Kubernetes(k8s)是自动化容器操作的开源平台,这些操作包括部署,调度和节点集群间扩展。如果你曾经用过Docker容器技术部署容器,那么可以将Docker看成Kubernetes内部使用的低级别组件。Kubernetes不仅仅支持Docker,还支持Rocket,这是另一种容器技术。 使用Kubernetes可以: 自动化容器的部署和复制 随时扩展或收缩容器规模 将容器组织成组,并且提供容器间的负载均衡 很容易地升级应用程序容器的新版本 提供容器弹性,如果容器失效就替换它,等等... 实际上,使用Kubernetes只需一个部署文件,使用一条命令就可以部署多层容器(前端,后台等)的完整集群: $ kubectl create -f single-config-file.yaml kubectl是和Kubernetes API交互的命令行程序。现在介绍一些核心概念。
2、集群
集群是一组节点,这些节点可以是物理服务器或者虚拟机,之上安装了Kubernetes平台。下图展示这样的集群。注意该图为了强调核心概念有所简化。这里可以看到一个典型的Kubernetes架构图。
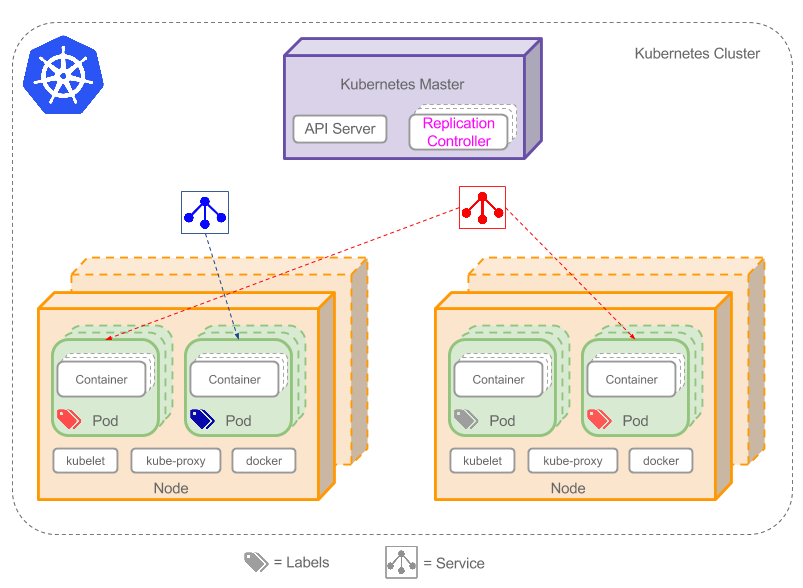
上图可以看到如下组件,使用特别的图标表示Service和Label:
- Pod
- Container(容器)
- Label(
 )(标签)
)(标签) - Replication Controller(复制控制器)
- Service(
 )(服务)
)(服务) - Node(节点)
- Kubernetes Master(Kubernetes主节点)
3、Pod
Pod(上图绿色方框)安排在节点上,包含一组容器和卷。同一个Pod里的容器共享同一个网络命名空间,可以使用localhost互相通信。Pod是短暂的,不是持续性实体。你可能会有这些问题:
如果Pod是短暂的,那么我怎么才能持久化容器数据使其能够跨重启而存在呢? 是的,Kubernetes支持卷的概念,因此可以使用持久化的卷类型。
是否手动创建Pod,如果想要创建同一个容器的多份拷贝,需要一个个分别创建出来么?可以手动创建单个Pod,但是也可以使用Replication Controller使用Pod模板创建出多份拷贝,下文会详细介绍。
如果Pod是短暂的,那么重启时IP地址可能会改变,那么怎么才能从前端容器正确可靠地指向后台容器呢?这时可以使用Service,下文会详细介绍。
4、Lable
正如图所示,一些Pod有Label()。一个Label是attach到Pod的一对键/值对,用来传递用户定义的属性。比如,你可能创建了一个"tier"和“app”标签,通过Label(tier=frontend, app=myapp)来标记前端Pod容器,使用Label(tier=backend, app=myapp)标记后台Pod。然后可以使用Selectors选择带有特定Label的Pod,并且将Service或者Replication Controller应用到上面。
5、Replication Controller
是否手动创建Pod,如果想要创建同一个容器的多份拷贝,需要一个个分别创建出来么,能否将Pods划到逻辑组里?
Replication Controller确保任意时间都有指定数量的Pod“副本”在运行。如果为某个Pod创建了Replication Controller并且指定3个副本,它会创建3个Pod,并且持续监控它们。如果某个Pod不响应,那么Replication Controller会替换它,保持总数为3.如下面的动画所示:
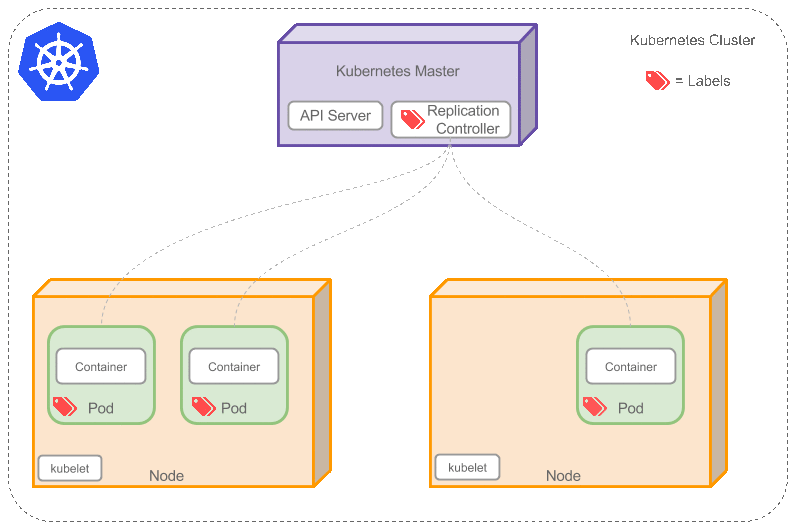
如果之前不响应的Pod恢复了,现在就有4个Pod了,那么Replication Controller会将其中一个终止保持总数为3。如果在运行中将副本总数改为5,Replication Controller会立刻启动2个新Pod,保证总数为5。还可以按照这样的方式缩小Pod,这个特性在执行滚动升级时很有用。
当创建Replication Controller时,需要指定两个东西:
Pod模板:用来创建Pod副本的模板
Label:Replication Controller需要监控的Pod的标签。
现在已经创建了Pod的一些副本,那么在这些副本上如何均衡负载呢?我们需要的是Service。
6、Service
如果Pods是短暂的,那么重启时IP地址可能会改变,怎么才能从前端容器正确可靠地指向后台容器呢? Service是定义一系列Pod以及访问这些Pod的策略的一层抽象。Service通过Label找到Pod组。因为Service是抽象的,所以在图表里通常看不到它们的存在,这也就让这一概念更难以理解。 现在,假定有2个后台Pod,并且定义后台Service的名称为‘backend-service’,lable选择器为(tier=backend, app=myapp)。backend-service 的Service会完成如下两件重要的事情: 会为Service创建一个本地集群的DNS入口,因此前端Pod只需要DNS查找主机名为 ‘backend-service’,就能够解析出前端应用程序可用的IP地址。 现在前端已经得到了后台服务的IP地址,但是它应该访问2个后台Pod的哪一个呢?Service在这2个后台Pod之间提供透明的负载均衡,会将请求分发给其中的任意一个(如下面的动画所示)。通过每个Node上运行的代理(kube-proxy)完成。这里有更多技术细节。 下述动画展示了Service的功能。注意该图作了很多简化。如果不进入网络配置,那么达到透明的负载均衡目标所涉及的底层网络和路由相对先进。如果有兴趣,这里有更深入的介绍。
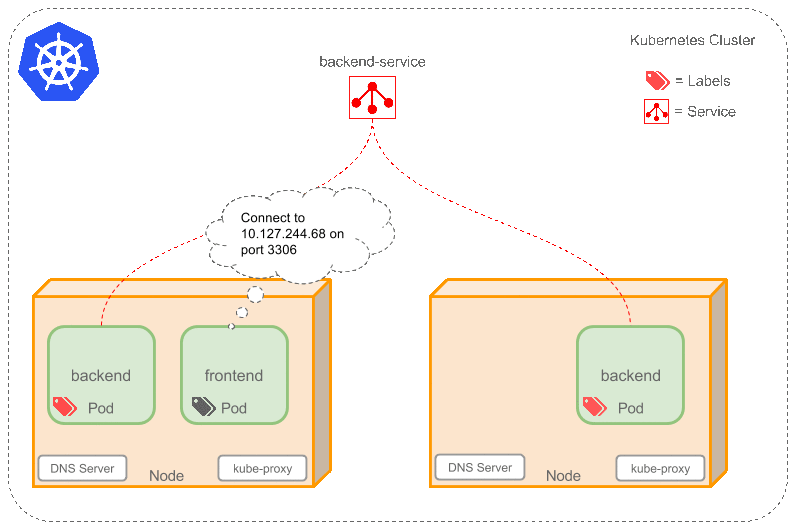
有一个特别类型的Kubernetes Service,称为'LoadBalancer',作为外部负载均衡器使用,在一定数量的Pod之间均衡流量。比如,对于负载均衡Web流量很有用。
7、Node
节点(上图橘色方框)是物理或者虚拟机器,作为Kubernetes worker,通常称为Minion。每个节点都运行如下Kubernetes关键组件: Kubelet:是主节点代理。 Kube-proxy:Service使用其将链接路由到Pod,如上文所述。 Docker或Rocket:Kubernetes使用的容器技术来创建容器。
8、Kubernetes Master
集群拥有一个Kubernetes Master(紫色方框)。Kubernetes Master提供集群的独特视角,并且拥有一系列组件,比如Kubernetes API Server。API Server提供可以用来和集群交互的REST端点。master节点包括用来创建和复制Pod的Replication Controller。
二、二进制源码安装部署(master节点)
1、环境
| 主机 | ip地址 | 软件版本 |
| k8s-master | 192.168.4.11 | docker-1.12.6-71 |
| k8s-node | 192.168.4.12 | kubernetes-1.6.13 |

bin:二进制文件,不需要安装,直接运行
kubernetes.tar.gz:源码包文件
docker镜像文件:kubernetes-dashboard-amd64-v1.5.1.tar、pause-amd64-3.0.tar
docker pull gcr.azk8s.cn/google_containers/pause-amd64:3.0
docker pull gcr.azk8s.cn/google_containers/kubernetes-dashboard-amd64:v1.5.1
bin目录
导入两个docker镜像
docker load < pause-amd64-3.0.tar docker load < kubernetes-dashboard-amd64-v1.5.1.tar
2、安装etcd
1、yum安装
yum -y install etcd
2、修改配置 修改etcd配置文件监听地址 # vim /etc/etcd/etcd.conf 6 ETCD_LISTEN_CLIENT_URLS="http://192.168.4.11:2379" 21 ETCD_ADVERTISE_CLIENT_URLS="http://192.168.4.11:2379"
3、启动服务 systemctl start etcd.service systemctl enable etcd.service
# 2379端口 是客户端连接端口
# 2380端口 是etcd集群连接端口
下载二进制文件的脚本,因为无法访问google所以这里我们是下不下来的
/root/k8s/kubernetes/cluster/get-kube-binaries.sh
我准备好的所需二进制文件(bin目录)
部署master
tar xf kubernetes.tar.gz
cd k8s/kubernetes/cluster/centos/master/scripts/
环境初始化
首先保证etcd2379端口存在 不然之后都无法操作 1、创建目录 因为安装脚本中会把配置文件和二进制文件放到指定的目录下面 mkdir -p /opt/kubernetes/{cfg,bin} 2、把所需要得二进制文件拷贝到指定目录(提前下载好的二进制文件) cd k8s/bin/ mv * /opt/kubernetes/bin/
3、配置启动kube-apiserver
cd /root/k8s/kubernetes/cluster/centos/master/scripts/
apiserver.sh其中有四个传参
MASTER_ADDRESS=${1:-"8.8.8.18"} MASTER地址 ETCD_SERVERS=${2:-"http://8.8.8.18:2379"} ETCD地址 SERVICE_CLUSTER_IP_RANGE=${3:-"10.10.10.0/24"} 服务的范围 ADMISSION_CONTROL=${4:-""} 资源控制列表
启动服务
./apiserver.sh 192.168.4.11 http://192.168.4.11:2379 10.1.0.0/16
查看服务和端口
systemctl status kube-apiserver.service
lsof -i :8080
脚本都干了什么
1、在/opt/kubernetes/cfg/目录下,创建了kube-apiserver配置文件 2、创建了/usr/lib/systemd/system/kube-apiserver.service 服务
kubernetes API Server的介绍
kube-apiserver提供了k8s各类资源对象(pod,RC,Service等)的增删改查及watch等HTTP Rest接口,是整个系统的数据总线和数据中心。
kubernetes API Server的功能:
提供了集群管理的REST API接口(包括认证授权、数据校验以及集群状态变更);
提供其他模块之间的数据交互和通信的枢纽(其他模块通过API Server查询或修改数据,只有API Server才直接操作etcd);
是资源配额控制的入口;
拥有完备的集群安全机制.
4、配置启动kube-controller-manager
controller-manager.sh 只有一个传参
MASTER_ADDRESS=${1:-"8.8.8.18"} master地址
启动服务
./controller-manager.sh 192.168.4.11
查看服务和端口
systemctl status kube-controller-manager.service
lsof -i :10252
介绍和功能
kube-controller-manager:副本控制器,监听pod副本数,使用10252端口
5、配置启动kube-scheduler
scheduler.sh 只有一个传参
MASTER_ADDRESS=${1:-"8.8.8.18"} master地址
启动服务
./scheduler.sh 192.168.4.11
查看服务和端口
systemctl status kube-scheduler.service lsof -i :10251
介绍和功能
kube-scheduler:资源调度器, 使用10251端口
6、测试
设置环境变量
# vim .bash_profile PATH=$PATH:$HOME/bin:/opt/kubernetes/bin # source .bash_profile
查看组件状态
kubectl -s http://192.168.2.100:8080 get cs

三、二进制源码安装部署(node节点)
环境
docker load < kubernetes-dashboard-amd64-v1.5.1.tar docker load < pause-amd64-3.0.tar mkdir -p /opt/kubernetes/{cfg,bin} mv /root/k8s/bin/* /opt/kubernetes/bin/ tar xf kubernetes.tar.gz
1、安装kubelet
在每个节点(node)上都要运行一个 worker 对容器进行生命周期的管理,这个 worker 程序就是 kubelet。 简单地说,kubelet?的主要功能就是定时从某个地方获取节点上 pod/container 的期望状态(运行什么容器、运行的副本数量、网络或者存储如何配置等等),并调用对应的容器平台接口达到这个状态。 kubelet 除了这个最核心的功能之外,还有很多其他特性: 定时汇报当前节点的状态给 apiserver,以供调度的时候使用 镜像和容器的清理工作,保证节点上镜像不会占满磁盘空间,退出的容器不会占用太多资源 运行 HTTP Server,对外提供节点和 pod 信息,如果在 debug 模式下,还包括调试信息
kubelet.sh 其中有四个传参
MASTER_ADDRESS=${1:-"8.8.8.18"} master地址
NODE_ADDRESS=${2:-"8.8.8.20"} node地址
DNS_SERVER_IP=${3:-"192.168.3.100"}
DNS_DOMAIN=${4:-"cluster.local"}
启动服务
./kubelet.sh 192.168.4.11 192.168.4.12
查看服务和端口
systemctl status kubelet.service
lsof -i :10250
2、安装proxy
在每个节点上运行网络代理。这反映每个节点上 Kubernetes API 中定义的服务,并且可以做简单的 TCP 和 UDP 流转发或在一组后端中轮询,进行 TCP 和 UDP 转发
proxy.sh 其中有两个传参
MASTER_ADDRESS=${1:-"8.8.8.18"} master地址
NODE_ADDRESS=${2:-"8.8.8.20"} node地址
启动服务
./proxy.sh 192.168.4.11 192.168.4.12
查看服务和端口
systemctl status kube-proxy.service lsof -i :10249
3、测试
master执行
kubectl get node
NAME STATUS AGE VERSION
192.168.4.12 Ready 12d v1.6.13
四、网络
1、Flannel介绍
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。
默认的Docker配置中,每个节点上的Docker服务会分别负责所在节点容器的IP分配。这样导致的一个问题是,不同节点上容器可能获得相同的内外IP地址。
Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的”IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。
Flannel实质上是一种“覆盖网络(overlay network)”,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持UDP、VxLAN、AWS VPC和GCE路由等数据转发方式。
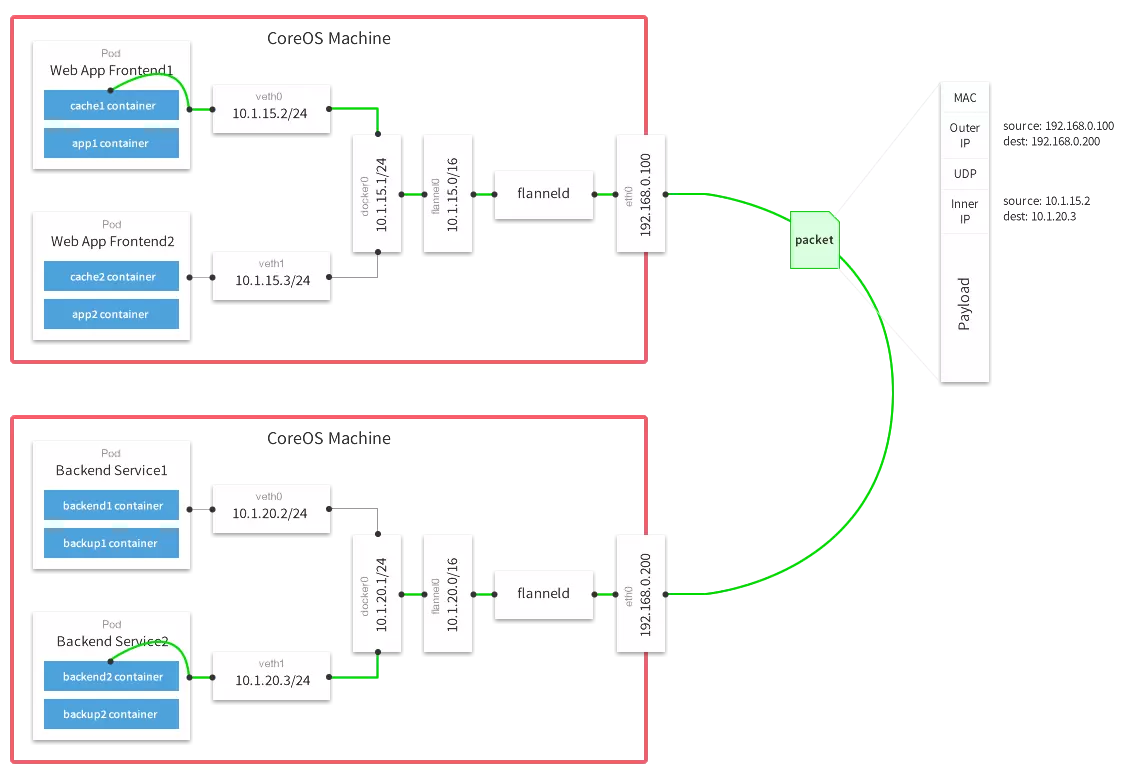
2、安装配置
官网下载flannel
https://github.com/coreos/flannel/releases/tag/v0.9.1
wget https://github.com/coreos/flannel/releases/download/v0.9.1/flannel-v0.9.1-linux-amd64.tar.gz

二进制文件和执行脚本,存放路径
/root/k8s/kubernetes/cluster/centos/node/scripts/flannel.sh
tar xf flannel-v0.9.1-linux-amd64.tar.gz
cp -a flanneld /opt/kubernetes/bin/flanneld
flannel.sh 其中有两个传参
ETCD_SERVERS=${1:-"http://8.8.8.18:2379"} etcd地址
FLANNEL_NET=${2:-"172.16.0.0/16"} flannel创建的网络
启动服务
./flannel.sh http://192.168.4.11:2379 10.2.0.0/16
systemctl start flanneld.service
查看服务和网络
systemctl status flannel.service
ifconfig flannel

配置Docker里使用Flannel网络
# vim /root/k8s/kubernetes/cluster/centos/node/scripts/docker.sh DOCKER_OPTS="-H tcp://127.0.0.1:4243 -H unix:///var/run/docker.sock --selinux-enabled=false ${DOCKER_OPTS}"
有些版本不支持overlay存储模式所以如果有报错就删除 -s overlay
启动docker
./docker.sh
如果执行还是启动不起来,进行如下操作 rm -f /opt/kubernetes/bin/dockerd ln -s /usr/bin/dockerd /opt/kubernetes/bin/
配置完成后查看网络状态
ifconfig docker0 && ifconfig flannel

测试网络
docker run -it --name test1 busybox
QQ:328864113 微信:wuhg2008

