学习GlusterFS(四)
基于 GlusterFS 实现 Docker 集群的分布式存储
以 Docker 为代表的容器技术在云计算领域正扮演着越来越重要的角色,甚至一度被认为是虚拟化技术的替代品。企业级的容器应用常常需要将重要的数据持久化,方便在不同容器间共享。为了能够持久化数据以及共享容器间的数据,Docker 提出了 Volume 的概念。单机环境的数据卷难以满足 Docker 集群化的要求,因此需要引入分布式文件系统。目前开源的分布式文件系统有许多,例如 GFS,Ceph,HDFS,FastDFS,GlusterFS 等。GlusterFS 因其部署简单、扩展性强、高可用等特点,在分布式存储领域被广泛使用。本文主要介绍了如何利用 GlusterFS 为 Docker 集群提供可靠的分布式文件存储。
GlusterFS 分布式文件系统简介
GlusterFS 概述
GlusterFS (Gluster File System) 是一个开源的分布式文件系统,主要由 Z RESEARCH 公司负责开发。GlusterFS 是 Scale-Out 存储解决方案 Gluster 的核心,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS 借助 TCP/IP 或 InfiniBand RDMA 网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS 基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
GlusterFS 总体架构与组成部分如图1所示,它主要由存储服务器(Brick Server)、客户端以及 NFS/Samba 存储网关组成。不难发现,GlusterFS 架构中没有元数据服务器组件,这是其最大的设计这点,对于提升整个系统的性能、可靠性和稳定性都有着决定性的意义。
- GlusterFS 支持 TCP/IP 和 InfiniBand RDMA 高速网络互联。
- 客户端可通过原生 GlusterFS 协议访问数据,其他没有运行 GlusterFS 客户端的终端可通过 NFS/CIFS 标准协议通过存储网关访问数据(存储网关提供弹性卷管理和访问代理功能)。
- 存储服务器主要提供基本的数据存储功能,客户端弥补了没有元数据服务器的问题,承担了更多的功能,包括数据卷管理、I/O 调度、文件定位、数据缓存等功能,利用 FUSE(File system in User Space)模块将 GlusterFS 挂载到本地文件系统之上,实现 POSIX 兼容的方式来访问系统数据。
图1. GlusterFS 总体架构
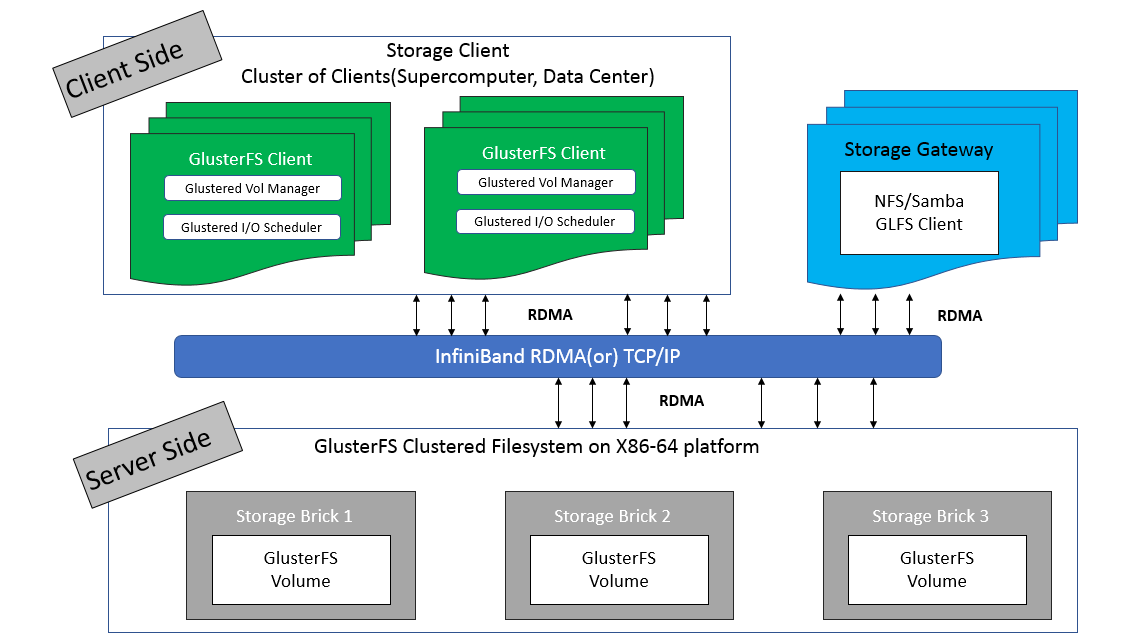
如图 1 中 GlusterFS 有非常多的术语,理解这些术语对理解 GlusterFS 的动作机理是非常重要的,表1给出了 GlusterFS 常见的名称及其解释。
表1. GlusterFS 常见术语
GlusterFS卷类型
为了满足不同应用对高性能、高可用的需求,GlusterFS 支持 7 种卷,即 distribute 卷、stripe 卷、replica 卷、distribute stripe 卷、distribute replica 卷、stripe Replica 卷、distribute stripe replica 卷。其实不难看出,GlusterFS 卷类型实际上可以分为 3 种基本卷和 4 种复合卷,每种类型的卷都有其自身的特点和适用场景。
基本卷:
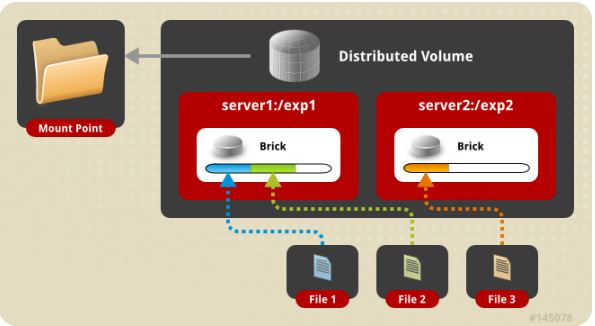
(1) distribute volume 分布式卷
基于 Hash 算法将文件分布到所有 brick server,只是扩大了磁盘空间,不具备容错能力。由于distribute volume 使用本地文件系统,因此存取效率并没有提高,相反会因为网络通信的原因使用效率有所降低,另外本地存储设备的容量有限制,因此支持超大型文件会有一定难度。图2 是 distribute volume 示意图。
图2. Distribute volume示意图
(2) stripe volume 条带卷
类似 RAID0,文件分成数据块以 Round Robin 方式分布到 brick server 上,并发粒度是数据块,支持超大文件,大文件的读写性能高。图3 是 stripe volume 示意图。
图3. Stripe volume示意图

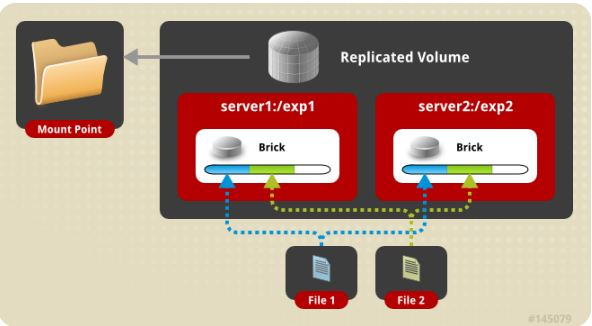
(3) replica volume 复制卷
文件同步复制到多个 brick 上,文件级 RAID1,具有容错能力,写性能下降,读性能提升。Replicated 模式,也称作 AFR(Auto File Replication),相当于 RAID1,即同一文件在多个镜像存储节点上保存多份,每个 replicated 子节点有着相同的目录结构和文件,replica volume 也是在容器存储中较为推崇的一种。图4 是 replica volume 示意图。
图4 . Replica volume示意图
复合卷:
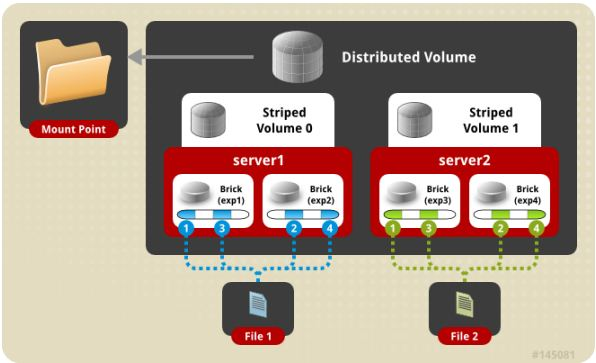
(4) distribute stripe volume 分布式条带卷
Brick server 数量是条带数的倍数,兼具 distribute 和 stripe 卷的特点。分布式的条带卷,volume 中 brick 所包含的存储服务器数必须是 stripe 的倍数(>=2倍),兼顾分布式和条带式的功能。每个文件分布在四台共享服务器上,通常用于大文件访问处理,最少需要 4 台服务器才能创建分布条带卷。图5 是distribute stripe volume 示意图。
图5 . Distribute stripe volume 示意图
(5) distribute replica volume 分布式复制卷
Brick server 数量是镜像数的倍数,兼具 distribute 和 replica 卷的特点,可以在 2 个或多个节点之间复制数据。分布式的复制卷,volume 中 brick 所包含的存储服务器数必须是 replica 的倍数(>=2倍),兼顾分布式和复制式的功能。图6 是 distribute replica volume 示意图。
图6 . Distribute replica volume 示意图
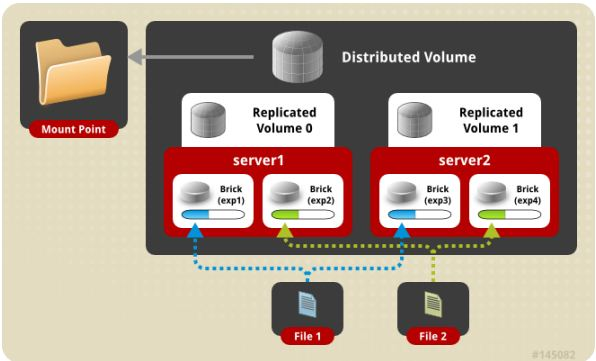
(6) stripe replica volume 条带复制卷
类似 RAID 10,同时具有条带卷和复制卷的特点。图7 是 distribute replica volume 示意图。
图7 . Stripe replica volume 示意图
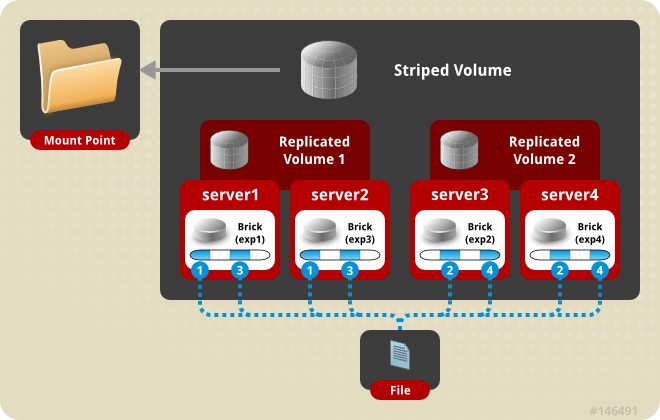
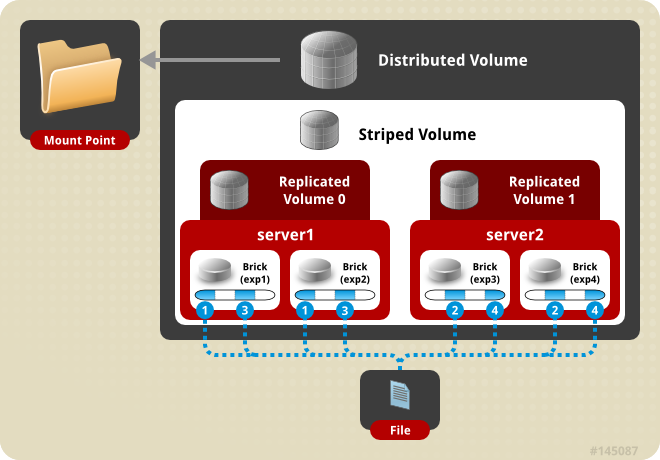
(7) distribute stripe replica volume:分布式条带复制卷
三种基本卷的复合卷,通常用于类 Map Reduce 应用。图8 是 distribute stripe replica volume 示意图。
图8 . Distribute stripe replica volume 示意图
GlusterFS 常用命令
GlusterFS 客户端提供了非常丰富的命令用来操作节点、卷,表2给出了常用的一些命令。在与容器对接过程中,通过我们需要创建卷、删除卷,以及设定卷的配额等功能,并且后续这些功能也需要 REST API 化,方便通过HTTP请求的方式来操作卷。
表2. GlusterFS 客户端常用命令
#################################################################################################33
glusterfs
GlusterFS是一个可伸缩的网络文件系统,使用常见的现成的硬件,您可以创建大型分布式存储流媒体解决方案、数据分析、和其他数据相关的任务。GlusterFS是自由和开源软件。
详细参考官网: gluster
资源定义
- Brick: 存储的基本单元,表现为服务器上可信存储池的导出目录
- Volume: 卷是bricks的逻辑集合
- Cluster: 一组计算机组成的集群
- Distributed File System: 允许多个客户端通过网络并发访问的文件系统
- GFID: 每个GlusterFs中的文件或者目录都有一个128bit的数字标识称为GFID
- glusterd: 管理守护进程需要运行在所有的提供授信存储池的服务器上
- Namespace: 名称空间是被创建的一个抽象容器或环境用来保存唯一标识符号
- Quorum: 设置一个可信的存储池中最多失效的主机节点数量
- Quota: 允许通过目录或者卷设置对磁盘空间使用的限制
- Posix: 可移植操作系统接口是IEEE定义的一系列相关api标准
- Vol File: Vol文件是glusterfs进程使用的配置文件
- Distributed: 分布卷
- Replicated: 复本卷
- Distributed Replicated: 分布式复制卷
- Geo-Replication: 异地备份为站点通过局域网、广域网、互联网提供一个连续的异步的和增量复制服务
- Metedata: 元数据定义为关于数据的数据描述信息,在GlusterFs没有专用的元数据存储内容
- Extended Attributes: 扩展属性是文件系统的一个特性
FUSE: 用户空间的文件系统是一个用于类Unix操作系统的可加载内核模块,以允许非特权用户在适用内核代码的情况下创建自己的文件系统。实现了在用户空间下运行文件系统代码
环境基础
10.1.1.11 c6-vm1 centos6.6 glusterfs-3.10 第二块硬盘10G 10.1.1.12 c6-vm2 centos6.6 glusterfs-3.10 第二块硬盘10G 10.1.1.13 c6-vm3 centos6.6 client
yum 仓库安装
[root@c6-vm1 yum.repos.d]# cat glusterfs.repo [glusterfs] name=glusterfs baseurl=http://buildlogs.centos.org/centos/6/storage/x86_64/gluster-3.10/ enabled=1 gpgcheck=0 [debuginfo] name=glusterfs debuginfo baseurl=http://debuginfo.centos.org/centos/6/storage/x86_64/ enabled=1 gpgcheck=0
install
yum install -y glusterfs-server glusterfs-cli glusterfs-geo-replication
启动程序加入开启自启动
[root@c6-vm1]# /etc/init.d/glusterd start [root@c6-vm1 ~]# chkconfig glusterd on
存储主机加入信任存储池
# 在其余主机添加除自己之外的主机就可以 [root@c6-vm1]# gluster peer probe c6-vm2 peer probe: success.
查看状态
[root@c6-vm1 ~]# gluster peer status Number of Peers: 1 Hostname: c6-vm2 Uuid: 60eac2bb-ae30-4c3d-8c14-b93a3cb0ad98 State: Peer in Cluster (Connected)
磁盘分区
fdisk -l 查看磁盘块设备,可以看到/dev/sdb 第二块新硬盘
[root@c6-vm1 ~]# fdisk -l Disk /dev/sda: 37.6 GB, 37580963840 bytes 255 heads, 63 sectors/track, 4568 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x000f1817 Device Boot Start End Blocks Id System /dev/sda1 * 1 26 204800 83 Linux Partition 1 does not end on cylinder boundary. /dev/sda2 26 3851 30720000 83 Linux /dev/sda3 3851 4569 5774336 82 Linux swap / Solaris Disk /dev/sdb: 10.7 GB, 10737418240 bytes 255 heads, 63 sectors/track, 1305 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00000000
注:mkfs支持的分区类型有限,且最大只支持16TB;当分区大于4T时,fdisk不适用,推荐用parted分区
# fdisk 分区操作 在二台机器上分别执行
# fdisk /dev/vdb => n => p => 1 => 回车 => w(w为保存、m为帮助)
[root@c6-vm1 ~]# fdisk /dev/sdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0xf2a1a3ec.
Changes will remain in memory only, until you decide to write them.
After that, of course, the previous content won't be recoverable.
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-1305, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-1305, default 1305):
Using default value 1305
[root@c6-vm1 ~]# mkfs.ext4 /dev/sdb1
# 在二台机器上分别执行 建立挂载块设备的目录并挂载加入fstab中 [root@c6-vm1 ~]# mkdir /data/gfs1 [root@c6-vm1 ~]# mount /dev/sdb1 /data/gfs1 [root@c6-vm1 ~]# mount -a [root@c6-vm1 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 29G 874M 27G 4% / tmpfs 358M 0 358M 0% /dev/shm /dev/sda1 190M 25M 156M 14% /boot /dev/sdb1 9.8G 23M 9.2G 1% /data/gfs1 [root@c6-vm1 ~]# echo "/dev/sdb1 /data/gfs1 ext4 defaults 1 2" >> /etc/fstab
公司如果有raid卡,可以在底层做一层raid5提高IO性能,再在上头做GlusterFS。当然没有raid卡直接做GlusterFS也没事
创建volume
Distributed:分布式卷,文件通过hash算法随机的分布到由bricks组成的卷上。 Replicated:复制式卷,类似raid1,replica数必须等于volume中brick所包含的存储服务器数,可用性高。 Striped:条带式卷,类似与raid0,stripe数必须等于volume中brick所包含的存储服务器数,文件被分成数据块,以Round Robin的方式存储在bricks中,并发粒度是数据块,大文件性能好。 Distributed Striped:分布式的条带卷,volume中brick所包含的存储服务器数必须是stripe的倍数(>=2倍),兼顾分布式和条带式的功能。 Distributed Replicated:分布式的复制卷,volume中brick所包含的存储服务器数必须是 replica 的倍数(>=2倍),兼顾分布式和复制式的功能。
创建复制卷
[root@c6-vm1 ~]# gluster volume create gv2 replica 2 c6-vm1:/data/gfs1 c6-vm2:/data/gfs1 force volume create: gv2: success: please start the volume to access data [root@c6-vm1 ~]# gluster volume info Volume Name: gv2 Type: Replicate Volume ID: fa64409f-814b-4191-b9e4-8c317bf63a94 Status: Created #这里状态表示刚刚被创建但是还没有启动 Snapshot Count: 0 Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: c6-vm1:/data/gfs1 Brick2: c6-vm2:/data/gfs1 Options Reconfigured: transport.address-family: inet nfs.disable: on
start volume
[root@c6-vm1 gfs1]# gluster volume start gv2 volume start: gv2: success [root@c6-vm1 gfs1]# gluster volume info Volume Name: gv2 Type: Replicate Volume ID: fa64409f-814b-4191-b9e4-8c317bf63a94 Status: Started #启动后状态变成start Snapshot Count: 0 Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: c6-vm1:/data/gfs1 Brick2: c6-vm2:/data/gfs1 Options Reconfigured: transport.address-family: inet nfs.disable: off
客户端挂载
c6-vm3
yum glusterfs
yum install -y glusterfs gluster-fuse
glusterfs 方式挂载
[root@c6-vm3 yum.repos.d]# mount -t glusterfs c6-vm1:/gv2 /mnt [root@c6-vm3 mnt]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 29G 923M 27G 4% / tmpfs 358M 0 358M 0% /dev/shm /dev/sda1 190M 25M 156M 14% /boot c6-vm1:/gv2 9.8G 23M 9.2G 1% /mnt
nfs 方式挂载
[root@c6-vm2 gfs1]# mount -t nfs -o mountproto=tcp,vers=3 c6-vm2:gv2 /mnt/ [root@c6-vm2 gfs1]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 29G 875M 27G 4% / tmpfs 358M 0 358M 0% /dev/shm /dev/sda1 190M 25M 156M 14% /boot /dev/sdb1 9.8G 23M 9.2G 1% /data/gfs1 c6-vm2:gv2 9.8G 33M 14G 1% /mnt
# 创建文件
[root@c6-vm3 mnt]# cd /mnt/
[root@c6-vm3 mnt]# touch file{1..10}
在存储端验证
c6-vm1
[root@c6-vm1 gfs1]# ls file1 file10 file2 file3 file4 file5 file6 file7 file8 file9 lost+found
c6-vm2
[root@c6-vm2 gfs1]# ls file1 file10 file2 file3 file4 file5 file6 file7 file8 file9 lost+found
status
[root@c6-vm1 gfs1]# gluster volume status gv2 Status of volume: gv2 Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick c6-vm1:/data/gfs1 49152 0 Y 1976 Brick c6-vm2:/data/gfs1 49152 0 Y 1883 NFS Server on localhost 2049 0 Y 1996 Self-heal Daemon on localhost N/A N/A Y 2007 NFS Server on c6-vm2 2049 0 Y 1903 Self-heal Daemon on c6-vm2 N/A N/A Y 1914 Task Status of Volume gv2 ------------------------------------------------------------------------------ There are no active volume task
故障演练
把c6-vm1关机
因为我们之前在c6-vm3(client)端mount挂载的时候指定的是c6-vm1主机
当我们把c6-vm1关机,观察后面的情况是怎么样

-w935
查看volume状态

-w808
在c6-vm3上操作 明显没有问题
注意: 当c6-vm1关机的时候,在ls该目录会有短暂时间的延迟卡主的现象

-w1006
在去c6-vm2上看文件状态
新建的bds已经有了,删除的file0也没有删除成功

-w1051
现在我们尝试开机c6-vm1
发现文件系统报错了,完了这个机器成功被我们弄坏了 修复吧

-w804
可以看到我们进入了 只读文件系统中 根本注释不了这行

-w855
解决办法重新挂载
# 根系统重新挂载 救命的命令啊 mount -o remount rw /

image
下图可以看到 我们已经把有问题那行 注释掉了 然后reboot

image
登录c6-vm1
[root@c6-vm1 gfs1]# mount /dev/sdb1 /data/gfs1/ [root@c6-vm1 gfs1]# gluster volume status Status of volume: gv2 Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick c6-vm1:/data/gfs1 N/A N/A N N/A Brick c6-vm2:/data/gfs1 49152 0 Y 1883 NFS Server on localhost 2049 0 Y 1082 Self-heal Daemon on localhost N/A N/A Y 1146 NFS Server on c6-vm2 2049 0 Y 1903 Self-heal Daemon on c6-vm2 N/A N/A Y 1914 Task Status of Volume gv2 ------------------------------------------------------------------------------ There are no active volume tasks
在正常的节点c6-vm2 执行命令查看信息
[root@c6-vm2 gfs1]# getfattr -d -m '.*' /data/gfs1/ getfattr: Removing leading '/' from absolute path names # file: data/gfs1/ trusted.afr.dirty=0sAAAAAAAAAAAAAAAA trusted.afr.gv2-client-0=0sAAAAAAAAAAAAAAAD trusted.gfid=0sAAAAAAAAAAAAAAAAAAAAAQ== trusted.glusterfs.dht=0sAAAAAQAAAAAAAAAA/////w== trusted.glusterfs.volume-id=0s+mRAn4FLQZG55Iwxe/Y6lA==
在机器关机的c6-vm1节点上进行set写入
[root@c6-vm1 gfs1]# setfattr -n trusted.glusterfs.volume-id -v 0s+mRAn4FLQZG55Iwxe/Y6lA== /data/gfs1/ [root@c6-vm1 gfs1]# setfattr -n trusted.glusterfs.volume-id -v 0s+mRAn4FLQZG55Iwxe/Y6lA== /data/gfs1/ [root@c6-vm1 gfs1]# setfattr -n trusted.gfid -v 0sAAAAAAAAAAAAAAAAAAAAAQ== /data/gfs1/ [root@c6-vm1 gfs1]# setfattr -n trusted.afr.dirty -v 0sAAAAAAAAAAAAAAAA /data/gfs1/ [root@c6-vm1 gfs1]# setfattr -n trusted.glusterfs.dht -v 0sAAAAAQAAAAAAAAAA/////w== /data/gfs1/
重启glusterfs
[root@c6-vm1 gfs1]# /etc/init.d/glusterd restart Stopping glusterd: [确定] Starting glusterd: [确定]
重启完成之后,根据数据的大小,等待片刻,则同步完成 观察下面目录变化
[root@c6-vm1 gfs1]# ll 总用量 32 -rw-r--r-- 2 root root 5 10月 9 23:08 a -rw-r--r-- 2 root root 29 10月 9 19:53 a.txt -rw-r--r-- 2 root root 0 10月 2 13:29 ba -rw-r--r-- 2 root root 0 10月 2 12:54 file1 -rw-r--r-- 2 root root 0 10月 2 12:54 file10 -rw-r--r-- 2 root root 5 10月 9 19:14 file2 -rw-r--r-- 2 root root 0 10月 2 12:54 file3 -rw-r--r-- 2 root root 0 10月 2 12:54 file4 -rw-r--r-- 2 root root 0 10月 2 12:54 file5 -rw-r--r-- 2 root root 0 10月 2 12:54 file6 -rw-r--r-- 2 root root 0 10月 2 12:54 file7 -rw-r--r-- 2 root root 0 10月 2 12:54 file8 -rw-r--r-- 2 root root 0 10月 2 12:54 file9 drwx------ 2 root root 16384 10月 9 03:12 lost+found
这个目录里面保存一些同步信息
[root@c6-vm1 gfs1]# cd .glusterfs/ [root@c6-vm1 .glusterfs]# ls 00 1c 31 3e 3f 46 4c 56 64 82 89 a3 c7 changelogs eb gfs1.db health_check indices landfill quanrantine unlink [root@c6-vm1 .glusterfs]# ll 总用量 100 drwx------ 3 root root 4096 10月 9 23:06 00 drwx------ 3 root root 4096 10月 9 23:08 1c drwx------ 3 root root 4096 10月 9 23:08 31 drwx------ 3 root root 4096 10月 9 23:08 3e drwx------ 3 root root 4096 10月 9 23:08 3f drwx------ 3 root root 4096 10月 9 23:08 46 drwx------ 3 root root 4096 10月 9 23:08 4c drwx------ 3 root root 4096 10月 9 23:07 56 drwx------ 3 root root 4096 10月 9 23:08 64 drwx------ 3 root root 4096 10月 9 23:08 82 drwx------ 3 root root 4096 10月 9 23:08 89 drwx------ 3 root root 4096 10月 9 23:08 a3 drwx------ 4 root root 4096 10月 9 23:08 c7 drw------- 4 root root 4096 10月 9 22:30 changelogs drwx------ 3 root root 4096 10月 9 23:08 eb -rw-r--r-- 1 root root 20480 10月 9 22:30 gfs1.db -rw-r--r-- 1 root root 19 10月 9 23:17 health_check drw------- 5 root root 4096 10月 9 22:30 indices drwxr-xr-x 2 root root 4096 10月 9 23:06 landfill drw------- 2 root root 4096 10月 9 22:30 quanrantine drw------- 2 root root 4096 10月 9 23:06 unlink
同步后的目录 与正常节点c6-vm2目录保持一致了
[root@c6-vm1 .glusterfs]# cd .. [root@c6-vm1 gfs1]# ls bds file1 file10 file2 file3 file4 file5 file6 file7 file8 file9 lost+found [root@c6-vm1 gfs1]# ll 总用量 24 -rw-r--r-- 2 root root 8 10月 9 23:21 bds -rw-r--r-- 2 root root 0 10月 2 12:54 file1 -rw-r--r-- 2 root root 0 10月 2 12:54 file10 -rw-r--r-- 2 root root 5 10月 9 19:14 file2 -rw-r--r-- 2 root root 0 10月 2 12:54 file3 -rw-r--r-- 2 root root 0 10月 2 12:54 file4 -rw-r--r-- 2 root root 0 10月 2 12:54 file5 -rw-r--r-- 2 root root 0 10月 2 12:54 file6 -rw-r--r-- 2 root root 0 10月 2 12:54 file7 -rw-r--r-- 2 root root 0 10月 2 12:54 file8 -rw-r--r-- 2 root root 0 10月 2 12:54 file9 drwx------ 2 root root 16384 10月 9 03:12 lost+found

 浙公网安备 33010602011771号
浙公网安备 33010602011771号