scrapy 启动
虚拟环境安装好了之后,scrapy 框架安装好了以后:
workon article_spider (项目名称)
scrapy startproject Article Spider 工程目录
cd 到 工程目录
Scrapy genspider jobbole blog.jobbole.com 第一个文件名称 要爬取网站的域名
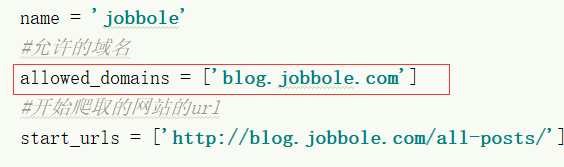
启动一个工程的cmd: scrapy crawl jobbole
如果 运行报 No module named “win32api”
要安装 pip install pypiwin32 这个包
settings
把 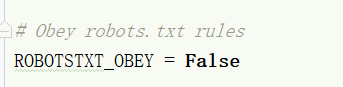
这样设置,否则 遵循 robots.txt rules ,它将会不爬
如果 是 xpath selector 对象 想提取里面的内容,调用extract()成一个列表,然后索引取出,但是列表没有值,索引取出就会报错,所以
extract_first 提取不到就返回None。比较好

