



LInkedList总结及部分底层源码分析
1. LinkedList的实现与继承关系
- 继承:AbstractSequentialList 抽象类
- 实现:List 接口
- 实现:Deque 接口
- 实现:Cloneable 接口
- 实现:Serializable 接口,标记该类支持序列化
2. LinkedList的底层数据结构
- LinkedList底层是基于双向链表实现的
1. 特点
链表在内存中存储空间是不连续的,只是利用相邻个节点之间的地址指向来保证存储在一条链表上的数据连续。
双向链表意思是一个节点有两个指向,一个指向后一个节点的地址(next),另一个指向前一个节点的地址(prev)。
主要实现的链表,在遍历时可以从头节点遍历到位节点,也可以从尾节点遍历到头节点。每个节点可以存储null
1. 单向链表举例:
张三认识李四知道李四的住址,李四认识王五知道王五的住址,王五认识赵六知道赵六的地址。那么用单链表来表示可以表示为如下:
- 说明:一个节点(node)有两个域,数据域(data)用于存放数据和指针域(next)用于指向下一个节点,所以这个指针域实际上保存的是下一个节点的地址。

2. 双向链表举例:
张三认识李四知道李四的住址,李四也知道张三的住址,李四认识王五知道王五的住址,王五也知道李四的住址。
双向链表有上域,两个指针域next:指向下一个节点,prev:指向前一个节点,数据域data:存放数据
双向链表表示:

2. 优点
-
以充分利用内存中散列的零碎的空间进行数据的存储。提高内存空间的利用率。
-
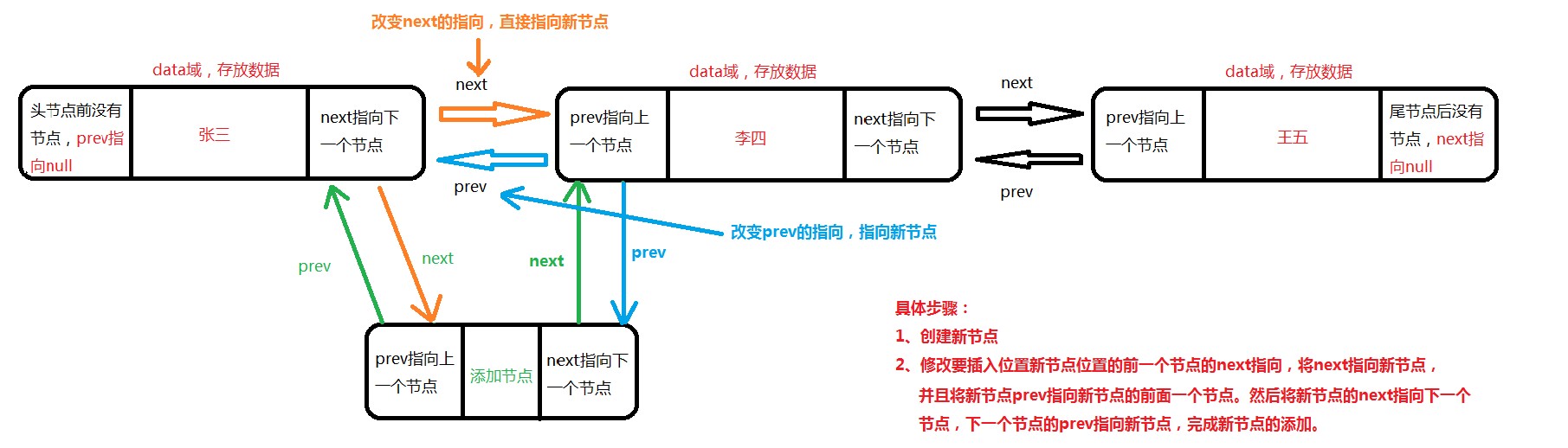
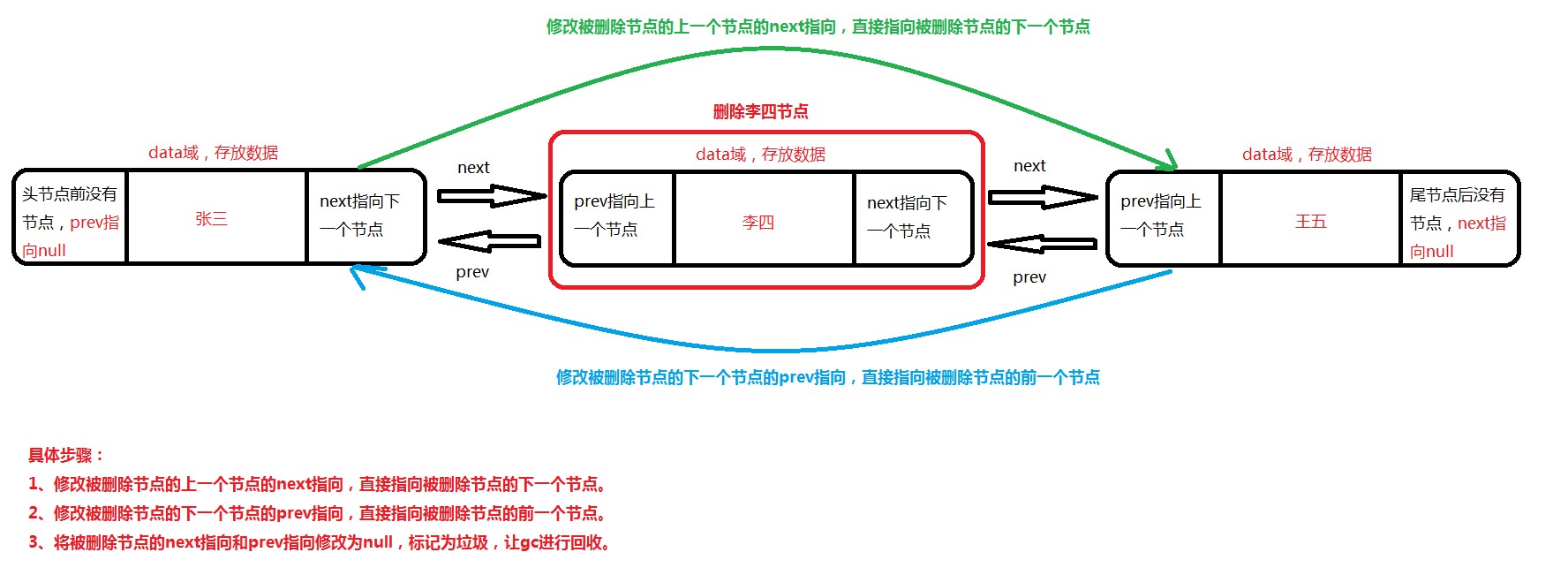
在进行数据插入和删除数据时执行效率快,因为在添加和删除数据时只需要改变指针的指向即可
添加节点画图说明:
删除节点画图说明:
3. 缺点
-
在链表存储的数据量比较大时,查找指定数据的效率较低,因为链表在查找指定的数据时,只能通过遍历的方式逐个去进行比较。不能像数组那样根据下标去进行查找。所以效率对较低。
-
LinkedList集合是线程不安全的集合,在多线程情况下可能会发生线程安全问题。如果需要在多线程情况下使用该集合。需要使用Collections集合工具类创建一个线程安全的LinkedList集合
// 创建一个线程安全的LinkedList集合 List<Integer> linkedList = Collections.synchronizedList(new LinkedList<Integer>());
3. LinkedList的适用场景
- 单线程环境下对集合中存储的数据频繁进行添加新数据或者删除旧数据适合使用LinkedList集合
- 如果需要在多线程情况下使用需要创建线程安全的LinkedList集合
4. 底层源码分析
1. 构造函数
2.无参构造函数
/**
* 默认无参构造函数,
*/
public LinkedList() {}
2. 有参构造函数
/**
* 在初始化的时候直接将一个集合传入,可以把传入集合的元素全部复制到创建的新集合中
* @param c 传入的集合
*/
public LinkedList(Collection<? extends E> c) {
// 调用无参构造
this();
// addAll()地方,添加传入集合中所有的元素
addAll(c);
}
-
addAll() 方法
/** * 将一个集合传入,可以把传入集合的元素全部复制到创建的新集合中 * @param c 传入的集合 * @return 成功返回true,失败返回false */ public boolean addAll(Collection<? extends E> c) { // 调用addAll() 重载的方法 return addAll(size, c); } -
addAll重载的方法(目前不去探究该方法的底层实现)
/** * * @param index * @param c * @return */ public boolean addAll(int index, Collection<? extends E> c) { checkPositionIndex(index); Object[] a = c.toArray(); int numNew = a.length; if (numNew == 0) return false; Node<E> pred, succ; if (index == size) { succ = null; pred = last; } else { succ = node(index); pred = succ.prev; } for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node<E> newNode = new Node<>(pred, e, null); if (pred == null) first = newNode; else pred.next = newNode; pred = newNode; } if (succ == null) { last = pred; } else { pred.next = succ; succ.prev = pred; } size += numNew; modCount++; return true; }
2. 添加一条数据的完整流程
1. 将数据包装
- 在每次添加数据时,如果数据是基本数据类型,会先将基本数据类型进行装箱操作,把基本数据类型转换成对应的包装类型(引用数据类型)
// 例如:集合中存放Integer数据类型,在进行add操作时,会先进行装箱操作
/**
* 将基本数据类转换为引用数据类型
* @param i 传入的参数为一个基本型数据类型
* @return 返回的参数是一个基本数据类型的包装类(引用数据类型)
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
2. 调用add方法进行add操作
/**
* 从尾部添加新节点的方法
* @param e
* @return
*/
public boolean add(E e) {
// 调用从尾部添加新节点的方法
linkLast(e);
return true;
}
3. linkLast() 从尾部添加新节点
/**
* 从链表尾部添加新节点
* @param e 要添加的新节点
*/
void linkLast(E e) {
// 将 last 尾部节点标记赋给辅助节点 l,last每次添加结束后会指向链表最后的一个节点
final Node<E> l = last;
// 调用内部类Node 将新创建的节点挂到 l 节点后面,e.next = null,e.prev = l,e.item = e
final Node<E> newNode = new Node<>(l, e, null);
// 将刚刚添加的新节点赋给尾部节点 last 标记该节点是尾节点,
// 此时last又指向了最后一个节点,L指向最后节点的前面一个节点
last = newNode;
// 判断 l 指向是否为空,如果 l 为空说明一开始 last 为空,则证明添加的节点是该链表的第一个节点。
if (l == null)
first = newNode; // 将头节点标记指向该节点
// 反之将尾节点 last 的前一个节点 l 指向新节点,完成了新节点在链表尾部的添加
else
l.next = newNode;
// 将链表实际长度加 1
size++;
// 将链表被修改的次数加 1
modCount++;
}
-
变量说明:
// 用于记录在链表中实际存储的元素个数,不参与序列化 transient int size = 0; // 用于记录链表被修改的次数,不参与序列化 protected transient int modCount = 0; -
内部类
/** * LinkedList集合的一个静态内部类,用于封装新创建的节点 */ private static class Node<E> { E item; Node<E> next; Node<E> prev; /** * 用于给新创建的节点 * @param prev 用于指向旧链表的尾节点 * @param element 存储新节点的数据 * @param next 指向下一个节点 */ Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }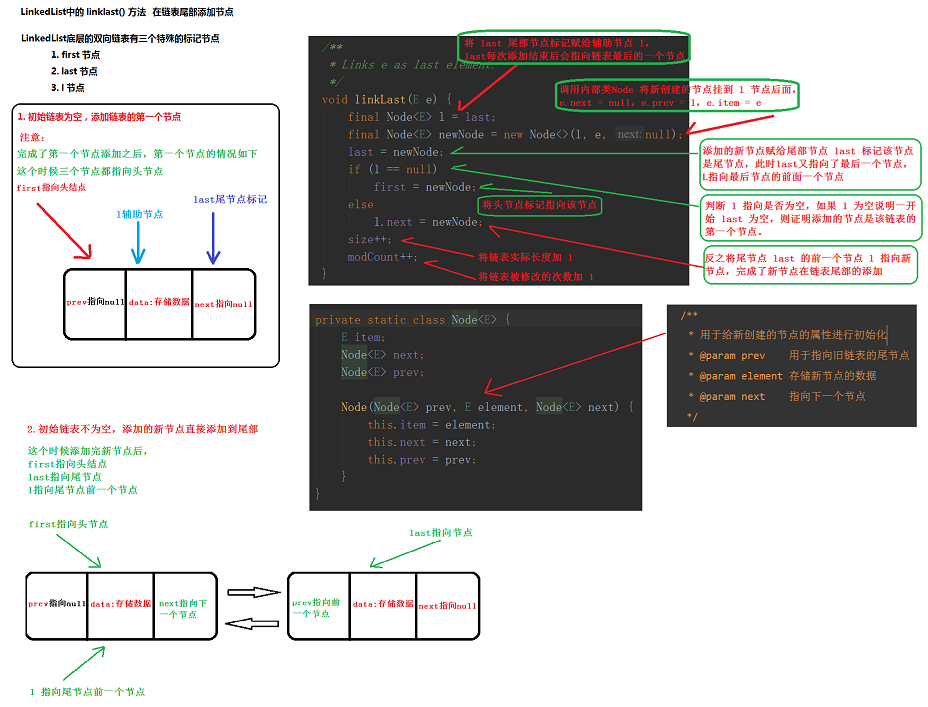
5. LinkedList三种添加节点的方法
1. 头插法
在链表的头部添加新的节点
对应方法:
linkFirst(存储的数据值)
2. 尾插法
在链表的尾部添加新的节点
对应方法:
linkLast(存储的数据值)
3. 在链表中间插入节点
对应方法:
add(指定位置的索引值, 存储的数据值)

