
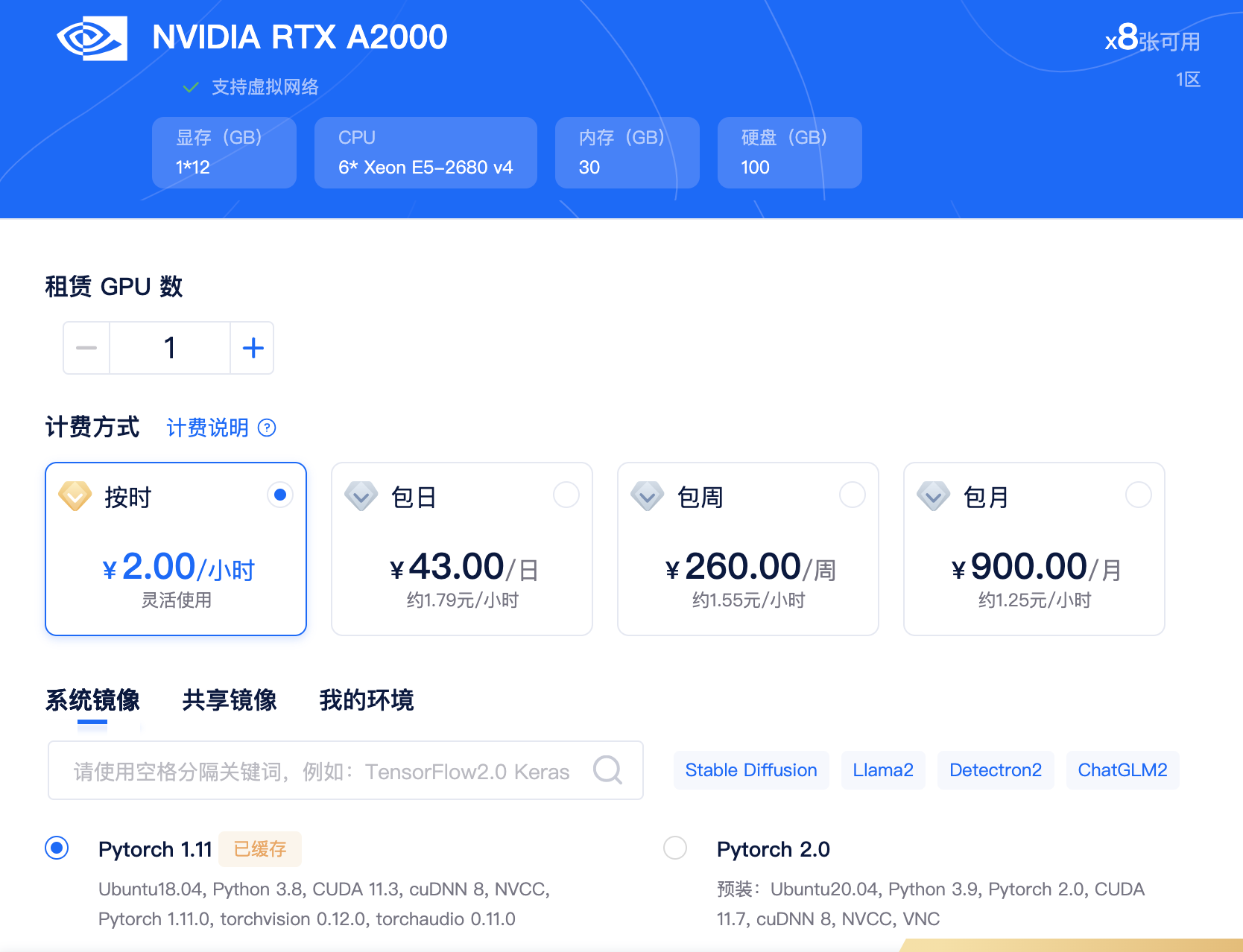
ChatGLM-6B-PT微调
开发环境
ChatGLM2-6B源码
git clone https://github.com/THUDM/ChatGLM2-6B.git
下载模型
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b-int4
安装依赖
cd ChatGLM2-6B
# 新建模型目录,将模型复制到model目录下
mkdir model
# 安装依赖
pip install -r requirements.txt -i https://mirror.sjtu.edu.cn/pypi/web/simple
# 运行微调除 ChatGLM2-6B 的依赖之外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets transformers[torch] -i https://pypi.douban.com/simple/
下载ADGEN数据集
微调前

cd ptuning
# 复制训练数据集到ptuning目录中
cp -r /mnt/AdvertiseGen .
# 微调训练
# 训练集目录 ptuning/AdvertiseGen/
# 模型目录 ChatGLM2-6B/model/
# 模型训练输出目录 ptuning/output/
# max_steps 最大训练步数
# save_steps 保存步骤数
# logging_steps 记录日志的频率
# quantization_bit 控制量化的精度
# pre_seq_len 预先设定的序列长度
# learning_rate 使用的学习率
# gradient_accumulation_steps 连续计算梯度的步数
torchrun --standalone --nnodes=1 --nproc-per-node=1 main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /home/ChatGLM2-6B/model/chatglm2-6b-int4 \
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 2e-2 \
--pre_seq_len 128 \
--quantization_bit 4
修改训练步数
torchrun --standalone --nnodes=1 --nproc-per-node=1 main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /home/ChatGLM2-6B/model/chatglm2-6b-int4 \
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 100 \
--logging_steps 10 \
--save_steps 50 \
--learning_rate 2e-2 \
--pre_seq_len 128 \
--quantization_bit 4
微调后
# 微调后
import os
import torch
from transformers import AutoConfig, AutoTokenizer, AutoModel
model_path = "model/chatglm2-6b-int4"
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 微调后代码
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained(model_path, config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join("/home/ChatGLM2-6B/ptuning/output/adgen-chatglm2-6b-pt--/checkpoint-3000", "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
model = model.half().cuda()
model.transformer.prefix_encoder.float()
model = model.eval()
# 使用 Markdown 格式打印模型输出
# from IPython.display import display, Markdown, clear_output
# def display_answer(model, query, history=[]):
# for response, history in model.stream_chat(
# tokenizer, query, history=history):
# clear_output(wait=True)
# display(Markdown(response))
# return history
# display_answer(model, "类型#上衣\*材质#牛仔布\*颜色#白色\*风格#简约\*图案#刺绣\*衣样式#外套\*衣款式#破洞")
prompt = "类型#上衣\*材质#牛仔布\*颜色#白色\*风格#简约\*图案#刺绣\*衣样式#外套\*衣款式#破洞"
# 模型输出
current_length = 0
for response, history in model.stream_chat(tokenizer, prompt, history=[]):
print(response[current_length:], end="", flush=True)
current_length = len(response)
print("")

本文作者:逢生博客
本文链接:https://www.cnblogs.com/wufengsheng/p/17735947.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步