


1 安装使用MongoDB
a) 下载MongoDB, 请注意,32bit只能存2GB的内容(32-bit builds are limited to around 2GB of data)。
b)配置好mongodb.config, 然后命令行:Mongod.exe --config /path/to/your/mongodb.config就可以了。
c) 下载pymongo, 后面用python来写测试程序。
请参阅:The Little MongoDB Book, (pdf)。
2 MapReduce
Map/reduce in MongoDB is useful for batch processing of data and aggregation operations. It is similar in spirit to using something like Hadoop with all input coming from a collection and output going to a collection. Often, in a situation where you would have used GROUP BY in SQL, map/reduce is the right tool in MongoDB.
参见MongoDB网站上对MapReduce的介绍。Map/reduce 流程如下:
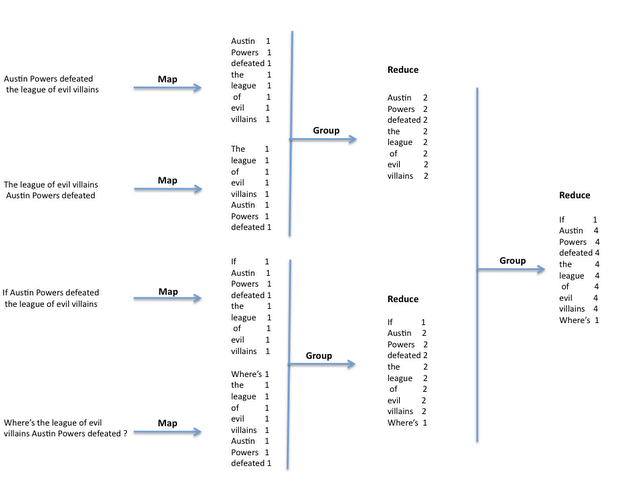
3 例子
以单词统计为例说明。输入文本是Obama的演讲词,可以看看里面里面单词的使用频率。如下图:

MongoDB 运行客户端用JS脚本。
Map程序为:

Reduce程序为:

客户端程序为:
from pymongo import Connection
from pymongo.code import Code
#'''
#Open a connection to MongoDb (localhost)
connection = Connection()
db = connection.test
#Remove any existing data
db.texts.remove()
#Insert the data
lines = open('2009-obama.txt').readlines()
[db.texts.insert({'text': line}) for line in lines]
#Load map and reduce functions
map = Code(open('wordMap.js','r').read())
reduce = Code(open('wordReduce.js','r').read())
#Run the map-reduce query
results = db.texts.map_reduce(map, reduce, "collection_name")
#Print the results
for result in results.find():
print result['_id'] , result['value']['count']
运行结果为:
文章代码可以在这里下载。

