
软件系统性能优化策略--SQL优化
非常感谢大家对《大白话系列之C#委托与事件讲解》的支持,这次我给大家带来的是《软件系统性能优化策略》的讲解,这个讲解分别围绕SQL优化、IIS优化、代码优化[BS架构]、数据库访问优化、缓存优化。
而这一篇中,我们就围绕SQL优化来开始这次讲解,为什么第一讲要说SQL优化?因为我认为这是程序员的基本功,而且也是我们必须要去掌握的,虽然你写的
SQL语句能完成相应的功能,但是你是否考虑过这些语句碰到海量数据或者暴力访问时会不会带来效率的大幅度的减慢?也许很多程序员和我一样在碰到系统响应时间过慢的时候,就会说:“怎么回事啦!服务器太破了,这么慢!”或者“网络怎么这么差的啦!”却很少抱怨自己编写的代码。其实这些细节也是我这次讲解的目的,希望大家在编写SQL语句时候,能看的更“远”,考虑的更“深”。
一、建立合适的索引
这里我不是想老生常谈“索引技术”,而是希望大家能重视“索引”,更希望大家能充分的理解“索引”,而不是仅仅停留在“主键就是索引”这样肤浅的认识上面。
首先我们大致了解什么是“索引”,在百度中打入“数据库索引是什么”,然后我们在百度百科中我们就能看到这样的解释
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
例如这样一个查询:select * from table1 where id=44。如果没有索引,必须遍历整个表,直到ID等于44的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),直接在索引里面找44(也就是在ID这一列找),就可以得知这一行的位置,也就是找到了这一行。可见,索引是用来定位的。
索引分为聚集索引和非聚集索引两种,聚集索引 是按照数据存放的物理位置为顺序的,而非聚集索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。
看完百度的解释,应该有了初步的了解,至于聚集索引和非聚集索引,大家可能还云里雾里的,其实你去问很多老程序员聚集索引和非聚集索引的区别时,他们的回答都是“去百度自己查去”,其实大家也不用去深究,可以理解成
1、聚集索引--字典里拼音查找,联想一下字典,当我们差找“金”时,我们会直接翻到"J"字母着去找,因为大家这本字典是按A-Z的排序去排列的,这个原理和数据库里的聚集索引很想,如果将一个索引设为聚集索引,那就说明这个字段是一定顺序排列的,而数据库表中也只能有一个聚集索引,多用在字段数据量大,但是相同值多的地方,打个比方像证劵公司,银行等系统的时间字段,因为这些系统一天里可能成交成千上万的数据,所以如果你在交易时间上设置聚集索引,那就说明当你查询“2010-3-16”的交易记录时,数据库将马上定位到这些记录上,不会去历遍这个数据表。
聚集索引经常使用的字段,分别为
a.使用运算符(如 BETWEEN、>、>=、 < 和 <=)返回一系列值
b.返回大型结果集。
c.使用 JOIN 子句;一般情况下,使用该子句的是外键列。
d.使用 ORDER BY 或 GROUP BY 子句。
2、非聚集索引--字典里笔画或偏旁查找,联想一下字典,当我们不知道一个字的读音“搳”,首先我们找偏帮,然后找到这个字的页码,最后找到这个字。在数据库字段中设置非聚集索引,那就说明,在这些字段中的记录中都有他们的索引地址,在查询记录时,就直接定位到该条记录。
探讨问题:
当我们在SQL2005中,给一个字段设置主键的时候,它会将这个主键默认设置成聚集索引,这样做有好处,就是可以让您的数据在数据库中按照ID进行物理排序,但是我觉的这并不是很合理,是对聚集索引的一种浪费。显而易见,聚集索引的优势是很明显的,而每个表中只能有一个聚集索引的规则,这使得聚集索引变得更加珍贵。从我们前面谈到的聚集索引的定义我们可以看出,使用聚集索引的最大好处就是能够根据查询要求,迅速缩小查询范围,避免全表扫描。在实际应用中,因为主键ID号是自动生成的,我们并不知道每条记录的ID号,所以我们很难在实践中用ID号来进行查询。这就使让ID号这个主键作为聚集索引成为一种资源浪费。
所以我觉得我们在对海量数据表的索引定义时要慎重!大家也可以对这个问题发表自己的意见。
最后我们回到出发点,我们为什么要设置索引?就是为了查询更迅速,快速呈现查询结果。有人会说在我们做的系统中,没有建索引速度也很快哦!那是你查询的数据量没有达到一个级别,一旦数据量达到百万级,你每写的一个不合理的SQL将会给你带来意想不到的麻烦。
记的我第一次认识到索引的重要性的时候,是在可口可乐公司工作的时候,当时我被分配到STM(冷柜快速投放系统)中,当时该系统的PHASE ONE 已经在全国7个厂房的生产环境使用,随着数据量一天天的累计,最后发现在一张KPI数据报表中,速度特别慢,而KPI报表都是可乐公司高层需要查看的,用来评估员工的工作效率,高层们当时就对我们的系统印象非常差,要知道在大公司一旦惹恼了高层,将在以后的很多活动中受限,当时我第一时间看了他们写的存储过程并且查看了数据库的数据量,报表I/O输出只有3000条左右,数据库也只有10W条左右的级别,这些都不可能让一个月的数据报表查询达到6分多钟的,然后我查看了这个KPI的存储过程,发现他们的在SELECT嵌套的时候,JOIN的表之间的主外键没有设置索引,导致他们的报表SQL嵌套是个乘积级数,也就是在嵌套语句中是一个全历遍过程。在我们刚查看这个存储过程的时候,我们都没有关注到只是索引的关系,还想了一大堆的方案,但是这些方案对原有的版本改动量太大,最后都夭折了。最后我们通过研究SQL的查询执行计划,发现嵌套查询中消耗的资源特别大,如下图:
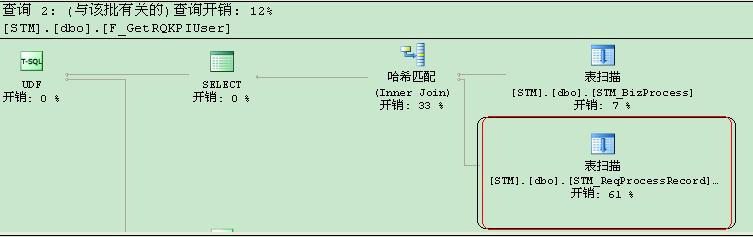
最后我们才发现原来是关联表的关联索引没建,当建完索引之后,从之前的6分钟减少到了6秒钟,这远远超过我们预期的期望,可想而知,没建索引之前,数据库做了多少的全历遍操作。
既然我们知道了索引的重要性,我们就要在日常的SQL编写的时候,尽量的不要破快索引,接下来我就列出几种导致索引失效的SQL写法
1、在索引字段中使用OR或者IN
例:Select * from table1 where id in (2,3) 或者 Select * from table1 where id=2 or tid=3
这些写法都会让id索引失效而引起全表历遍,当然当数据没有达到海量的时候,你爱这么写都可以,只要实现功能,一旦达到海量便一个细节决定成败
解决方案一:
Select * from table1 where id = 2 UNION Select * from table1 where id = 3
当然大家也可以用别的写法来实现功能。
注【上面的结论 是扯蛋的】
2、通配符%在字符串的开通使得索引无法使用
例:Select * from table1 where name like ‘%张’
如果在name字段设置索引,那这样的写法将导致索引失效
注:Select * from table1 where name like ‘张%’不会导致索引失效
3、非操作符将会引起索引无法使用
例:NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE等都会引起索引失效
二、限制物理I/O操作
事实上,在查询和提取超大容量的数据集时,影响数据库响应时间的最大因素并不是数据查找,而是物理的I/0操作。这时候我们在SQL语句编写中要注意2个问题
1、避免“SELECT *”操作
当我们写SQL语句时候,经常为了方便,我们用"SELECT * FROM TABLE" 。其实这是一个非常不好的习惯,当达到百万级的数据量之后,多一个字段,那将多N秒钟。
2、使用“TOP”进行数据提取
这是当我们查询海量数据的时候,假如查询结果是10W行,这时候我们就需要用真分页控件来进行分页,而我们用的原理就是TOP来实现的。
注:这些结论大家最好建张百万级的数据表来验证一下,毕竟动手操作过,将会有一个更清晰的概念。
在我们做一些统计或者报表的时候,80%的效率问题都是可以通过建立合理的索引和SQL来优化来解决,而且效果也是非常的明显。这次关于SQL的优化就讲到这里,其实还是很多很多其它方面需要注意的问题没有列举,这都需要我们在日常的编程中去细细的体会。
推荐文章
推荐2篇文章,是关于人生的

