
redis集群
什么是集群和分布式
一起干同样的事叫集群,分工合作的叫分布式。
集群
就是一群计算机集中到一起,他们都做同一件事,作为一个整体,向用户提供资源。每一个计算机就是一个集群中的节点,管理员可以配置这些节点。但是用户的是感觉不到节点的,感觉不到是很多计算机,用户感觉他就是一个网站 一个PC应用 一组服务 等。
理想的模式,服务器压力大了,配置上去一两个节点,分担压力,性能得以提升。
两大特性
· 可扩展性--集群的性能不限于单一的服务实体,新的服务实体可以动态地加入到集群,从而增强集群的性能。
· 高可用性--集群通过服务实体冗余使客户端免于轻易遇到out of service的警告。在集群中,同样的服务可以由多个服务实体提供。如果一个服务实体失败了,另一个服务实体会接管失败的服务实体。集群提供的从一个出 错的服务实体恢复到另一个服务实体的功能增强了应用的可用性。
两大能力
· 负载均衡--负载均衡能把任务比较均衡地分布到集群环境下的计算和网络资源。
· 错误恢复--由于某种原因,执行某个任务的资源出现故障,另一服务实体中执行同一任务的资源接着完成任务。这种由于一个实体中的资源不能工作,另一个实体中的资源透明的继续完成任务的过程叫错误恢复。
负载均衡和错误恢复都要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图(信息上下文)必须是一样的。
两大技术
· 集群地址--集群由多个服务实体组成,集群客户端通过访问集群的集群地址获取集群内部各服务实体的功能。具有单一集群地址(也叫单一影像)是集群的一个基 本特征。维护集群地址的设置被称为负载均衡器。负载均衡器内部负责管理各个服务实体的加入和退出,外部负责集群地址向内部服务实体地址的转换。有的负载均 衡器实现真正的负载均衡算法,有的只支持任务的转换。只实现任务转换的负载均衡器适用于支持ACTIVE-STANDBY的集群环境,在那里,集群中只有 一个服务实体工作,当正在工作的服务实体发生故障时,负载均衡器把后来的任务转向另外一个服务实体。
· 内部通信--为了能协同工作、实现负载均衡和错误恢复,集群各实体间必须时常通信,比如负载均衡器对服务实体心跳测试信息、服务实体间任务执行上下文信息的通信。
具有同一个集群地址使得客户端能访问集群提供的计算服务,一个集群地址下隐藏了各个服务实体的内部地址,使得客户要求的计算服务能在各个服务实体之间分布。内部通信是集群能正常运转的基础,它使得集群具有均衡负载和错误恢复的能力。
分布式
就是把任务细分到不同的服务器,(权限服务器 邮件服务器 文件服务器等等)
区别
1、分布式是指将不同的业务分布在不同的地方。 而集群指的是将几台服务器集中在一起,实现同一业务。
2、分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的。
3、分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率
推荐文章
http://blog.chinaunix.net/uid-7374279-id-4413214.html
http://blog.csdn.net/liuliufa/article/details/2103263
http://blog.csdn.net/u013142781/article/details/51307229
redis集群提供功能特点
1)在多个nodes间自动切分数据的能力(split)
2)当部分nodes失效时(或者nodes无法与其他nodes通信时),集群仍然可以继续操作
3)redis cluster3.0+可以支持1000个节点,在通常情况下,集群可能在10-20个节点,redis cluster设计的节点可以自动发现,failover,slave自动迁移等。
4)集群中每个redis实例都需要连个tcp端口,其中一个服务于客户端port,默认6379.另外一个为redis cluster bus端口。值为port+10000,如果port为6379那么bus就是16379。bus端口用于nodes通讯,此端口只对nodes集群有效。
windows端口
65535个 但是一般使到的也就是十几个,下面是一些常用端口简介:
1、公认端口(Well Known Ports):从0到1023,它们紧密绑定于一些服务。通常这些端口的通讯明确表明了某种服务的协议。例如:80端口实际上总是HTTP通讯。(系统预留)
2、注册端口(Registered Ports):从1024到49151。它们松散地绑定于一些服务。也就是说有许多服务绑定于这些端口,这些端口同样用于许多其它目的。例如:许多系统处理动态端口从1024左右开始。
3、动态和/或私有端口(Dynamic and/or Private Ports):从49152到65535。理论上,不应为服务分配这些端口。实际上,机器通常从1024起分配动态端口。但也有例外:SUN的RPC端口从32768开始
5)集群数据分片
Redis Cluster并没有使用一致性hash机制,但是使用了一种不同的sharding方式:hash slot(哈希槽);Cluster将会分配16384个slot(此值不可修改),对于指定的key,将会对key使用CRC16算法计算出long数值,然后对16384取模,即可得出此key所属的slot。那么集群中每个node都负责一部分slots,比如集群由A、B、C三个节点构成(3个masters):
1)A中的slots区间为:0~5500
2)B中的slots区间为:5501~11000
3)C中的slots区间为:11001~16383
hash slot机制很像存储层面的block,所以在集群中新增、移除nodes将变得简单。比如,我想添加一个新的node D,我只需要将A、B、C中的部分slots迁移到D上即可(而不是对集群中所有的数据重新resharding);同理,如果想移除节点A,只需要将A上的slots迁移到其他节点,此后即可将A从集群中移除。(言外之意,不需要resharding,而且对客户端透明)
由此可见,hash slots从一个node迁移到另一个node,或者增删节点,都不需要中断用户操作,集群仍可以正常服务。
我们知道Redis支持“multiple key”操作(即多个key的数据在一次调用中返回),那么Cluster也支持此特性,但是要求所有的keys需要在一个hash slot上(即在同一个node上),为了确保多个keys所属与同一个slot,则要求使用“hash tags”。
“hash tags”:Redis Cluster支持的特性,在key字符串中如果包含"{}",那么“{}”之间的字符串即为“hash tags”,客户端(包括Server端)将根据“hash tags”来计算此key所属的slots,而不是key完整的字符串,当然存储仍使用key。所以,有了“hash tags”,我们可以强制某些keys被保存在相同的slots:比如,“foo”和“{foo}.another”将会保存同一个slot上。这对“multiple key”操作非常有帮助。
6)集群节点的主备模式
当部分masters节点失效或者无法与大多数节点通讯时,为了能够保持集群的有效性,Redis Cluster通常使用Master-Slave模式,即一个Master节点通常需要一个或者多个slaves,通过replicas方式来提高可用性。
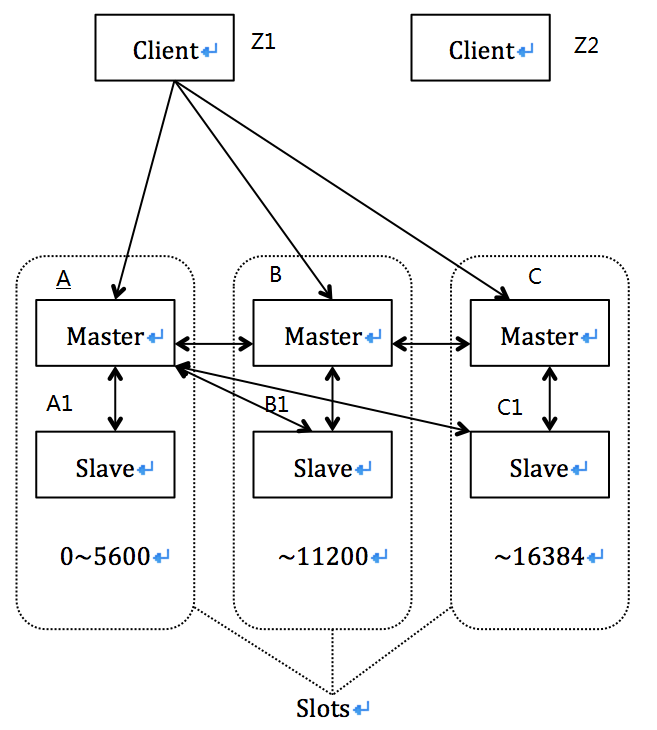
比如下图中的三个节点(在没有slaver情况下),如果B失效,那么集群将无法继续提供服务,因为“5501~11000”区间的slots完全“丢失”了。为了避免这种情况,我们通常需要为每个Master增加至少一个slave。比如A1、B1、C1分别为A、B、C的slave节点,那么当B失效时,B1可以被提升为master,接管B的服务,从而集群仍然可以继续操作。(不过,此后如果B1也失效,集群将不可用)
从集群的整体架构拓扑可知,Cluster并没有统一的Primary节点,也不存在所谓的集群单点问题。
7)数据一致性(主要就是主从切换的时候导致的)
Redis Cluster不能保证“强一致性”(strong consistency),即在实际使用中,某些情况下已经writes成功的数据(已经向客户端确认成功的)可能会丢失。
第一个原因就是Master与slaves之间采用异步复制的方式,这意味着那些在master上写入成功但尚未replicas到slave时,如果master失效,也意味着这些writes数据丢失了。
1)Client向A提交write操作
2)A写入成功且向Client返回“OK”。(此时客户端逻辑则认为write操作成功)
3)A将操作通过异步的方式replication到slave A1上。
上述过程中可见,A不会等到slave A1复制成功后才向Client返回确认消息;所以在2)过程之后如果A失效了,A1将会被提升为Master,那么A1上尚未复制的writes操作意味着丢失了。。。
Redis Cluster支持“同步复制”,即使用“WAIT”指令(即在write操作之后紧跟一个WAIT指令,表示此客户端等待,直到Master将write被同步给slave之后才返回确认消息),它可以降低数据丢失的可能性,但这仍然不是严格意义上的“强一致性”(通常是二阶段提交)。
还有另一种情况会导致writes丢失:网络分区,network partition。比如有6个节点A、B、C,以及其对应的slaves A1、B1、C1,以及Client端为Z1;此时网络分区导致“A,C,A1,B1,C1”、“B、Z1”,其中Z1与“B”在一个分区,且与第一个分区完全隔离,即客户端被隔离在一个小分区中。因为Z1认为B是Master,所以它将继续writes;集群中故障检测、判定以及failover都需要一定的时间量,在此时间内,Z1仍将writes操作发送给B,但是failover结束后,B1被提升为Master(B也在隔离指定时间后,切换为read only状态),但是因为网络分区导致B无法将数据同步给B1,所以在failover期间发生的writes将丢失。
这里引入一个“node timeout”配置参数,当node将链接中断超过timeout后,master将被认为失效,此后将有其中一个slave来替代。当然,如果在timeout超时后,没有master接管,那么整个集群将处于error状态,中断所有的write请求。
http://www.redis.cn/topics/cluster-tutorial.html
http://www.redis.cn/topics/cluster-spec.html
http://shift-alt-ctrl.iteye.com/blog/2284890
http://blog.csdn.net/ymr0717/article/details/51909225
http://blog.csdn.net/cywosp/article/details/23397179
redis集群配置文件
配置项默认在redis.windows.conf配置文件中


################################ REDIS CLUSTER ############################### # # ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ # WARNING EXPERIMENTAL: Redis Cluster is considered to be stable code, however # in order to mark it as "mature" we need to wait for a non trivial percentage # of users to deploy it in production. # ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ # # Normal Redis instances can't be part of a Redis Cluster; only nodes that are # started as cluster nodes can. In order to start a Redis instance as a # cluster node enable the cluster support uncommenting the following: # # cluster-enabled yes # Every cluster node has a cluster configuration file. This file is not # intended to be edited by hand. It is created and updated by Redis nodes. # Every Redis Cluster node requires a different cluster configuration file. # Make sure that instances running in the same system do not have # overlapping cluster configuration file names. # # cluster-config-file nodes-6379.conf # Cluster node timeout is the amount of milliseconds a node must be unreachable # for it to be considered in failure state. # Most other internal time limits are multiple of the node timeout. # # cluster-node-timeout 15000 # A slave of a failing master will avoid to start a failover if its data # looks too old. # # There is no simple way for a slave to actually have a exact measure of # its "data age", so the following two checks are performed: # # 1) If there are multiple slaves able to failover, they exchange messages # in order to try to give an advantage to the slave with the best # replication offset (more data from the master processed). # Slaves will try to get their rank by offset, and apply to the start # of the failover a delay proportional to their rank. # # 2) Every single slave computes the time of the last interaction with # its master. This can be the last ping or command received (if the master # is still in the "connected" state), or the time that elapsed since the # disconnection with the master (if the replication link is currently down). # If the last interaction is too old, the slave will not try to failover # at all. # # The point "2" can be tuned by user. Specifically a slave will not perform # the failover if, since the last interaction with the master, the time # elapsed is greater than: # # (node-timeout * slave-validity-factor) + repl-ping-slave-period # # So for example if node-timeout is 30 seconds, and the slave-validity-factor # is 10, and assuming a default repl-ping-slave-period of 10 seconds, the # slave will not try to failover if it was not able to talk with the master # for longer than 310 seconds. # # A large slave-validity-factor may allow slaves with too old data to failover # a master, while a too small value may prevent the cluster from being able to # elect a slave at all. # # For maximum availability, it is possible to set the slave-validity-factor # to a value of 0, which means, that slaves will always try to failover the # master regardless of the last time they interacted with the master. # (However they'll always try to apply a delay proportional to their # offset rank). # # Zero is the only value able to guarantee that when all the partitions heal # the cluster will always be able to continue. # # cluster-slave-validity-factor 10 # Cluster slaves are able to migrate to orphaned masters, that are masters # that are left without working slaves. This improves the cluster ability # to resist to failures as otherwise an orphaned master can't be failed over # in case of failure if it has no working slaves. # # Slaves migrate to orphaned masters only if there are still at least a # given number of other working slaves for their old master. This number # is the "migration barrier". A migration barrier of 1 means that a slave # will migrate only if there is at least 1 other working slave for its master # and so forth. It usually reflects the number of slaves you want for every # master in your cluster. # # Default is 1 (slaves migrate only if their masters remain with at least # one slave). To disable migration just set it to a very large value. # A value of 0 can be set but is useful only for debugging and dangerous # in production. # # cluster-migration-barrier 1 # By default Redis Cluster nodes stop accepting queries if they detect there # is at least an hash slot uncovered (no available node is serving it). # This way if the cluster is partially down (for example a range of hash slots # are no longer covered) all the cluster becomes, eventually, unavailable. # It automatically returns available as soon as all the slots are covered again. # # However sometimes you want the subset of the cluster which is working, # to continue to accept queries for the part of the key space that is still # covered. In order to do so, just set the cluster-require-full-coverage # option to no. # # cluster-require-full-coverage yes # In order to setup your cluster make sure to read the documentation # available at http://redis.io web site.
cluster-enabled <yes/no>
开启集群
cluster-config-file <filename>
cluster配置文件的名称,当集群信息发生变更时,node将会自动把这些信息持久化到此配置文件中,以便在启动时重新读取它。对于用户而言,通常不应该认为修改此文件内容(自动生成自动维护)。文件中会包含:集群中其他nodes信息、以及他们的状态,还有一些持久性的变量等。
cluster-node-timeout <毫秒数>
node在被认为失效之前,允许不可用的最长时间。如果Master处于“不可达”的时间超过此值,将会被failover(灾难转移 就是切换从数据库顶上来,做主数据库)。当然,每个node在此时间内不能与“多数派”nodes通讯,它也将终止接收writes请求,切换到read only模式。这个参数很重要,选择合适的值,对集群的有效性、数据一致性有极大影响。 ( 比如说设置为15000毫秒,则是失效时间超过15000毫秒 则进行failover)
cluster-slave-validity-factor <factor>
用于限定slave于master的失联时长的倍数;如果设置为0,slave总是尝试failover,不管master与slave之间的链接断开多久(即只要slave无法与master通讯,都会尝试进行failover;Cluster有选举机制,有可能会被否决);如果此值为正值,则失联的最大时长为:(node-timeout * slave-validity-factor) + repl-ping-slave-period,当失联时长超过此值后,slave触发failover。比如node timeout为5秒,factor为10,repl-ping-slave-period为10,那么当slave与master失联超过,60秒时,slave将会尽力尝试failover。此值需要合理设置,也会对集群有效性、数据一致性产生影响。
cluster-migration-barrier <count>
适用于“migration”架构场景;master需要保留的slaves的最少个数;如果一个master拥有比此值更多的slaves,那么Cluster将会使用“migration”机制,将多余的slaves迁移到其他master上,这些master持有的slaves的数量低于此值。最终Cluster希望做到,slaves能够按需迁移,在failover期间,确保每个master都有一定量的slaves,以提高集群整体的可用性。(比如A有三个slaves:A1、A2、A3,而B只有一个slave B1,当B失效后,B1提升为master,但是B1没有任何slave,所以存在风险,那么migration机制,可以将A下的某个slave迁移到B1下,成为B1的slave。)
cluster-require-full-coverage <yes/no>
“集群是否需要全量覆盖”,如果设置为yes(默认值),当集群中有slots没有被任何node覆盖(通常是由于某个master失效,但是它也没有slave接管时),集群将会终止接收writes请求;如果设置为no,集群中那些服务正常的nodes(slots)仍然可以继续服务。(也就是说一个点死掉了,是否要全部停止写工作。)
redis集群搭建
推荐 搭建过程
https://www.cnblogs.com/tommy-huang/p/6240083.html
Resharding
Resharding就是将数据重新分片,意味着我们可以将nodes上的部分slots迁移到其他nodes上,redis-trib辅助工具仍然可以帮助我们:
在slots重新分配的过程中,
1)需要输入允许迁移的slots数量,最终将有指定数量的slots被迁移到目标node上。
2)需要输入“Receiving”端的node ID,表示集群中哪个node接收slots,通常是新的node或者负载较小的node。
3)需要输入“Source”端的node ID,表示“指定数量的slots”将从哪些nodes上迁出;允许依次输入多个ID,输入“all”表示从所有nodes上(不包括Receiving端),“done”表示输入结束,开始执行reshard。
之所以“reshard”,原因就是Redis Cluster目前还没有提供“rebalance”机制,它不能自动平衡集群中每个节点上的slots分布,不过此特性将来会添加进去
自动Failover
如果需要人为的Failover,比如希望将某个Slave提升为Master,我们可以在指定的slave上使用“CLUSTER FAILOVER”指令即可。
新增节点
这是一个非常普遍的运维操作,我们将一个新的node添加到集群中,如果它是一个master节点,还可以将其他nodes上的部分slots迁移到此node上;当然也可以为现有的master新增slave节点。
移除节点
“del-node”指令可以将一个空的node移除集群,所谓空node就是此node上没有覆盖任何slots。如果你要移除一个master,那么首先需要将此节点上的所有slots迁移到其他nodes上(reshard指令),否则移除节点将会抛出错误。
副本迁移(migration)
我们也会经常遇到这样的需求,将某个master的其中一个slave迁移到其他master,即重新配置slave从属:
不过对于集群而言,有时候我们希望slave能够自动迁移到合适的master下,不需要人工干预,这种机制称为“副本迁移”(replicas migration)。
1)集群总是将slaves数量最多的master下的某个slave,迁移到slave个数最小的master下。即平衡每个master持有的slaves数量。
2)通常我们可以将多个slave随意加入集群,而不需要关注它们究竟归属哪个master;因为副本迁移机制,可以动态平衡它们。
3)配置参数“cluster-migration-barrier”用于限定每个master下应该保留的最少slaves个数,那么在副本迁移时,集群应该首先保证当前master下的slaves个数不低于此值。
https://www.cnblogs.com/tommy-huang/p/6240083.html
http://blog.csdn.net/u011342403/article/details/67629141
http://www.sohu.com/a/79200151_354963

