
SQL常用语句简单


USE [Test] GO /****** Object: Table [dbo].[Class] Script Date: 2017/6/29 13:17:14 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Class]( [ClassID] [int] NULL, [ClassName] [nvarchar](50) NULL ) ON [PRIMARY] GO /****** Object: Table [dbo].[Student] Script Date: 2017/6/29 13:17:14 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Student]( [StuID] [int] NOT NULL, [StuName] [nvarchar](50) NULL, [StuAge] [int] NULL, [ClassID] [int] NULL ) ON [PRIMARY] GO INSERT [dbo].[Class] ([ClassID], [ClassName]) VALUES (1, N'班级1') GO INSERT [dbo].[Class] ([ClassID], [ClassName]) VALUES (2, N'班级2') GO INSERT [dbo].[Class] ([ClassID], [ClassName]) VALUES (3, N'班级3') GO INSERT [dbo].[Class] ([ClassID], [ClassName]) VALUES (4, N'班级4') GO INSERT [dbo].[Class] ([ClassID], [ClassName]) VALUES (5, N'班级5') GO INSERT [dbo].[Class] ([ClassID], [ClassName]) VALUES (2, N'班级2') GO INSERT [dbo].[Student] ([StuID], [StuName], [StuAge], [ClassID]) VALUES (1, N'张三', 19, 1) GO INSERT [dbo].[Student] ([StuID], [StuName], [StuAge], [ClassID]) VALUES (2, N'李四', 18, 1) GO INSERT [dbo].[Student] ([StuID], [StuName], [StuAge], [ClassID]) VALUES (3, N'王五', 16, 2) GO INSERT [dbo].[Student] ([StuID], [StuName], [StuAge], [ClassID]) VALUES (4, N'啦啦', 20, 7) GO INSERT [dbo].[Student] ([StuID], [StuName], [StuAge], [ClassID]) VALUES (5, N'王五2', 16, 2) GO INSERT [dbo].[Student] ([StuID], [StuName], [StuAge], [ClassID]) VALUES (5, N'王五3', 16, 2) GO INSERT [dbo].[Student] ([StuID], [StuName], [StuAge], [ClassID]) VALUES (5, N'王五3', 16, 2) GO
一、排序
排序的可以产生序号,所以都可以分页查询
1、row_number() over(order by 字段)
SELECT *,ROW_NUMBER() OVER ( ORDER BY s.StuAge) FROM Student AS s
3 王五 16 2 1 5 王五2 16 2 2 5 王五3 16 2 3 5 王五3 16 2 4 2 李四 18 1 5 1 张三 19 1 6 4 啦啦 20 7 7
2、row_number() over(PARTITION BY 字段order by 字段) over中可以分区在编号
SELECT *,ROW_NUMBER() OVER ( PARTITION BY s.ClassID ORDER BY s.StuAge) FROM Student AS s
2 李四 18 1 1 1 张三 19 1 2 3 王五 16 2 1 5 王五2 16 2 2 5 王五3 16 2 3 5 王五3 16 2 4 4 啦啦 20 7 1
3、DENSE_RANK()出现 并列排序 (序号连续)
--DENSE_RANK()
SELECT *,DENSE_RANK() OVER ( ORDER BY s.StuAge DESC) FROM Student AS s
4 啦啦 20 7 1 1 张三 19 1 2 2 李四 18 1 3 3 王五 16 2 4 5 王五2 16 2 4 5 王五3 16 2 4 5 王五3 16 2 4
4、RANK() 出现并列排序(序号不连续)
--rank()
SELECT *,RANK() OVER (ORDER BY s.StuAge ) FROM Student AS s
3 王五 16 2 1 5 王五2 16 2 1 5 王五3 16 2 1 5 王五3 16 2 1 2 李四 18 1 5 1 张三 19 1 6 4 啦啦 20 7 7
5、NTILE(INT) 要把查询得到的结果平均分为几组
--NTILE 要把查询得到的结果平均分为几组,总数/组数=每组数量 --如果每组数量部位整数 则在第一组多加行 少的话在最后一组减 SELECT *,NTILE(3) OVER (ORDER BY s.StuAge DESC) FROM Student AS s
4 啦啦 20 7 1 1 张三 19 1 1 2 李四 18 1 1 3 王五 16 2 2 5 王五2 16 2 2 5 王五3 16 2 3 5 王五3 16 2 3
二、结果集合并
1、UNION
--UNION 去除两个表中重复的行
SELECT * FROM Student AS s UNION SELECT * FROM Student
1 张三 19 1 2 李四 18 1 3 王五 16 2 4 啦啦 20 7 5 王五2 16 2 5 王五3 16 2
2、UNION ALL
--UNION ALL 完全合并,不去除两个表中重复的行
SELECT * FROM Student AS s UNION ALL SELECT * FROM Student
1 张三 19 1 2 李四 18 1 3 王五 16 2 4 啦啦 20 7 5 王五2 16 2 5 王五3 16 2 5 王五3 16 2 1 张三 19 1 2 李四 18 1 3 王五 16 2 4 啦啦 20 7 5 王五2 16 2 5 王五3 16 2 5 王五3 16 2
三、GROUP BY产生高级汇总结果
https://msdn.microsoft.com/zh-cn/library/ms175939(v=sql.90).aspx
小计 合计
1、WITH CUBE(英文多维数据集) 生成的结果集显示了所选列中值的所有组合的聚合。
正常分组
select s.ClassID,s.StuAge,COUNT(1) FROM Class AS c inner JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY s.ClassID,s.StuAge
ClassID StuAge (无列名) 2 16 8 1 18 1 1 19 1
with cube 汇总
--只是在基于GROUP BY 子句创建和汇总分组的可能的组合上有一定差别,CUBE将返回的更多 --的可能组合。如果在GROUP BY子句中有N个列或者是有N个表达式的话,SQLSERVER在结果集 --上会返回2的N-1次幂个可能组合。 select s.ClassID,s.StuAge,COUNT(1) FROM Class AS c inner JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY s.ClassID,s.StuAge WITH CUBE
ClassID StuAge (无列名) 2 16 8 NULL 16 8 1 18 1 NULL 18 1 1 19 1 NULL 19 1 NULL NULL 10 1 NULL 2 2 NULL 8
select s.ClassID,s.StuAge,COUNT(1) FROM Class AS c inner JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY CUBE( s.ClassID,s.StuAge)
ClassID StuAge (无列名) 2 16 8 NULL 16 8 1 18 1 NULL 18 1 1 19 1 NULL 19 1 NULL NULL 10 1 NULL 2 2 NULL 8
select s.ClassID,s.StuAge,COUNT(1) FROM Class AS c inner JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY CUBE( s.ClassID),s.StuAge
ClassID StuAge (无列名) 2 16 8 NULL 16 8 1 18 1 NULL 18 1 1 19 1 NULL 19 1
2、WITH ROLLUP(英文汇总) 生成的结果集显示了所选列中值的某一层次结构的聚合
https://msdn.microsoft.com/zh-cn/library/ms189305(v=sql.90).aspx
ROLLUP就是将GROUP BY后面的第一列名称求总和,而其他列并不要求而CUBE则会将每一个列名称都求总和
select s.ClassID,s.StuAge,COUNT(1) FROM Class AS c inner JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY s.StuAge,s.ClassID WITH ROLLUP
ClassID StuAge (无列名) 2 16 8 NULL 16 8 1 18 1 NULL 18 1 1 19 1 NULL 19 1 NULL NULL 10
select s.ClassID,s.StuAge,COUNT(1) FROM Class AS c inner JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY s.ClassID,s.StuAge WITH ROLLUP
ClassID StuAge (无列名) 1 18 1 1 19 1 1 NULL 2 2 16 8 2 NULL 8 NULL NULL 10
四、GROUPING SETS和GROUPING函数
1、GROUPING SETS可以简化大量的UNION
插叙:
SQL统计函数https://docs.microsoft.com/zh-cn/sql/t-sql/functions/aggregate-functions-transact-sql
使用union合并
SELECT c.ClassName,NULL,COUNT(1) FROM Class AS c INNER JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY c.ClassName UNION SELECT NULL,s.StuAge,COUNT(1) FROM Class AS c INNER JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY s.StuAge
ClassName (无列名) (无列名) NULL 16 8 NULL 18 1 NULL 19 1 班级1 NULL 2 班级2 NULL 8
对应执行计划
使用grouping sets(列明,表达式,(列名1,列名2...)) 可以是列名 表达式,多个组合。
SELECT c.ClassName,s.StuAge,COUNT(1) FROM Class AS c INNER JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY GROUPING SETS(s.StuAge,c.ClassName)
ClassName StuAge (无列名) 班级1 NULL 2 班级2 NULL 8 NULL 16 8 NULL 18 1 NULL 19 1
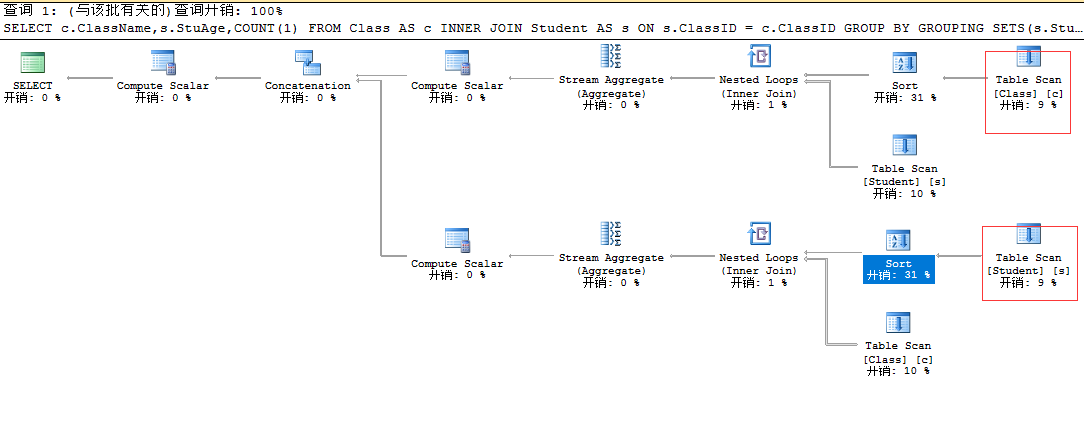
GROUPING SETS不仅仅只是语法糖.而是从执行原理上做出了改变.(可以查看这两者的执行计划,第二次表扫描增多,第一次少,但是前面就行union操作。)
2、grouping sets和grouping 联合使用
grouping(列名或者表达式) grouping(列名1,列名2...) 返回 0 1,必须和group by一起使用。参数必须在GROUPBY里面的
MSDN:Is a column or an expression that contains a column in a GROUP BY clause.
SELECT CASE WHEN GROUPING(c.ClassName)=0 THEN c.ClassName ELSE '空' end as ClassName,s.StuAge,COUNT(1) FROM Class AS c INNER JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY GROUPING SETS(s.StuAge,c.ClassName)
ClassName StuAge (无列名) 班级1 NULL 2 班级2 NULL 8 空 16 8 空 18 1 空 19 1
3、GROUPING_ID
GROUPING_ID (<column_expression> [ ,...n ]) 也可以是组合(根据groupingsets 里面的组合),作用:计算分组等级
SELECT s.StuAge,s.ClassID,COUNT(1),grouping_id(s.StuAge,s.ClassID) AS c FROM Student AS s GROUP BY cube(s.StuAge,s.ClassID) ORDER BY c
StuAge ClassID (无列名) c 18 1 1 0 19 1 1 0 16 2 4 0 20 7 1 0 16 NULL 4 1 18 NULL 1 1 19 NULL 1 1 20 NULL 1 1 NULL 2 4 2 NULL 1 2 2 NULL 7 1 2 NULL NULL 7 3
SELECT s.StuAge,s.ClassID,COUNT(1),grouping_id(s.StuAge) AS c FROM Student AS s GROUP BY cube(s.StuAge,s.ClassID) ORDER BY c
StuAge ClassID (无列名) c 18 1 1 0 19 1 1 0 16 2 4 0 16 NULL 4 0 18 NULL 1 0 19 NULL 1 0 20 NULL 1 0 20 7 1 0 NULL 7 1 1 NULL NULL 7 1 NULL 2 4 1 NULL 1 2 1
SELECT CASE WHEN GROUPING(c.ClassName)=0 THEN c.ClassName ELSE '空' end as ClassName,s.StuAge,COUNT(1),grouping_id(s.StuAge,c.ClassName) FROM Class AS c INNER JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY GROUPING SETS(s.StuAge,c.ClassName)
ClassName StuAge (无列名) (无列名) 班级1 NULL 2 2 班级2 NULL 8 2 空 16 8 1 空 18 1 1 空 19 1 1
SELECT CASE WHEN GROUPING(c.ClassName)=0 THEN c.ClassName ELSE '空' end as ClassName,s.StuAge,COUNT(1),grouping_id(s.StuAge) FROM Class AS c INNER JOIN Student AS s ON s.ClassID = c.ClassID GROUP BY GROUPING SETS(s.StuAge,c.ClassName)
ClassName StuAge (无列名) (无列名) 班级1 NULL 2 1 班级2 NULL 8 1 空 16 8 0 空 18 1 0 空 19 1 0
只有一个分组等级
SELECT s.StuAge,s.ClassID,COUNT(1),grouping_id(s.StuAge) AS c FROM Student AS s GROUP BY s.StuAge,s.ClassID ORDER BY c SELECT s.StuAge,s.ClassID,COUNT(1),grouping_id(s.StuAge,s.ClassID) AS c FROM Student AS s GROUP BY s.StuAge,s.ClassID ORDER BY c
两个sql结果一样
StuAge ClassID (无列名) c 18 1 1 0 19 1 1 0 16 2 4 0 20 7 1 0
思考:group 里面分组,
单一条件分组,group by 列1,列2

多项分组,例如 group by grouping sets(列1,列2,(列3,列4)),GROUP BY cube(s.StuAge,s.ClassID)
五、WITH AS 公用表表达式(CTE)(common table expression) 也叫做子查询部分
MSDN详解:https://docs.microsoft.com/zh-cn/sql/t-sql/queries/with-common-table-expression-transact-sql (还是这帮老外厉害)
http://wudataoge.blog.163.com/blog/static/80073886200961652022389/
1、语法格式
[ WITH <common_table_expression> [ ,n ] ]
<common_table_expression>::=
expression_name [ ( column_name [ ,n ] ) ]
AS
( CTE_query_definition )
如果WITH AS短语所定义的表名被调用两次以上,则优化器会自动将
WITH AS短语所获取的数据放入一个TEMP表里,如果只是被调用一次,则不会。而提示materialize则是强制将WITH AS
短语里的数据放入一个全局临时表里。很多查询通过这种方法都可以提高速度。
2、用法
DECLARE @cname NVARCHAR(50),@cclass NVARCHAR(50) SET @cname='%名%'; SET @cclass='%班级%'; WITH stu AS (SELECT * FROM Student AS s WHERE s.StuName LIKE @cname), claa AS (SELECT * FROM Class AS c WHERE c.ClassName LIKE @cclass) SELECT * FROM stu st INNER JOIN claa AS s ON st.ClassID =s.ClassID
--下面一句不能执行
SELECT * FROM claa
StuID StuName StuAge ClassID ClassID ClassName 8 名字8 8 1 1 班级1
3、递归
数据库脚本
USE [Test] GO /****** Object: Table [dbo].[Deparment] Script Date: 2017/6/30 11:23:18 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Deparment]( [ID] [int] NULL, [PID] [int] NULL, [Name] [nvarchar](50) NULL ) ON [PRIMARY] GO INSERT [dbo].[Deparment] ([ID], [PID], [Name]) VALUES (1, NULL, N'永赢基金') GO INSERT [dbo].[Deparment] ([ID], [PID], [Name]) VALUES (2, 1, N'人力资源') GO INSERT [dbo].[Deparment] ([ID], [PID], [Name]) VALUES (3, 1, N'财务部') GO INSERT [dbo].[Deparment] ([ID], [PID], [Name]) VALUES (4, 2, N'人力主管') GO INSERT [dbo].[Deparment] ([ID], [PID], [Name]) VALUES (5, 2, N'人力员工') GO INSERT [dbo].[Deparment] ([ID], [PID], [Name]) VALUES (6, 5, N'人力大员工') GO INSERT [dbo].[Deparment] ([ID], [PID], [Name]) VALUES (7, 5, N'人力小员工') GO INSERT [dbo].[Deparment] ([ID], [PID], [Name]) VALUES (8, 1, N'监察稽核部') GO
递归语句
WITH dep AS (SELECT *,0 AS DepLeavel FROM Deparment WHERE ID=1
UNION ALL
SELECT d.*,dtemp.DepLeavel+1 FROM dep AS dtemp INNER JOIN Deparment AS d ON d.PID=dtemp.ID
)
SELECT * FROM dep AS d OPTION (MAXRECURSION 3)
ID PID Name DepLeavel 1 NULL 永赢基金 0 2 1 人力资源 1 3 1 财务部 1 8 1 监察稽核部 1 4 2 人力主管 2 5 2 人力员工 2 6 5 人力大员工 3 7 5 人力小员工 3

