ES-IK分词器
一、安装
https://www.cnblogs.com/wudequn/p/11001382.html
https://github.com/medcl/elasticsearch-analysis-ik/(官方文档)
二、配置
IKAnalyzer.cfg.xml 这个是配置文件,其他的都是自带的分词文件。
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
将分词文件填入***.dic <entry key ="exyt_dict">my.dic<entry>中,在重启es。
或者
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">words_location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">words_location</entry>
其中location是指一个 url,比如http://*******,该请求只需满足以下两点即可完成分词热更新。
1、该 http 请求需要返回两个头部(header),一个是Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
2、该 http 请求返回的内容格式是一行一个分词,换行符用\n即可。
满足上面两点要求可实现热更新分词,不需要重启 ES 实例。
cd../bin
elasticsearch-plugin list 即可列出系统的插件三、测试
https://github.com/medcl/elasticsearch-analysis-ik/ (官网教程 要是跑不通就试试下面的)

mapping相当于指定表中字段 以及 字段类型。这时也可以指定分词。
https://blog.csdn.net/qinyuezhan/article/details/82463340 (mapping 详解)
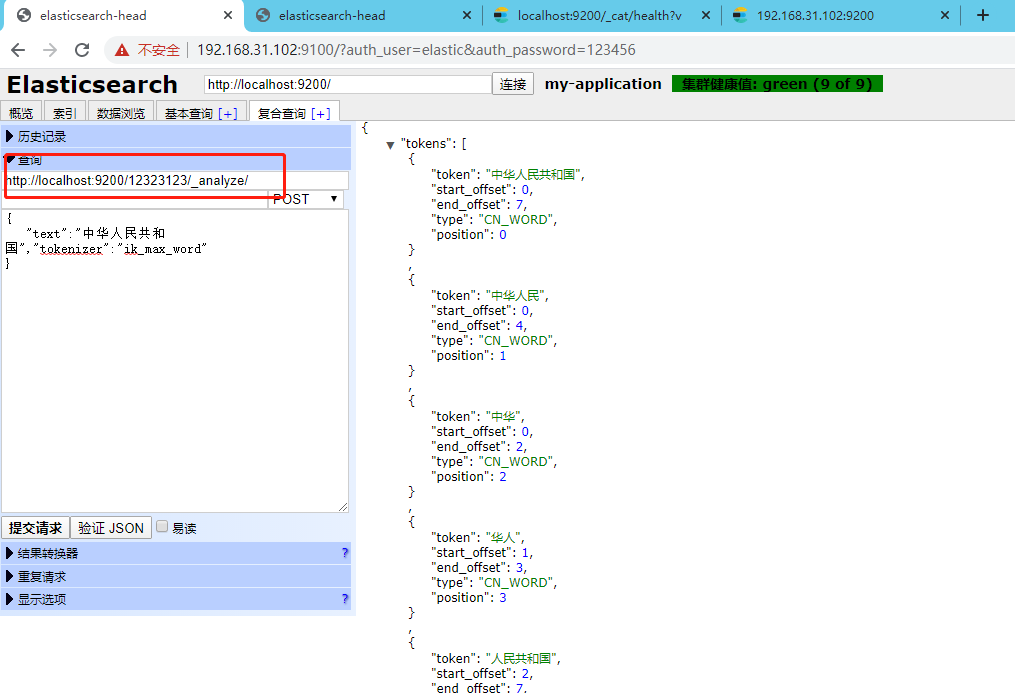
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
http://localhost:9200/这里是索引名称/_analyze/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号