模块的使用
一:什么是模块?
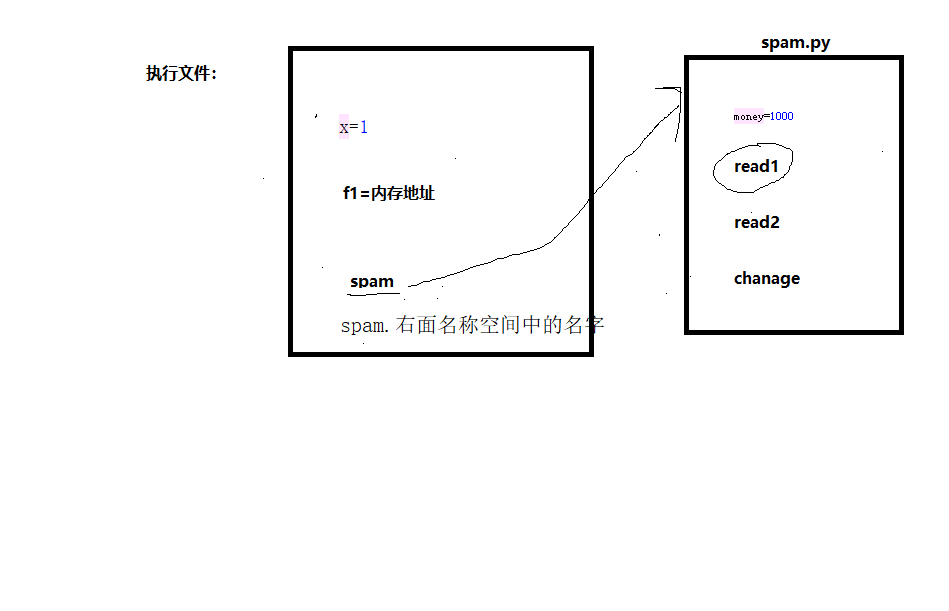
模块就是一系列功能的集合体,在python中,一个py文件就是一个模块
1、创建一个模块的名称空间
2、执行模块对应文件,将产生的名字存放于1中的名称空间
3、当前执行文件中拿到一个模块名,该模块名指向1的名称空间
def f1(): pass import spam # 强调:之后的导入会直接引用第一次导入的结果,不会重复执行文件 print(spam.money) spam.read1() # 模块中功能的执行始终以模块自己的名称空间为准 read1=111111 print(spam.read1) money=1111111 spam.change() print(money) spam.read1()
# 为模块起别名
import spam as sm
print(sm.money)
sm.read1()
engine=input('>>>:').strip()
if engine =='mysql':
import mysql as db
elif engine =='oracle':
import ocacle as db
db.parse()
print(help(parse()))
# 一行导入多个模块(不推荐使用)
# 推荐写成多行
import spam
import mysql
import orcacle
二:使用模块
import spam
from spam import money,read1,read2,change
print(money)
read1()
read2()
change()
import spam
print(money)
注意:
1.同import、执行模块中的功能,始终以模块的名称空间为准
money=11111111
change()
print(money)
# 2.from......import 名字,拿到的名字可以不加前缀直接使用,使用起来更加方便
# 当问题是容易与当前执行文件中相同的名字冲突
money=111111111111
print(money)
read1=1111111
read1()
# 起别名
from spam import money as m
print(m)
在一行导入多个
from spam import money,read1,read2
from.....import
from spam import
print(money)
print(read1)
print(read2)
print(change)
三:模块搜索路径
1、内存中已经加载的模块
2、内置模块
3、sys.path的路径中包含的模块
import time
import m1
m1.f1()
time.sleep(15)
import m1
m1.f1()
import sys
print('time'in sys.modules)
import time
time.sleep(2)
print('time' in sys.modules)
import sys
sys.path.append(r'/Users/ryan/PycharmProjects/ryan/4月3号/spam.py')
强调强调强调强调强调
sys.path的第一个路径是当前执行的文件所在的文件夹
# print(__name__)
# __name__的值
#1、在文件被直接执行的情况下,等于'__main__'
#2、在文件被导入的情况下,等于模块名
if __name__ == '__main__':
# print('文件被当中脚本执行啦。、。')
read1()
else:
print('文件被导入啦')
作业:
1、求文件a.txt中总共包含的字符个数?思考为何在第一次之后的n次sum求和得到的结果为0?
2、思考题
with open('a.txt',encoding='utf-8') as f:
g=(len(line) for line in f)
print(sum(g))
3、文件shopping.txt内容如下
mac,2000,3
lenovo,3000,10
tesla,1000000,10
chicken,200,1
求总共花了多少钱?
打印出所有的商品信息,格式为
[{'name':'xxx','price':'3333','count':3},....]
求单价大于10000的商品信息,格式同上
4、改写ATM作业,将重复用到的功能放到模块中,然后通过导入的方式使用
1. with open ('a.txt','r',encoding='utf-8')as f: print(list(len(line) for line in f)) 迭代器只能使用一次,需要再次赋值 2 因为文件没有关闭 3 with open('shopping.txt','r',encoding='utf-8')as f: info=[line.split(',')for line in f] cost=sum(float(price)*int(count)for *_,price,money in info) print(cost) g=[] with open('shopping.txt','r',encoding='utf-8')as f: for line in f: data=line.strip('/n').split(' ,') dic={'name':data[0],'price':data[1],'count':[2]} g.append(dic) print(g)
with open ('shopping.txt','r',encoding='utf-8')as f: g=(line.strip('\n').split(',')for line in f) info=[{'name':name,'price':int(price),'count':int(count)}for name ,price, count in g] apple=filter(lambda x:x['price']>10000,info) print(list(apple))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号