
python全栈开发day35-线程、协程
一、线程
1.线程
1)、什么是线程
线程是cpu调度的最小单位
线程是进程的必要组成单位
一个进程里至少含有一个线程
2)、主线程
程序开始运行的视乎,就产生了一个主线程来运行这个程序
3)、子线程
是由主线程开启的其他线程
4)、各线程之间的工作
异步的
数据共享的
5)、GIL Cpython全局解释器锁
Cpython解释器,在同一个进程中的多个线程,每次只能有一个线程可以获得执行CPU的权限。
这是由于Cpython的垃圾回收线程等原因导致
2.线程的开启
# 线程不能在外界的干扰下结束,而是等待程序的执行完毕才结束,主线程要等待子线程的结束而结束。


from threading import Thread,currentThread def t_func(): global n n -= 1 print(currentThread()) if __name__ == '__main__': n = 100 t_lst = [] for i in range(100): t = Thread(target=t_func) t.start() t_lst.append(t) print(t.ident,t.name,t.is_alive()) for t in t_lst:t.join() print(n)
3.守护线程
# 守护线程,会等待主线程执行完毕才结束,主线程会等待所有子线程结束而结束。
from threading import Thread,currentThread,active_count,enumerate import time def func1(): time.sleep(3) print('in func1') def func2(): while True: time.sleep(0.5) print('in func2') if __name__ == '__main__': Thread(target=func1).start() t = Thread(target=func2, daemon=True) # t.setDaemon(True) # t.daemon = True t.start() # print(enumerate()) # print(active_count()) # print(currentThread()) # print(t.getName()) # print(t.setName('zzz')) # print(t.getName()) print('主线程') # 守护线程:会等待主线程执行完毕而结束,主线程会等待所有子进程结束后才结束
4.锁
区别GIL和锁,GIL只是同进程中的不同线程只能有一个线程访问CPU,而互斥锁,是保障数据安全的一种机制,二者不冲突。
from threading import Lock,RLock,Thread # 数据不安全实例,由于global数据共享,导致两个线程可能仅计算完+8,还未写入,就被另一个线程抢到执行 # 权限被赋值为0 # def change_balance(n): # global balance # balance += n # balance -= n # # # def run_thread(n): # for i in range(150000): # change_balance(n) # # # balance = 0 # t1 = Thread(target=run_thread, args=(5,)) # t2 = Thread(target=run_thread, args=(8,)) # t1.start() # t2.start() # t1.join() # t2.join() # print(balance) # 加锁 保障数据安全 def change_balance(n): global balance balance += n balance -= n def run_thread(n): for i in range(150000): with lock:change_balance(n) balance = 0 lock = Lock() t1 = Thread(target=run_thread, args=(5,)) t2 = Thread(target=run_thread, args=(8,)) t1.start() t2.start() t1.join() t2.join() print(balance)
5.死锁和递归锁
互斥锁和递归锁的区别:
#互斥锁在同一个线程中连续acquire一次以上就会死锁
#递归锁在同一个线程中可以连续的acquire多次而不发生死锁
#普遍:递归锁可以代替互斥锁来解决死锁现象
#实际上:递归锁的解决死锁实际上是牺牲了时间和空间的
# 死锁从本质上来说是一种逻辑错误
# 递归锁没有从根本上解决死锁问题
递归锁画图描述:
from threading import Lock # 互斥锁 # lock = Lock() # lock.acquire() # print(123) # lock.release() from threading import RLock # 递归锁 # lock = RLock() # lock.acquire() # lock.acquire() # print(123) # lock.release() # 死锁 # 科学家吃面问题 # import time # from threading import Thread,Lock # # def eat1(name,fork_lock,noodle_lock): # fork_lock.acquire() # print('%s拿到叉子了'%name) # noodle_lock.acquire() # print('%s拿到面条了' % name) # print('%s吃面'%name) # noodle_lock.release() # fork_lock.release() # # def eat2(name,fork_lock,noodle_lock): # noodle_lock.acquire() # print('%s拿到面条了' % name) # time.sleep(1) # fork_lock.acquire() # print('%s拿到叉子了' % name) # print('%s吃面'%name) # fork_lock.release() # noodle_lock.release() # # fork_lock = Lock() # noodle_lock = Lock() # Thread(target=eat1,args=('alex',fork_lock,noodle_lock)).start() # Thread(target=eat2,args=('wusir',fork_lock,noodle_lock)).start() # Thread(target=eat1,args=('yuan',fork_lock,noodle_lock)).start() # Thread(target=eat2,args=('jin',fork_lock,noodle_lock)).start() # 递归锁解决死锁现象 # import time # from threading import Thread,RLock # # def eat1(name,fork_lock,noodle_lock): # fork_lock.acquire() # print('%s拿到叉子了'%name) # noodle_lock.acquire() # print('%s拿到面条了' % name) # print('%s吃面'%name) # noodle_lock.release() # fork_lock.release() # # def eat2(name,fork_lock,noodle_lock): # noodle_lock.acquire() # print('%s拿到面条了' % name) # time.sleep(1) # fork_lock.acquire() # print('%s拿到叉子了' % name) # print('%s吃面'%name) # fork_lock.release() # noodle_lock.release() # # noodle_lock = fork_lock = RLock() # Thread(target=eat1,args=('alex',fork_lock,noodle_lock)).start() # Thread(target=eat2,args=('wusir',fork_lock,noodle_lock)).start() # Thread(target=eat1,args=('yuan',fork_lock,noodle_lock)).start() # Thread(target=eat2,args=('jin',fork_lock,noodle_lock)).start() # import time # from threading import Thread,RLock # # def eat1(name,lock): # lock.acquire() # print('%s拿到叉子了'%name) # print('%s拿到面条了' % name) # print('%s吃面'%name) # lock.release() # # def eat2(name,lock): # lock.acquire() # print('%s拿到面条了' % name) # time.sleep(1) # print('%s拿到叉子了' % name) # print('%s吃面'%name) # lock.release() # # noodle_fork_lock = Lock() # Thread(target=eat1,args=('alex',noodle_fork_lock)).start() # Thread(target=eat2,args=('wusir',noodle_fork_lock)).start() # Thread(target=eat1,args=('yuan',noodle_fork_lock)).start() # Thread(target=eat2,args=('jin',noodle_fork_lock)).start() # 互斥锁和递归锁的区别 ***** # 互斥锁在同一个线程中连续acquire一次以上就会死锁 # 递归锁在同一个线程中可以连续的acquire多次而不发生死锁 # 普遍 :递归锁可以代替互斥锁来解决死锁现象 # 实际上 : 递归锁的解决死锁实际上是牺牲了时间和空间的 **** # 死锁从本质上来讲是一种逻辑错误 # 递归锁没有从根本上解决死锁问题
6.事件
event.isSet():返回event的状态值;
event.wait():如果 event.isSet()==False将阻塞线程;
event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度;
event.clear():恢复event的状态值为False。
from threading import Thread,Event,currentThread import time,random def check_mysql(): print('\033[45m[%s]正在检查mysql' % currentThread().getName()) time.sleep(random.randint(0,2)) event.set() def conn_mysql(): count = 1 while not event.is_set(): if count > 3: raise TimeoutError('链接超时') print('%s第%s次尝试链接' %(currentThread().getName(),count)) time.sleep(0.5) count += 1 print('<%s>连接成功' % currentThread().getName()) if __name__ == '__main__': event = Event() check = Thread(target=check_mysql) conn1 = Thread(target=conn_mysql) conn2 = Thread(target=conn_mysql) check.start() conn1.start() conn2.start()
7.定时器
# 可以定时多少时间后开始执行线程中的任务。
from threading import Timer,Thread,currentThread def func(n): print('in func', currentThread().getName(),'args%s'%n) t = Timer(3,func,args=(1,)) t.start() print(currentThread().getName())
from threading import Timer,Thread,currentThread import time def func(n): print('in func', currentThread().getName(),'args%s'%n) t = Timer(3,func,args=(1,)) t.start() time.sleep(1) print(t.is_alive()) print(currentThread().getName())
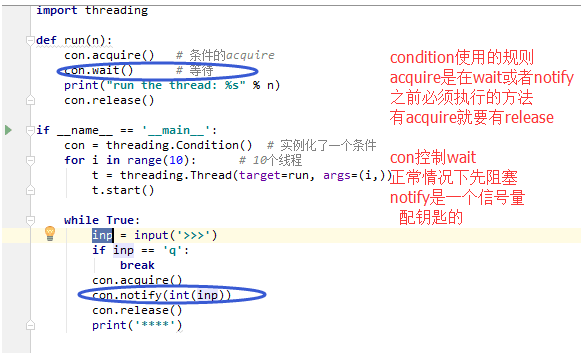
8.条件
# 一次放行多少个线程,放完就没有了,顺序通过,
# 在acquire()和release必须一一对应,wait或notify之前必须有acquire()
from threading import Condition,Thread def func(n): con.acquire() con.wait() print('run the thread %s' % n) con.release() if __name__ == '__main__': con = Condition() for i in range(10): t = Thread(target=func,args=(i,)) t.start() while True: inp = input('>>>') if inp == 'q': break con.acquire() con.notify(int(inp)) con.release()
9.队列(和threading模块没关系了)
Queue(),PriorityQueue(),LifoQueue()
import queue # q = queue.Queue() # 先进先出队列,维护先进先出顺序 # q.put(2) # q.put(3) # q.put(4) # print(q.get()) # print(q.get()) # print(q.get()) # q = queue.LifoQueue() # 后进先出队列,栈 # q.put(2) # q.put(3) # q.put(4) # print(q.get()) # print(q.get()) # print(q.get()) q = queue.PriorityQueue() # 优先级队列,优先级相同,根据ascii码先后 q.put((10, 2)) q.put((20, 3)) q.put((1, 4)) q.put((100, 'b')) q.put((100, 'a')) print(q.get()) print(q.get()) print(q.get()) print(q.get()) print(q.get())
10.池
multiprocessing中的Pool:
# apply_async 异步提交任务
# 必须close join之后才能维护主进程和进程池之间的同步
# map自带close、join效果
# 获取执行结果get
# 回调函数 指定callback参数,由主进程执行
concurrent.futures.ThreadPoolExecutor/concurrent.futures.ProcessPoolExecutor
# submit 异步提交任务
# 使用shutdown来维护主进程和进程池之间的同步
# map是不自带shutdown
# 获取执行结果用result
# 回调函数 直接调用add_done_callback方法,由子线程/子进程执行
# 用concurrent.futures,可以轻松的在进程和线程之间切换(代码改个名字即可)
#并发程序,线程池进程池都要用,只需要导入一个模块
# concurrent.futures模块是一个新的模块,同意了线程池和进程池的使用方式,对一些操作进行了更合理的规划。
二、协程
1)、协程--纤程,本质是线程的一部分
2)、对比线程和协程
# 线程,正常的线程,遇到阻塞就停下来,直到阻塞事件结束,才继续执行
# 协程,利用了协程,就把线程分成了好几段,在一个任务出现阻塞的时候,自动切换到另一任务去执行,这些事情在一个线程里面完成。
3)、如果这个程序从头到尾没有IO,没有阻塞,程序根本就不会在多个任务之间切换,就是一个顺序执行的协程,对于高计算型的代码没有用。
4)、协程
# 数据安全的问题不存在了
# 如何调度的呢?
# 操作系统不调度协程
# 用户级别来调度的gevent
# 协程的调度速度比线程还快
# 协程的调度由于是python代码级别而不是操作系统级别,所有用户的可控性更强,降低了操作系统的工作量。
5)、协程到底是怎么实现程序之间的切换的
生成器:
def func(): print(123) yield 1 print(456) yield 2 print(789) yield 3 def wahaha(g): for i in g: print(i) g = func() wahaha(g)
协程之间的切换:gevent依赖greenlet,协程之间的切换有greenlet完成
# def func(): # print(123) # yield 1 # print(456) # yield 2 # print(789) # yield 3 # # # def wahaha(g): # for i in g: # print(i) # # g = func() # wahaha(g) # 协程之间的切换 from greenlet import greenlet def eat(name): print('%s eat 1' %name) g2.switch('egon') print('%s eat 2' %name) g2.switch() def play(name): print('%s play 1' %name) g1.switch() print('%s play 2' %name) g1 = greenlet(eat) g2 = greenlet(play) g1.switch('alex')
from gevent import monkey monkey.patch_all() import time import gevent # 能够在遇到自己认识的IO操作的时候主动调用greenlet中的switch来切换到其他的任务以提高程序的效率 from threading import currentThread def eat(name): print(currentThread()) print('%s eat 1' %name) time.sleep(2) print('%s eat 2' %name) def play(name): print(currentThread()) print('%s play 1' %name) time.sleep(1) print('%s play 2' %name) g1=gevent.spawn(eat,'egon') # 就是发布了任务 g2=gevent.spawn(play,name='egon') # 就是发布了任务 # g1.join() # 等待g1任务执行完毕,阻塞,帮助你完成g1中函数的全部内容 # g2.join() gevent.joinall([g1,g2]) print('主')
# 效率对比 from gevent import spawn, joinall, monkey; monkey.patch_all() import time def task(pid): time.sleep(0.5) print('Task %s done' % pid) def synchronous(): # 同步 for i in range(10): task(i) def asynchronous(): # 异步 # g_l = [] # for i in range(10): # g = spawn(task,i) # g_l.append(g) # for g in g_l:g.join() # joinall(g_l) joinall([spawn(task, i) for i in range(10)]) if __name__ == '__main__': # print('Synchronous:') # synchronous() print('Asynchronous:') asynchronous()
# 解决并发问题???
# 多进程 高计算型,浪费操作系统和资源,可以利用多核
# 多线程 高IO型,也会给操作系统添加负担,会占用比进程少的资源,
# 受到GIL,不能利用多核
# 协程 高IO型,完全不会给操作系统添加负担,几乎不占资源
# 始终不能利用多核
# 多进程 + 多线程 = 100
# 多进程 + 多线程 + 协程 = 50000/4c
# 4c
# 多进程 CPU+1 = 5
# 多线程 CPU*5 = 20
# 协程 500个协程
