

软工个人阅读作业2
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2021春北航计算学院软件工程(罗杰 任健) |
| 这个作业的要求在哪里 | 作业要求 |
| 我在这个课程的目标是 | 提升代码能力,掌握工程化方法 |
| 这个作业在哪个具体方面帮助我实现目标 | 了解软件工程理论知识,掌握持续集成/持续部署工具 |
一、阅读提问
单元测试应该产生可重复、一致的结果......单元测试的运行/通过/失败不依赖于别的测试,可以人为构造数据,以保持单元测试的独立性。
Q1:书中的说法是否过于绝对?当针对多线程尤其是死锁等偶发性的问题进行测试时如何保证单元测试可重复性?另外,进行压力测试时,单元测试的运行会依赖别的测试,显然不满足书中所说条件,那我们难道就不测了吗?
我认为,书中说的单元测试应当产生可重复、一致的结果主要是便于程序员溯源问题,问题不一定真的要每次都可以复现。对于这类不可复现的问题,测试人员应当及时调取相关的日志文件并保存下现场(例如记录发生死锁的线程编号或者引起系统崩溃时的资源占用率),并且撰写出bug文档返回给开发人员进行修改,这样开发人员即使无法复现问题,但是可以通过测试人员提供的信息来改正错误。
项目/任务有多大?说到项目的大小,一般用代码行数来表示......也可以用小时、天、月、年来表示......也可以用re-work(返工)的次数来表示
Q2:项目/任务的大小应当由什么指标来决定?我认为书中的答案只在特定前提下才能够很好的衡量工作量。
以上学期的编译课设为例,有的同学编译器代码只有3000+行,而有的同学代码量则达到了7000+行,能说后者的工作量是前者的两倍吗?显然不行。由于每个人采用的算法不同、架构不同,会导致代码行数有所差异,用代码量衡量会有失偏颇。此外,用工作时长和返工的质量也会由于个体能力水平的差异而导致评价结果不够客观。书中的比较方法只有在团队中各成员代码水平相差不大、采用的工程架构以及主要算法相同时才比较好用。
我认为,要衡量工作量,应当由专门的评估人员通过经验来评估误差比较小。产生这样的想法,是从英美法系获得的灵感。英美法系又称为判例法系,法官判决时主要根据过去对于类似案件的判决情况进行宣判。在软件企业中,对于大部分的工程企业都曾经接手过类似的项目,有经验的管理人员对于项目的前端、后端等各部分工作量的占比都应当大致有所了解,因此,在工作量评估时只需要根据已有的经验来评估工作量即可。而对于以前没有接手过的工程项目,可以成立一个类似陪审团的、具有丰富软件开发经验的小组,由程序员阐述工作量,由陪审小组来裁决该程序员对自身工作量的定位和描述是否准确。
软件团队和客户代表要在需求阶段把这些问题(指对产品功能性的需求、对产品开发过程的需求、非功能性的需求、综合需求)给搞清楚。
Q3:能在需求阶段就把这些问题都搞清楚当然最好,但是实际情况往往是用户并不了解自己的需求,或者软件团队无法准确获取用户在表述中隐含的需求,此时应当怎么办?
我认为,解决这类问题的一个办法是首先构建一个满足用户最基础要求的最小化版本并交给用户试用,让用户边试用边反馈,根据用户的反馈进行开发;当然,也可以让用户在客户经理的身边进行试用,一旦找不到某个界面或者某个功能就及时反馈给客户经理。而软件团队在构建最小化版本时一定要注意代码架构的可扩展性,预留好足够的接口为后续的迭代开发做好准备。
我平时接触的同学都说计算机专业的,我平时上的网站都geek味或者hacker味十足......原来我并不了解海量中国用户,原来真实的用户并不是我想象的那样。我不理解为什么360的装机量那么大,但实际上有海量的用户不懂得如何管理电脑软件;我不理解为什么hao123能有那么大影响,但实际上有海量的用户并不会直接输入常用网站的网址;我不理解为什么那么多人愿意在QQ上为虚拟形象付费,但实际上有许多年轻女孩愿意花钱来为自己在社交平台上的形象打扮。
Q4:这个人不了解大多数用户的需求是因为他本人是计算机专业的,他周围接触的人大多都是计算机领域的,因此他认为的用户和实际情况相去甚远。而企业做调研报告的时候,回收的样本往往也会由于回收样本的群体不同而使得结果产生偏差。怎样尽量减少偏差?
上述现象在统计学上被称为选择性偏差,它指的是在研究过程中因样本选择的非随机性而导致得到的结论存在偏差,包括自选择偏差和样本选择偏差。而企业在做调研时,会发现无论是通过何种形式(包括纸质问卷,网络问卷,用户评价)得到的结果都会存在偏差,这是由于倾向于通过该种形式来返回结果的用户群体总是有共同点的(例如家庭主妇更加倾向于通过邮寄纸质问卷来回复,而年轻人更倾向于在网上进行评论来回复),这样子就不可避免地导致由于反馈群体的差异而使得到的结果存在偏差。
那怎么解决这个问题呢?我认为,要解决这个问题,我们必须要明白一件事——设计出的软件不是为每个人服务的,是对特定群体服务的,一个软件只要让大部分用户满意它就是一个成功的软件。我们收集调研结果并不是为了像国家统计局统计数据一样要求尽可能的准确、覆盖每一位被调查的对象,我们主要是针对特定的用户群体。因此,我们就应该让我们调研的反馈群体存在偏差,而且其中来自我们主要受众的占比越高越好。这样,我们得到的反馈结果也许不够客观,但是会更有利于软件后续的迭代。
PM(Program Manager)和大家平等工作,推动团队完成软件的功能......一个团队可以有很多PM......PM管事不管人。
Q5:PM没有领导权,会不会导致团队里的开发者偷懒?PM的工作分配很难做到平均,由于不存在领导关系,所以难以有效管理?创新不仅需要个人魄力,还需要有权力才能推动?
PM没有领导权,这就意味着他分配的工作不一定能被有效执行,如何把控好进度?如果工作分配不均,内部团队不和睦该如何解决?如果团队不和睦的话会与初衷背道而驰。此外,如果有创新或者革命性的工作,如果主张改革的人没有权力则难以冲破重重阻力推动创新的产品落实。
我认为,这种管理模式只适用于内部人员关系和睦,整体素质较高的团队。在这样的团队里每个成员都有自己的追求,在PM阐述清楚创新的利弊后愿意接受新的想法并进行尝试。
二、调研源代码版本管理软件
本博客中主要讨论github、gitlab、Bitbucket的异同点。
1.相同点
- 都使用git这一源代码管理系统
- 都有拉取请求、代码审查、内联编辑、问题跟踪、Markdown支持、双向认证、fork/clone等功能
- 都支持通过第三方服务扩展功能,提供了功能丰富的API
2.不同点
| GitHub | GitLab | Bitbucket | |
|---|---|---|---|
| 导入种类 | 支持导入Git,SVN,HG,TFS | 支持导入Git | 支持导入Git,CodePlex,Google Code,HG,SourceForge,SVN |
| 大小限制 | 项目不能超过 1 GB,单个文件不能超过 100 MB | 每个存储库有 10GB 的空间限制 | 当项目即将达到 1GB 时,会有邮件通知 |
| 收费策略 | GitHub 的企业版起价为 $2500 /10人,每年计费一次 | 收费为$10 /10人,每年收费一次 | 每位用户$39 ,对用户数没有限制,每年收费一次 |
三、调研持续集成/部署工具
1.Gitlab CI
-
使用 oo-2020 pre2task4 的内容,本地用 maven 创建 project,并编写一个简易的 JUnit4 测试
-
编写.gitignore文件,让git忽略idea自带的工程文件
-
配置 Gitlab CI,上传到 Gitlab仓库 触发 CI
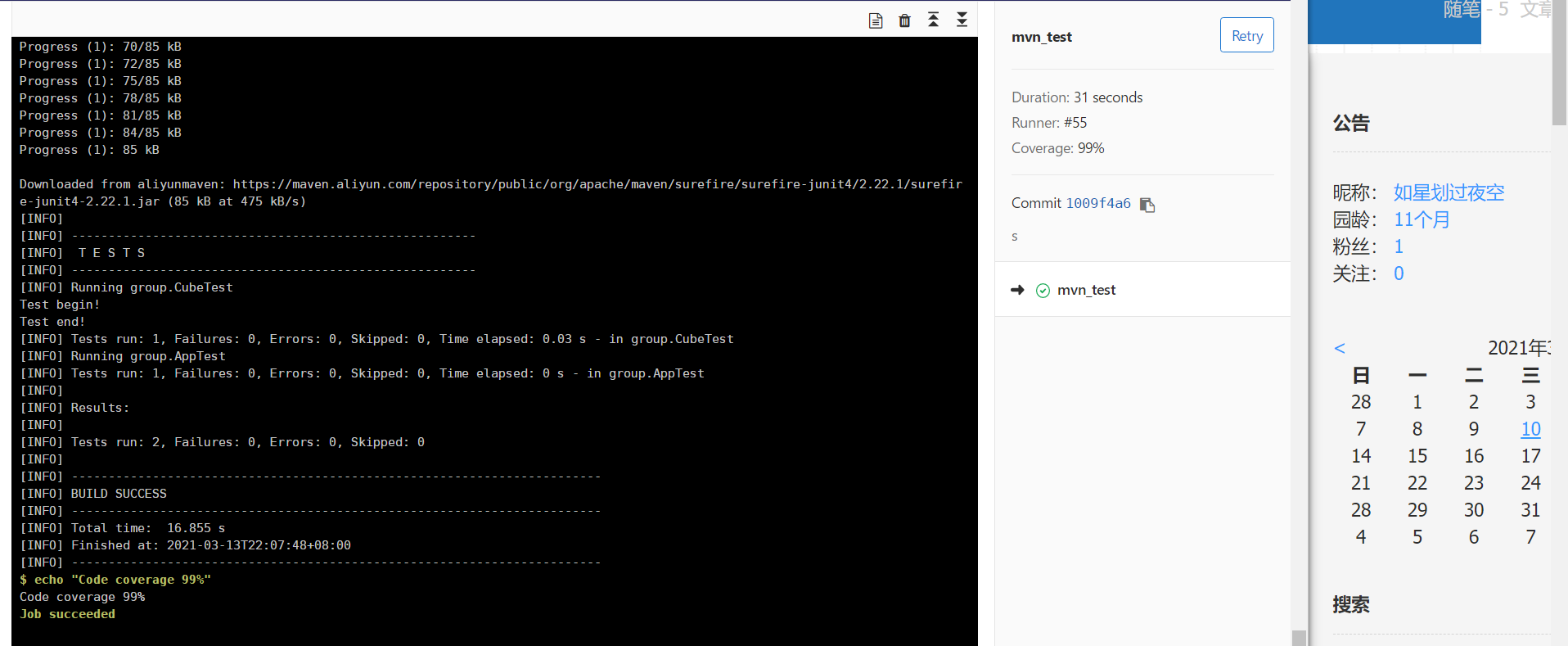
2.GitHub Actions
-
使用同样的工程,修改.yml配置文件
-
上传到Github仓库触发自动评测
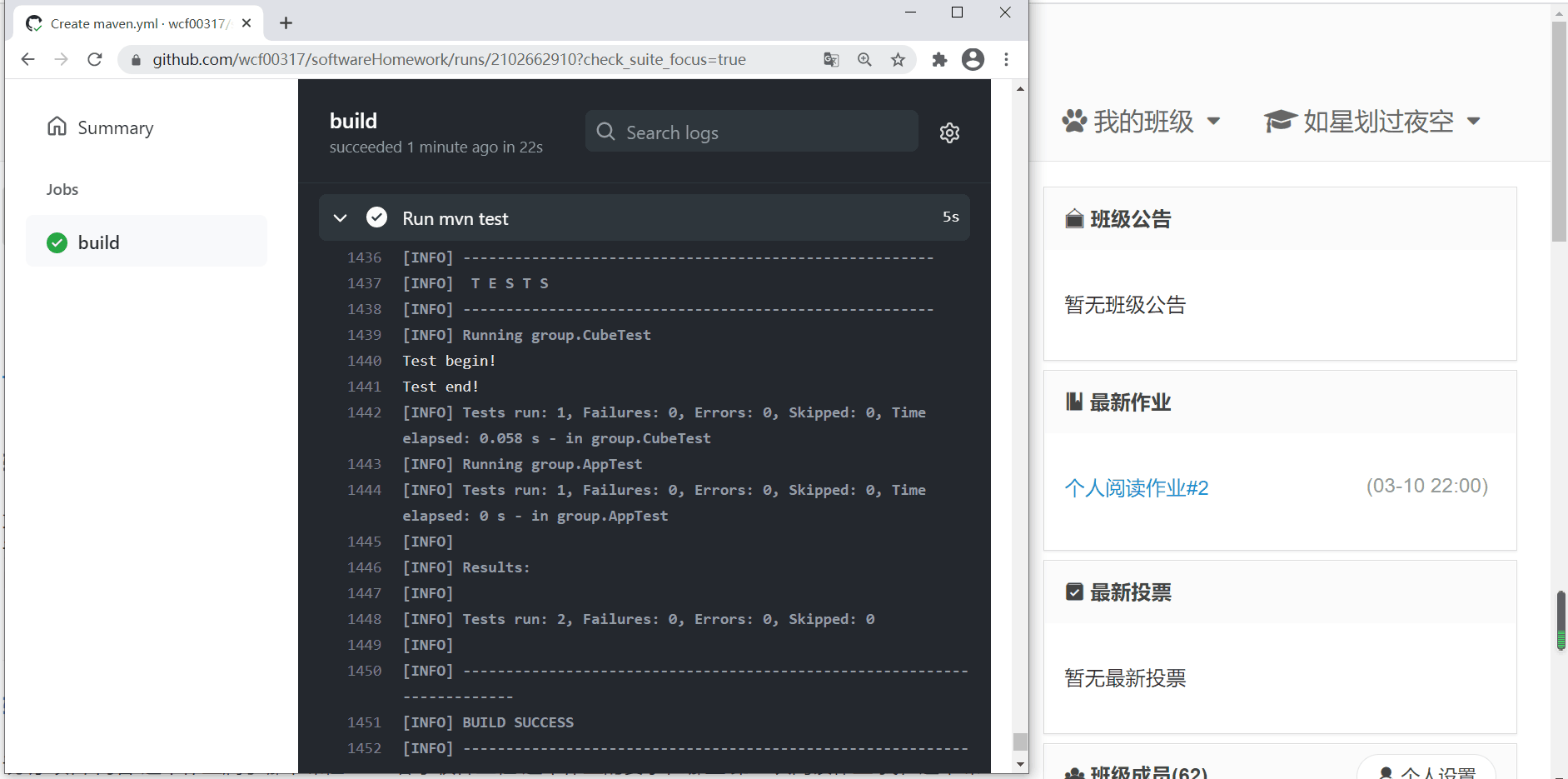
3.使用CI和CD工具后的看法
GitLab-CI的优势
1.和GitLab集成,功能集成度较高
2.界面美观,结果直接展现在GitLab页面上,直观清晰
3.无需复杂配置,上手容易
GitHub Actions的优势
1.actions可以用来作为CI/CD使用,但是它不只是CI/CD,因为它其实是一组docker容器所组成的Workflow,可以完成除了CI/CD之外的许多自动化操作
2.与 GitHub 高度整合的,只需一个配置文件即可自动开启服务
适用场景
GitLab CI/CD对流水线的管理要更加简单易懂,各阶段的定义和阶段之间的依赖关系显式列在配置文件中,因此可以有多种自定义选择方式,而Github Actions则显得较为复杂,因为使用了大量插件,插件背后的运行逻辑比较复杂,但是也能完成一些更为复杂的任务。
总而言之,GitLab CI/CD更加灵活方便,更适合个人用户开发中小型项目使用;而Github Actions则有较多的插件支持,更加适合大型项目的使用。
