

OO第三单元作业——魔教规格
-
-
OO第三单元作业——魔教规格
-
JML的理论基础和相关工具
JML(Java Modeling Language,Java建模语言),在Java代码种增加了一些符号,这些符号用来标志一个方法是干什么的,但是不关心它的具体实现。通过使用JML,在实现代码前,我们可以描述一个方法的预期功能,而尽可能地忽略实现,从而把过程性思考一直延迟到方法设计的层面。
如果仅仅是描述方法的功能,那么自然语言一样可以做到,但是,使用JML语言的好处是,相比于容易产生歧义的自然语言,以前置条件、副作用、异常行为、作用域、后置条件等为标准规格的JML规格语言能减少歧义的产生。
此外,只要有了一套规范的语言,就代表有可能实现形式化验证,也就是说,给定一组输入和输出,就一定可以判定这一组输入和输出是否符合规格要求。而这带来的好处就是,在智能的配套工具链下可能可以实现自动化测试。自动化测试是在由机器自动生成合理且覆盖性强的测试数据来判断是否符合规格要求,这样做可以进一步解放人的时间,还可以避免人思维的死角JML的核心是用表达式,对于方法规格,类型规格进行控制的一种语言。
-
这里面就涉及到了三个要素,什么是JML表达式,什么是方法规格,什么是类型规格。
-
(1)表达式
\result表示非void的返回值,
\forall表示全称量词,给定范围,全部满足约束
\exist表示存在量词,给定范围,存在一个满足约束
\max表示给定范围最大值
\min表示给定范围最小值
\not_assigned(x,y,...)括号内没赋值就是true,反之false
\nothing 表示空集
\everything 表示全集
(2)方法规格
方法规格的核心就是,满足什么条件达成什么样的结果。特别强调的是,方法规格只规定了满足什么条件,和产生什么结果。不关心产生结果的过程。
在这句核心的基础之上,生发出来各种各样的约束,
前置条件(@require):调用者应当保证的前提
后置条件(@ensure):实现者需要保证的结果
副作用(@assignable):允许你的方法对什么进行成员修改,避免产生调用者不知道的其他影响
异常(@exceptional_behavior,@signal):满足什么条件,需要你去抛出什么样的异常(使用signal 标注出异常类型)
这样可以很好的实现权责分明,如果让实现者考虑所有可能的输入并且一一检查和判断的话将会产生巨大的工作量以及许多遗漏,而程序的输入往往是决定于调用者的,这样的分工使得工作量的分担更加均匀,也减少了无用功
(3)类型规格
类型规格的核心是变与不变,不变式(invariant)就是告诉你,在方法执行前,完成等可见状态下某种数据变量的要求。与之相对的约束就是状态变化约束(constraint),如果要变化,怎么变,描述变前变后的关系。
-
-
-
- JML工具链
- (1) openjml与solver
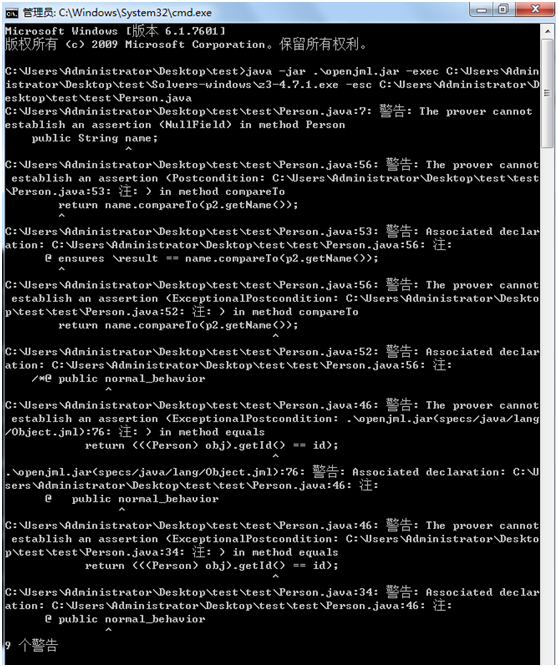
部署好Solver和openjml包后将自己的Person类进行测试,发现除了一堆warning啥都没有,一开始我以为“没有错误就是正确”,这也是Windows等系统在设计命令行的时候所遵循的一个宗旨,但是当我故意把自己Person类改错了一些地方后发现还是只有一堆warning,于是我只能转向网上在线的OpenJML。
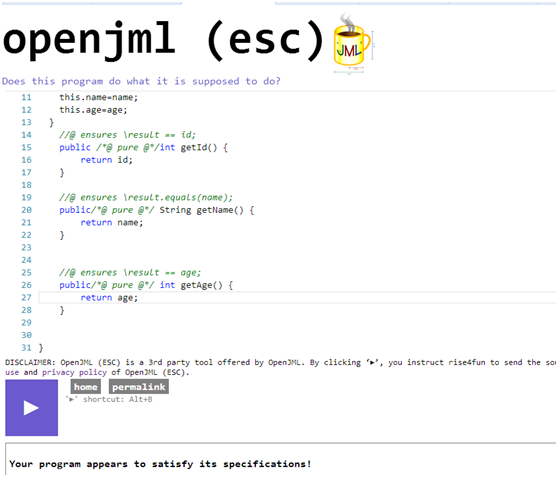
- 同时,我在故意将getAge函数改错以后,发现网页果然报错了。
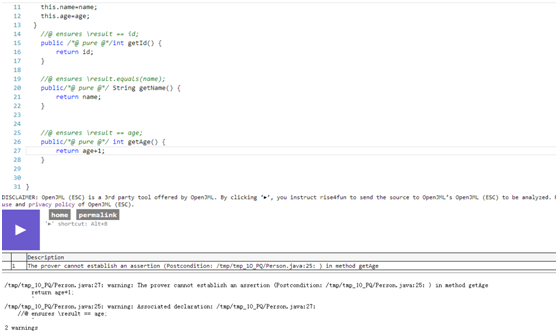
- 这说明openJML是可以初步进行测试的,但是openJML也有缺陷,比如为了优化将数据结构变得较为复杂(如采用Hashmap、Hashset等)时便无法进行检查。
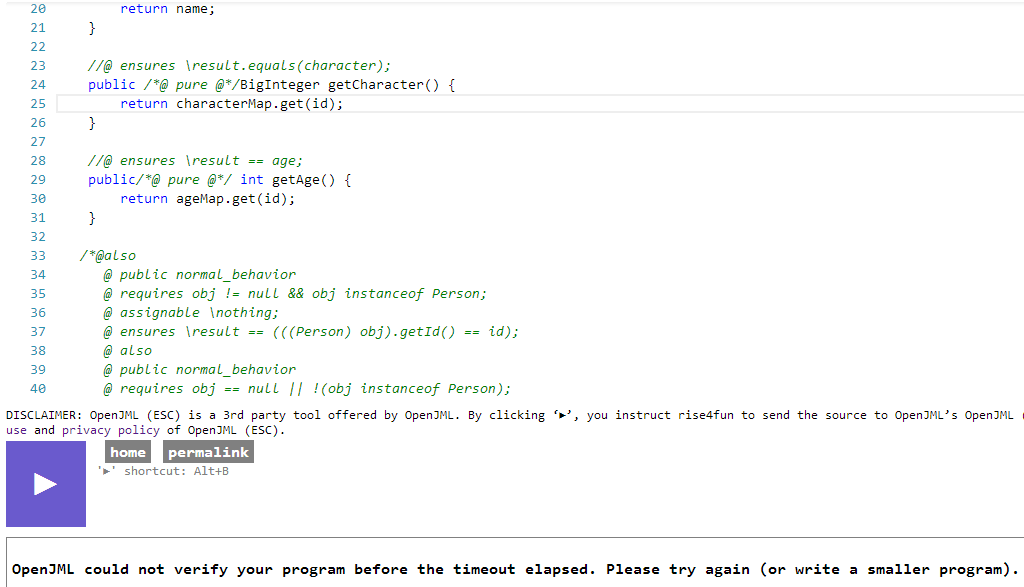
不过这也难为机器了,毕竟它无法读懂注释,也没法真正理解代码的含义只能机械比对,被各种数据结构绕晕也可以原谅。
-
(2)JMLUNITNG
-
在阅读完这个工具的简介以后我是如获至宝的,毕竟Junit单元测试只能自动搭建一个框架,具体的实现还需要你来写测试数据以及assert来完成正确性的判断,而这个工具可以实现全自动测试。部署好JMLUnitNG以后,在命令行输入test指令,果然生成了一堆测试文件:
-

进行编译并导入jar包后也一切正常。
-
然而最后的结果却让我哭笑不得:
-

自动生成的所谓边界数据竟然就是一堆null,真让人大跌眼镜。无奈之下只好重新改动了MyGroup使得它符合测试的条件,并且成功测试了大部分方法。
-
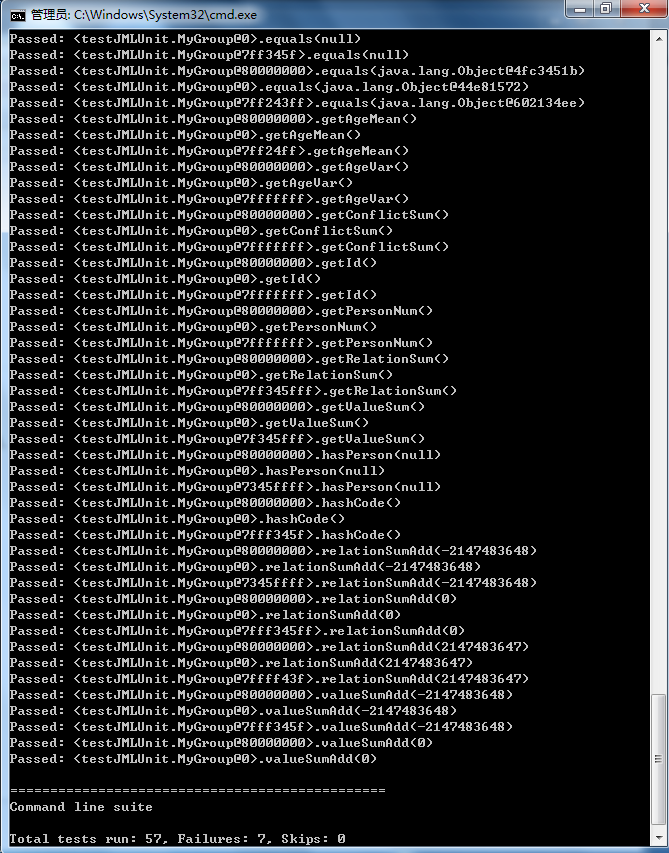
但是它只测试了边界的条件,有的边界数据不合法(age是负数或者一个很大的正数),有的输入依然是null,因此这个覆盖是不完备的,同时也是低效的。
-
三次作业架构设计
第一次作业
-
(1)架构设计
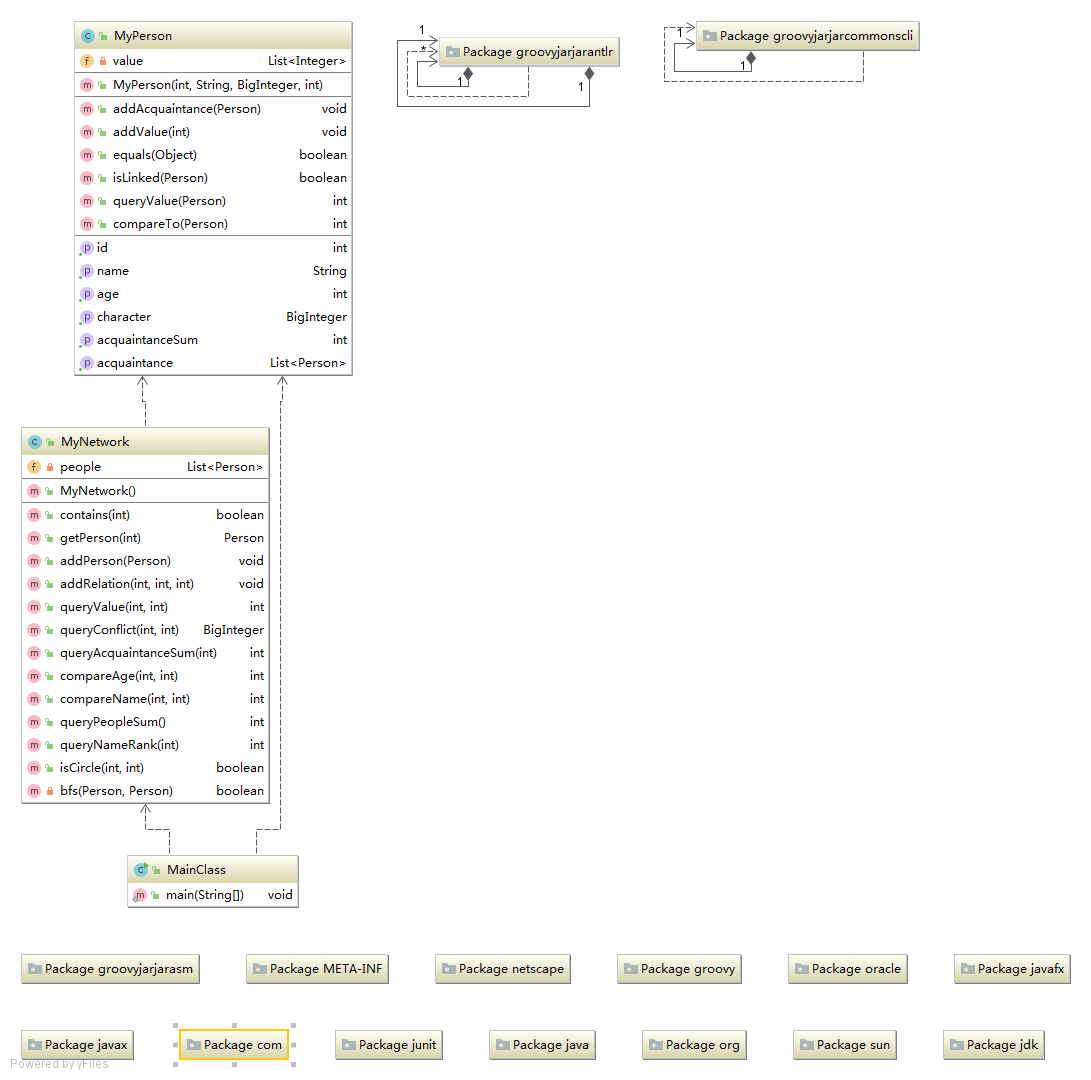
(2)算法分析
所有的数组都是采用ArrayList实现,每当寻找需要的数据便直接遍历寻找。对于isCircle方法我采用的是bfs,这样不像dfs让系统维护栈,运行效率高,同时便于寻找最短路径,具有一定的可扩展性。
(3)复杂度分析
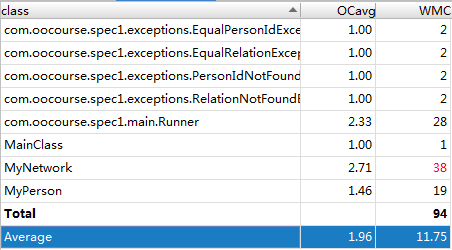
-
-
第二次作业
-
(1)架构设计

(2)算法分析
本次作业在理解了各个变量的基础上,将ArrayList均变更为Hashmap,这样虽然在遍历的时候会慢一些但是所有查找的时间复杂度都降低至O(1)。此外,由于强测数据量较大,因此设置了缓存机制来防止少量加入、大量查询导致的超时。
(3)复杂度分析
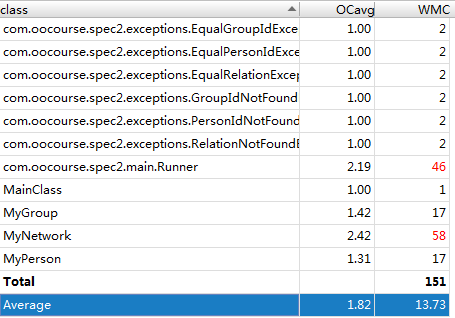
-
第三次作业
-
(1)架构设计

(2)算法分析
本次作业保留了上一次作业的缓存思想,同时对于isCircle操作以及queryBlockSum操作,通过并查集的方式进行了优化,将查询的时间复杂度降低到了O(1);对于queryMinPath方法,由于我们的图在顶点数最多是800而边数最多的5000,因此采用堆优化后的dijkstra算法(时间复杂度是O(mlogm),其中m为边数)比使用dijkstra算法(时间复杂度是O(n2),n为顶点数)更加省时间;在queryStrongLink方法中,我采用的是删点法,即如果两个人不是直接连接,就采取每次删除一个人,遍历删除所有人的每一个,之后判断起点终点是否可达的方法。如果两个人因为删除一个人无法连通,就不是强连通。但是有一种特殊情况,当两个人直接link的时候,这种做法是无效的,此时只需要寻找到一条长度大于2的路径即可判定强连通为此需要有一个记录路径的bfs来缩小暴力删点范围,以及一个能够接受删点的bfs遍历,还有一个忽略起点终点直接相连路径的bfs,因此我专门建立了一个bfs类来管理不同的bfs。总体而言,我的时间复杂度控制的非常好,仅queryStrongLink方法时间复杂度达到了O(n2),其他方法均不超过线性的复杂度。
(3)复杂度分析
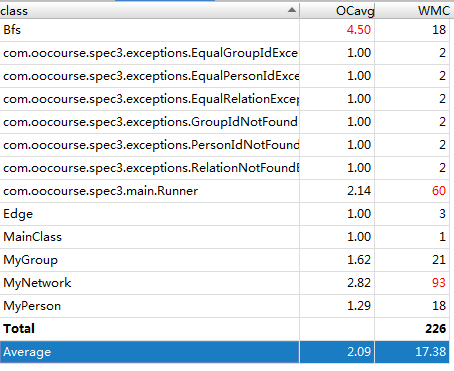
bug分析
第一次作业:在强测和互测中均未被发现BUG,也未在互测中发现他人的BUG。
第二次作业:在强测和互测中均未被发现BUG,在互测中只要单一方法时间复杂度达到O(n2)即可构造数据来使得程序运行超时,比较典型的超时例如求方差的时候平均数没有提前求好而是每次都代入计算,没有缓存导致relationSum需要二重遍历,以及bfs使用数组而非链表导致每次删除数组第一位时时间复杂度都是O(n),这样总体的时间复杂度便上升为O(n2)
第三次作业:在强测中由于int溢出问题WA了两个测试点,互测中未被发现BUG,在互测中利用对拍器发现他人一个缓存不当导致的WA,一个dijkstra写错导致的TLE和一个强连通判断有误的WA。
对于我自己的Bug,我当时想到了可能出现的int溢出,于是将total变量改成了long,但是我忽略了中间计算过程中还可能存在的溢出导致最后出错。同时,我没有做好边界测试导致这个BUG没有在强测开始前被发现,这样的数据仅仅通过对拍器随机生成是难以查出的。这次的惨痛教训告诉我们,设计上要小心再小心,测试上要严密再严密。
心得体会
对于JML的感悟
-
跟别的同学介绍JML的时候,我开玩笑说JML是一个程序员写给另一个程序员的情书,情书是假,给对方分配任务是真。那为什么要用JML这种晦涩难懂的语言来描述呢?
- 有一个笑话,程序员的妻子对程序员说:“你去菜市场买两个苹果,看到西瓜就买一个。”过了一会儿,程序员拿着一个苹果回来了......
- 还有一个笑话,程序员的妻子对加班到很晚才回家的程序员说:“你明天提早点回来吧!”第二天程序员没有回家,第三天一大早,他手里拎着早餐回到了家......
- 这说明自然语言有许多局限性,首先它容易产生歧义,其次由于程序员的国界不同语言不同很难跨国交流。
-
但是JML语言消除这种歧义,逻辑严密,同时它又是一种通用的语言,不受国界影响。
-
(2)启发和感悟
-
本单元的作业对我的能力是有提高的,首先在阅读JML规格的时候,如何从一串复杂的\forall、\exist和循环中读懂要求并转化成自己的语言是第一个考验,如何确保自己的提取和原规格等价以及发现边界条件和特殊情况是第二个考验,同时由于JML规格只负责描述任务而不关心具体实现,因此如何选择合适的数据结构来简化实现过程是第三个考验,最后为了程序的性能还要使用各种各样的算法进行优化是第四个考验。无论是哪一关出现了问题都会导致最终的结果错误,因此这是一个很好的锻炼过程。
-
通过本单元的学习,我对容器的选择有了更深刻的理解,对于抽象和具体的转化能力有了进一步的提高,对于程序运行时间的估计和时间复杂度的控制也有了明显的提升,对于架构的把握和接口的管理也颇有收获。
- 最后,希望OO课程能够越来越好!
-
