


elasticsearch
【Ant说题】不是吧,阿sir!ElasticSearch这么问你都栽了,不合适吧_哔哩哔哩_bilibili 专注面试的up主

数据量大
全文检索
从内存中找到主键id
倒排索引,字典+倒排列表
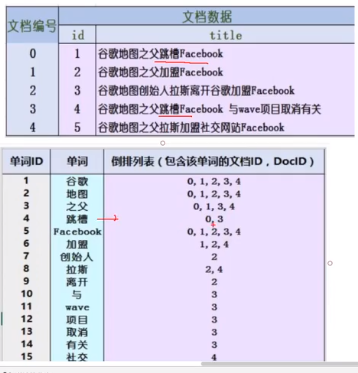
数据量大,单词就会多,用线性表,操作复杂度。
基于单词列表,提高检索效率,所以,除了倒排索引,还会用到树的理论,使用的是k-d树
倒排索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件。建立全文索引中有两项非常重要,一个是如何对文本进行分词,一是建立索引的数据结构。分词的方法基本上是二元分词法、最大匹配法和统计方法。索引的数据结构基本上采用倒排索引的结构。
英文原名Inverted index,大概因为 Invert 有颠倒的意思,就被翻译成了倒排。
但是倒排这个名称很容易让人理解为从A-Z颠倒成Z-A。
个人认为翻译成转置索引可能比较合适。
一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。
而Inverted index 指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号