聚合分析与分组
创建表
create table teacher ( tno int not null, tname char(10) not null, cno int not null, sal int, dname char(10) not null, tsex char(10) not null, age int not null );
插入数据
insert into teacher values(1,'王军',4,800,'数学','男',32); insert into teacher values(2,'李彤',5,1200,'生物','女',54); insert into teacher values(3,'王永军',1,900,'计算机','男',40); insert into teacher values(4,'刘小静',2,1200,'计算机','女',46); insert into teacher values(5,'高伟',8,2100,'电子工程','男',39); insert into teacher values(6,'李伟',7,1200,'机械工程','男',29); insert into teacher values(7,'刘辉',3,900,'生物','女',46); insert into teacher values(8,'李伟',9,null,'计算机','女',43); insert into teacher values(9,'刘静',12,1300,'经济管理','女',28); insert into teacher values(10,'刘一凯',13,null,'计算机','女',33);
查询所有数据

聚合分析
对表中的某列进行统计分析
聚合函数
求和函数SUM()
比如求所有男性教师的总工资:
select sum(sal) as boysal from teacher where tsex='男';

比如年龄大于40的教师工资总数
select sum(sal) as oldsal from teacher where age>40;

计数函数count()
计算表中记录的个数
count(*):计算行的总个数,记录为null的也计算在内
count(col):计算col列包含的值的函数,若有一行的该列值为null,则不计算在内
比如查询教师总数
select count(*) as totalTeacher from teacher;

比如查询多个列的数目
select count(tno) as tonTotal ,count(cno) as cnoTotal,count(sal) as salTotal from teacher;

最大最小值函数:max(),min()
比如查询年龄最大的教师的信息
select * from teacher where age = (select max(age) from teacher);

均值函数avg()
比如求所有教师的平均年龄
select avg(age) from teacher;
组合查询
将查询对象按一定条件分组,然后对每一组进行聚合分析
group by子句创建分组
以性别为基准,将教师分为男性和女性,分别对两组数据进行聚合分析,计算平均工资
select tsex as teacher,avg(sal) as avgSal from teacher group by tsex;

group by子句根据多列组合行
当行组依赖于多列时,只需要在group by后面列出所有列即可(select查询的字段要么是聚合的结果,要么包含在group后面的字段)
比如将查询对象按专业和性别分组,然后统计教师数量
group by dname,tsex先将查询对象按专业分组,然后将分组后的数据再按性别分组
select dname,tsex,count(*) as total_num from teacher group by dname,tsex order by dname;

group by子句中NULL的处理
当用于分组的列出现null值时,会将这些含有null的记录归为一组。
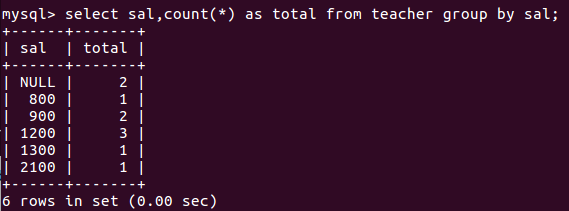
比如查询教师工资种类,工资为null的记录会被归为一组
select sal,count(*) as total from teacher group by sal;
having子句
group by只是简单的根据所选的列对记录进行分组,而有时候需要对分组进行筛选,排除不符合条件的分组,因此常常使用having来搭配group by使用
比如查询每个专业的教师数目,并且只查询至少有两个教师的专业
select dname,count(*) as total from teacher group by dname having count(*)>=2;

having子句与where子句
having子句和where子句的相似之处在于,它也定义搜索条件。但与where子句不同,having子句与组有关,而不是单个的行有关。
1)如果指定了group by子句,那么having子句定义的搜索条件将作用于这个group by子句创建的那些组
2)如果指定了where子句而没有指定group by子句,那么having定义的搜索条件将作用于where子句的输出,把这个输出看作一个组
3)如果既没有指定where也没有指定group by,那么having定义的搜索条件将作用于from子句的输出,将这个输出看作一个组
以下举一个例子:
当我们查询女教师的专业和女教师的数目时,可以如下:
select dname,count(tsex) as total from teacher where tsex='女' group by dname;
但如果不使用where而是使用having如下:
select dname,count(tsex) as total from teacher group by dname having tsex='女';
结果如下:
ERROR 1054 (42S22): Unknown column 'tsex' in 'having clause'
这是因为group by dname having tsex='女'语句错误,因为group by得到的是分组,having是分析的每个分组,而单个值是没有没法应用在一个组上的,即不能判断一个组是否满足tsex='女'这个条件。having子句的列必须是组列,比如count(*)>2或sum(sal)>3000,having分析的是一个组是否满足要求,而不是组中的某一个列是否满足要求。

