第六章——优先队列
1、概述
队列是一种满足先进先出(FIFO)的数据结构,数据从队列头部取出,新的数据从队列尾部插入,数据之间是平等的,不存在优先级的。这个就类似于普通老百姓到火车站排队买票,先来的先买票,每个人之间是平等的,不存在优先的权利,整个过程是固定不变的。而优先级队列可以理解为在队列的基础上给每个数据赋一个权值,代表数据的优先级。与队列类似,优先级队列也是从头部取出数据,从尾部插入数据,但是这个过程根据数据的优先级而变化的,总是优先级高的先出来,所以不一定是先进先出的。这个过就类似于买火车票时候军人比普通人优先买,虽然军人来的晚,但是军人的优先级比普通人高,总是能够先买到票。通常优先级队列用在操作系统中的多任务调度,任务优先级越高,任务优先执行(类似于出队列),后来的任务如果优先级比以前的高,则需要调整该任务到合适的位置,以便于优先执行,整个过程总是使得队列中的任务的第一任务的优先级最高。
优先级队列有两种:最大优先级队列和最小优先级队列,这两种类别分别可以用最大堆和最小堆实现。书中介绍了基于最大堆实现的最大优先级队列。一个最大优先级队列支持的操作如下操作:
INSERT(S,x):把元素x插入到集合S
MAXIMUM(S):返回S中具有最大关键字的元素
EXTRACT_MAX(S):去掉并返回S中的具有最大关键字的元素
INCREASE_KEY(S,x,k):将元素x的关键字的值增加到k,这里k值不能小于x的原关键字的值。
2、最大优先级队列操作实现
(1)HEAP_MAXIMUM用O(1)时间实现MAXIMUM(S)操作,即返回最大堆第一个元素的值即可(return A[1])。
(2)HEAP_EXTRACT_MAX实现EXTRACT_MAX操作,删除最大堆中第一个元素,然后调整堆。操作过程如下:将最堆中最后一个元素复制到第一个位置,删除最后一个节点(将堆的大小减少1),然后从第一个节点位置开始调整堆,使得称为新的最大堆。操作过程如下图所示:
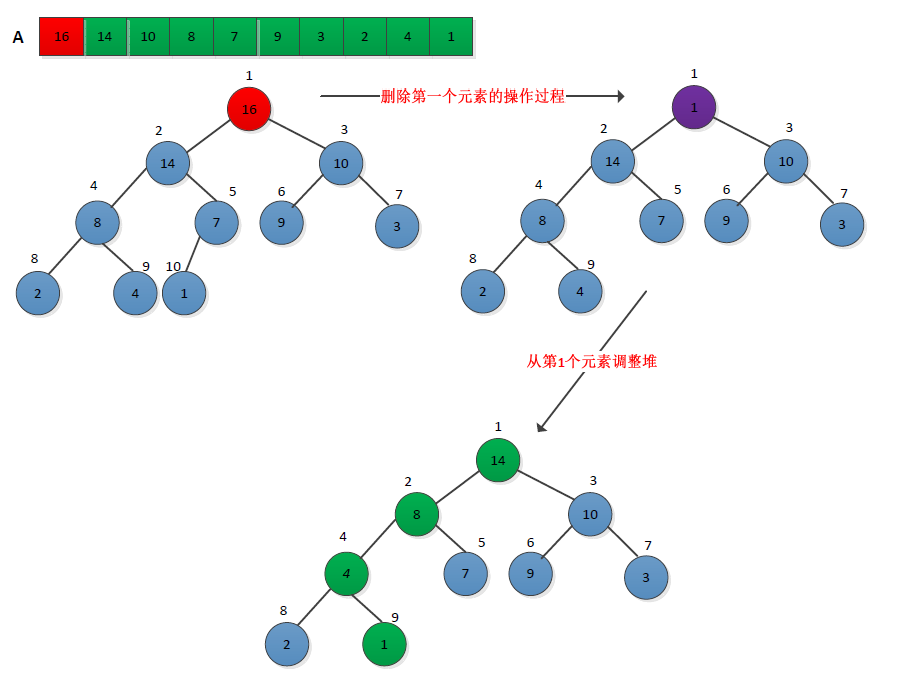
伪代码描述如下:

1 HEAD_EXTRACT_MAX(A) 2 if heap_size[A]<1 3 ther error 4 max = A[1] 5 A[1] = A[heap_size[A]]; 6 heap_size[A] = heap_size[A]-1 7 adjust_max_heap(A,1) 8 return MAX
(3)HEAP_INCREASE_KEY实现INCREASE_KEY,通过下标来标识要增加的元素的优先级key,增加元素后需要调整堆,从该节点的父节点开始自顶向上调整。操作过程如下图所示: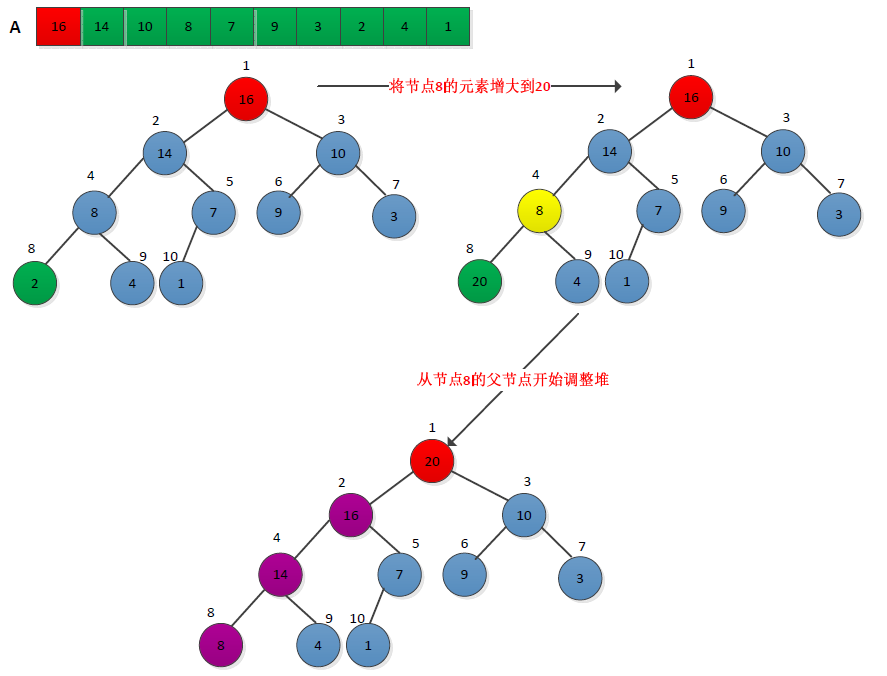
伪代码描述如下:
1 HEAP_INCREASE_KEY(A,i,key) 2 if key < A[i] 3 then error 4 A[i] = key 5 while i>1 && A[PARENT(i)] <A[i] 6 do exchange A[i] <-> A[PARENT(i)] 7 i = PARENT(i)
(4)MAX_HEAP_INSERT实现INSERT操作,向最大堆中插入新的关键字。新的关键字插入在优先级的队尾部,然后从尾部的父节点开始自顶向上调整堆伪代码描述如下:
1 MAX_HEAP_INSERT(A,key) 2 heap_size[A] = heap_size[A]+1 3 A[heap_size[A]] = -0; 4 HEAP_INCREASE_KEY(A,heap_size[A],key)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号