

redis面试题
一、线程
1.1、redis是单线程还是多线程
1 2 | 无论什么版本,工作线程就是一个6.0之后的版本出现了IO多线程 |
Redis 6.0版本以前的单线程是指其网络I/O和键值对读写是由一个线程完成的
Redis 6.0引入的多线程指的是网络请求过程采用了多线程,而键值对读写命令仍然是单线程处理的,命令到服务端去执行还是排队的顺序执行的,所以Redis仍然是并发安全的,因为命令还是一个个去执行
也就是只有网络请求模块和数据操作模块是单线程的,而其他的持久化、集群数据同步等,其实是由额外的线程执行的
1.2、redis是单线程为什么还能这么快
1 2 3 4 | 1、命令执行基于内存操作,一条命令在内存里操作的时间是几十纳秒2、命令执行是单线程操作,没有线程切换开销3、基于IQ多路复用机制提升Redis的I/O利用率4、高效的数据存储结构:全局hash表以及多种高效数据结构,比如:跳表,压缩列表,链表等等 |
1.3、redis是单线程的,如何做到支持高并发?
IO多路服用,是网络请求过程采用了多线程
二、key相关
2.1、redis是怎么删除过期的key的?
3种:
①、定时删除
定时删除是在设置 key 的过期时间的同时,会创建一个定时器(timer)。定时器在 key 的过期时间来临时,立即执行对 key 的删除操作
②、定期删除
定期删除是每隔一段时间,程序就会对 Redis 数据进行一次检查,删除里面的过期 key,至于要删除多少过期 key,以及要检查多少个 db,则是由 Redis 内部算法决定
③、惰性删除
惰性删除是定时删除和定期删除的折中处理方案。它放任 key 过期不管,但是每次获取 key 时,都会检查取得的 key 是否过期,如果过期,则删除该 key;若没有过期,就返回该 key 的值
2.2、Redis key 的过期时间和永久有效分别怎么设置?
设置过期时间
1 | expire key second:设置key的过期时间 |

设置永久有效
1 | PERSIST KEY_NAME Redis PERSIST 命令用于移除给定 key 的过期时间,使得 key 永不过期。 |
2.3、一个Redis实例最多能存放多少的keys?List、Set、Sorted Set 他们最多能存放多少元素?
2.4、redis大key如何解决,如何优雅的删除?
2.5、redis Key过期了为什么内存没有释放?
可能性有两种:
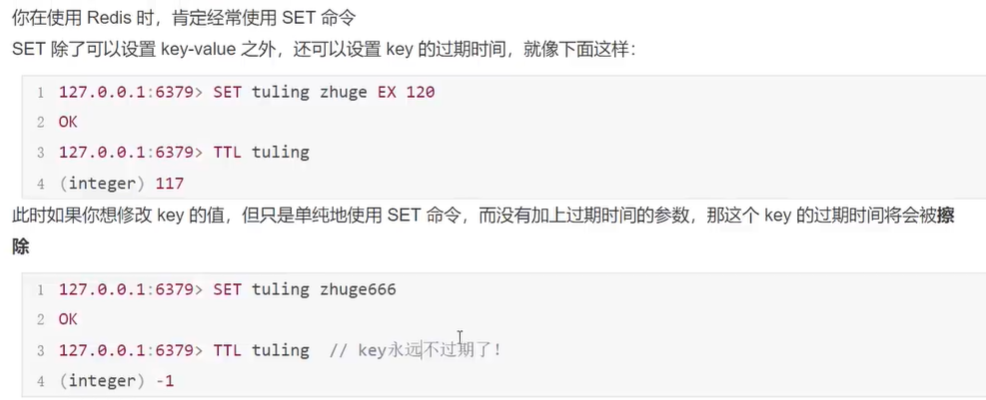
1、一开始对key设置了过期时间,但是后面又修改了key的值,只是单纯的使用了SET命令,没有加上过期时间的参数
2、由于是定时删除机制,可能正处于删除的过程中,未全部清理完成
Redis对于过期key的处理一般有惰性删除和定时删除两种策略
1、惰性删除:当读/写一个已经过期的key时,会触发惰性删除策略,判断key是否过期,如果过期了直接删除掉这个key
2、定时删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期(默认每100ms)主动淘汰一批已过期的key,这里的一批只是部分过期key,所以可能会出现部分key已经过期但还没有被清理掉的情况,导致内存并没有被释放
2.6、Redis Key没有设置过期时间为什么被Redis删除了
Redis Key没设置过期时间为什么被Redis主动删除了
原因:
当Redis已用内存超过maxmemory限定时,触发主动清理策略,比如maxmemory为4G,这个是可以手动配置的,删除的原因可能是删除策略使用的是LRU和LFU算法进行的处理,对所有的key进行了处理
主动清理策略在Redis 4.0之前一共实现了|6种内存淘汰策略,在4.0之后,又增加了2种策略,总共8种:
a)针对设置了过期时间的key做处理:
1. volatile-ttI:在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
2. volatile-random:就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
3. volatile-Iru:会使用LRU算法筛选设置了过期时间的键值对删除。
4. volatile-Ifu:会使用LFU算法筛选设置了过期时间的键值对删除。
b)针对所有的key做处理:
5. allkeys-random:从所有键值对中随机选择并删除数据。
6. allkeys-Iru:使用LRU算法在所有数据中进行筛选删除。
7. allkeys-Ifu:使用LFU算法在所有数据中进行筛选删除。
c)不处理:
8. noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error)OOM command not allowed when used memory",此时Redis只响应读操作。
2.7、Redis淘汰key的策略?
一共六种策略:
1、noeviction(默认策略):对于写请求不再提供服务,直接返回错误(DEL请求和部分特殊请求除外)
2、allkeys-lru:从所有key中使用LRU算法进行淘汰(LRU算法:即最近最少使用算法)
3、volatile-lru:从设置了过期时间的key中使用LRU算法进行淘汰
4、allkeys-random:从所有key中随机淘汰数据
5、volatile-random:从设置了过期时间的key中随机淘汰
6、volatile-ttl:在设置了过期时间的key中,淘汰过期时间剩余最短的
如何获取及设置内存淘汰策略
1、获取当前内存淘汰策略:
1 | 127.0.0.1:6379> config get maxmemory-policy |
可以看到当前使用的默认的noeviction策略
2、获取Redis能使用的最大内存大小
1 | 127.0.0.1:6379> config get maxmemory |
3、设置淘汰策略
通过配置文件设置淘汰策略(修改redis.conf文件):
1 | maxmemory-policy allkeys-lru |
通过命令修改淘汰策略:
1 | 127.0.0.1:6379> config set maxmemory-policy allkeys-lru |
4、设置Redis最大占用内存大小
1 2 | #设置Redis最大占用内存大小为100M127.0.0.1:6379> config set maxmemory 100mb |
2.8、删除key的命令会阻塞redis吗?
格式:DEL key [key ...]
删除给定的一个或多个key。
不存在的key会被忽略
返回值:
被删除key的数量
时间复杂度:
O(N),N为被删除的key的数量,如果key很大几百M会阻塞
删除单个列表、集合、有序集合或哈希表类型的key,会发生阻塞
三、缓存
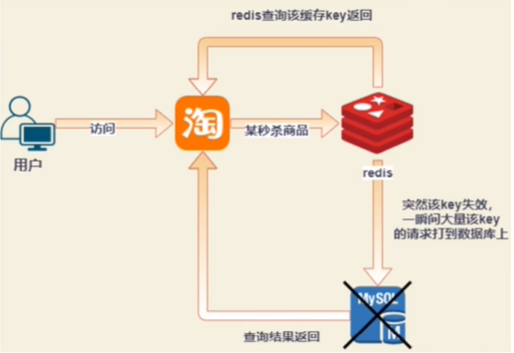
正常的缓存流程图:

1、遇到过缓存击穿吗?描述一下
现象:查询的时候一些热key失效,一瞬间大量该key的请求打到数据库上了
解决思路:
1、用久缓存;
2、分布式锁
a.单体应用—>互斥锁—>zookeeper ,redis实现。
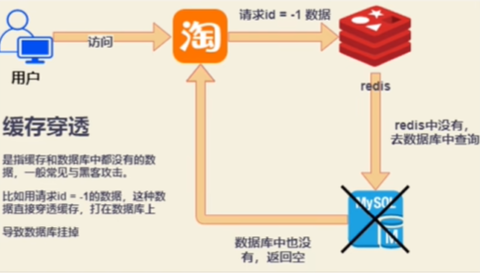
2、遇到过缓存穿透吗?描述一下
主要是恶意用户
现象:缓存和数据库都没有的数据,一般常见于黑客攻击,比如用请求id=-1的数据,这种数据直接穿透缓存,打在数据库上,导致数据库挂掉
解决方法:
1、无意义数据放入缓存,下一次相同请求就会命中缓存;
2、IP过滤;
3、参数校验;
4、布隆过滤器;
3、如何避免缓存雪崩?
现象:大量缓存数据同时间失效,导致用户直接发起大量请求到数据库,产生瓶颈

解决思路:
1、设置缓存失效时间不要在同一时间失效
2、集群部署,将热点key放到不同的节点上去,
3、定时任务去定时刷新redis缓存,或者不设置失效时间
4、缓存如何回收的?
四、Redis集群三种方式
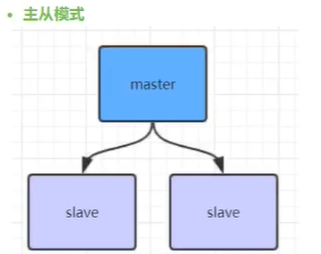
4.1、主从模式
4.2、哨兵模式
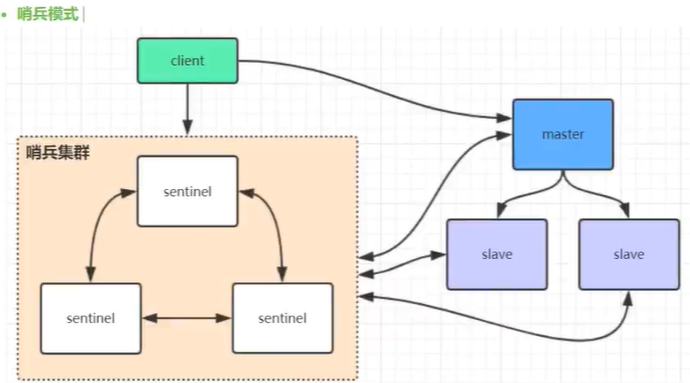
在主从集群之外添加3个哨兵节点组成哨兵集群,对每个Redis节点进行监听,Client通过哨兵节点访问Redis节点,如果有主节点宕机了,哨兵节点会从从节点里面选一个新的节点作为主节点,也因此会出现瞬断的情况
4.3、高可用集群模式
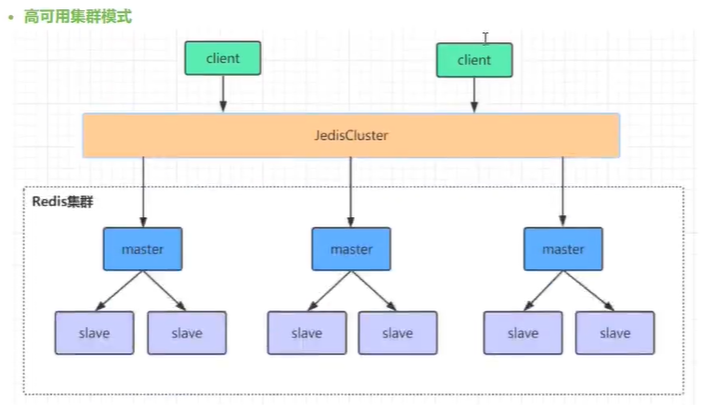
redis集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵·也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单
五、Redis主从
5.1、Redis的主从复制原理?
Redis Replication是一种 master-slave 模式的复制机制,这种机制使得 slave 节点可以成为与 master 节点完全相同的副本,可以采用一主多从或者级联结构。架构如下
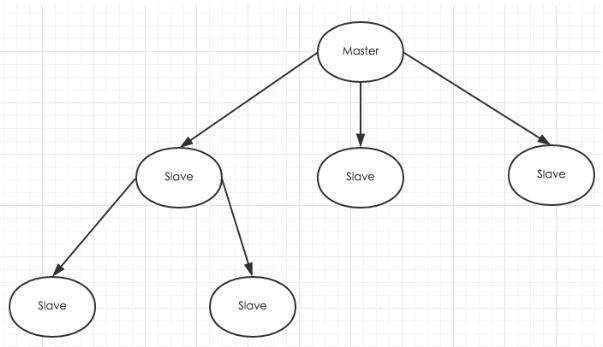
主从复制的配置要点:
(1)配从库不配主,从库配置:slaveof 主库IP 主库端口
(2)查看redis的配置信息:info replication
主要原理和流程:
从总体上来说,Redis主从复制的策略就是:当主从服务器刚建立连接的时候,进行全量同步;全量复制结束后,进行增量复制。当然,如果有需要,slave 在任何时候都可以发起全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份,具体步骤如下:
(1)slave服务器连接到master服务器,便开始进行数据同步,发送psync命令(Redis2.8之前是sync命令)
(2)master服务器收到psync命令之后,开始执行bgsave命令生成RDB快照文件并使用缓存区记录此后执行的所有写命令
1 2 3 | 如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是每个连接都执行一次,然后再把这一份持久化的数据发送给多个并发连接的slave。如果RDB复制时间超过60秒(repl-timeout),那么slave服务器就会认为复制失败,可以适当调节大这个参数 |
(3)master服务器bgsave执行完之后,就会向所有Slava服务器发送快照文件,并在发送期间继续在缓冲区内记录被执行的写命令
1 2 | client-output-buffer-limit slave 256MB 64MB 60,如果在复制期间,内存缓冲区持续消耗超过64MB,或者一次性超过256MB,那么停止复制,复制失败 |
(4)slave服务器收到RDB快照文件后,会将接收到的数据写入磁盘,然后清空所有旧数据,在从本地磁盘载入收到的快照到内存中,同时基于旧的数据版本对外提供服务。
(5)master服务器发送完RDB快照文件之后,便开始向slave服务器发送缓冲区中的写命令
(6)slave服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
(7)如果slave node开启了AOF,那么会立即执行BGREWRITEAOF,重写AOF
5.2、redis的主从风暴是怎么回事?
如果Redis主节点有很多从节点,在某一时刻如果所有从节点都同时连接主节点,那么主节点会同时把内存快照RDB发给多个从节点,这样会导致Redis主节点压力非常大,这就是所谓的Redis主从复制风暴问题。
这种问题我们对Redis主从架构做一些优化得以避免,比如可以做下面这个树形复制架构
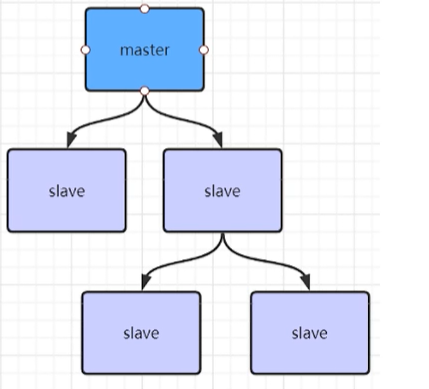
5.3、简述一下主从不一致的问题?
六、Redis锁
分布式锁:在分布式集群中,对某个节点添加锁之后,其他节点无法感应到,那么如何解决呢?这个时候就要引入分步式锁,一个节点添加锁之后,所有其他节点都能访问使用
6.1、使用过redis锁吗?他是怎么回事?
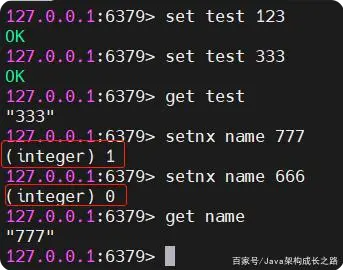
通过setnx实现,加一些过期时间
为什么setnx可以实现?
1、setnx是原子性,依赖于setnx的原子性,维护一个键,原子性的话就可以做到互斥的效果,中间还有一些细节,上锁之后需要加一些过期时间,比如某个线程死锁了就不能拿到锁
上锁同时设置过期时间
1 | set users 10 nx ex 12 |
2、setnx key value 也是设置key的值为value,不过,它会先判断key是否已经存在,如果key不存在,那么就设置key的值为value,并返回1;如果key已经存在,则不更新key的值,直接返回0
感谢您的阅读,如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮。本文欢迎各位转载,但是转载文章之后必须在文章页面中给出作者和原文连接。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构