JavaFrag
总结
Java在官网也有相应的教程,去JDK官网也能了解到新版本JDK相关的特性,所以说直接浏览JDK官网是没有任何信息差的。(自己有充足时间的前提下)
《On Java》、《Effective Java》是必看的两本书,读书百遍,其义自见。读一遍也许理解不了什么。
Centos7安装JDK
安装步骤:
1、下载安装包,建议直接搜索jdk linux安装包,网上已经有人整理成帖子或者分享了网盘链接可以直接下载,省去了再去官网翻阅查找的麻烦。
2、解压缩
# 创建java文件夹备用
mkdir /usr/local/java
tar -zxvf jdk-8u11-linux-x64.tar.gz -C /usr/local/java
3、进入解压好的java目录,pwd一下bin目录路径
4、编辑/etc/profile配置Java环境变量
vim /etc/profile
# 向文件中添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_162
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
5、配置完毕之后执行source /etc/profile,环境变量即可生效。
1. Java概述
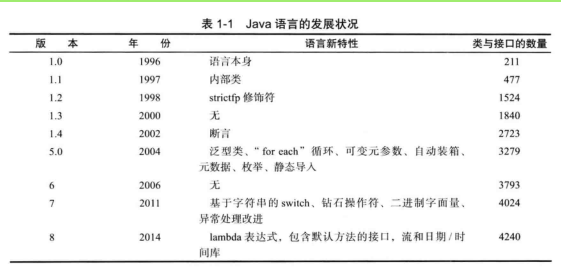
早期的Java是一种解释型语言。现在Java虚拟机使用了即时编译器,运行速度和C++相差无几。
编译型、解释型?(高级语言的分类)
编译型语言
定义:将高级语言源代码一次性的编译成能够被该平台执行的机器码并生成可执行程序。
特点:执行速度快、效率高;依靠编译器、跨平台性差。
包括:C、C++、Delphi、Pascal、Fortran...
解释型语言
定义:使用专门的解释器对源程序逐行解释成特定平台的机器码,逐行编译,解释执行。
特点:执行速度慢、效率低;依靠解释器、跨平台性好。
包括:Java、python、JavaScript...
因为编译型语言是一次性地编译成机器码,所以可以脱离开发环境独立运行,而且通过运行效率较高;但因为编译型语言的程序被编译成特定平台上的机器码,因为编译生成的可执行性程序通常无法移植到其他平台上运行;如果需要移植,则必须将源代码复制到特定平台上,针对特定平台进行修改,至少也需要采用特定平台上的编译器重新编译。
每次执行解释型语言的程序都需要进行一次编译,因此解释型语言的程序运行效率通常较低,而且不能脱离解释器独立运行。但解释型语言有一个优势:跨平台比较容易,只需提供特定平台的解释器即可,每个特定平台上的解释器负责将源程序解释成特定平台的机器指令即可。解释型语言可以方便地实现源程序级的移植,但这是以牺牲程序执行效率为代价的。
Java术语
Java安装
JDK JRE JVM
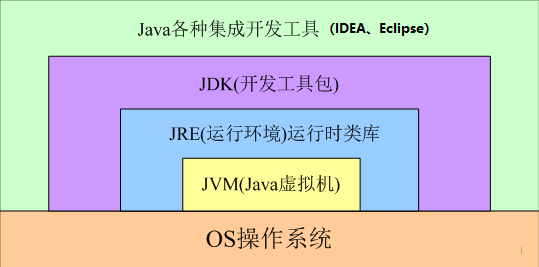
JDK包含了JRE和JVM。
JDK:(Java SE Development Kit)Java开发工具包,它提供了编译、运行Java程序所需的各种工具和资源,包括Java编译器、Java运行时环境,以及常用的Java类库等。
JRE:( Java Runtime Environment) 、Java运行环境,用于解释执行Java的字节码文件。普通用户而只需要安装 JRE来运行 Java 程序。而程序开发者必须安装JDK来编译、调试程序。
JVM:(Java Virtual Machine),即Java虚拟机, 是JRE的一部分。它是Java实现跨平台最核心的部分,负责解释执行字节码文件,是可运行Java字节码文件的虚拟计算机。Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。
当使用Java编译器编译Java程序时,生成的是与平台无关的字节码,这些字节码只面向JVM。不同平台的JVM都是不同的,但它们都提供了相同的接口。这就是Java的能够“一次编译,到处运行”的原因。
小结:
JDK用于开发,JRE用于运行应用程序,如果只是运行Java程序,那么只安装JRE就够了。
JDk包含JRE,JDK 和 JRE 中都包含 JVM。
JVM解释生成的与平台无关的字节码是Java实现跨平台的核心。
环境变量
path:系统运行可执行命令时搜索的路径列表。
作用:DOS下,根目录或者任意目录下运行任何可执行命令,必须配置可执行程序的(如.exe)的路径。
执行机制:path环境变量是先在当前目录找执行程序,如果没有,再到path指定目录中去寻找。
JAVA_HOME:java的安装目录
安装
JDK后,只要把/bin/java.exe配置在系统PATH环境变量中,那么java程序基本上能正常执行。基本上满足开发了开发要求。没有JAVA_HOME、CLASS_PATH也能正常执行。
为什么要配置JAVA_HOME?
(1)方便引用:比如,你JDK安装在C:\ProgramFiles\Java\jdk1.7.0目录里,则设置JAVA_HOME为该目录路径, 那么以后你要使用这个路径的时候, 只需输入%JAVA_HOME%即可,避免每次引用都输入很长的路径串;
(2)归一原则:机器上如果JDK版本发生了变化,java8转到了java11,安装路径发生了变化,这时候只需要改JAVA_HOME的值,那么相继引用JAVA_HOME的也会跟随变化。若没有配置JAVA_HOME,则需要手动修改PATH。
(3)第三方java应用程序需要JAVA环境的支持,我觉得这也是配置JAVA_HOME最重要的一点。比如tomcat、groovy的运行需要用到JAVA_HOME。
CLASS_PATH:指定JRE查找.class文件时的类路径
JAVA1.5之后无需配置,JRE会自动搜索当前路径下的类文件。编译、运行时,系统可以自动加载dt.jar和tools.jar文件中的Java类。
如果指定了CLASS_PATH,会怎么样?
java命令会严格按照CLASSPATH变量中的路径来寻找class文件的,即使当前路径下有.class文件但是不在类路径下也不能执行。
小结:
JAVA_HOME开发中最好配置,提供第三方的环境。CLASSPATH不用配置。PATH运行可执行命令都要必须配置。
查看win
java环境变量的值 echo %JAVA_HOME%echo 输出命令
Java常用命令
# 查看java版本
java -version
# 编译java
javac Xxx.java
# 运行class文件 不带后缀
java Xxx
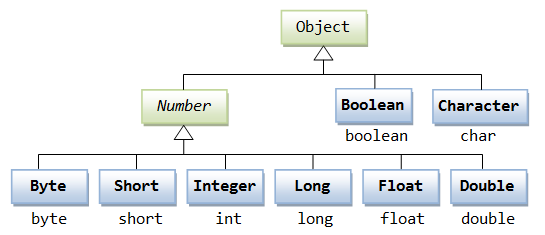
2. Java基础程序设计
1. 数据类型
Java是一种强类型语言。定义变量必须声明类型。
数据类型的分类不在介绍,请看思维导图
Java中int和long等类型的大小与平台无关(c++、c平台相关),这就解决了Java可移植、跨平台所带来的一些数据溢出等问题。
整型范围
| 类型 | 字节 |
|---|---|
| int | 4字节 |
| long | 8字节 |
| short | 2字节 |
| byte | 1字节 |
浮点型
| 类型 | 字节 |
|---|---|
| float | 4字节 |
| double | 8字节 |
字符和布尔类型
| 类型 | 字节 |
|---|---|
| char | 2 |
| boolean | 1 |
注:float|Float、double|Double,Long加后缀
float声明的变量数值类型必须要有F或f,默认没有后缀F的浮点数值默认为double类型,如果 float f = 3.14没有指定,idea出现类型转化错误(double->float).
(Long)长整型引用类型声明需要添加后缀。
true false和null不属于关键字,他们是一个单独标识类型,不能直接使用。
2. 类型转换
数值类型之间的隐式转换:默认都会向上转型,虚线箭头代表可能有精度损失的转化。
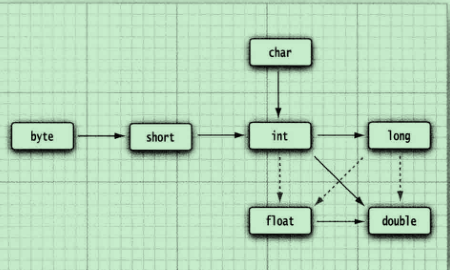
注意,这里将char也归入到了数值型之间的类型转化,char类型本质上是以ASCII码的形式存储的。
隐式只能向上转,可以跨多个维度。
char a = 'A';// char a = 65; 是一样的效果,char类型本质上是以ASCII码的形式存储的
double d = a;
System.out.println(d);//65.0
强制类型转换
int i = (int) 3.14;
隐式类型转化
数值运算过程中的类型转化问题:
-
所有的byte,short,char型的值将被提升为int型;
-
final修饰的变量运算会被JVM自动优化为字面量(常量)
-
如果有一个操作数是long型,计算结果是long型;
-
如果有一个操作数是float型,计算结果是float型;
-
如果有一个操作数是double型,计算结果是double型;
1、运算过程中的向上转型
float d = 3.1 + 2.6;//error,运算结果为double类型
double d = 3.1 + 2.6;
2、复合赋值运算符自动类型强转
byte a = 2;
byte b = 3;
a = a + b; //error
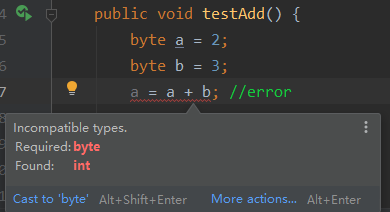
byte类型的变量在做运算时被会转换为int类型的值,int赋值给结果类型为byte的变量发生错误,同理,如果int和float混合运算,会向精度高的类型转化,所以也会发生错误。但是
如果采用复合赋值运算符则将会自动类型强转
@Test
public void testAdd() {
byte a = 2;
byte b = 3;
// a = a + b; //error
a += b;
System.out.println(a);//5
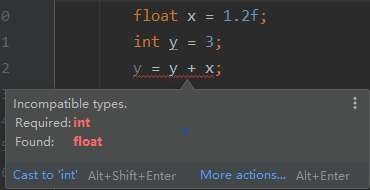
float x = 1.2f;
int y = 3;
// y = y + x;
y += x;
System.out.println(y);//4
}
3、final修饰的变量运算会被JVM自动优化为字面量(常量)
final byte a = 10, b = 20;
byte c;
// a + b被编译为字面量相当于30,在编译器就已经确定了
c = a + b;
3. Java运算符
Java运算符的分类:算数运算符、关系运算符、逻辑运算符、位运算符、赋值运算符、条件运算符
算数运算符
分类:+ 、-、*、/、%、自增(++)、自减(--)
Java中的取模对浮点型也适用,取模结果的符号取决于第一个运算数
进行算数运算的操作数若类型不一致,则会发生类型转化
关系运算符
分类:>、< 、==、>= 、<=、!=
关系运算符是一个二元运算符,也就是说必须要有两个操作数,运算结果是一个逻辑值(boolean)
Java中"=="和"!="适用于任何数据类型。可以判断数值是否相等,还可以判断对象或数组的实例是否相等
逻辑运算符
分类
逻辑与( && ) :全真则真
逻辑或( || ):一真则真
逻辑非( ! ):真则假,假则真
逻辑与(&)逻辑非 (!)
&&和||运算符属于二元运算符,逻辑非属于一元运算符,并且Java中 && 和 || 存在"短路"效应
&&和&、||和|相同点是运算结果一样,不同点是&和|没有短路效应即当左边条件不成立时也会执行右边的判断
位运算符
概念:位算符主要用来对二进制位进行操作,其操作数和运算结果都是整型值
分类
位与(&):同1则1
位或( | ):有1则1
位异或(^):位相异为1,相同为0
位非(取反) ~:单目运算,0变1,1变0
左移(<<):高位舍弃,低位补零(正负数都一样)
右移(>>):低位舍弃,高位补符号位(正数补零,负数补一)
无符号右移(>>>):忽略符号位,高位通补0
注:计算机是以数字的补码进行运算
赋值运算符
=、各种运算简化赋值(+=、-=...)
条件运算符
三目运算符:expression ? (true->exp1) : (false->exp2)
运算符优先级如下图,级别由高到低。
| 类别 | 操作符 | 关联性 |
|---|---|---|
| 后缀 | () [] . (点操作符) | 左到右 |
| 一元 | expr++ expr-- | 从左到右 |
| 一元 | ++expr --expr + - ~ ! | 从右到左 |
| 乘性 | * /% | 左到右 |
| 加性 | + - | 左到右 |
| 移位 | >> >>> << | 左到右 |
| 关系 | > >= < <= | 左到右 |
| 相等 | == != | 左到右 |
| 按位与 | & | 左到右 |
| 按位异或 | ^ | 左到右 |
| 按位或 | | | 左到右 |
| 逻辑与 | && | 左到右 |
| 逻辑或 | | | | 左到右 |
| 条件 | ?: | 从右到左 |
| 赋值 | = + = - = * = / =%= >> = << =&= ^ = | = | 从右到左 |
| 逗号 | , | 左到右 |
3. 字符串
知识点:final关键字 不可变对象 String常量池 编码
1. final关键字
*final关键字的用法:
- final修饰类,表示该类不可以被继承,俗称断子绝孙类
- final修饰方法,子类不可重写该方法,final修饰的方法可以被重载,但不能被重写。
- final修饰基本数据类型变量,表示该变量为常量,变量值不能被修改
- final修饰引用类型变量,表示该引用在初始化指向某对象后,这个引用不能在指向其他对象,但该引用的对象的状态可以改变。
疑问点:引用的对象的状态可以改变?
final int a = 10;
a = 20; //error final 修饰基本类型,值不可变
final String str = "hello world!";
str = "java"; // error final 修饰引用类型 引用的对象地址不能发生变化
final StringBuilder builder = new StringBuilder("hello world");
builder.append("!");// final 修饰引用类型,对象的状态,这里就是指的builder构造的字符串可以发生变化
builder = new StringBuilder();// error 但是builder引用的地址不能在变
final修饰时,要能够区分是引用不可变,还是内部状态不可变!
final作为对象成员存在时,必须初始化;但是,如果不初始化,也可以在类的构造函数中初始
2. 不可变对象
不可变对象(Immutable Object):对象一旦被创建后,对象所有的状态及属性在其生命周期内不会发生任何变化。
如果一个对象在创建之后就不能再改变它的状态,那么这个对象是不可变的(Immutable)。不能改变状态的意思是,不能改变对象内的成员变量,包括基本数据类型变量的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变。
如何创建不可变对象
1)所有属性私有化,并用final标记(非必须)
2)不提供修改原有对象状态的方法
- 去除setter方法
- 如果提供修改方法,则需要新创建对象,并在新创建的对象上进行修改
3)最好不允许类被继承
4)通过构造器初始化所有成员变量,引用类型的变量必须进行深拷贝(deep copy)
3. String的不可变性
String对象一旦被创建并初始化后,这个对象的值就不会发生变化。String类中的所有方法并不是改变String对象本身,相关的任何change操作都是重新创建一个新的String对象。
为什么String类是不可变的?
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
{
/** The value is used for character storage. */
private final char value[];
/** The offset is the first index of the storage that is used. */
private final int offset;
/** The count is the number of characters in the String. */
private final int count;
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
........
}
String底层存储字符串就是依靠private final char value[];一个字符数组,并且String没有提供修改value值的方法,sub、replace不是吗?这些都在新生成的String实例上操作的,并不是改变对象原有的状态,这正好对应上面如何创建不可变对象的原则。正因为如此String对象创建后,就不能修改对象中存储的字符串内容,所以String类型是不可变的(immutable)。
String的不可变是否是真的不可变?
这里仅仅记录一下,网上也有很多这样的帖子,留个印象。
private final char value[];String底层就是用value数组来存储的字符串,final修饰,数组引用不可变化,但是数组中的值可以变化,通过反射可以改变数组引用内部变量的值。
String str = "hello world_";
Field field = str.getClass().getDeclaredField("value");
field.setAccessible(true);
char[] value = (char[]) field.get(str);
value[str.length() - 1] = '!';
System.out.println(value);//hello world!
如果利用反射,那就根本就不存在什么可变不可变的了。
4. 字符串常量池
字符串的分配和其他对象分配一样,需要消耗高昂的时间和空间,而且字符串我们使用的非常多,JVM为了提高性能和减少内存的开销,在实例化字符串的时候进行了一些优化:使用字符串常量池。
必知一:当我们创建字符串常量时,JVM首先检查字符串常量池,如果该字符串已经存在常量池中,那么就直接返回常量池中的实例引用。如果字符串不存在常量池中,就会实例化该字符串并将其放到常量池中。由于String字符串的不可变性我们可以十分肯定常量池中一定不存在两个相同的字符串。
Java中的常量池,实际上分为两种形态:静态常量池和运行时常量池。
所谓静态常量池,即*.class文件中的常量池,class文件中的常量池不仅仅包含字符串(数字)字面量,还包含类、方法的信息,占用class文件绝大部分空间。
而运行时常量池,则是jvm虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。
String a = "hello";
String b = "hello";
String c = new String("hello");
上述变量的内存图示:
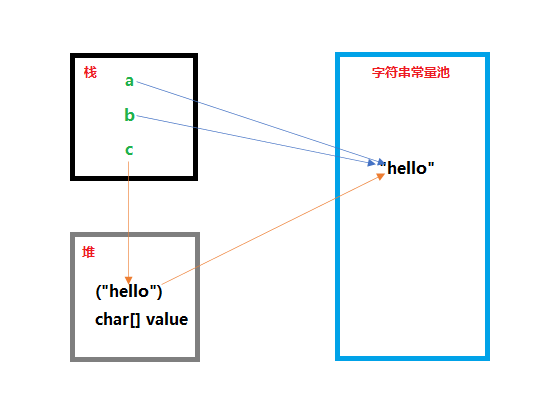
必知二:字面量"+"拼接是在编译期间进行的,拼接后的字符串存放在字符串池中;而字符串引用的"+"拼接运算是在运行时进行的,新创建的字符串放在堆中。
所以String相关的疑问点就迎刃而解了!
String s = " world";
String s1 = "hello";
String s2 = "hello";
System.out.println(s1 == s2);// true
String s3 = new String("hello");
System.out.println(s1 == s3);//false
String s4 = "hello world";
System.out.println(s4 == ("hello" + " world"));//true
String s5 = s1 + s2;
System.out.println(s4 == s5);//false
5. 字符集和编码规则
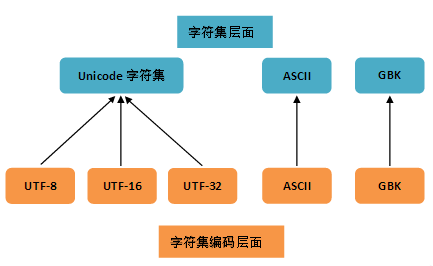
字符集:多个字符的集合。例如GB2312是中国国家标准的简体中文字符集,GB2312收录简化汉字(6763个)及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。
字符编码:把字符集中的字符编码为(映射)指定集合中的某一对象(例如:比特模式、自然数序列、电脉冲),以便文本在计算机中存储和通过通信网络的传递。
字符集和字符编码的关系 :
字符集是书写系统字母与符号的集合,而字符编码则是将字符映射为一特定的字节或字节序列,是一种规则。通常特定的字符集采用特定的编码方式(即一种字符集对应一种字符编码(例如:ASCII、IOS-8859-1、GB2312、GBK,都是即表示了字符集又表示了对应的字符编码,但Unicode不是,它采用现代的模型)),因此基本上可以将两者视为同义词。
字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)
编码规则:将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)
4 对象 引用
1. 何为对象?何为对象的引用?
每种编程语言都有自己的数据处理方式。有些时候,程序员必须注意将要处理的数据是什么类型。你是直接操纵元素,还是用某种基于特殊语法的间接表示(例如C/C++里的指针)来操作对象。所有这些在 Java 里都得到了简化,一切都被视为对象。因此,我们可采用一种统一的语法。尽管将一切都“看作”对象,但操纵的标识符实际是指向一个对象的“引用”(reference)。
—《Java编程思想》
也就是说,在Java中我们操作对象都是通过引用来间接操作对象的。一个引用可以指向多个对象,一个对象也可以被多个引用所指。(相当于C/C++的指针,但又有所差别)
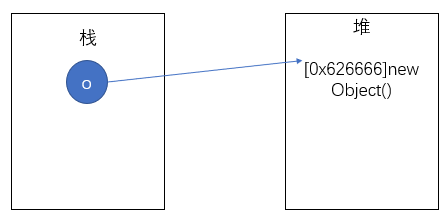
Object o; // 栈空间创建引用变量,此时o默认为null
o = new Object();// 堆空间实例化一个对象,栈空间的引用变量o指向了堆空间中该对象的地址。
Object obj = new Object();// 堆空间实例化对象后,引用obj指向了该地址
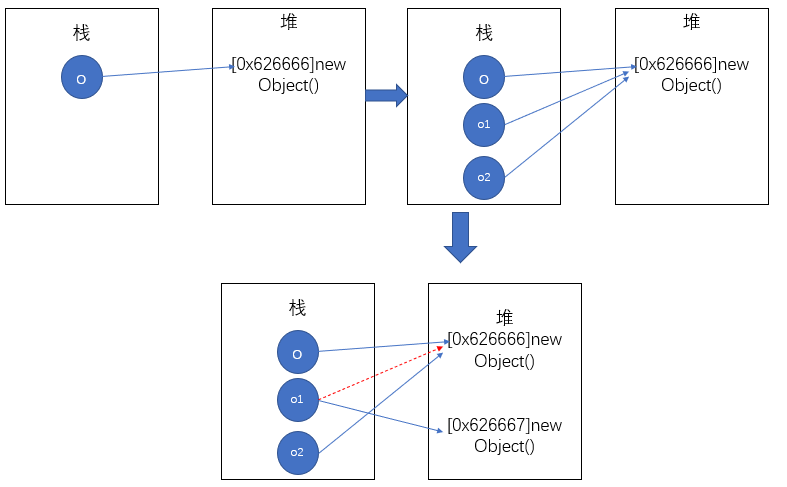
Object o = new Object();
Object o1 = o;
Object o2 = o;
System.out.println(o == o1);// true
System.out.println(o2 == o1);// true
// 一个对象可以被多个 引用变量(对象引用) 同时引用
o1 = new Object();
// 一个引用可以指向不同的对象,但同一时刻只能指向一个
System.out.println(o == o1);// false
如下表达式:
A a1 = new A();
它代表A是类,a1是引用,a1不是对象,new A()才是对象,a1引用指向new A()这个对象。在JAVA里,“=”不能被看成是一个赋值语句,它不是在把一个对象赋给另外一个对象,它的执行过程实质上是将右边对象的地址传给了左边的引用,使得左边的引用指向了右边的对象。JAVA表面上看起来没有指针,但它的引用其实质就是一个指针,引用里面存放的并不是对象,而是该对象的地址,使得该引用指向了对象。在JAVA里,“=”语句不应该被翻译成赋值语句,因为它所执行的确实不是一个赋值的过程,而是一个传地址的过程,被译成赋值语句会造成很多误解,译得不准确。
再如:
A a2;
它代表A是类,a2是引用,a2不是对象,a2所指向的对象为空null;再如:
a2 = a1;
它代表,a2是引用,a1也是引用,a1所指向的对象的地址传给了a2(传址),使得a2和a1指向了同一对象。综上所述,可以简单的记为,在初始化时,“=”语句左边的是引用,右边new出来的是对象。
在后面的左右都是引用的“=”语句时,左右的引用同时指向了右边引用所指向的对象。再所谓实例,其实就是对象的同义词。
小结:
对象,堆中的空间;对象的引用保留了对象在堆中的地址,按C/C++指针理解的话,就是指针(引用)指向了对象。总的来说,我觉得引用本质上就是指针,只不过它和C++指针有所不同,他淡化了C++一些难以理解的抽象概念和用法,比如说在C++中指针可以自增减,Java没有这样的操作,开发者也不用担心自增减所带来一些异常等问题。
一个对象变量并没有实际包含一个对象,而仅仅引用一个对象。在Java中,任何对象变量的值都是对存储在另外一个地方的一个对象的引用。new操作符的返回值也是一个引用。
2. 引用相等和对象状态(内容)相等

(1)对于==,比较的是值是否相等
如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等;
如果作用于引用类型的变量,则比较的是所指向的对象的地址
(2)对于equals方法,注意:equals方法不能作用于基本数据类型的变量,equals继承Object类,比较的是是否是同一个对象
如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;
诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
总结:
通过以上例子可以说明,如果一个类没有自己定义equals()方法,它默认的equals()方法(从Object类继承的)就是使用“”运算符,也是在比较两个变量指向的对象是否是同一对象,此时使用equals()方法和使用“”运算符会得到同样的结果。若比较的是两个独立的对象,则总返回false。如果编写的类希望能够比较该类创建的两个实例对象的内容是否相同,那么必须覆盖equals()方法,由开发人员自己编写代码来决定在什么情况下即可认为两个对象的内容是相同的。
3. 值传递和引用传递
概念 方法参数 Java值传递
错误理解一:值传递和引用传递,区分的条件是传递的内容,如果是个值,就是值传递。如果是个引用,就是引用传递。
错误理解二:Java是引用传递。
错误理解三:传递的参数如果是普通类型,那就是值传递,如果是对象,那就是引用传递。
值调用:方法接受的是调用者提供的值
按引用调用:方法接受的是调用者提供的变量地址
Java程序设计语言总是采用按值调用(call by value),方法得到的是所有参数值的拷贝。
public class CallByTest {
public static void main(String[] args) {
int a = 10;
int b = 20;
change(a, b);
System.out.println(a + " " + b);// 10 20
StringBuilder builder1 = new StringBuilder();
StringBuilder builder2 = new StringBuilder();
builder1.append("hello");
builder2.append("world!");
change(builder1); // hello,world!
swap(builder1, builder2);// hello,world! world!
}
private static void change(StringBuilder builder) {
builder.append(",world!");
}
/**
* Java对象采用的是按引用调用,那么该方法就能够实现交换数据,但是方法并没有改变builder1和builder2对象 * 的引用。说明swap方法参数只是两个对象引用的拷贝,方法交换的是拷贝,当方法退栈之后,拷贝就会被丢弃,对原 * 有对象引用没有影响。
*/
private static void swap(StringBuilder b1, StringBuilder b2) {
StringBuilder temp = b1;
b1 = b2;
b2 = b1;
}
private static void change(int a, int b) {
int temp = a;
a = b;
b =temp;
}
}
总结Java对象参数的使用情况
- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)
- 一个方法可以改变一个对象参数的状态
- 一个方法不能让对象参数引用一个新的对象
4. hashCode和equals方法
重写equals方法的场景:当需要判断两个对象的引用内容相等时,需要重写equals方法
为什么重写equals方法通常有必要重写hashCode方法
重写hashCode的要求
生活中我们用身份证来标识一个人,身份证号码具有唯一性,如果两个人的身份证号一样,那么就说明这两个人是一个人。所以在程序中我们重写equals方法,以id作为判断两个对象是否相等的依据。
public class Person {
String id;// 身份ID,唯一标识
String name;
int age;
...
@Override
public boolean equals(Object otherObject) {
if (otherObject == this) {// 自身性
return true;
}
if (otherObject == null) {
return false;
}
if (!(obj instanceof Person)) {
return false;
}
Person other = (Person) otherObject;
// 身份ID相等则为同一个人 调用Objects.equals()防止NullPointException
return Objects.equals(id, other.id) && other.id.equals(this.id);
}
}
测试
Person p1 = new Person("001", "小明", 18);
Person p2 = new Person("001", "小明明", 18);
System.out.println(p1 == p2);// false 引用肯定不同
System.out.println(p1.equals(p2));//true
==============Set集合测试============================
HashSet<Person> peoples = new HashSet<>();
peoples.add(p1);
peoples.add(p1);// Set集合特性:相同的引用,只会保留一个
peoples.add(p2);// p2 虽然和 p1是同一个人,但因为没有重写hashCode方法,所以还是会存入HashSet中
System.out.println(peoples);//[corejava1.Person@677327b6, corejava1.Person@1540e19d]
程序达到了我们的预期,p1和p2姓名不同但是ID一样(同一个人可能之后改名了),这说明就是同一个人。
p1.equals(p2)并不会调用hashCode方法,所以单单用equals方法就可以完成我们的实际需求为什么还要hashCode?正如Set集合测试那样,使用Set集合存放这两个对象(实质应该是同一个人),Set集合特性不会保留重复元素,但是实际测试结果,Set集合将对象都放入了容器。
重写hashCode(),再次测试就不会出现上述结果了。
@Override
public int hashCode() {
int result = 17;
result = result * 31 + id.hashCode();
return result;
}
重写hashCode的要求:
-
初始化一个整型变量,为此变量赋予一个非零的常数值,通常为
int result = 17 -
对equals方法中用于比较的所有域的属性进行计算,不能包含equals方法中没有的字段,否则会导致相等的对象可能会有不同的哈希值。
(1) 如果是boolean值,则计算f ? 1:0
(2) 如果是byte\char\short\int,则计算(int)f
(3) 如果是long值,则计算(int)(f ^ (f >>> 32))
(4) 如果是float值,则计算Float.floatToIntBits(f)
(5) 如果是double值,则计算Double.doubleToLongBits(f),然后返回的结果是long,再用规则(3)去处理long,得到int
(6) 如果是对象应用,如果equals方法中采取递归调用的比较方式,那么hashCode中同样采取递归调用hashCode的方式。 否则需要为这个域计算一个范式,比如当这个域的值为null的时候,那么hashCode 值为0
(7) 如果是数组,那么需要为每个元素当做单独的域来处理。如果你使用的是1.5及以上版本的JDK,那么没必要自己去 重新遍历一遍数组,java.util.Arrays.hashCode方法包含了8种基本类型数组和引用数组的hashCode计算,算法同上,
@Override public int hashCode() { int result = 17; result = 31 * result + mInt; result = 31 * result + (mBoolean ? 1 : 0); result = 31 * result + Float.floatToIntBits(mFloat); result = 31 * result + (int)(mLong ^ (mLong >>> 32)); long mDoubleTemp = Double.doubleToLongBits(mDouble); result =31 * result + (int)(mDoubleTemp ^ (mDoubleTemp >>> 32)); result = 31 * result + (mString == null ? 0 : mMsgContain.hashCode()); result = 31 * result + (mObj == null ? 0 : mObj.hashCode()); return result; }为什么是计算中会有17和31,请参考正确重写hashCode方法、通用的Java hashCode重写方案
小结
-
equal()相等的两个对象他们的hashCode()肯定相等,也就是用equal()对比是绝对可靠的。
-
hashCode()相等的两个对象他们的equal()不一定相等,也就是hashCode()不是绝对可靠的。
因为散列表肯定用到equals,所以说对于需要大量并且快速的对比的话如果都用equal()去做显然效率太低,所以解决方式是,每当需要对比的时候,首先用hashCode()去对比,如果hashCode()不一样,则表示这两个对象肯定不相等(也就是不必再用equal()去再对比了),如果hashCode()相同,此时再对比他们的equal(),如果equal()也相同,则表示这两个对象是真的相同了,这样既能大大提高了效率也保证了对比的绝对正确性。
额外扩展
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。
hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。
虽然,每个Java类都包含hashCode() 函数。但是,仅仅当创建并某个“类的散列表,该类的hashCode() 才有用(作用是:确定该类的每一个对象在散列表中的位置;其它情况下(例如,创建类的单个对象,或者创建类的对象数组等等),类的hashCode() 没有作用。
上面的散列表,指的是:Java集合中本质是散列表的类,如HashMap,Hashtable,HashSet。
也就是说:hashCode() 在散列表中才有用,在其它情况下没用。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
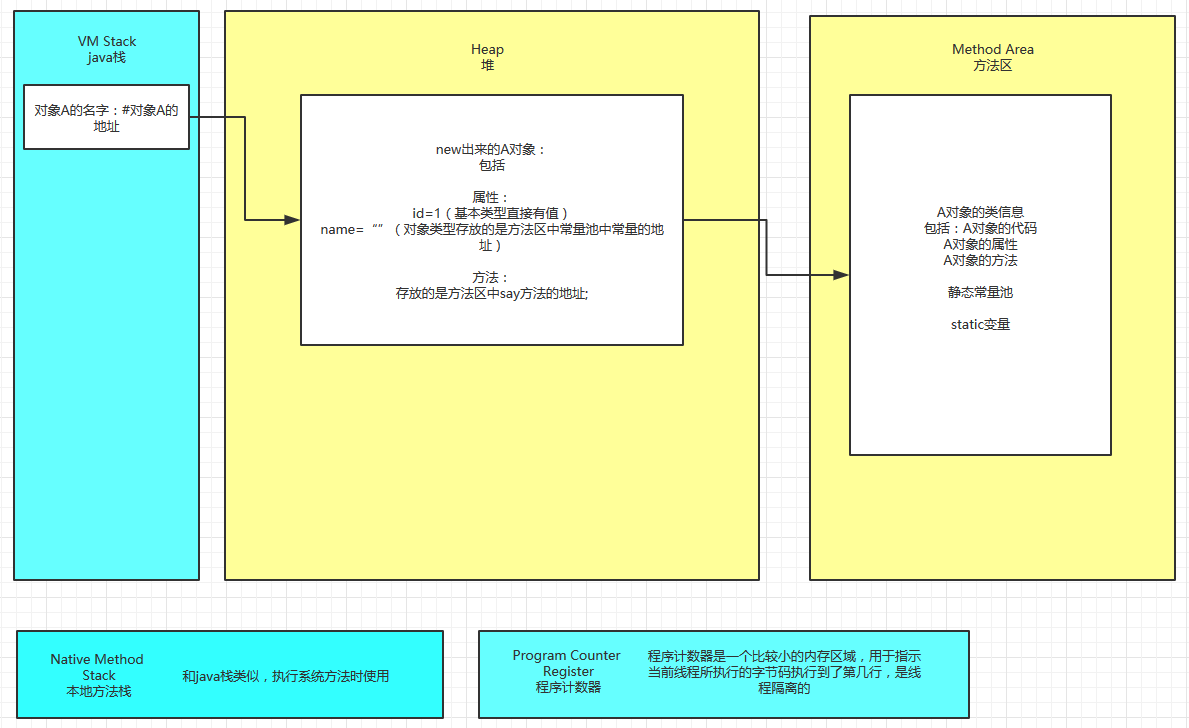
5. 栈、堆、方法区

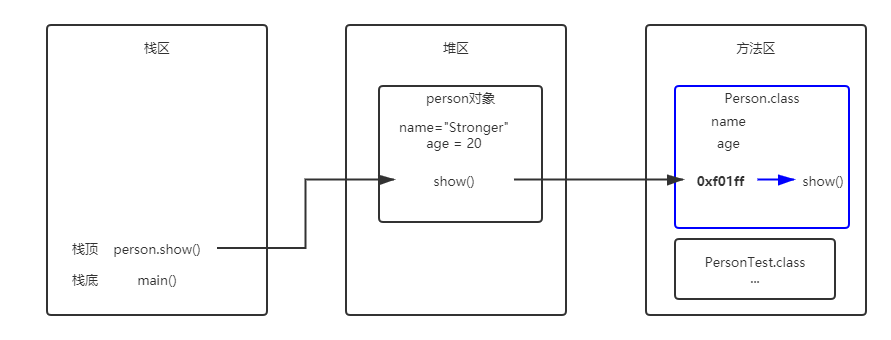
public class Person {
String name;
int age;
public void show() {
System.out.println(name + " age:" + age);
}
}
class PersonTest {
public static void main(String[] args) {
Person person = new Person();
person.name = "Stronger";
person.age = 20;
person.show();
}
}
6. 浅拷贝和深拷贝
1. 浅拷贝(Shallow Copy)
浅拷贝,按位拷贝对象,会创建新对象,这个对象的属性值有着和原始对象的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果是引用类型,拷贝的是引用类型的内存地址,因此如果其中一个对象状态发生改变,就会影响到另一个对象。(值拷贝[变量值引用值])
2. 深拷贝(Deep Copy)
深拷贝,拷贝所有属性,如果属性为引用类型,则会为该属性新开辟一块独立的内存空间,拷贝属性指向的动态分配的内存。(内存拷贝)
总结:两者的差异之处,浅拷贝,值拷贝;深拷贝,内存拷贝。
如何实现拷贝?
要拷贝的类必须实现Cloneable接口,如果要在外部类调用则需要,"修改"clone()方法
Object中的clone函数,方法修饰符为protected,说明只能在实现Cloneable接口的类(子类)内部调用,默认都继承自超类,如果子类在没有实现Cloneable接口的前提下调用会抛出exception at run time.;若类实现了Cloneable接口,并重写了方法,默认为protected,要想在外部调用,必须将修饰符改为public。
protected native Object clone() throws CloneNotSupportedException;
示例
class Address implements Cloneable{
private long postId;
private String addrInfo;
...
/**
* 默认方法的修饰符为protected,为了在外部能够调用
* 修改方法修饰符
* @return
* @throws CloneNotSupportedException
*/
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
如何实现深拷贝?
在一个类中的属性成员如果是一个引用类型的变量,浅拷贝默认是拷贝的引用的对象地址,更改拷贝后对象的状态会影响之前对象的状态,这时候就要使用深拷贝,当拷贝引用类型的属性时,同时拷贝动态的内存空间。
示例:
public class Person implements Cloneable{
private String id;// 身份ID,唯一标识
private String name;
private int age;
private Address address;
...
/**
* 默认方法的修饰符为protected,为了在外部能够调用
* 修改方法修饰符
* @return
* @throws CloneNotSupportedException
*/
@Override
public Object clone() throws CloneNotSupportedException {
Person person = (Person) super.clone();
Address address = person.getAddress();
Address addrDeepCopy = (Address) address.clone();
person.setAddress(addrDeepCopy);
return person;
}
}
class Address implements Cloneable{
private long postId;
private String addrInfo;
...
/**
* 默认方法的修饰符为protected,为了在外部能够调用
* 修改方法修饰符
* @return
* @throws CloneNotSupportedException
*/
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
7. main方法传参
java 类 param1, parm2, param3
3. 对象与类
3.1 类
类:具体事物的抽象。
类是描述了一组有相同特性(属性)和相同行为(方法)的一组对象的集合。
类之间的关系:
-
依赖(uses-a)—如果一个类的方法操纵另一个类的对象,我们就睡一个类依赖于另一个类。
-
聚合(has-a)—类A的对象包含类B的对象
-
继承(is-a)—如果类A继承自类B,类A不但包括从类B继承的方法,还会拥有一些额外的功能。
表示类之间关系的UML符号

注:开发中应尽可能地将相互依赖的类减至最少。如果类A不知道类B的存在,它就不会关心B的任何改变(B的任何改变不会对类A产生影响)。用软件工程的术语来说,就是让类之间的耦合度最小。
在一个源文件中,只能有一个公有类,但可以有任意数目的非公有类。
3.1.1 类的定义
格式
[修饰符] [static] [final] [abstract] [strictfp] class 类名 [extends 父类名] [implements 接口名] {
...
}
3.1.2 修饰符
Java中的修饰符包括访问修饰符和非访问修饰符
修饰符上面指的就是访问权限修饰符了,包括
- public:对所有类课件。使用对象:类、接口、变量、方法
- protected:对同一包内的类和所有子类可见。适用对象:变量、方法。注:不能修饰类(外部类)
- private:类内可见。适用对象:变量、方法。注:不能修饰类(外部类)
- 默认(缺省值):什么也不写,同一包内可见。使用对象:类、接口、变量、方法
访问权限:public > protected > default > private
非访问修饰符
- static 修饰符,用来修饰类方法和类变量。(不能修饰外部类,内部类可以)
- final 修饰符,用来修饰类、方法和变量,final 修饰的类不能够被继承,修饰的方法不能被继承类重新定义,修饰的变量为常量,是不可修改的。
- abstract 修饰符,用来创建抽象类和抽象方法。
- synchronized 和 volatile 修饰符,主要用于线程的编程。
3.2 对象
对象:类的实例。
类是概念模型,定义对象的所有特性和所需的操作,对象是真实模型,是具体的一个实体。类是构造对象的模板或蓝图。
对象的三个主要特性:
- 对象的行为(behavior)—可以对对象施加哪些操作,或可以对对象施加哪些方法
- 对象的状态(state)—当施加那些方法时,对象如何响应
- 对象标识(identity)—如何辨别具有相同行为与状态的不同对象
面向对象的三大核心特性:封装、继承、多态
3.2.1 对象构造
实例化对象的方法:
-
通过new 类即调用构造函数实例化类
-
调用 java.lang.Class 或者java.lang.reflect.Constuctor 类的 newlnstance()实例方法(默认通过无参构造函数构造)
java.lang.Class Class 类对象名称 = java.lang.Class.forName(要实例化的类全称); 类名 对象名 = (类名)Class类对象名称.newInstance(); -
调用对象的clone()方法(必须实现Cloneable接口)
-
序列化
# nowcoder:
构造方法不能被static、final、synchronized、abstract、native修饰,但可以被public、private、protected修饰。
识别合法的构造方法;
1 构造方法可以被重载,一个构造方法可以通过this关键字调用另一个构造方法,this语句必须位于构造方法的第一行;
2 当一个类中没有定义任何构造方法,Java将自动提供一个缺省构造方法;
3 子类通过super关键字调用父类的一个构造方法;
4 当子类的某个构造方法没有通过super关键字调用父类的构造方法,通过这个构造方法创建子类对象时,会自动先调用父类的缺省构造方法
5 构造方法不能被static、final、synchronized、abstract、native修饰,但可以被public、private、protected修饰;
6 构造方法不是类的成员方法;
7 构造方法不能被继承。
3.2.2 重载
重名不重参,返回值无关
构造函数重载:一个类有多个构造器,针对不同的构造器提供的初始化构造条件(参数类型或者个数)来区别调用哪一个。
成员方法重载:定义和构造函数的意思一致。方法名相同,参数类型或者个数不同。
Java允许重载任何方法,而不只是构造器方法。因此要完整地描述一个方法,需要指出方法名以及参数类型。这叫做方法的签名(signature)
例如String类中indexOf的方法签名
indexOf(int)
indexOf(int, int)
indexOf(String)
indexOf(String, int)
注:返回类型不是方法签名的一部分。不能有两个名字相同、参数类型也相同却返回类型不同的方法。
默认域初始化:如果在构造器中没有显式地给域赋初值,那么就会被自动地赋为默认值,数值类型为0,布尔值为false、对象引用为null。
默认构造器相关:当类没有提供任何构造器的时候,系统才会提供一个默认的构造器。默认的构造方法不包含任何参数,并且方法体为空。如果在编写类的时候,给出了一个或多个构造方法,则系统不会再提供默认构造方法。
3.3 静态域与静态方法
静态域:如果将域定义为static,每个类中只有一个这样的域。而一个对象对于所有的实例域却都有自己的一份拷贝。
比如有1000个Employee对象,则有1000个实例域id。但是,只有一个静态域nextId。即使没有一个Employee对象,静态域nextId也存在。它属于类,而不属于任何一个独立的对象。
静态方法:静态方法是一种不能面向对象实施操作的方法。(不依赖于对象)
不能调用类中非静态属性,可以调用静态属性。
静态代码块&构造函数执行顺序:static->constructor,若类之间存在继承,执行顺序为:父类static->子类static->父类构造->子类构造(静态代码块优先执行)
3.3 静态块和构造块
静态块
- static修饰,所属类,主要用来为类的属性进行初始化,随着类的加载而执行,且只能执行一次。
- 静态代码优先于非静态代码执行,如果类中存在多个静态块,执行顺序与定义顺序相关。
构造块
-
类中被{...}所包裹的程序块,所属对象,主要用来为对象初进行初始化操作(很少),new一次执行一次。
-
执行顺序优先于构造函数,多个构造块执行顺序和定义顺序呢相关。
构造块和构造函数的区别:
构造代码块是给所有对象进行统一初始化,而构造函数是给对应的对象初始化,因为构造函数是可以多个的,运行哪个构造函数就会建立什么样的对象,但无论建立哪个对象,都会先执行相同的构造代码块。也就是说,构造代码块中定义的是不同对象共性的初始化内容。
3.4 继承
继承:继承已存在的类就是复用(继承——这些类的方法和域。在此基础上,还可以添加一些新的方法和域,以满足新的需求。
继承的核心:代码复用
继承是一个“是不是”的关系,而接口实现则是“有没有“的关系
3.4.1 this&super
this用途
1)引用引式参数(调用实例方法,一般不显示使用this)
2)调用该类其他的构造器
super用途
1)调用超类的方法
2)调用超类的构造器
注意点:
1)this、super在调用本类或者超类的构造器的时候,调用语句只能出现在第一行,且this和super在构造器中只能出现一个(不共存)
2)调用超类的方法必须有super参数super.xxx(...),否则执行的是this(当前类)所调用的方法this.xxx(...)
3)this是一个对象的引用,super不是
3.4.2重载和重写
方法重载:多个同名函数同时存在,具有不同的参数个数或者类型,调用方法根据类型个数和次序确定调用哪一个。
方法重写:子类修改了默认从父类中继承的方法。
重载和重写的区别(一图概括了重写和重载时的注意点)
| 作用位置 | 修饰符 | 返回值 | 方法名 | 参数 | 抛出异常(类型) | |
|---|---|---|---|---|---|---|
| 重载(overload) | 同类中 | 无关 | 无关 | 相同 | 不同 | 无关 |
| 重写(override) | 子类和父类 | 大于等于 | 小于等于 | 相同 | 相同 | 小于等于 |
重写函数签名(方法名、参数类型、次序)必须相同,子类返回值类型必须小于等于父类返回值类型,修饰符权限父类小于等于子类。
方法重载无关返回值和修饰符。
3.4.3 多态
1)什么是多态?
同一个行为对于不同事物具有多种不同的表现形式或形态叫做多态。
不同对象对同一消息做出不同的反应或行为。
例:就像上课铃响了,上体育课的学生跑到操场上站好,上语文课的学生在教室里坐好一样。
2)多态的分类
编译时多态:根据方法参数类型、个数和次序方法来确定调用的哪一个方法,对应的就是方法重载。
运行时多态:程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定。主要是靠方法重写实现。
3)Java实现多态的三个必要条件:继承、重写和向上转型
- 继承:在多态中必须存在有继承关系的子类和父类。
- 重写:子类对父类中某些方法进行重新定义,在调用这些方法时就会调用子类的方法。
- 向上转型:在多态中需要将子类的引用赋给父类对象,只有这样该引用才既能可以调用父类的方法,又能调用子类的方法。
分析多态问题的原则
- 向上转型是自动的,不需要强转。
- 向下转型要强转。必须要让父类知道它要转换成哪个具体子类。
- 父类引用子类对象,子类重写了父类的方法,调用父类的方法,实际调用的是子类重写了的父类的该方法。
总结:三定义两方法,父类定义子类构建、接口定义实现类构建和抽象类定义实体类构建。两方法,方法重载和方法重写。
代码示例:
public abstract class Person {
private String name;
public abstract void getDescription();
public Person() {}
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
public class Employee extends Person{
static {
System.out.println("Employee static ...");
}
private String name;
private double salary;
private LocalDate hireDay;
public Employee() {
System.out.println("Employee()...");
}
public Employee(String name, double salary, int year, int month, int day) {
super(name);
System.out.println("Employee constructor...");
this.name = name;
this.salary = salary;
this.hireDay = LocalDate.of(year, month, day);
}
// getter ...
public void raiseSalary(double byPercent) {
double raise = salary * byPercent / 100;
salary += raise;
}
@Override
public void getDescription() {
System.out.println("Employee getDescription...");
}
}
public class Manager extends Employee {
static {
// 静态代码块优先,父类static->子类static->父constructor—>子constructor
System.out.println("Manger static ...");
}
private double bonus;
public Manager() {
// super();默认存在于每个构造函数的第一行,前提是父类必须存在一个无参构造
// 或者显示调用super有参构造
System.out.println("Manger()...");
}
public Manager(String name, double salary, int year, int month, int day) {
// Manger类假如没有无参构造,并且Employee也没有无参构造,
// 那么必须必须显示的调用父类的某个构造初始化父类,否则编译不通过(如下)
super(name, salary, year, month, day);
bonus = 0;
}
public double getSalary() {
double baseSalary = super.getSalary();
return baseSalary + bonus;
}
public void setBonus(double bonus) {
this.bonus = bonus;
}
}
测试:
public void testInherit() {
Manager boss = new Manager("Stronger", 8000, 2020, 11, 11);
boss.setBonus(2000);
Employee[] employees = new Employee[3];
employees[0] = boss; // 1. 父类可以引用子类的对象
// employees[0].setBonus(2000); error 现在类型父为Employee,子类的方法不可见,没有setBonus方法
employees[1] = new Employee("Gang", 5000, 2020, 11, 10);
employees[2] = new Employee("Long", 6000, 2020, 11, 9);
for (Employee e : employees) {
// 2. 动态绑定(dynamic binding): employee[0]调用的是Manger里的方法
System.out.println(e.getName() + " salary:" + e.getSalary());
}
// 3. Java中,子类数组的引用可以转换成超类数组的引用;但是,不能将
// 一个超类的引用赋给子类变量。
Manager[] managers = new Manager[10];
Employee[] staff = managers;
//staff[0] = new Employee("Long", 6000, 2020, 11, 9); 编译通过,但是运行不通过抛出
// java.lang.ArrayStoreException
// 4.强制类型转化 对象强转的一个原因是要适用对象的全部功能,前提是强转后的对象类型是特定类的实例
// employees[0]强转后必须是Manger类型
Manager m = (Manager) employees[0];
System.out.println(m.getSalary());
// 若强转后的对象不是Manger类型
// m = (Manager) employees[1]; 运行抛出java.lang.ClassCastException
// 所以说我们可以通过 instanceof运算符判断某个对象是否为某类的实例
if (employees[1] instanceof Manager) {
m = (Manager) employees[1];
}
// 5. 抽象类
// new Person(); ERROR 抽象类不可以实例化
Person p = new Employee();// 抽象类的变量只能引用非抽象子类的对象
p.getDescription();
}
3.4.4 Object类
Object是所有类的超类,可以使用Object类型的变量引用任何类型的对象。Object类型的变量只能用于作为各种值的通用持有者。要想对其中的内容进行具体的操作,还需要清除对象的原始类型,并进行相应的类型转换。
在Java中,只有基本类型不是对象,例如,数值、字符和布尔类型的值都不是对象。所有的数组类型,不管是对象数组还是基本类型的数组都扩展了Object类。
3.4.5 自动装箱和自动拆箱
装箱:将基本数据类型转化为包装类型。
拆箱:将包装类型转化为基本数据类型。
// 自动装箱
Integer autoBoxing = 99;
// 反编译之后其实执行了 Integer.valueOf(99);
// 自动拆箱
int unboxing = autoBoxing;
//反编译:autoBoxing.intValue();
反编译:javap -c 类名

支持自动拆装箱的类型:
必知必会
Integer相关源码
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
示例
@Test
public void testWrapper() {
/*
1. 包装类型比较
首先a、b、c、d变量进行了自动装箱,将基本类型转化为包装类型
"=="比较的是引用的对象是否为同一个
a == b为true,[-128,127]从缓冲中取,得到的是同一个对象的引用
c == d为false,number<-128 && number> 127则是会实例化对象new Integer(number);
*/
Integer a = 100;
Integer b = 100;
Integer c = 200;
Integer d = 200;
System.out.println(a == b); // true
System.out.println(c == d); // false
/*
2. 基本类型和包装类型进行 == 、+、-、*、/运算或者
当操作符一侧为封装类型的表达式(包装类型),
封装类自动拆箱为基本类型,所以比较和运算的都是基本类型。
*/
int a1 = 100;
int c1 = 300;
System.out.println(a == a1); // true
System.out.println((a+c) == c1); // true
/*
3. 包装类型在拆包的时候可能会引发空指针异常
*/
Integer d1 = null;
d1.intValue();
}
总结:
1)基本类型与包装类型进行比较的时候,包装类型会自动拆箱,按值比较。
2)包装类型与包装类型进行比较时
2.1)new实例化的包装类型比较永远为false。
2.2)非new的,如果范围在[-128,127]直接,比较按值比较,否则符合(2.1)这种情况。
public static void main(String[] args) {
// 基本类型与包装类型的比较
int a1 = 127;
Integer a2 = 127;
Integer a3 = new Integer(127);
System.out.println(a1 == a2);
System.out.println(a1 == a3);
int a4 = 128;
Integer a5 = 128;
Integer a6 = new Integer(128);
System.out.println(a4 == a5);//true
System.out.println(a4 == a6);//true
// 包装类型的比价
//1.非new产生,反编译实际是调用了Integer.valueOf()
// 方法来生成一个Integer类型的对象。而Integer.valueOf()
// 方法中当其范围属于[-128,127]之间则从缓冲区中取,否则
// new一个对象。
Integer b1 = 127;
Integer b2 = 127;
Integer b3 = 128;
Integer b4 = 128;
System.out.println(b1 == b2);//true
System.out.println(b3 == b4);//false
//2.new比较,不会相等,除非自身比较
Integer c1 = new Integer(127);
Integer c2 = new Integer(127);
Integer c3 = new Integer(128);
Integer c4 = new Integer(128);
System.out.println(c1 == c2);//false
System.out.println(c3 == c4);//false
}
3.5 枚举类
枚举类型本质上是类类型,枚举类是一种特殊的类。
应用场景:定义常数集合
public enum Weekday {
MON, TUE, WED, THU, FRI, SAT,SUN;
}
枚举类基础知识
-
枚举enum是一个特殊的class,相当于final修饰,不能被继承。
-
构造函数强制私有化,所以说不可以在外部实例化对象,有一个默认空参构造。
-
当使用枚举类的时候,只需通过类名.属性名访问,枚举类对象自动调用构造函数实例化,类中所有变量全部实例化,且只实例化一次。
-
枚举类的所有实例必须在枚举类的第一行显示列出,否则这个枚举类永远都不能产生实例
-
获取枚举常量的方法
类名.常量名
类名.valueOf(常量名 String)返回一个Enum实体
自定义枚举类
public enum EnumEntity {
FIRST,SECOND,THIRD
}
反编译之后的代码,通过浏览编译后的代码,也就能理解为什么enum不能继承,为什么可以直接"类名.常量名"引用...
public final class EnumEntity extends java.lang.Enum<EnumEntity> {
public static final EnumEntity FIRST;
public static final EnumEntity SECOND;
public static final EnumEntity THIRD;
public static EnumEntity[] values();
Code:
0: getstatic #1 // Field $VALUES:[LEnumEntity;
3: invokevirtual #2 // Method "[LEnumEntity;".clone:()Ljava/lang/Object;
6: checkcast #3 // class "[LEnumEntity;"
9: areturn
public static EnumEntity valueOf(java.lang.String);
Code:
0: ldc #4 // class EnumEntity
2: aload_0
3: invokestatic #5 // Method java/lang/Enum.valueOf:(Ljava/lang/Class;Ljava/lang/String;)Ljava/lang/Enum;
6: checkcast #4 // class EnumEntity
9: areturn
static {};
Code:
0: new #4 // class EnumEntity
3: dup
4: ldc #7 // String FIRST
6: iconst_0
7: invokespecial #8 // Method "<init>":(Ljava/lang/String;I)V
10: putstatic #9 // Field FIRST:LEnumEntity;
13: new #4 // class EnumEntity
16: dup
17: ldc #10 // String SECOND
19: iconst_1
20: invokespecial #8 // Method "<init>":(Ljava/lang/String;I)V
23: putstatic #11 // Field SECOND:LEnumEntity;
26: new #4 // class EnumEntity
29: dup
30: ldc #12 // String THIRD
32: iconst_2
33: invokespecial #8 // Method "<init>":(Ljava/lang/String;I)V
36: putstatic #13 // Field THIRD:LEnumEntity;
39: iconst_3
40: anewarray #4 // class EnumEntity
43: dup
44: iconst_0
45: getstatic #9 // Field FIRST:LEnumEntity;
48: aastore
49: dup
50: iconst_1
51: getstatic #11 // Field SECOND:LEnumEntity;
54: aastore
55: dup
56: iconst_2
57: getstatic #13 // Field THIRD:LEnumEntity;
60: aastore
61: putstatic #1 // Field $VALUES:[LEnumEntity;
64: return
}
枚举类常用方法
int compareTo(E o): 该方法用于与制定枚举对象比较顺序,同一个枚举实例只能与相同类型的枚举实例比较。如果该枚举对象位于指定枚举对象之后,则返回正整数;反之返回负整数;否则返回零。
static values(): 返回一个包含全部枚举值的数组,可以用来遍历所有枚举值。
String name(): 返回此枚举实例的名称,即枚举值。
ordinal():返回实例声明时的次序,从 0 开始。
static valueOf(): 返回带指定名称的指定枚举类型的枚举常量,名称必须与在此类型中声明枚举常量所用的标识符完全匹配
boolean equals()方法: 比较两个枚举类对象的引用。
注:因为枚举量在JVM中只会保存一个实例,所以枚举常量比较直接使用"=="比较即可
枚举类综合案例:
public enum EnumEntity {
/**
* (1)下面定义了无参枚举和有参枚举变量,***枚举变量
* 必须写在所有其他成员基本变量(int String...)的之前***
* 每个枚举变量都是EnumEntity的实例,每个成员变量
* 都是final static修饰,可以直接 类名.变量名 使用;
* (2)每个枚举变量都有一个默认的序号,下标从零开始;
* (3)若定义了有参枚举变量,那么也要添加相应的有参
* 构造函数。默认都是private修饰不可修改,不可实例化
*/
FIRST,SECOND,THIRD,
ONE("first"),TWO("second"),THREE("second"),
SPRING("Mar", "春天"), SUMMER("June", "夏天"), AUTUMN("Sep", "秋天");
private String typeName;
private String month;
private String season;
/**
* 实例化对象的时候,隐式自动调用构造方法,无参调无参,有参调有参
*/
EnumEntity(){
}
EnumEntity(String typeName) {
this.typeName = typeName;
}
EnumEntity(String month, String season) {
this.month = month;
this.season = season;
}
/**
* 根据类型名称返回枚举实例
* @param typeName 类型名称
* @return Enum
*/
public static EnumEntity fromTypeNameToType(String typeName) {
EnumEntity[] values = EnumEntity.values();
for (EnumEntity value : values) {
if (value.typeName != null) {
if (typeName.equals(value.typeName))
return value;
}
}
return null;
}
geter...setter
}
3.6 反射
什么是反射?
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制。
3.6.1 Class对象
在程序运行期间,Java运行时系统始终为所有的对象维护一个被称为运行时的类型标识,这个信息跟踪着每个对象所属的类。虚拟机利用运行时类型信息选择相应的方法执行。然而可以通过专门的Java类访问这些信息。保存这些信息的类被称为Class。
获取Class对象的方法
-
Class.forName("全类名");将字节码文件加载进内存,返回Class对象 -
- 多用于配置文件,将类名定义在配置文件中。读取文件,加载类
-
类名.class通过类名的属性class获取 -
- 多用于参数的传递
-
对象.getClass() -
- 多用于对象的获取字节码的方式
- 基本类型的封装类是通过
封装类.TYPE来获取对应的基本类型的类实例
注意:
1)一个Class对象实际上表示的是一个类型,而这个类型未必一定是一种类。比如,int不是类,但int.class是Class类型的对象。比如说获取int类型的类实例应该是int.class,而不是Integer.class,Integer是int的封装类。
2)同一个字节码文件(*.class)在一次程序运行过程中,只会被加载一次,不论通过哪一种方式获取的class对象都是同一个。
3)Class类实际上是一个泛型类。只不过它将已经抽象的概念更加复杂化了。
利用反射分析类的结构
public class ReflectionTest {
public static void main(String[] args) throws ClassNotFoundException {
String cssName = null;
if (args.length > 0) {
cssName = args[0];
} else {
Scanner scanner = new Scanner(System.in);
cssName = scanner.next();
}
Class<?> cls = Class.forName(cssName);
Class<?> supercl = cls.getSuperclass();
String modifies = Modifier.toString(cls.getModifiers());
if (modifies.length() > 0) {
System.out.print(modifies + " ");
}
System.out.print("class " + cls.getName());
if (supercl != null && supercl != Object.class) {
System.out.print(" extends " + supercl.getName());
}
System.out.print("\n{\n");
printConstructors(cls);
System.out.println();
printMethods(cls);
System.out.println();
printFields(cls);
System.out.println("}");
}
private static void printConstructors(Class cl) {
Constructor[] constructors = cl.getDeclaredConstructors();
for (Constructor c : constructors) {
String name = c.getName();
System.out.print(" ");
String modifiers = Modifier.toString(c.getModifiers());
if (modifiers.length() > 0) {
System.out.print(modifiers + " ");
}
System.out.print(name + "(");
Class[] parameterTypes = c.getParameterTypes();
for (int i = 0; i < parameterTypes.length; i++) {
if (i > 0)
System.out.print(", ");
System.out.print(parameterTypes[i].getName());
}
System.out.println(");");
}
}
private static void printMethods(Class cl) {
Method[] methods = cl.getDeclaredMethods();
for (Method m : methods) {
Class<?> retType = m.getReturnType();
String name = m.getName();
String modifiers = Modifier.toString(m.getModifiers());
System.out.print(" ");
// print modifies, return type and method name
if (modifiers.length() > 0) {
System.out.print(modifiers + " ");
}
System.out.print(retType.getName() + " " + name + "(");
Class[] parameterTypes = m.getParameterTypes();
for (int i = 0; i < parameterTypes.length; i++) {
if (i > 0)
System.out.print(", ");
System.out.print(parameterTypes[i].getName());
}
System.out.println(");");
}
}
private static void printFields(Class cl) {
Field[] fields = cl.getDeclaredFields();
for (Field f : fields) {
Class<?> type = f.getType();
String modifiers = Modifier.toString(f.getModifiers());
System.out.print(" ");
if (modifiers.length() > 0) {
System.out.print(modifiers + " ");
}
System.out.print(type.getName());
System.out.println(";");
}
}
}
---------------------------test java.lang.Double---------------------------
// 打印结果
public final class java.lang.Double extends java.lang.Number
{
public java.lang.Double(double);
public java.lang.Double(java.lang.String);
public boolean equals(java.lang.Object);
public static java.lang.String toString(double);
public java.lang.String toString();
public int hashCode();
public static int hashCode(double);
public static double min(double, double);
public static double max(double, double);
public static native long doubleToRawLongBits(double);
public static long doubleToLongBits(double);
public static native double longBitsToDouble(long);
public volatile int compareTo(java.lang.Object);
public int compareTo(java.lang.Double);
public byte byteValue();
public short shortValue();
public int intValue();
public long longValue();
public float floatValue();
public double doubleValue();
public static java.lang.Double valueOf(java.lang.String);
public static java.lang.Double valueOf(double);
public static java.lang.String toHexString(double);
public static int compare(double, double);
public static boolean isNaN(double);
public boolean isNaN();
public static boolean isFinite(double);
public static boolean isInfinite(double);
public boolean isInfinite();
public static double sum(double, double);
public static double parseDouble(java.lang.String);
public static final double;
public static final double;
public static final double;
public static final double;
public static final double;
public static final double;
public static final int;
public static final int;
public static final int;
public static final int;
public static final java.lang.Class;
private final double;
private static final long;
}
Skill Points:
反射机制相关的类
| 类名 | 用途 |
|---|---|
| Class类 | 代表类的实体,在运行的Java应用程序中表示类和接口 |
| Field类 | 代表类的成员变量(成员变量也称为类的属性) |
| Method类 | 代表类的方法 |
| Constructor类 | 代表类的构造方法 |
Modifier(修饰符相关类)
* 返回对应modifiers中位设置的修饰符的字符串表示
static String toString(int modifiers);
* 检测方法名中对应的修饰符在modifiers值中的位
static boolean is修饰符(int modifiers);
4. 接口
4.1 接口概述
1)什么是接口?
接口是一系列方法的声明,是一些方法特征的集合,一个接口只有方法的特征没有方法的实现,因此这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的行为。
现实中的接口:接口不是类,而是对类的一组需求描述,这些类要遵从接口描述的统一格式进行定义。换句话说,接口就是制定各种功能特征的规范,而不实现这些规范的细节。
public interface InterfaceOne {
int a = 10;
void say();
}
// 反编译后的代码
// class version 52.0 (52)
// access flags 0x601
public abstract interface InterfaceOne {
// compiled from: InterfaceOne.java
// access flags 0x19
public final static I a = 10
// access flags 0x401
public abstract say()V
}
通过反编译之后,我们可以得知接口的特性
2)接口的特性
- 接口中方法默认是抽象方法,且会自动的添加
public abstract - 在接口中声明的变量其实都是常量,将隐式地声明为
public static fina,所以接口中定义的变量必须初始化。不允许使用其他修饰符(public、default除外JDK8)。 - 接口中没有构造方法,不能被实例化
- 接口支持多继承(必须继承接口而非类)
4.2 抽象类
抽象类:abstract修饰的类叫做抽象类,类是具体事物的抽象,而抽象类则是对类的抽象,也可以说是对具体事物的进一步抽象。
抽象类的约定
1)abstract修饰,类中方法访问修饰符不允许为private,只能是public或protected。(private组织了创建抽象类让其他类继承从而实现方法)
2)不能被实例化,可以有成员变量、成员方法、构造方法。
3)继承抽象方法的子类必须重写该方法,否则该子类也必须声明为抽象类。
4)抽象类中不一定包含抽象方法,但是有抽象方法的类一定是抽象类。
5)继承体系是一种is...a的关系
总之,抽象类除了不能被实例化和其他的一些小细节外,其余的和普通的类用法没有什么区别
4.3 抽象类与接口的区别
接口是对动作(行为)的抽象,抽象类是对类(事物本质)的抽象。抽象类表示的是这个对象是什么,接口表示的是这个对象能做什么。
抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
不同点:
- 接口解决了java单继承的问题,抽象类不行
- 接口只有方法的定义,不能有方法的实现,
java 1.8中可以定义default方法体,而抽象类可以有定义与实现,方法可在抽象类中实现。 - 接口强调特定功能的实现,而抽象类强调所属关系(is-a)。
设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。
什么是模板式设计?最简单例子,大家都用过ppt里面的模板,如果用模板A设计了ppt B和ppt C,ppt B和ppt C公共的部分就是模板A了,如果它们的公共部分需要改动,则只需要改动模板A就可以了,不需要重新对ppt B和ppt C进行改动。
而辐射式设计,比如某个电梯都装了某种报警器,一旦要更新报警器,就必须全部更新。也就是说对于抽象类,如果需要添加新的方法,可以直接在抽象类中添加具体的实现,子类可以不进行变更;而对于接口则不行,如果接口进行了变更,则所有实现这个接口的类都必须进行相应的改动。
如何选择抽象类和接口?
根据上述理解去选择,事物选择类,行为动作选接口。
4.4 jdk8接口新特性
1)接口中可定义静态方法
静态方法必须通过接口类进行调用
2)接口中可定义默认方法
default方法必须通过实现类的对象来调用
注:如果多个接口中存在同样的static和default方法,并且一个实现类中实现了多个这样的接口,会怎样?
static函数签名相同的方法:编译正常通过,因为静态方法可以直接通过类名调用。
default函数签名相同的方法:编译报错,实现类必须重写该方法,解决二义性。如果想调用父类方法,可以通过接口名.super.function
4.5 接口示例(Arrays.sort)
java.lang.Comparable<T>
int compareTo(T other)
用这个对象与other进行比较。如果这个对象小于 other则返回负值,如果相等则返回0;否则返回正值
java.util.Arrays
static void sort(Object[] a)
使用mergesort算法对象数组a中的元素进行排序。 要求数组中的元素必须属于实现了Comparable接口的类,并 且元素之间必须是可比较的。【默认升序排序】
下面是对Employee数组进行排序的代码
public class Employee implements Comparable<Employee>{
static {
//System.out.println("Employee static ...");
}
private String name;
private double salary;
private LocalDate hireDay;
...
@Override
public int compareTo(Employee o) {
return Double.compare(this.salary, o.salary);
}
}
// 测试
public void testComparable() {
Employee[] employees = new Employee[3];
employees[0] = new Employee("Xiu", 3000, 2020, 11, 10);
employees[1] = new Employee("Gang", 5000, 2020, 11, 10);
employees[2] = new Employee("Long", 2000, 2020, 11, 9);
Arrays.sort(employees);
}
Comparator接口
前面,我们如果想要对自定义类的对象进行排序,只需要重写Comparable接口即可;String类默认实现了Comparable接口,并且排序规则是按照字典顺序排序,现在有一需求,将字符串数组根据字符串的长度进行排序,这时就需要用到另一个Arrays.sort相关的API
public static <T> void sort(T[] a, Comparator<? super T> c)
自定义LengthComparator实现Comparator接口
class LengthComparator implements Comparator<String> {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();
}
}
// 测试
public void testComparable() {
LengthComparator lengthComparator = new LengthComparator();
String[] friends = {"Peter", "Paul", "Mary"};
System.out.println("sorted by dic -->" + Arrays.toString(friends));
Arrays.sort(friends, lengthComparator);
System.out.println("sorted by length -->" + Arrays.toString(friends));
}
4.6 lambda表达式
下面部分章节选自 —《On Java 8》
顺序阅读可能会有点困难,因为一开始就用了一些lambda相关的语法,推荐先整体阅读,之后返回到懵懂点,再次阅读。
推荐阅读《On Java 8》、《Effective Java》
4.6.1 函数式编程和闭包
函数式编程(英语:functional programming)或称函数程序设计、泛函编程,是一种编程范式,它将电脑运算视为函数运算,并且避免使用程序状态以及易变对象。其中,λ演算(lambda calculus)为该语言最重要的基础。而且,λ演算的函数可以接受函数当作输入(引数)和输出(传出值)。
比起指令式编程,函数式编程更加强调程序执行的结果而非执行的过程,倡导利用若干简单的执行单元让计算结果不断渐进,逐层推导复杂的运算,而不是设计一个复杂的执行过程。
在函数式编程中,函数是第一类对象,意思是说一个函数,既可以作为其它函数的参数(输入值),也可以从函数中返回(输入值),被修改或者被分配给一个变量。
函数式语言的特性
- 高阶函数(Higher-order function)
- 偏应用函数(Partially Applied Functions)
- 柯里化(Currying)
- 闭包(Closure)
Summary:(函数式和面向对象的区别【未完待续】)
函数式编程将函数作为解决问题的出发点,以函数的思维去解决问题。这种编程的基础是λ演算,接收函数作为输入和输出。【强调:做什么】
面向对象编程将事物看做是由属性和行为组成的,以对象为核心去处理问题。【强调:怎么做】
闭包:内部函数总是可以访问其所在的外部函数中声明的参数和变量,即使在其外部函数被返回(寿命终结)了之后。
闭包三要素:函数、自由变量、环境
突然发现这里面水好深,停更,未完待续!!!
4.6.2 新旧对比
通常,传递给方法的数据不同,结果不同。如果我们希望方法在调用时行为不同,该怎么做呢?JDK8之前,我们可以通过在方法中创建包含所需行为的对象,然后将对象传递给我们想要控制的方法来完成操作即可。下面我们用传统形式和Java8的方法引用、Lambda表达式分别演示。
// functional/Strategize.java
interface Strategy {
String approach(String msg);
}
class Soft implements Strategy {
public String approach(String msg) {
return msg.toLowerCase() + "?";
}
}
class Unrelated {
static String twice(String msg) {
return msg + " " + msg;
}
}
public class Strategize {
Strategy strategy;
String msg;
Strategize(String msg) {
strategy = new Soft(); // [1]
this.msg = msg;
}
void communicate() {
System.out.println(strategy.approach(msg));
}
void changeStrategy(Strategy strategy) {
this.strategy = strategy;
}
public static void main(String[] args) {
Strategy[] strategies = {
new Strategy() { // [2]
public String approach(String msg) {
return msg.toUpperCase() + "!";
}
},
msg -> msg.substring(0, 5), // [3]
Unrelated::twice // [4]
};
Strategize s = new Strategize("Hello there");
s.communicate();
for(Strategy newStrategy : strategies) {
s.changeStrategy(newStrategy); // [5]
s.communicate(); // [6]
}
}
}
// 输出结果
hello there?
HELLO THERE!
Hello
Hello there Hello there
Strategy 接口提供了单一的 approach() 方法来承载函数式功能。通过创建不同的 Strategy 对象,我们可以创建不同的行为。
传统上,我们通过创建一个实现 Strategy 接口的类来实现此行为,比如在 Soft。
- [1] 在 Strategize 中,Soft 作为默认策略,在构造函数中赋值。
- [2] 一种略显简短且更自发的方法是创建一个匿名内部类。即使这样,仍有相当数量的冗余代码。你总是要仔细观察:“哦,原来这样,这里使用了匿名内部类。”
- [3] Java 8 的 Lambda 表达式。由箭头
->分隔开参数和函数体,箭头左边是参数,箭头右侧是从 Lambda 返回的表达式,即函数体。这实现了与定义类、匿名内部类相同的效果,但代码少得多。 - [4] Java 8 的方法引用,由
::区分。在::的左边是类或对象的名称,在::的右边是方法的名称,但没有参数列表。 - [5] 在使用默认的 Soft strategy 之后,我们逐步遍历数组中的所有 Strategy,并使用
changeStrategy()方法将每个 Strategy 放入 变量s中。 - [6] 现在,每次调用
communicate()都会产生不同的行为,具体取决于此刻正在使用的策略代码对象。我们传递的是行为,而非仅数据。[^3]
在 Java 8 之前,我们能够通过 [1] 和 [2] 的方式传递功能。然而,这种语法的读写非常笨拙,并且我们别无选择。方法引用和 Lambda 表达式的出现让我们可以在需要时传递功能,而不是仅在必要才这么做。
4.6.3 lambda初识
个人理解
lambda表达式 :接口中特定方法的快速实现。两个点,一必须是函数式接口,二特定方法单一抽象方法(SAM)。lambda表达式属于函数式编程的思想,通过写lambda表达式,lambda更多的是强调做什么,结果是什么,只关心核心。面向对象解决问题的核心关注带你是怎么做。
lambda表达式的应用场景:
1)简化匿名内部类
在匿名内部类中,有许多内容都是冗余的,对业务处理是没有一毛联系的。整个匿名内部类中最关键的东西是方法,方法中最关键的有参数、方法体、返回值。lambda就是根据这三个核心内容,简化匿名内部类。
// 比如常见的匿名内部类格式:
new 父类或接口() {
//重写的方法
}
// 比如Runnable接口
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "执行了");
}
}).start();
// lambda格式
new Thread(() -> System.out.println(Thread.currentThread().getName() + "执行了")).start();
4.6.5函数式接口
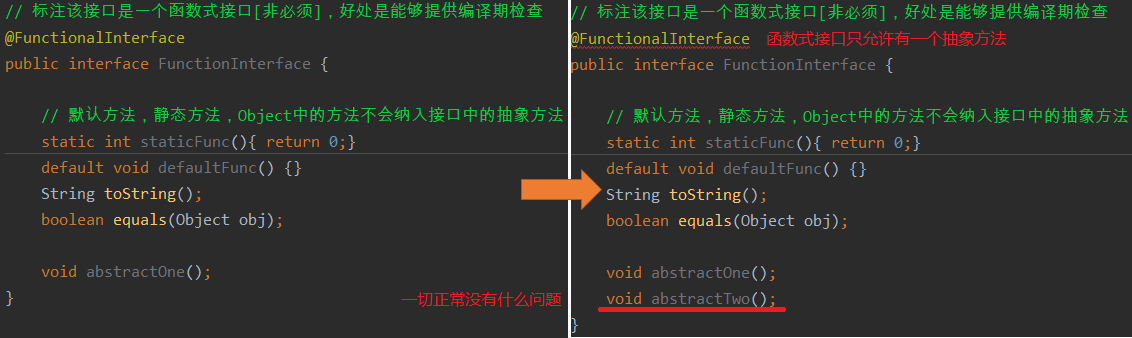
对于只有一个抽象方法的接口(SAM Single Abstract Method),需要这种接口的对象时,可以提供一个lambda表达式。这种接口称为函数式接口(functional interface),@FunctionInterface标注(非必须)。
# 为什么定义只有一个抽象方法,接口中的方法不都是抽象的吗?
* java8接口新增default、静态方法,这些新特性有可能使接口中的方法不在是抽象的。另外重写Object中的默认方法(equals、String)不会计入接口中的抽象方法。
例如
public interface IExample
default void post() {...};
static void delay() {...};
boolean equals(Object obj);//父类中的方法,不会纳入接口中的抽象方法
}
上面接口的方法不在是抽象的,并且也没有抽象方法。
# 为什么interface可以包括Object类的方法的抽象声明重写?
* Object是所有类的默认父类,也就是说任何对象都会包含Object里面的方法,即使是函数式接口的实现,也会有Object的默认方法,所以,重写Object中的方法,不会计入接口方法中,除了final不能重写的,Object中所能重写的方法,写到接口中,不会影响函数式接口的特性
* 换个角度说,interface也默认继承了Object类;这里可以把inteface看作一个抽象类的极致,也就是说本质也是一个类,这样就可以继承Object类。但interface只是声明了Object中的方法,具体实现还是靠interface的实现类,写一个interface引用是可以调用Object类中的方法的,但因为没有实现,所以运行会报错;;;但因为它的实现类也继承了Object类,所以相当于重写了Object中的方法的interface只是一个中介,连接了Object与接口的实现类。
JDK提供的函数式接口
// JDK8之前符合函数式的接口
java.lang.Runnable
java.util.concurrent.Callable
java.security.PrivilegedAction
java.util.Comparator
java.io.FileFilter
java.nio.file.PathMatcher
java.lang.reflect.InvocationHandler
java.beans.PropertyChangeListener
java.awt.event.ActionListener
javax.swing.event.ChangeListener
// JDK8新增重磅函数式接口 java.util.function.*包下的接口都是函数式接口
java.util.function.*
下面我们重点来认识一下java.util.function.*包下的函数式接口以及如何使用它们。
Supplier-生产型接口
特定类型对象实例的提供者。无参数,返回类型任意。指定接口的泛型是什么类型,那么接口的get方法就会生产什么类型的数据,有返回值。
@FunctionalInterface
public interface Supplier<T> {
T get();
}
示例:
// 还是前面的Employee例子
//Supplier<Employee> supplier = Employee::new; 空参构造函数
Supplier<Employee> supplier = () -> new Employee("Long", 5000D, 2020,7, 7);
Employee employee = supplier.get();
IntSupplier intSupplier = () -> 3*5;
int asInt = intSupplier.getAsInt();
Consumer 消费型接口
消费一个指定泛型的数据,无返回值。
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
/**
* 返回一个组合的{@code Consumer},它依次执行此accept操作,然后执行{@code after}操作。如果执行操作 * 中的任何一个引发异常,则将其中传递给合成操作的调用方。如果执行此操作引发异常,则将不会执行{@code * after}操作。
*/
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
默认方法andThen:如果一个方法的参数和返回值全部是Consumer类型,那么就可以实现:消费数据的时候,首先做一个操作,然后在做一个操作,实现组合,而这个方法就是Consumer接口中的default方法
Consumer<Employee> name = e -> e.setName("001");
Consumer<Employee> salary = e -> e.setSalary(5000.0);
Consumer<Employee> hireDay = e -> e.setHireDay(LocalDate.now());
name.andThen(salary).andThen(hireDay)
.andThen(System.out::println).accept(supplier.get());
//Employee{name='001', salary=5000.0, hireDay=2020-07-17}
Predicate 判断接口
判断是否的接口
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
/**
*返回表示该谓词和另一个谓词的短路逻辑* AND的组合谓词。在评估组成的谓词时,如果此谓词为{@code false}, *则不会评估{@code other} *谓词。
* 相当于&&功能
*/
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
// 非运算
default Predicate<T> negate() {
return (t) -> !test(t);
}
// 或运算
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
// 判相等
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
示例:
Predicate<LocalDate> year = y -> LocalDate.now().getYear() == y.getYear();
Predicate<LocalDate> month = m -> m.getMonth() == LocalDate.now().getMonth();
Predicate<LocalDate> day = d -> d.getDayOfMonth() == LocalDate.now().getDayOfMonth();
boolean isToday = year.and(month).and(day).test(LocalDate.of(2020, 7, 17));
//boolean isYesterday = year.and(month).and(day).test(LocalDate.of(2020, 7, 16));
System.out.println("isToday-->" + isToday); // true
Predicate<Integer> exp1 = i -> i > 0;
Predicate<Integer> exp2 = i -> {
System.out.println("exp2");
return true;
};
// 测试 or and短路功能
System.out.println(exp1.and(exp2).test(-1));//false
System.out.println(exp1.or(exp2).test(-1));//exp2 true
System.out.println(exp1.and(exp2).test(1));//exp2 true
System.out.println(exp1.negate().and(exp2).test(-1));//exp2 true
// equals是Predicate中的静态方法
Predicate<String> s = Predicate.equals("hello");
s.test("hello");//true
Function 数据类型转换接口
根据一个数据类型得到另一个数据类型。在使用默认方法时,注意默认方法的形参类型,一定要类型匹配。
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
// 和andThen执行顺序相反,它先执行before,后执行所调用的
// 将后来的输出作为先前的输入,后来的输出的类型必须是Function输入所定义的类型
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
// 学习完泛型再回过头来看就感觉好点
// 将先前的输出作为后来的输入
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
static <T> Function<T, T> identity() {
return t -> t;
}
}
示例:
Function<String, Integer> func = Integer::parseInt;
Integer apply = func.apply("1024");
//Function<String,Integer> -> String->T,Integer->R,将String类型作为输入,Integer类型作为输出
//andThen函数形参也是一个函数式接口,函数原型在上面展示了,
//andThen(Function<? super T, ? extends V)); i -> i*2就是将func的输出(Integer)作为输入(Integer),输出又定义了一个新的参数类型V
func.andThen(i -> i*2).apply("1024");
Function<Integer, Integer> func1 = i -> ++i;
//func.compose(func1); error 输入参数类型T不一致
Integer res = func1.compose(func).apply("1024");
//看下面这几个例子
Function<String, Long> func = Long::parseLong;
String res = func.andThen(String::valueOf).apply("123");
Function<Long, String> func1 = l -> String.valueOf(l*2);
Long res1 = func.compose(func1).apply(123L);
4.6.4 走进lambda
基本语法
// functional/LambdaExpressions.java
interface Description {
String brief();
}
interface Body {
String detailed(String head);
}
interface Multi {
String twoArg(String head, Double d);
}
public class LambdaExpressions {
static Body bod = h -> h + " No Parens!"; // [1]
static Body bod2 = (h) -> h + " More details"; // [2]
static Description desc = () -> "Short info"; // [3]
static Multi mult = (h, n) -> h + n; // [4]
static Description moreLines = () -> { // [5]
System.out.println("moreLines()");
return "from moreLines()";
};
public static void main(String[] args) {
System.out.println(bod.detailed("Oh!"));
System.out.println(bod2.detailed("Hi!"));
System.out.println(desc.brief());
System.out.println(mult.twoArg("Pi! ", 3.14159));
System.out.println(moreLines.brief());
}
}
任何 Lambda 表达式的基本语法是:
- 参数。
- 接着
->,可视为“产出”。 ->之后的内容都是方法体。- [1] 当只用一个参数,可以不需要括号
()。 然而,这是一个特例。 - [2] 正常情况使用括号
()包裹参数。 为了保持一致性,也可以使用括号()包裹单个参数,虽然这种情况并不常见。 - [3] 如果没有参数,则必须使用括号
()表示空参数列表。 - [4] 对于多个参数,将参数列表放在括号
()中。
- [1] 当只用一个参数,可以不需要括号
到目前为止,所有 Lambda 表达式方法体都是单行。 该表达式的结果自动成为 Lambda 表达式的返回值,在此处使用 return 关键字是非法的。 这是 Lambda 表达式缩写用于描述功能的语法的另一种方式。
[5] 如果在 Lambda 表达式中确实需要多行,则必须将这些行放在花括号中。 在这种情况下,就需要使用 return。
为什么可以那样写就是接下来说的类型推断。
类型推断
lambda类型推断的依据一方面根据函数接口的类型从而推断参数类型,是否有返回值,返回值类型等。所以说lambda表达式可以简写到什么地步,可以根据实现的函数接口来判断。但是类型推断机制并不是完美无瑕的,当编译不能识别类型的时候,这时候必须显示给出类型。
lambda表达式简写依据:
1)如果可以推导出一个lambda表达式的参数类型,则可以忽略其类型
2)如果方法只有一个参数,而且这个参数的类型可以推导出,那么甚至可以省略小括号
3)无需指定lambda表达式的返回类型。lambda表达式的返回类型总是会由上下文推倒得出。
4)当只有一个参数时,圆括号可以省略 param -> {...},当无参数时,必须有括号() -> {...},括号和单参可以看成是一个构成lambda的标识,如果空参的lambda这样写-> {...},编译器肯定不认啊。
这时候在回过头去看基本语法中刚开始的例子就会有所感悟,下面给出了自己当时写的例子。
public class LambdaTest {
public static void main(String[] args) {
// 完整声明
Arithmetic addOperation = (int a, int b) -> {
// you can do everything in here.
return a + b;
};
// 省略
Arithmetic minusOperation = (a, b) -> a - b;
// 无参数有返回值
ArithmeticNoParam noParam = () -> 1 + 2;
// 无参数无返回值
ArithmeticNoParamVoid noParamVoid = () -> System.out.println(Integer.MAX_VALUE);
// 单参数有返回值
LogicOperation logicOperation = b -> !b;
}
interface Arithmetic {
int arithmetic(int a, int b);
}
interface ArithmeticNoParam {
int arithmetic();
}
interface ArithmeticNoParamVoid {
void arithmetic();
}
interface LogicOperation {
boolean logicOperation(boolean b);
}
}
方法引用*
what? why? how? ❓❓❓
1)什么是方法引用
方法引用是lambda表达式的一种特殊形式,当我们要编写一个lambda表达式时,发现已经有一个方法实现了我们在lambda表达式中要实现的功能,那么可以直接使用方法引用进行替换。
2)为什么使用
lambda 优于匿名类的主要优点是它们更简洁。Java 提供了一种生成函数对象的方法,它比 lambda 更简洁:方法引用。
方法引用通常提供一种更简洁的 lambda 替代方案。在使用方法引用可以更简短更清晰的地方,就使用方法引用,如果无法使代码更简短更清晰的地方就坚持使用 lambda。(Where method references are shorter and clearer, use them; where they aren’t, stick with lambdas.)
3)上手
方法引用的分类
- 类名::静态方法名
- 对象::实例方法名 (绑定的方法引用)
- 类名::实例方法名 (未绑定的方法引用)
- 类名::new (构造器引用)
在绑定引用中,接收对象在方法引用中指定。绑定引用在本质上类似于静态引用:函数对象采用与引用方法相同的参数。在未绑定的引用中,在应用函数对象时,通过方法声明的参数之前的附加参数指定接收对象。未绑定引用通常用作流管道(stream pipelines)(第 45 项)中的映射和过滤功能。最后,对于类和数组,有两种构造函数引用。构造函数引用充当工厂对象。
—摘自《Effective Java》
3.1 类名::静态方法名
首先,定义一个Student类
public class Student {
String name;
int score;
public Student() {}
public Student(String name, int score) {
this.name = name;
this.score = score;
}
public static int compareByScore(Student s1, Student s2) {
return s1.score - s2.score;
}
public int compareByName(Student s2) {
return this.name.compareTo(s2.name);
}
// toString...
}
类中提供了一个返回两个学生成绩大小的静态方法和一个按字典顺序比较两个学生姓名的成员方法。接下来我们对学生进行按成绩排序,首先我们先使用lambda表达式处理:
public static void main(String[] args) {
Student s1 = new Student("Long", 90);
Student s2 = new Student("XiuYu", 80);
Student s3 = new Student("MingSh", 70);
Student[] students = {s1, s2, s3};
Arrays.sort(students, (x, y) -> x.score - y.score);
System.out.println(Arrays.toString(students));
//[Student{name='MingSh', score=70}, Student{name='XiuYu', score=80}, Student{name='Long', score=90}]
}
Arrays.sort第二个参数接受一个Comparator函数式接口,接口中的唯一抽象方法compare接收两个参数返回一个int类型值,比较的具体逻辑由lambda表达式给出即(x, y) -> x.score - y.score,前面我们已经提到过,当lambda表达式所实现的功能之前已经有实现的方法了,那么可以直接用方法引用代替。有没有返回两个学生成绩的大小呢?已经有的了,在Student类中正好定义着一个静态方法,方法的形参和返回值正好和Comparator中的抽象方法相对应,所以我们可以使用 Student::compareByScore来代替lambda表达式
//Arrays.sort(students, (x, y) -> x.score - y.score);
Arrays.sort(students, Student::compareByScore);
3.2 对象::实例方法名
绑定引用在本质上类似于静态引用:函数对象采用与引用方法相同的参数。
在Student类中新增成员方法
public int compareByScoreNoStatic(Student s1, Student s2) {
return s1.score - s2.score;
}
然后通过对象实例方法名引用
Student s = new Student();
Arrays.sort(students,s::compareByScoreNoStatic);
现在再回过头去理解引用的那句话,实例对象并没有作为方法的参数,它和静态方法本质上是一样的,方法参数对应函数式接口中的方法参数。
接下来我们在看类名::方法名,它会有什么不同点。
3.3 类名::实例方法名
这种方法引用和前两种有所不同,因为无论是通过类名调用静态方法和对象调用实例方法都是符合常规,并且方法参数和返回类型都符合函数式接口中的SAM。Student类中的compareByScore看似没什么问题,但是由于其是静态方法,所以在任何地方都可以调用,而不单单是从属于Student实例了,如果定义非静态的,那么类的封装性更好一些,那么又会存在方法参数的问题,如果签名为compareByScoreNoStatic(Student s1, Student s2) 那不就和对象::方法名那种引用方式重复了吗,因为实例方法隐式持有this引用,我可以通过this来确定一个对象和另一个对象。所以说就有了如下:
public static int compareByScore(Student s1, Student s2) {
return s1.score - s2.score;
}
// -->非静态
public int compareByScoreNoStatic(Student s) {
return this.score - s2.score;
}
之后,我们可以通过 类名::实例方法名 这种形式的方法引用代替lambda,当使用 类名::实例方法名 方法引用时,lambda表达式所接收的第一个参数来调用实例方法,如果lambda表达式接收多个参数,其余的参数作为方法的参数传递进去。所以说在使用未绑定的方法引用时,必须提供调用方法的对象。
//Arrays.sort(students, (x, y) -> x.score - y.score);
Arrays.sort(students, Student::compareByName);
看到这可能就有疑问了,实现的方法有两个参数,为什么这里就有一个。其实它等价于Arrays.sort(students, (x, y) -> x.compareByName(y));参数实质并没有变。
思考:Comparator
comparator = Comparator.comparingInt(String::length); 函数式接口,方法引用,函数签名不在和ToIntFunction中的int applyAsInt(T t);签名相同。
3.4 构造方法引用
这个就简单多了,直接看实例
Student下新增一个接口,通过类名::new 的形式提供一个构造函数的引用
public interface Creature {
void instantiate();
}
public static void main(String[] args) {
Creature creature = Student::new;
creature.instantiate();
}
总结
如何判断自己掌握了lambda的语法和方法引用,如果你能够根据lambda表达式和方法引用的形式,反推回去,根据lambda和方法引用所需的形式能够自己构造出相应的函数式接口并且lambda或者方法化,那么说明你对lambda已经有所了解了。
附:函数式接口里面用到了大量的泛型,所以说当对泛型基础有一定的把握之后,一定要看一看函数式接口中的泛型方法,能进一步加深自己对泛型的理解。
public SummaryTest {
interface Concat {
String concat(String thisObj, String str);
}
interface ConcatAno {
String concatAno(String str);
}
interface ToUpper {
String toUpper();
}
public static void main(String[] args) {
// lambda表达式
String[] planets = {"Mercury", "Venus", "Mars", "Earth", "Jupiter"};
Arrays.sort(planets, (String x, String y) -> {
return x.length() - y.length();
});
Arrays.sort(planets, (String x, String y) -> x.length() - y.length());
Integer[] degree = {1, 3, 5, 7, 9};
// lambda表达式 类型自动推断,无需return
Arrays.sort(planets, (x, y) -> x.length() - y.length());
// 方法引用
// 类名::静态方法 public static int compare(int x, int y)
Arrays.sort(degree, Integer::compare);
// 类名::实例方法 注意区别
Arrays.sort(degree, Integer::compareTo);
Arrays.sort(planets, String::compareTo);
// 再次理解类名实例方法名
// public String concat(String str)方法签名不在与
// String concat(String obj, String str);相同,如果把Concat中的函数签名改为
// String concat(String str);在String::concat引用方法的时候会报错,尽管这时候
// 签名相同了,但是由于concat方法的执行必须有一个对象来调用,str只是形参不是执行
// 调用方法的对象,所以我们必须提供一个调用方法的对象,下面"hello"就是执行调用方法的对象,
// 如何hello就是调用方法的对象验证?如果将"hello"替换为NULL run下就明白了。
// Concat ano = String::concatAno; error 未提供调用方法的对象
Concat c = String::concat;
//Concat lambdaC = (obj, str) -> obj.concat(str); 结合lambda理解
String result = c.concat("hello", " world!");
System.out.println(result);//hello world!
// 对象实例方法名
String s = "to upper";
ToUpper toUpper = s::toUpperCase;
System.out.println(toUpper.toUpper());//TO UPPER
}
}
4.6.5 变量作用域
Lambda可以没有限制地捕获(也就是在其主体中引用)实例变量和静态变量。但局部变量必须显式声明为final或事实上是final(隐性final)。
示例:
// 对象中的实例变量 堆中保存,不会随方法销毁而销毁,延时(满足条件才会执行的)lambda使用实例变量没有问题.
// 但是如果使用的是局部变量,方法销毁,变量也会销毁,这时候变量必须是final类型的。
public class TimerTest {
int y;
interface Listener {
int click(int x);
}
public static void main(String[] args) {
TimerTest timerTest = new TimerTest();
timerTest.test();
}
private void test() {
int z = 10;
String s = "hello";
ArrayList<String> list = new ArrayList<>();
list.add("hello");
Listener listener = (x) -> {
x++;
// z++; error
list.add(" world");
return x+y++;
};
int res1 = listener.click(1);
System.out.println(res1);// 2
int res2 = listener.click(1);
System.out.println(res2);// 3
int res3 = listener.click(1);
System.out.println(res3);// 4
System.out.println(Arrays.toString(list.toArray()));
//[hello, world, world, world]
}
}
lambda引用变量使用注意
-
只能引用标记了 final 的外层局部变量,这就是说不能在 lambda 内部修改定义在域外的局部变量,否则会编译错误。
-
局部变量可以不用声明为 final,但是必须不可被后面的代码修改(即隐性的具有 final 的语义)等同final效果。
等同 final 效果(Effectively Final)。这个术语是在 Java 8 才开始出现的,表示虽然没有明确地声明变量是
final的,但是因变量值没被改变过而实际有了final同等的效果。 如果局部变量的初始值永远不会改变,那么它实际上就是final的。 -
不允许声明一个与局部变量同名的参数或者局部变量。
4.7 内部类

一个定义在另一个类中的类,叫做内部类
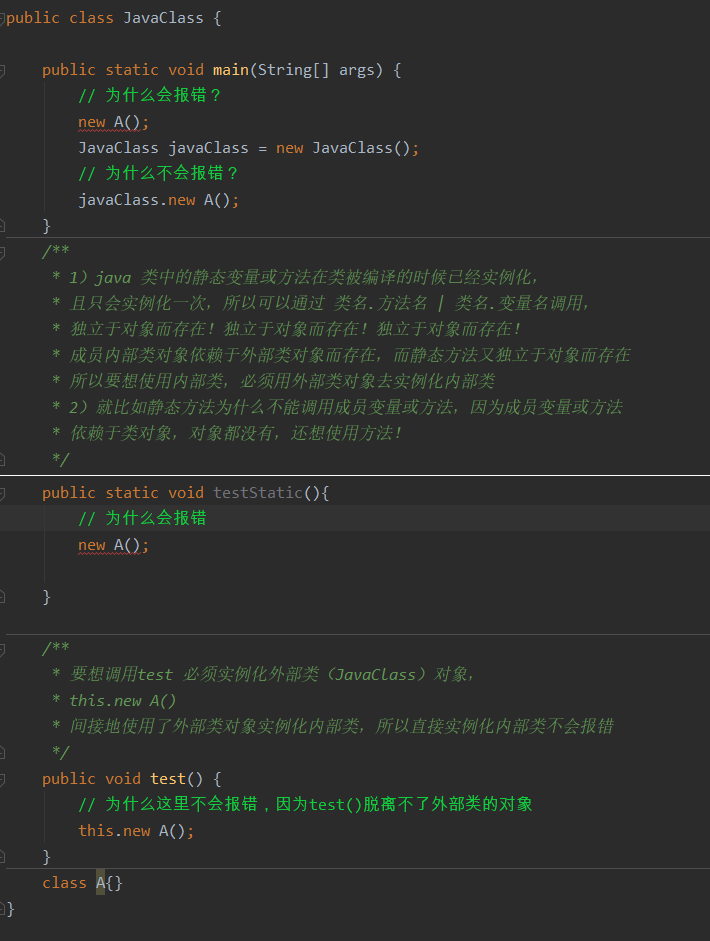
public class JavaClass {
public static void main(String[] args) {
OuterClass outerClass = new OuterClass();
// 第一种访问内部类的方法,通过在Outer内部实例化Inner
outerClass.show();
// 第二种访问内部类方法,直接实例化内部类对象
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
innerClass.show();
}
}
class OuterClass {
private String tag = "OuterTag";
class InnerClass {
public void show() {
System.out.println(tag);
}
}
public void show() {
InnerClass innerClass = new InnerClass();
innerClass.show();
}
}
4.7.1 为什么使用内部类
也许,搞清楚为什么使用这种技术比会使用某项技术更能让人愿意去了解。内部类给开发带来了什么便利?什么情况下使用内部类?我的理解内部类解决了:
单继承问题,如果没有内部类提供的、可以继承多个具体的或抽象类的能力,一些设计与编程问题就很难解决。换个角度说,内部类有效地实现了“多重继承”。也就是说,内部类允许继承多个非接口类型(类或抽象类)。
简化多余代码,比如匿名内部类,有时对于某个接口的实现,并不常用接口中的方法,或者只调用一次,这时我们就可以使用匿名内部类来代替声明类实现接口的操作,这肯定会带来冗余的代码,而前面所讲的lambda表达式也是一种代替匿名内部类很好地方案,但是并不是所有的接口抽象方法都可以使用lambda表达式(SAM才可以使用),所以这时候最好就是使用匿名内部类。
内部类方法可以访问该类定义所在的作用域中的数据,包括私有的数据。
内部类可以对同一个包中的其他类隐藏起来。
4.7.2 内部类的创建
语法:记住一个原则,非静态内部类默认会有一个外部类的引用,即依赖外部对象的创建,静态内部类独立于外部类而存在,不需要与外部类对象建立关联。
//在外部类外部(静态方法内|非静态方法内),创建非静态内部类对象
Outer.Inner in=new Outer().new Inner();
//在外部类外部(静态方法内|非静态方法内),创建静态内部对象
Outer.Inner in=new Outer.Inner();
//----------------------------------------------------------------------
//在外部类内部(非静态方法内)创建成员内部类对象,就像普通对象一样直接创建
Inner in=new Inner();
//在外部类内部(静态方法内)创建成员内部类对象
Outer.Inner in=new Outer().new Inner();
//在外部内部类(静态方法内|非静态方法内)创建静态内部类对象
Inner in=new Inner();
4.7.2 内部类的分类
成员内部类
成员内部类既可以访问自身的数据域,也可以访问它的外围类对象的数据域,对于外围类来说,要想访问内部类属性,必须先创建内部类对象。你可能会有疑问了这是为什么?一个重要的原因是内部类的对象会保留一个指向创建它的外部类的引用。
1)成员内部类内部不允许存在任何static变量或方法,但可以有常量。正如成员方法中不能有任何静态属性 (成员方法与对象相关、静态属性与类有关)!!!
为什么不允许存在任何static变量或方法?
静态变量是属于类的,成员变量和方法是属于对象的,非静态内部类可以看成是一个外部类的成员属性,依赖于对象的,因为静态属性随类而加载而不是随对象加载,所以如果内部类中存在静态属性,由于静态属性会随类加载,而内部类又是外部类的一个成员属性随外部类对象而加载,这样就会在没有外部类对象的情况下,却加载了内部类的静态成员属性,产生了矛盾。
在类加载的时候,静态属性和代码块会先加载,那么按照这个逻辑,非静态内部类里面的静态属性也要优先于这个内部类加载,但这个时候这个内部类都还没有初始化,这就出现矛盾了。
2)成员内部类是依附外部类的,只有创建了外部类才能创建内部类。
静态内部类(嵌套类)
关键字static可以修饰成员变量、方法、代码块、其实还可以修饰内部类,使用static修饰的内部类我们称之为静态内部类,静态内部类和非静态内部类之间存在一个最大的区别,非静态内部类在编译完成之后会隐含的保存着一个引用,该引用是指向创建它的外围类,但是静态类没有。没有这个引用就意味着:
1)静态内部类的创建不需要依赖外部类可以直接创建。
2)静态内部类不可以使用任何外部类的非static类(包括属性和方法),但可以存在自己的成员变量。
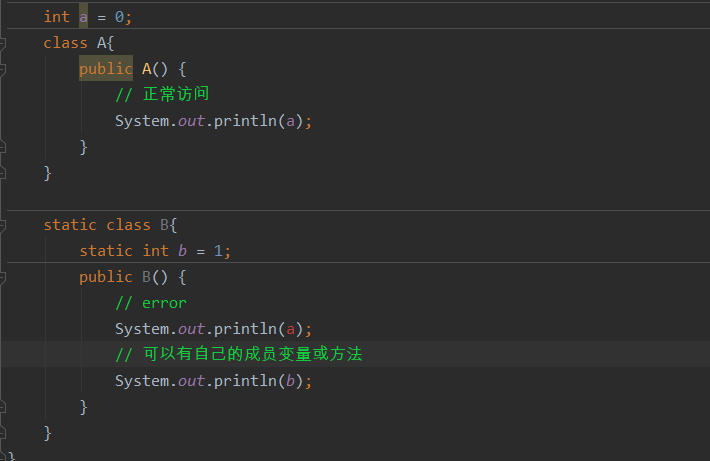
局部内部类
局部内部类使用的比较少,其声明在一个方法体 / 一段代码块的内部,而且不在定义类的定义域之内便无法使用,其提供的功能使用匿名内部类都可以实现,而本身匿名内部类可以写得比它更简洁,因此局部内部类用的比较少。来看一个局部内部类的小例子:
public class InnerClassTest {
public int field1 = 1;
protected int field2 = 2;
int field3 = 3;
private int field4 = 4;
public InnerClassTest() {
System.out.println("创建 " + this.getClass().getSimpleName() + " 对象");
}
private void localInnerClassTest() {
// 局部内部类 A,只能在当前方法中使用
class A {
// static int field = 1; // 编译错误!局部内部类中不能定义 static 字段
public A() {
System.out.println("创建 " + A.class.getSimpleName() + " 对象");
System.out.println("其外部类的 field1 字段的值为: " + field1);
System.out.println("其外部类的 field2 字段的值为: " + field2);
System.out.println("其外部类的 field3 字段的值为: " + field3);
System.out.println("其外部类的 field4 字段的值为: " + field4);
}
}
A a = new A();
if (true) {
// 局部内部类 B,只能在当前代码块中使用
class B {
public B() {
System.out.println("创建 " + B.class.getSimpleName() + " 对象");
System.out.println("其外部类的 field1 字段的值为: " + field1);
System.out.println("其外部类的 field2 字段的值为: " + field2);
System.out.println("其外部类的 field3 字段的值为: " + field3);
System.out.println("其外部类的 field4 字段的值为: " + field4);
}
}
B b = new B();
}
// B b1 = new B(); // 编译错误!不在类 B 的定义域内,找不到类 B,
}
public static void main(String[] args) {
InnerClassTest outObj = new InnerClassTest();
outObj.localInnerClassTest();
}
}
匿名内部类
匿名内部类是一个没有名字的方法内部类,它的特点有
1)匿名内部类必须继承一个类或者实现一个接口(类可以是抽象类,也可以是具体类)
2)匿名内部类没有类名,因此没有构造方法
个人觉得匿名内部类其实就是对接口简单快速的实现
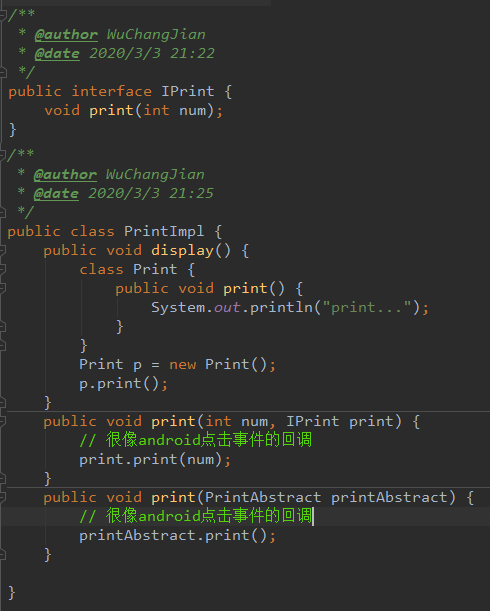
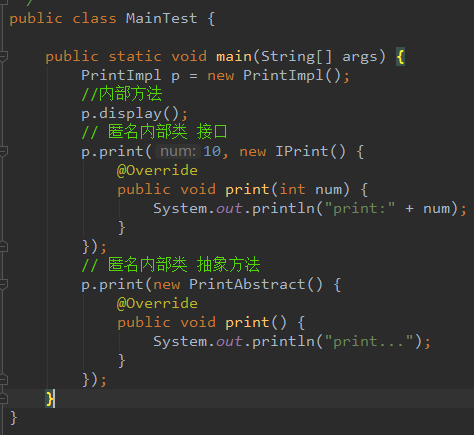
推荐比较好的两篇文章:详解 Java 内部类、内部类定义
// 附加:具体类也可以用内部类实现
// 下面定义了一个Object的匿名内部类,新增了一个方法并调用
// 编译通过,并能运行
Object obj = new Object() {
public void func() {...}
}.func();
// 下面就不能通过编译
Object obj = new Object() {
public void func() {...}
};
obj.func();//compile error 没有该方法
第二个编译失败,因为匿名内部类是一个 子类对象,Object类型的obj指向了一个匿名子类内部,向上转型了,所以编译时会检查Object里面是否有func方法。
5. 异常、断言和日志
5.1 异常分类
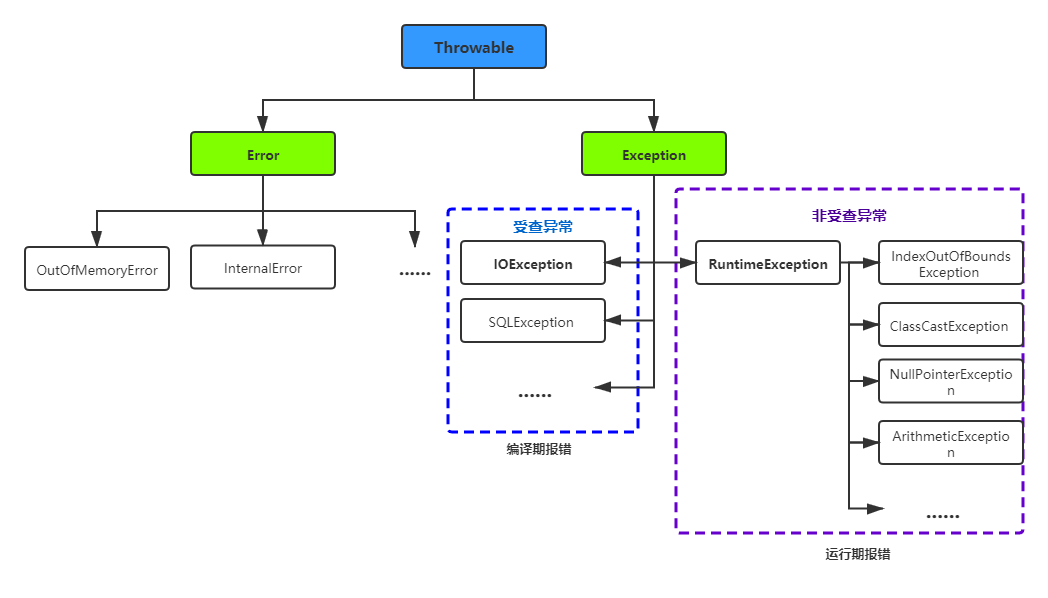
如图所示,Throwable是所有异常的父类,往下划分为两大门派Error和Exception。
Error类是指Java运行时系统的内部错误和资源耗尽错误,应用程序不会抛出这种类型的对象。如果出现这种错误,听天由命...
Exception又分解为两个分支,可以看做是受查异常和非受查异常或者是其他分支和RuntimeException;程序错误导致:错误的类型转化、数组访问越界、空指针等都属于运行时异常,“如果出现RuntimeException异常,那么就一定是你的问题”很有道理。受查异常必须被处理,否则编译器报错。
Java语言将派生于Error类或RuntimeException类的所有异常称为非受查(unchecked)异常,所有其他的异常称为受查(checked)异常。
public class ExceptionTest {
/**
* 第一个疑问点?
* 当在方法内部throw之后,有时方法会有throws,有时没有?
* 其实就是受查和非受查异常区别:
* 一般我们处理的都是受查异常
*/
public void writeData() throws IOException {
// IOException属于受查异常,必须处理,要么抛出要么捕获
//write...
throw new IOException();
/*
try {
throw new FileNotFoundException();
} catch (IOException e) {
e.printStackTrace();
}
*/
}
public void uncheck() {
// ClassCastException属于RuntimeException非受查异常
// 出现这种错误,就是代码有问题(数组下标越界..),
// 这种错误一般是在运行期发现的,由JVM抛出,我们人为不需要处理,
// 如果我们知道数组下标越界,为什么还不修改代码。
throw new ClassCastException();
// throw new RuntimeException();
}
}
常用非受查异常
| 异常 | 描述 |
|---|---|
| ArithmeticException | 当出现异常的运算条件时,抛出此异常。例如,一个整数"除以零"时,抛出此类的一个实例。 |
| ArrayIndexOutOfBoundsException | 用非法索引访问数组时抛出的异常。如果索引为负或大于等于数组大小,则该索引为非法索引。 |
| ArrayStoreException | 试图将错误类型的对象存储到一个对象数组时抛出的异常。 |
| ClassCastException | 当试图将对象强制转换为不是实例的子类时,抛出该异常。 |
| IllegalArgumentException | 抛出的异常表明向方法传递了一个不合法或不正确的参数。 |
| IllegalMonitorStateException | 抛出的异常表明某一线程已经试图等待对象的监视器,或者试图通知其他正在等待对象的监视器而本身没有指定监视器的线程。 |
| IllegalStateException | 在非法或不适当的时间调用方法时产生的信号。换句话说,即 Java 环境或 Java 应用程序没有处于请求操作所要求的适当状态下。 |
| IllegalThreadStateException | 线程没有处于请求操作所要求的适当状态时抛出的异常。 |
| IndexOutOfBoundsException | 指示某排序索引(例如对数组、字符串或向量的排序)超出范围时抛出。 |
| NegativeArraySizeException | 如果应用程序试图创建大小为负的数组,则抛出该异常。 |
| NullPointerException | 当应用程序试图在需要对象的地方使用 null 时,抛出该异常 |
| NumberFormatException | 当应用程序试图将字符串转换成一种数值类型,但该字符串不能转换为适当格式时,抛出该异常。 |
| SecurityException | 由安全管理器抛出的异常,指示存在安全侵犯。 |
| StringIndexOutOfBoundsException | 此异常由 String 方法抛出,指示索引或者为负,或者超出字符串的大小。 |
| UnsupportedOperationException | 当不支持请求的操作时,抛出该异常。 |
常用受查异常
| 异常 | 描述 |
|---|---|
| ClassNotFoundException | 应用程序试图加载类时,找不到相应的类,抛出该异常。 |
| CloneNotSupportedException | 当调用 Object 类中的 clone 方法克隆对象,但该对象的类无法实现 Cloneable 接口时,抛出该异常。 |
| IllegalAccessException | 拒绝访问一个类的时候,抛出该异常。 |
| InstantiationException | 当试图使用 Class 类中的 newInstance 方法创建一个类的实例,而指定的类对象因为是一个接口或是一个抽象类而无法实例化时,抛出该异常。 |
| InterruptedException | 一个线程被另一个线程中断,抛出该异常。 |
| NoSuchFieldException | 请求的变量不存在 |
| NoSuchMethodException | 请求的方法不存在 |
Throwable方法
| 序号 | 方法及说明 |
|---|---|
| 1 | public String getMessage() 返回关于发生的异常的详细信息。这个消息在Throwable 类的构造函数中初始化了。 |
| 2 | public Throwable getCause() 返回一个Throwable 对象代表异常原因。 |
| 3 | public String toString() 使用getMessage()的结果返回类的串级名字。 |
| 4 | public void printStackTrace() 打印toString()结果和栈层次到System.err,即错误输出流。 |
| 5 | public StackTraceElement [] getStackTrace() 返回一个包含堆栈层次的数组。下标为0的元素代表栈顶,最后一个元素代表方法调用堆栈的栈底。 |
| 6 | public Throwable fillInStackTrace() 用当前的调用栈层次填充Throwable 对象栈层次,添加到栈层次任何先前信息中。 |
5.2 异常的处理
异常的处理要么捕获、要么抛出(异常声明)。
5.2.1 受查异常声明
受查异常的声明也是一种处理方案,利用throws声明方法可能抛出的异常,在调用此方法时必须对异常进行处理,要么捕获,要么继续向上级传递抛出,如果主方法上使用了throws抛出,则交给JVM处理,。
在编写方法时,不必将所有可能出现的异常都进行声明(throws)。什么异常使用throws子句进行声明,什么时候不需要,遵循下面原则:
- 调用一个抛出受查异常的方法
- 程序运行过程中发现错误,并且利用throw语句抛出的一个受查异常
- 不需要声明Java的内部错误,即从Error继承的错误。我们对其没有任何控制能力
一个方法必须声明所有可能抛出的受查异常,而非受查异常要么不可控制(Error),要么应该避免发生(RuntimeException)。
throw和throws的区别?
throw和throws都是在异常处理中使用的关键字,区别如下:
- throw:指的是在方法中人为抛出一个异常对象(这个异常对象可能是自己实例化或者抛出已存在的);
- throws:在方法的声明上使用,表示此方法在调用时必须处理异常。
5.2.2 异常捕获
Java提供了try、catch、finally三个关键字来捕获处理异常。
(1)try后必须要有一个catch或者finally块,否则编译不通过。
(2)catch依附于try而存在,有catch必有try,同一个catch语句可以捕获多个异常。
(3)同级异常,catch不分前后,上下级(父子关系),上级放后(其实就是让异常的信息更具体)。
(4)try/catch是最常用的捕获异常的一种方案,finally非必须。
(5)无论是否发生异常或者try语句块存在return,finally里面的代码最终都执行。若finally里面也存在return,那么会覆盖catch或者try里面return的值。编写资源回收的代码通常在finally语句块中
public void readData() {
FileInputStream in = null;
//-----------示例一-----------
try {
in = new FileInputStream("/usr/data");
int read = in.read();
// FileNotFoundException 是IOException的子类,必须放在父类之前
// catch可以捕获多个异常,前提是不存在子类关系。异常之间的类无关联
} catch (FileNotFoundException | UnknownElementException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// finally最终都会执行
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//-----------示例二-----------
// 父类可以捕获其任何子类的异常
// 通过捕获更大范围的异常,可以减少catch语句的数量
try {
in = new FileInputStream("/usr/data");
int read = in.read();
// IOException可以捕获其子类的异常
} catch (IOException e) {
e.printStackTrace();
} finally {
// finally最终都会执行
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//-----------示例三-----------
// JDK1.7新增特性 (try-with-resources)带资源的try catch
// 假设资源属于AutoCloseable类型,try(Resources res=...){},当try语句块执行完毕之后
// 会自动调用res.close方法
try(FileInputStream fin = new FileInputStream("/user/data")) {
int read = fin.read();
} catch (IOException e) {
e.printStackTrace();
}
}
小结
// 向下面那样,finally里面又有try..catch很繁琐,对于处理IO流的关闭,如果项目中有很多这种代码块时,我们不得不考虑优化了
(1)try-with-resources
(2)自定义类继承自AutoCloseable接口,重写close方法,将异常提升到这里面。
finally {
// finally最终都会执行
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
5.3 自定义异常类 断言
在 Java 中你可以自定义异常。编写自己的异常类时需要记住下面的几点。
- 所有异常都必须是 Throwable 的子类。
- 如果希望写一个检查性异常类,则需要继承 Exception 类。
- 如果你想写一个运行时异常类,那么需要继承 RuntimeException 类。
按照国际惯例,自定义的异常应该总是包含如下的构造函数:
- 一个无参构造函数
- 一个带有String参数的构造函数,并传递给父类的构造函数。
- 一个带有String参数和Throwable参数,并都传递给父类构造函数
- 一个带有Throwable 参数的构造函数,并传递给父类的构造函数。
编写自定义异常类,可以参考java源码,例如IOException
package java.io;
public class IOException extends Exception {
static final long serialVersionUID = 7818375828146090155L;
public IOException() {
super();
}
public IOException(String message) {
super(message);
}
public IOException(String message, Throwable cause) {
super(message, cause);
}
public IOException(Throwable cause) {
super(cause);
}
}
如何优雅的处理异常?
6. 泛型程序设计
泛型,即“参数化类型”,将原来的具体类型参数化。在不创建新类型的情况下,通过泛型指定不同的类型形参,来控制实际传入实参的具体类型。换句话说,就是在使用和调用时传入具体的类型。
为什么使用泛型?
- 能够对类型进行限定(比如集合)
- 将运行期错误提前到编译期错误
- 获取明确的限定类型时无需进行强制类型转化
- 具有良好的可读性和安全性
6.1 泛型类
泛型类的定义
一个简单的泛型类,和普通类的区别是,类名后添加了<T>一个泛型标识,“T"类型参数(类型形参),传入的是类型实参,当然也可以用其他字母标识,但是"<>"左右尖括号必须存在。
public class Generic<T> {
private T data;
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
public static void main(String[] args) {
/* 1.没有传入具体的类型参数,可以存放任何类型的数据【下图】
* 本质:虚拟机会对泛型代码进行类型擦除,类型擦除后Generic<T>会变为
* Generic(原始类型),后面会讲到,无限定类型的域用Object代替,即擦除
* 后T data->Object data,这也是为什么没有传入具体类型,却能存放多种
* 类型的原因。
*/
Generic generic = new Generic();
generic.setData(1);
generic.setData("String");
generic.setData(new Object());
Generic genericStr = new Generic<String>();//CORRECT [1]
genericStr.setData("hello");
genericStr.setData(1);
/*
* 2.参数化类型(初始化时传入具体的类型参数)【下图】
* 本质:由编译器进行类型转化的处理,无需人为干预。
* 当调用泛型方法时,编译器自动在调用前后插入相应的
* 强转和调用语句。
*/
Generic<String> genericString=new Generic<>();
genericString.setData("hello");
//Generic<int> genericInt=new Generic<>(); ERROR [2]
Generic<Integer> genericInt=new Generic<>();
}
}
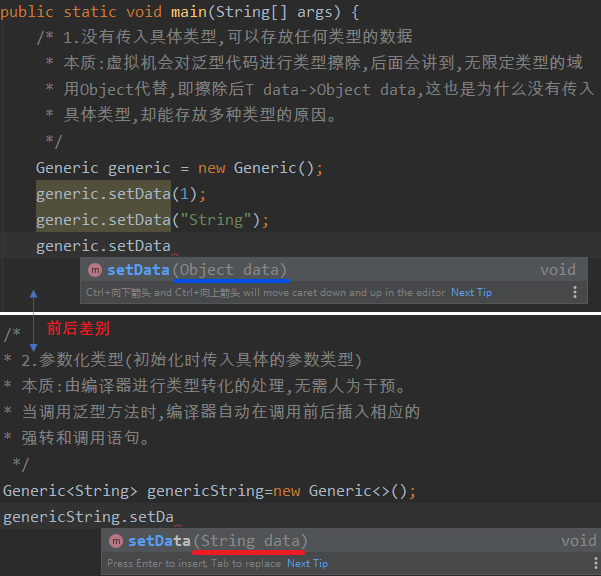
【1】原始类型可以接受任何参数化类型,即Generic generic == new Generic<String>()如[1]处所示。
【2】泛型的类型参数只能是类类型,不能是基本类型。如[2]处,但可以使用期包装类型。
【3】泛型参数命名规范如下:
泛型命名规范:国际惯例,类型参数的命名采用单个大写字母。
常见的泛型命名有:
T- Type:第一类通用类型参数。S- Type:第二类通用类型参数。U- Type:第三类通用类型参数。V- Type:第四类通用类型参数。E- Element:主要用于Java集合(Collections)框架使用。K- KeyV- ValueN- NumberR- Result
6.2 泛型接口
泛型接口的定义
和泛型类定义相似,如下:
public interface GenericInterface<T> {
T getData();
T setData(T data);
}
类接口的实现
类接口的实现存在三种形式,第一种无泛型,域类型用Object定义;第二种有泛型,域变量用泛型参数定义;第三种传递具体的类型参数,域变量的类型为具体的类型。
public class GenericInterfaceImpl implements GenericInterface {
@Override
public Object getData() {
return null;
}
@Override
public Object setData(Object data) {
return null;
}
}
/*
* 实现类的类型参数也需要声明,否则编译器会报错
*/
class GenericInterfaceImpT<T> implements GenericInterface<T> {
@Override
public T getData() {
return null;
}
@Override
public T setData(T data) {
return null;
}
}
/*
* 传入具体的类型实参
*/
class GenericInterfaceImplStr implements GenericInterface<String> {
@Override
public String getData() {
return null;
}
@Override
public String setData(String data) {
return null;
}
}
6.3 泛型方法
泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。
1、泛型方法的定义:类型变量放在修饰符前,返回类型的后面
# 修饰符 <T> 返回值 方法名(...);
* 示例
class ArrayAlg {
/*
*修饰符与返回值(T)中间的<T>标识此方法为泛型方法
*<T>表明该方法可以使用泛型类型T,可以在形参或者方法体中声明变量
/
public static <T> T getMiddle(T...a) {
return a[a.length/2];
}
}
2、调用泛型方法,在方法名前的尖括号放入具体的类型:
String middle = ArrayAlg.<String>getMiddle("John","Q","Public");
// 类型推断:类型参数可以省略 等同于
String middle = ArrayAlg.getMiddle("John","Q","Public");
使用泛型方法时,通常不需要指定参数类型,因为编译器会找出这些类型。 这称为 类型参数推断。
3、泛型方法辨别真假
/*
* 泛型类
* 注意:下面为了介绍,不把泛型方法归类到成员方法里,泛型方法是特指!
*/
public class GenericMethod<T> {
private T data;
/*
* [成员方法:非泛型方法]
* T getData()和setData(T data) 都不是泛型方法
* 他们只是类中的成员方法,只不过是方法的返回值类型
* 和方法的形参类型是用的泛型类上的T所声明的。
*/
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
/*
* [泛型方法]
* 泛型参数可以有多个,这里的T和泛型类上的T无任何关联,但是但是
* 它和泛型类上的参数类型变量相同,这时候idea会给予一个rename提示
*/
public <T,S> T genericMethod(S...a) {
return null;
}
/*
* [泛型方法]
* 使用泛型类上的泛型变量
* 这时候的T就和泛型类的类型相关了
*/
public <V> T genericMethod$1(T a, V b) {
return null;
}
/*
* [静态方法]
* 静态方法不能使用泛型类上的类型参数
* 如果静态方法要使用泛型的话,必须将静态方法也定义成泛型方法
*/
//public static T getDataStatic(T e) { } //ERROR [1]
/*
* [泛型方法]
* 静态泛型方法
*/
public static <E> E genericMethodS(E e) {
return e;
}
}
/*
*普通类中的泛型方法
*/
class OrdinaryClass {
public <T> void sayHello() {
T a;
//...
}
}
下面以苹果为例:
public class GenericClass<T> {
//成员方法,形参类型与泛型类的类型参数相关
public void print$1(T a) {
System.out.println(a.toString());
}
//下面三个都为泛型方法
//--begin
public <T> void print$2(T a) {
System.out.println(a.toString());
}
public <S> void print$3(S a) {
System.out.println(a.toString());
}
public static <T> void print$4(T a) {
System.out.println(a.toString());
}
//--end
public static void main(String[] args) {
Apple apple = new Apple();
MacBook macBook = new MacBook();
HongFuShi hongFuShi = new HongFuShi();
// 泛型类在初始化时限定了参数类型,成员方法中若使用泛型参数将会受限
GenericClass<Apple> genericCls = new GenericClass<>();
genericCls.print$1(apple);
//MacBook是apple的一个子类
genericCls.print$1(macBook);// OK
//由于初始化指定了泛型类型,print$1形参中的参数类型和泛型类的类型参数相关联
//所以,只能打印Apple及其子类
//genericCls.print$1(hongFuShi); ERROR
//泛型方法中的泛型变量类型与泛型类中的泛型参数没有任何关联
//所以说下面都能正常执行
genericCls.print$2(apple);
genericCls.<MacBook>print$2(macBook);//类型参数可以省略 [2]
genericCls.print$2(hongFuShi);
GenericClass.print$4(hongFuShi);
}
}
class Apple {
@Override
public String toString() {
return "Apple,Steve Jobs";
}
}
class MacBook extends Apple {
@Override
public String toString() {
return "MacBook";
}
}
class HongFuShi{
@Override
public String toString() {
return "HongFushi";
}
}
小结:
【1】泛型方法的标识:方法修饰符后返回值之前有"<...>"的声明。(判断是否为泛型方法)
【2】泛型方法可以定义在普通类中,也可以定义在泛型类中。
【3】静态方法不能使用泛型类上的类型参数,如[1]处
【4】成员方法中使用的参数类型和泛型类中的声明的类型参数有关联。
【5】泛型类中的参数类型与泛型方法中的参数类型的关联:泛型方法可以使用泛型类上的参数类型,这时候就与泛型类上的参数相关联;如果泛型方法中声明了与泛型类上相同的参数类型,那么优先使用泛型方法上的参数类型,这时候idea会给予一个rename提示。
【6】泛型方法的使用过程中,无需对类型进行声明,它可以根据传入的参数,自动判断。[2]
【7】方法中泛型参数不是凭空而来的,要么来自于泛型类上所定义的参数类型,要么来自于泛型方法中定义的参数类型。
泛型方法能独立于类而发生变化,所以说在使用原则上,在能达到目的的情况下,尽量使用泛型方法。即,如果使用泛型方法可以取代将整个类泛化,那么应该有限采用泛型方法。
6.3 类型变量的限定
对于类型变量没有限定的泛型类或方法, 它是默认继承自Object,当没有传入具体类型时,它有的能力只有Object类中的几个默认方法实现,原因就是类型擦除。
如果某个类实现Comparable接口中的compareTo方法,我们就可以通过compareTo比较两个值的大小。比如我们要计算数组中的最小元素:
public static void main(String[] args) {
// 传入 4 , 2 , 自动装箱成Integer类
int r = max(4, 2);
}
static <T> T min(T[] a) {
if (a == null || a.length == 0)
return null;
T smallest = a[0];
for (int i = 1; i < a.length; i++)
if (smallest.compareTo(a[i]) > 0)// ERROR,因为编译器不知道T声明的变量是什么类型
smallest = a[i];
return smallest;
}
如果没有对类型进行限定,它默认只有Object能力,变量smallest类型为T,编译器不知道他是否是实现了Comparable接口(是否是Comparable类型),所以可以通过将T限定为实现了Comparable接口的类,就可以解决这一问题。
对 类型参数进行限定,让它能够默认拥有一些类的"能力"。
static <T extends Comparable> T min(T[] a){...}
类型变量限定格式:<T extends BoundingType>
【1】T应该是绑定类型的子类型(subtype)。T和绑定类型可以是类,也可以是接口。
【2】一个类型变量或通配符可以有多个限定,限定类型用”&“分隔,类型变量用逗号分隔。例如:
<T extends Comparable & Serializable>;
<T,E extends Comparable & Serializable>;
【3】在 Java 的继承中, 可以拥有多个接口超类型, 但限定中至多有一个类。 如果用 一个类作为限定, 它必须是限定列表中的第一个。
<T extends ArrayList & LinkedList>;//ERROR,限定中至多有一个类
<T extends Comparable & LinkedList>;//ERROR,必须是限定列表中的第一个
<T extends ArrayList & Comparable>;//CORRECT
【4】类型限定不仅可以在泛型方法上,也可以在泛型类上,类型限定必须与泛型的声明在一起。
public <T extends Number> T compare(Generic<T extends Comparable> a) {..}//ERROR
public <T extends Number> T compare(Generic<T> a) {..}//ERROR
6.4 类型擦除
虚拟机没有泛型类型对象—所有对象都属于普通类。
类型擦除:无论何时定义一个泛型类型,都自动提供了一个相应的原始类型(raw type)。原始类型的名字就是删去类型参数后的泛型类型名。擦除(erased)类型变量,并替换为限定类型,如果没有给定限定就用Object替换。
例如,Holder的原始类型如下:
public class Holder {
private Object holder;
public Holder(Object holder) {
this.holder = holder;
}
public Object getHolder() {
return holder;
}
}
// 类型擦除也会出现在泛型方法中。
public static <T extends Comparable> T min(T[] a);
// 擦除类型之后,只剩下
public static Comparable min(Comparable[] a);
Java泛型 转换的事实:
- 虚拟机中没有泛型,只有普通的类和方法。
- 所有的类型参数都用它们的限定类型替换。
- 桥方法被合成来保持多态。
- 为保持类型安全性,必要时插入强制类型转换。
6.5 泛型的约束与局限
(1)不能用基本类型实例化类型参数
其原因是当类型擦除后,Object类型的域不能存储基本类型的值。
(2)所有的类型查询只产生原始类型
List<Number> numbers = new ArrayList<>();
List<Integer> integers = new ArrayList<>();
System.out.println(numbers.getClass() == integers.getClass());//true
if (integers instanceof List){//true
System.out.println(true);
}
/*if (integers instanceof List<Integer>){//compile error
System.out.println(true);
}*/
(3)不能创建一个确切的泛型类型的数组
//List<Integer>[] lists = new ArrayList<Integer>[10];//ERROR
//可以声明原始类型创建数组,但是会得到一个警告
//可以通过@SuppressWarnings("unchecked")去除
List<Integer>[] list = new ArrayList[10];
//使用通配符创建泛型数组也是可以的,但是需要强制转换
List<Integer>[] listWildcard = (List<Integer>[])new ArrayList<?>[1];
下面采用通配符的方式是被允许的:数组的类型不可以是类型变量,除非是采用通配符的方式,因为对于通配符的方式,最后取出数据是要做显式的类型转换的。
List<?>[] lsa = new List<?>[10]; // OK, array of unbounded wildcard type.
Object o = lsa;
Object[] oa = (Object[]) o;
List<Integer> li = new ArrayList<Integer>();
li.add(new Integer(3));
oa[1] = li; // Correct.
Integer i = (Integer) lsa[1].get(0); // OK
(4)不能实例化类型变量
static <T> Object init(Class<T> cls) throws Exception {
//T a = new T(); // ERROR
// 注意不存在T.class.newInstance();
T t = cls.newInstance();//Class本身也是一个泛型类
return t;
}
(5)不能构造泛型数组
(6)泛型类的静态上下文中类型变量无效
(7)不能抛出或捕获泛型类的实例
6.6 不变 协变 逆变
首先看一段代码
Number[] n = new Integer[10];
ArrayList<Number> list = new ArrayList<Integer>(); // ERROR type mismatch
为什么Number类型的数组可以由Integer实例化,而ArrayList<Number>却不能被ArrayList<Integer>实例化呢?这就涉及到将要介绍的主题。
不变协变逆变的定义:
逆变与协变用来描述类型转换(type transformation)后的继承关系,其定义:如果AA、BB表示类型,f(⋅)表示类型转换,≤表示继承关系(比如,A≤B表示A是由B派生出来的子类);
- f(⋅)是逆变(contravariant)的,当A≤B时有f(B)≤f(A)成立;
- f(⋅)是协变(covariant)的,当A≤B时有f(A)≤f(B)成立;
- f(⋅)是不变(invariant)的,当A≤B时上述两个式子均不成立,即f(A)与f(B)相互之间没有继承关系。
容易证明数组是协变的即Number[] n = new Integer[10];泛型是不变的,即使它的类型参数存在继承关系,但是整个泛型之间没有继承关系 : ArrayList<Number> list = new ArrayList<Integer>();
6.7 泛型类型的继承规则
1. 泛型参数是继承关系的泛型类之间是没有任何继承关系的。
在java中,Number是所有数值类型的父类,任何基本类型的包装类型都继承于它。
ArrayList<Integer> integers = new ArrayList<>();
ArrayList<Number> numbers = new ArrayList<>();
numbers = integers; // ERROR,就上上面刚刚提到的泛型是不变的
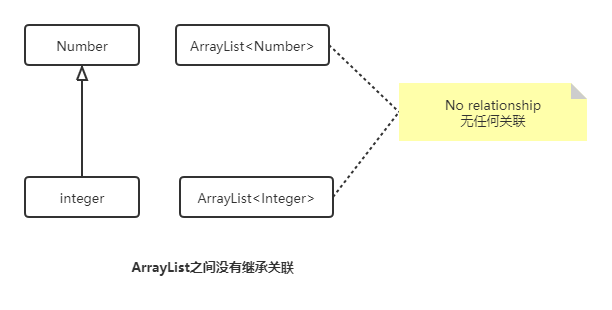
2. 泛型类可以扩展或实现其他的泛型类。这一点和普通类没有声明区别。比如ArrayList<T>类实现List<T>接口。这意味着,一个ArrayList<Integer>可以转换为一个List<Integer>(父类指向了子类的引用),但是,一个ArrayList<Integer>不是一个ArrayList<Number>或List<Number>(泛型参数继承与类无关)。
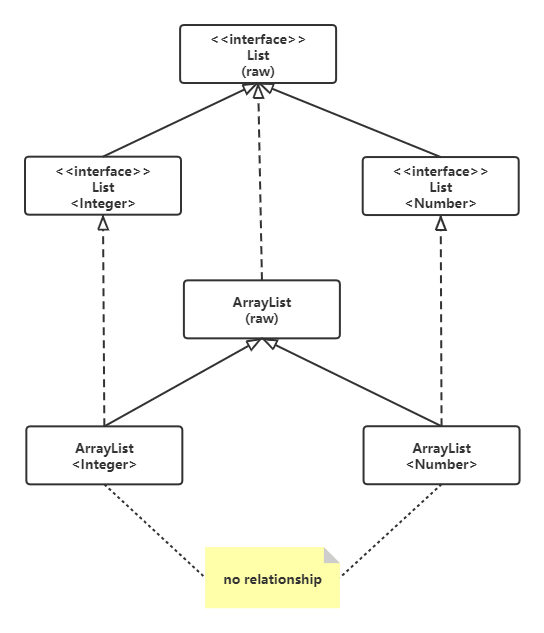
6.7 通配符
Java中引入通配符?来实现逆变和协变,通过通配符之前的操作也能赋值成功,如下所示:
List<? extends Number> number = new ArrayList<Integer>();// CORRECT
List<? super Number> list = new ArrayList<Object>();// CORRECT 逆变的代表
使用通配符的子类型关系
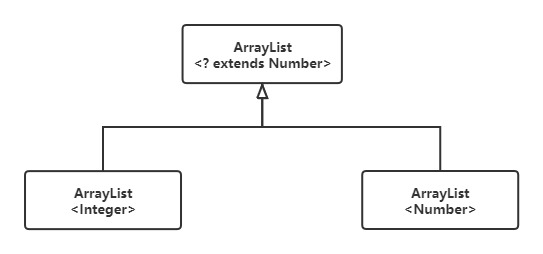
ArrayList<Integer>是ArrayList<? extends Number>的一个子类型。
通配符的分类
-
? extends T(上边界通配符 upper bounded wildcard)"?"是继承自T的任意子类型,表示一种约束关系。即泛型类型的范围不能超过T。
可以取元素,不能添加元素。
-
?(无限定通配符) -
? super T(下边界通配符 lower bounded wildcard)可以取元素,但是取出的元素是Object,可以添加元素,添加的元素,必须是T类或者其子类
记忆:上不存,下不取
示例:类型上边界通配符为什么只能添加?
ArrayList<Integer> integers = new ArrayList<>();
ArrayList<Object> objects = new ArrayList<>();
ArrayList<Number> nums = new ArrayList<>();
/*
* 1. 类型上边界通配符
* 对变量numbers赋值,引用的集合类型参数只能是Number或者其子类。
*/
ArrayList<? extends Number> numbers;
numbers = nums;
numbers = integers;
//引用的类对象类型超过了泛型类型的上边界
//numbers = objects; ERROR
integers.add(1);// 正常添加元素
//numbers.add(1); ERROR numbers只能读取,不能添加[1]
//但是可以添加null
numbers.add(null);
Number number = numbers.get(0);//可以读取元素
为什么只能读取,不能添加?[1]
? extends T 表示类型的上界,类型参数是T的子类,那么可以肯定的说,get方法返回的一定是个T(不管是T或者T的子类)编译器是可以确定知道的。但是add方法只知道传入的是个T,至于具体是T的那个子类,不知道。
转化到本例来说就是:
理解方式一:
? extends Number指定类型参数必须是Number的子类,get方法返回的一定是Number
编译器确定,但是对于ArrayList的add方法为来说add(E e)->add(? extends Number e);
调用add函数不能够确定传入add的是Number的哪个子类型。编译器不确定。
理解方式二:
List是线性表吧【线性结构的存储】,线性表是n个具有相同类型的数据元素的有限序列。假若number能够add,因为? extends Number泛型通配符,可以添加Number的任何子类型,那么numbers在get时,极有可能引发ClassCastException,比如numbers引用了<Integer>,但是在索引0处却add了float类型的数据,取出的时候如果numbers.get(0).intValue();就会抛出异常。并且这也违背了线性表中特性,只能存放单一类型的元素。
/*
* 2. 类型下边界通配符
* numbersSuper所能引用的变量必须是Number或者其父类
*/
ArrayList<? super Number> numbersSuper;
numbersSuper = objects;// 逆变
numbersSuper = nums;
//限定了通配符的下界,类型最低是Number,Integer达不到
//下界,类型不匹配
//numbersSuper = integers; ERROR
numbersSuper.add(1); [2]
numbersSuper.add(2.0f); [3]
//numbersSuper.add(new Object()) ERROR
Object object = numbersSuper.get(0);
System.out.println(object);
? super T 表示类型的下界,类型参数是T的超类(包括T本身), 那么可以肯定的说,get方法返回的一定是个T的超类,那么到底是哪个超类?不知道,但是可以肯定的说,Object一定是它的超类,所以get方法返回Object。 编译器是可以确定知道的。对于add方法来说,编译器不知道它需要的确切类型,但是T和T的子类可以安全的转型为T。
为什么? super Number就可以add了呢?[2、3]
首先要明确的一点是,add的时候只能是Number[T]及其它的子类,不要和numberSuper只能引用Number的父类所混淆了。正因为numberSuper引用了<Object>,那么numberSuper在add的时候类型确定,都可以看作是Object类型,即Number的子类Integer和Float也是其Object的子类。但是相对于? extends T就add就不能调用,numbers如果限定了<Integer>,还是那句话,假若能放的话,number存放float类型的数据,取值时极易引发类型转化异常。
泛型方法和类型通配符
类型通配符所能解决的泛型方法一定也能解决
# 类型通配符
`public void func(List<? extends E> list);`
# 泛型方法
`public <T extends E> void func(List<T> list);`
* 上面两种方法可以达到同样的效果,两者的主要区别还是
i. 泛型对象是只读的,不可修改,因为?类型是不确定的,可以代表范围内任意类型;
ii. 而泛型方法中的泛型参数对象是可修改的,因为类型参数T是确定的(在调用方法时确定),因为T可以用范围内任意类型指定;
泛型方法和类型通配符(上界和下界)我们应该如何选择?
(1)泛型方法和通配符之间
修改最好使用泛型方法,在多个参数、返回值之间存在类型依赖关系就应该使用泛型方法,否则就应该使用通配符。
(2)什么时候用extends什么时候用super
PECS: producer-extends, consumer-super.
—《Effective Java》
- 要从泛型类取数据时,用extends
- 要往泛型类写数据时,用super
7. 集合
Java 集合框架简图,黄色为接口,绿色为抽象类,蓝色为具体类。虚线箭头表示实现关系,实线箭头表示继承关系。
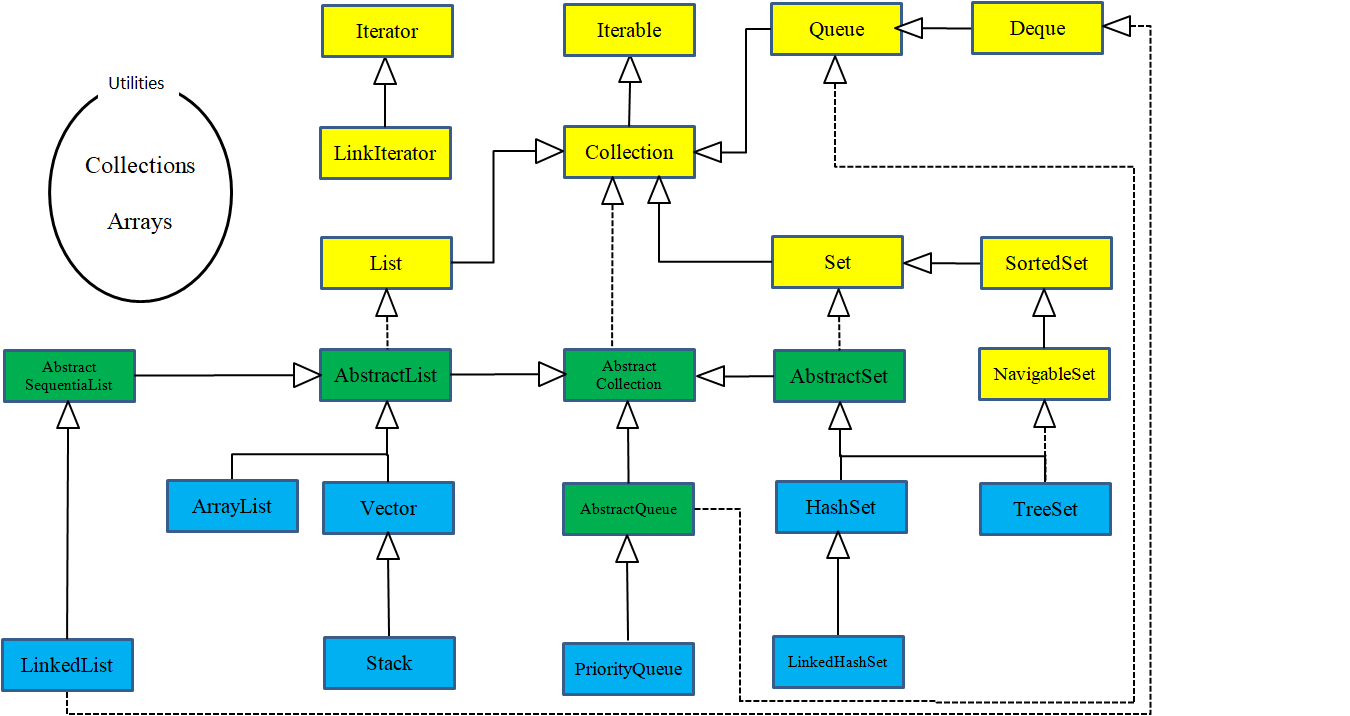
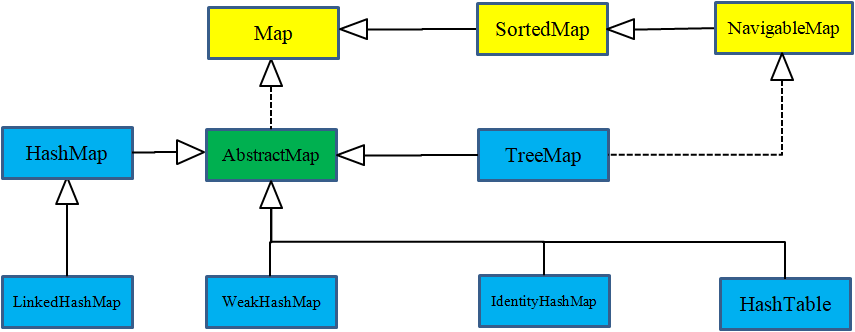
集合和数组,为什么使用集合?
我们可以通过数组来保存一定数量的对象,类型和数量这些都是提前已知的的,但是有时程序需要根据运行时动态创建新的对象,在此之前,无法知道所需对象的数量甚至确切类型,所以集合的出现就可以解决这一问题。
7.1 基本概念
Java集合类库采用接口与实现分离的结构,为不同类型的集合定义了大量接口,Java集合框架中的接口如下图:
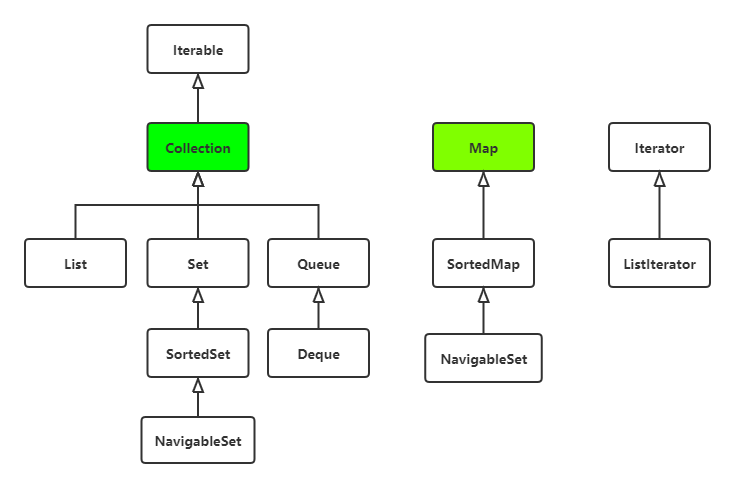
集合中有两个基本接口,Collection和Map
- 集合(Collection):一个独立元素的序列,这些元素都服从一条或多条规则。List 有序集合,必须以插入的顺序保存元素,集合中允许重复元素, Set 集合不保证集合有序,不能包含重复元素, Queue 按照排队规则来确定对象产生的顺序(通常与它们被插入的顺序相同)。
- 映射(Map):一组成对的“键值对”对象。允许使用键来查找值。键唯一,可以为NULL,但只能有一个。ArrayList 使用数字来查找对象,因此在某种意义上讲,它是将数字和对象关联在一起。 map 允许我们使用一个对象来查找另一个对象,它也被称作关联数组(associative array),因为它将对象和其它对象关联在一起;或者称作字典(dictionary),因为可以使用一个键对象来查找值对象,就像在字典中使用单词查找定义一样。
List是一个有序集合(order collection),元素能被增加到容器中特定位置。List集合中的元素有两种访问方式整数索引访问和迭代器访问,整数索引访问又称为随机访问,因为可以按任一顺序访问元素,与之不同的是迭代器访问,只能顺序访问元素。List接口定义了多个随机访问的方法:
void add(int index, E element);
void remove(int index);
E get(int index);
E set(int index, E element);
在程序中使用集合时,往往在构建时才指定具体的实现类,接口指向实现,
List<Apple> apples = new ArrayList<>();
使用接口的好处是,如果你想要改变具体的实现只需要在创建时改变就可以了,如
List<Apple> apples = new LinkedList<>();
但这种方法并非总是可行,因为实现类向上转型为父类型,调用方法只能是父类通用的方法,而具体类存在父类没有的方法,例如, LinkedList 具有 List 接口中未包含的额外方法,而 TreeMap 也具有在 Map 接口中未包含的方法。如果需要使用这些方法,就不能将它们向上转型为更通用的接口。
7.2 Java库中的具体集合
| 集合类型 | 描述 |
|---|---|
| ArrayList | 一种可以动态增长和缩减的索引序列 |
| LinkedList | 一种可以在任何位置进行高效地插入和删除操作的有序序列 |
| ArrayDeque | 一种用循环数组实现的双端队列 |
| HashSet | 一种没有重复元素的无序集合 |
| TreeSet | 一种有序集 |
| EnumSet | 一种包含枚举类型值的集 |
| LinkedHashSet | 一种可以记住元素插入次序的集 |
| PriorityQueue | 一种允许高效删除最小元素的集合 |
| HashMap | 一种存储键/值关联的数据结构 |
| TreeMap | 一种键值有序排列的映射表 |
| EnumMap | 一种键值属于枚举类型的映射表 |
| LinkedHashMap | 一种可以记住键/值项添加次序的映射表 |
| WeakHashMap | 一种其值无用武之地后可以被垃圾回收器回收的映射表 |
| IdentityHashMap | 一种用==而不是用equals比较值的映射表 |
除以Map结尾的类之外,其他类都实现了Collection接口,而以Map结尾的类实现了Map接口。
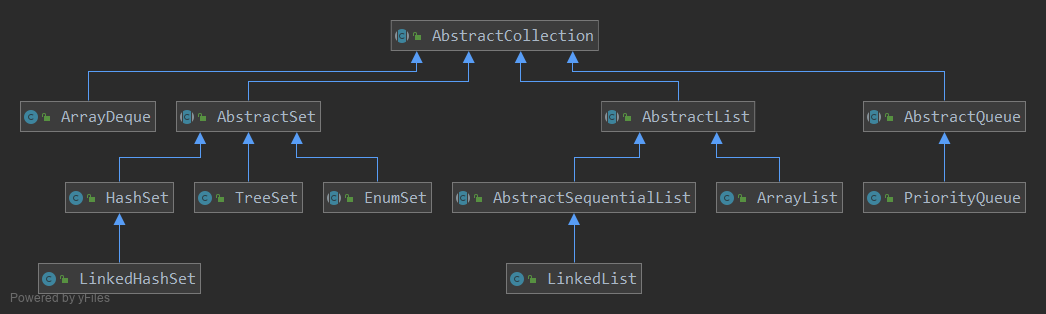
7.2 添加元素组&打印元素
7.4 列表List
List接口在Collection的基础上添加了许多方法,允许在list中间插入和删除元素。
List主要有两种类型的具体实现:
- ArrayList:底层数组实现,动态调整集合的大小,擅长随机访问,但在ArrayList中插入和删除元素速度较慢。
- LinkedList:底层链表实现,擅长插入和删除,对于随机访问来说相对较慢。
7.4.1 List
下面以一个例子来介绍List接口中方法的使用:首先定义一个外部类Phone,提供一个静态方法list返回一组Phone集合。
class Phone {
String name;
static List<Phone> list() {
// Exception in thread "main" java.lang.UnsupportedOperationException
//return Arrays.asList(new HuaWei(), new Nova(), new P40(), new Honor(), new IPhone(), new OnePlus());
return new ArrayList<>(Arrays.asList(new HuaWei(), new Nova(), new P40(), new Honor(), new IPhone(), new OnePlus()));
}
@Override
public String toString() {
return name;
}
}
class HuaWei extends Phone{public HuaWei() {super.name = "HuaWei";}}
class Nova extends Phone{public Nova() {super.name = "Nova";}}
class P40 extends Phone{public P40() {super.name = "P40";}}
class Honor extends Phone{public Honor() {super.name = "Honor";}}
class Honor20 extends Phone{public Honor20() {super.name = "Honor20";}}
class IPhone extends Phone{public IPhone() {super.name = "IPhone";}}
class OnePlus extends Phone{public OnePlus() {super.name = "OnePlus";}}
public class ListTest {
public static void main(String[] args) {
List<Phone> phones = Phone.list();
System.out.println(phones);
//=================[1]====================
Honor20 honor20 = new Honor20();
phones.add(honor20); // Automatically resizes
System.out.println("insert honor20->" + phones);
System.out.println("contains honor20->" + phones.contains(honor20));
phones.remove(honor20); // Remove by Object
phones.remove(1); // Remove by index
System.out.println("remove honor20 and object in 1 index->" + phones);
/*
输出:
[HuaWei, Nova, P40, Honor, IPhone, OnePlus]
insert honor20->[HuaWei, Nova, P40, Honor, IPhone, OnePlus, Honor20]
contains honor20->true
remove honor20 and object in 1 index->[HuaWei, P40, Honor, IPhone, OnePlus]
*/
//=================[2]====================
Phone p = phones.get(0);
System.out.println(p + " index:" + phones.indexOf(p));
HuaWei huaWei = new HuaWei();
// 因为集合中存有一个HuaWei对象
// 在没有将新对象huaWei加入到集合中之前,删除这个新对象,查看是否会影响集合中的HuaWei对象
System.out.println(phones.indexOf(huaWei));
System.out.println(phones.remove(huaWei));
// 删除集合中的HuaWei对象
System.out.println(phones.remove(p));
System.out.println(phones);
phones.add(0, new HuaWei()); // 在指定索引处插入对象
System.out.println(phones);
/*
输出:
HuaWei index:0
-1
false
true
[P40, Honor, IPhone, OnePlus]
[HuaWei, P40, Honor, IPhone, OnePlus]
*/
//=================[3]====================
List<Phone> sub = phones.subList(1, 4);// 求子集范围[1,4),4是开区间
System.out.println("subList: " + sub);
System.out.println("before shuffled containsAll->" + phones.containsAll(sub));
Collections.shuffle(phones); // 打乱集合
System.out.println("shuffled subList: " + sub);
System.out.println("after shuffled containsAll->" + phones.containsAll(phones)); //集合元素的顺序不影响containsAll的结果
ArrayList<Phone> copy = new ArrayList<>(phones);//[3.1]
sub = Arrays.asList(phones.get(1), phones.get(4));//[3.2]
System.out.println("copy: " + copy + " sub: " + sub);
copy.retainAll(sub); //求交集
System.out.println("retainAll(求交集之后)的copy: " + copy);
/*
输出:
subList: [P40, Honor, IPhone]
before shuffled containsAll->true
shuffled subList: [OnePlus, Honor, HuaWei]
after shuffled containsAll->true
copy: [IPhone, OnePlus, Honor, HuaWei, P40] sub: [OnePlus, P40]
retainAll(求交集之后)的copy: [OnePlus, P40]
*/
//=================[4]====================
copy = new ArrayList<>(phones);
copy.removeAll(sub);
System.out.println(copy);
copy.set(1, new Honor()); // replace an element
copy.addAll(2, sub); // 在指定索引处插入集合
System.out.println("before clear phones is empty:" + phones.isEmpty());
phones.clear();
System.out.println("clear phones->" + phones);
System.out.println("after clear phones is empty:" + phones.isEmpty());
phones.addAll(Phone.list());
Object[] objects = phones.toArray();
System.out.println(objects[3]);
Phone[] ph = phones.toArray(new Phone[0]);
System.out.println(ph[3]);
/*
输出:
[IPhone, Honor, HuaWei]
before clear phones is empty:false
clear phones->[]
after clear phones is empty:true
Honor
Honor
*/
}
}
[1]:当向List的实现ArrayList集合中插入元素时,能够动态增减大小(自动扩容调整索引),contains方法判断指定的对象是否在集合内,remove是一个重载方法,可以根据对象删除,也可以根据索引删除。
[2]:如果集合中已存在一个HuaWei对象,在没有将新对象HuaWei加入到集合中之前,删除这个新对象,查看是否会影响集合中的HuaWei对象,这是不会影响原集合的,尽管在认知上认为是同一个。contains行为依赖于equals方法。下面会介绍依赖于equals() 的点。
[3]:subList() 方法可以轻松地从更大的列表中创建切片,注意这里不包括边界,当将切片结果传递给原来这个较大的列表的 containsAll() 方法时,很自然地会得到 true。请注意,顺序并不重要,在 sub 上调用直观命名的 Collections.sort() 和 Collections.shuffle() 方法,不会影响 containsAll() 的结果。 subList() 所产生的列表的幕后支持就是原始列表,sub只持有原始列表的部分引用。
retainAll() 方法实际上是一个“集合交集”操作,在本例中,它保留了同时在 copy 和 sub 中的所有元素。请再次注意,所产生的结果行为依赖于 equals() 方法。
[3.1]、[3.2]处的代码,展示了集合是“持有对象引用”的,集合对象变了,但是集合中数据元素的对象引用并没有发生变化,copy、sub集合里面的对象引用和phone中的对象引用是相同的。
[4]:removeAll() 方法也是基于 equals() 方法运行的。 顾名思义,它会从 List 中删除在参数 List 中的所有元素。可以通过set()方法替换指定索引处的元素值,clear()用于清空集合中的元素(清空了集合中持有的对象引用),isEmpty()判断集合中是否含有对象引用(元素)。对于 List ,有一个重载的 addAll() 方法可以将新列表插入到原始列表的中间位置,而不是仅能用 Collection 的 addAll() 方法将其追加到列表的末尾。
toArray() 方法将任意的 Collection 转换为数组。这是一个重载方法,其无参版本返回一个 Object 数组,但是如果将目标类型的数组传递给这个重载版本,那么它会生成一个指定类型的数组(假设它通过了类型检查)。如果参数数组太小而无法容纳 List 中的所有元素(就像本例一样),则 toArray() 会创建一个具有合适尺寸的新数组
依赖于equals方法?持有对象引用?集合常见误区
1、依赖于equals方法
当确定元素是否是属于某个 List ,寻找某个元素的索引,以及通过引用从 List 中删除元素时,都会用到 equals() 方法(根类 Object 的一个方法),如List.indexOf(Object obj)、List.contains(Object obj)、List.containsAll(List lists)、List.remove(Object obj)、List.removeAll(List lists)、List.retainAll(List lists)。上面的HuaWei的例子也可以说明,新生成的HuaWei对象,当调用contains()方法时,怎么知道集合是否包含HuaWei对象,底层就是通过调用对象的equals()判断是否包含,因为类中都没有重写equals()方法,所以默认调用的是父类中的equals()(判断地址),所以当对新实例HuaWei调用indexOf时,就会返回 -1 (表示未找到),或者调用remove就会返回false。如果我们重写了 equals() ,那么结果就会有所不同。
对于其他类,
equals()的定义可能有所不同。例如,如果两个 String 的内容相同,则这两个 String 相等。因此,为了防止出现意外,请务必注意 List 行为会根据equals()行为而发生变化。
@Test
public void testList() {
List<String> strings = new ArrayList<>(Arrays.asList("Long", "Abc", "Qwe"));
strings.add("Long");
System.out.println(Arrays.toString(strings.toArray()));
System.out.println(strings.remove("Long"));
//System.out.println(strings.remove(new String("Long"))); 等同于上面
System.out.println(Arrays.toString(strings.toArray()));
System.out.println(strings.remove("Long"));
System.out.println(Arrays.toString(strings.toArray()));
/*
输出:
[Long, Abc, Qwe, Long]
true
[Abc, Qwe, Long]
true
[Abc, Qwe]
*/
}
从上面结果我们就可以看出,一String类重写了equals方法,所以remove方法看的效果和之前是不一样的;二因为集合中有两个与"Long"相等的数据元素,默认是从第一个开始处理的,不仅仅是对于remove还有contains等等都会处理第一个出现的元素。
2、持有对象引用
public static void main(String[] args) {
// 持有对象引用思想
List<Phone> phones = Phone.list();
System.out.println(phones);
// copy集合也保存了phones集合中的所持有的对象引用,
// 注意仅仅是保存了一组地址值在集合中,并不是保存了数据对象。
// 注意理解 对象引用的概念。
ArrayList<Phone> copy = new ArrayList<>(phones);
copy.clear();
System.out.println("copy->" + copy);
// copy仅仅是清空了集合中保存的地址值,并没有销毁对象,只是不在持有对象引用
// phones并没有清空引用值,所以说phone还是保留着手机对象的引用值。
System.out.println("phones->" + phones);
// 还是对象引用的概念,这里不再阐述。
Phone phone = phones.get(0);
System.out.println(phone.name);
copy = new ArrayList<>(phones);
Phone copyPhone = copy.get(0);
copyPhone.name = "Nokia";
System.out.println(phone.name);
}
3、集合常见误区?
Phone类中存在一个静态方法
static List<Phone> list() {
// Exception in thread "main" java.lang.UnsupportedOperationException
//return Arrays.asList(new HuaWei(), new Nova(), new P40(), new Honor(), new IPhone(), new OnePlus());[1]
return new ArrayList<>(Arrays.asList(new HuaWei(), new Nova(), new P40(), new Honor(), new IPhone(), new OnePlus()));
}
当使用[1]构造的集合列表,若之后对该集合列表进行add或者remove操作就会引发java.lang.UnsupportedOperationException,这是为什么呢?来看一下Arrays.asList(T... a)底层源码:
@SafeVarargs
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
方法返回的ArrayList,ArrayList集合不可以动态扩容吗?这就很奇怪了,当仔细观察,发现ArrayList并不是java.util.ArrayList,而是java.util.Arrays.ArrayList,属于Arrays的一个私有内部类,继承了AbstractList并重写了一些方法,add和remove方法并没有重写,那么默认会调用父类AbstractList的方法,AbstractList抽象类的add和remove的方法体就是抛出异常,所以说这就是为什么对Arrays.asList(T... a)的结果进行写操作时会引发异常。另一方面来说,java.util.Arrays.ArrayList底层是数组来存储值的,由于add和remove这两个方法会尝试修改数组大小,所以会在运行时得到“Unsupported Operation(不支持的操作)”错误:
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
public E remove(int index) {
throw new UnsupportedOperationException();
}
7.4.2 LinkedList(链表)
数组和数组列表都有一个重大的缺陷,当从数组的中间位置删除一个元素要付出很大的代价,因为数组中处于被删除元素之后的所有元素都要向数组的前端移动,如果数据量大的话,这是十分耗时的。Java中的链表解决了这个问题,链表将对象存放在独立的结点中,每个结点保留着下一个结点的引用。
LinkedList底层结构就是链表,它实现了基本的List接口,它在List中间执行插入和删除时比ArrayList更高效,但随机访问操作效率不及ArrayList。
在Java中,所有链表实际上都是双向链表(doubly linked)—每个结点还存放着指向前驱结点的引用。
LinkedList 还添加了一些方法,使其可以被用作栈、队列或双端队列(deque) 。在这些方法中,有些彼此之间可能只是名称有些差异,或者只存在些许差异,以使得这些名字在特定用法的上下文环境中更加适用(特别是在 Queue 中)。例如:
getFirst()和element()是相同的,element()底层就是调用的getFirst(),它们都返回列表的头部(第一个元素)而并不删除它,如果 List 为空,则抛出 NoSuchElementException 异常。peek()方法与这两个方法只是稍有差异,它在列表为空时返回 null 。removeFirst()和remove()也是相同的,它们删除并返回列表的头部元素,并在列表为空时抛出 NoSuchElementException 异常。poll()稍有差异,它在列表为空时返回 null 。addFirst()在列表的开头插入一个元素。offer()与add()和addLast()相同。 它们都在列表的尾部(末尾)添加一个元素。removeLast()删除并返回列表的最后一个元素。
示例:
public class LinkedListTest {
public static void main(String[] args) {
LinkedList<Phone> phones = new LinkedList<>(Phone.list());
System.out.println(phones);
// 获取第一个元素,不同点是对empty-list的行为不同
System.out.println("getFirst:" + phones.getFirst());
System.out.println("element:" + phones.element());
System.out.println("peek:" + phones.peek());
// 删除并返回删除的元素
System.out.println("phones.remove():" + phones.remove());// 底层通过removeFirst删除
System.out.println("phones.removeFirst():" + phones.removeFirst());
System.out.println("phones.poll():" + phones.poll());
System.out.println(phones);
// 在列表头插入一个元素
phones.addFirst(Phone.get());
System.out.println("After addFirst():" + phones);
// 在列表尾插入元素 offer add addLast
phones.offer(Phone.get());
System.out.println("After offer():" + phones);
phones.add(Phone.get());
System.out.println("After add():" + phones);
phones.addLast(new Honor20());
System.out.println("After addLast(): " + phones);
/*
输出:
[HuaWei, Nova, P40, Honor, IPhone, OnePlus]
getFirst:HuaWei
element:HuaWei
peek:HuaWei
phones.remove():HuaWei
phones.removeFirst():Nova
phones.poll():P40
[Honor, IPhone, OnePlus]
After addFirst():[OnePlus, Honor, IPhone, OnePlus]
After offer():[OnePlus, Honor, IPhone, OnePlus, IPhone]
After add():[OnePlus, Honor, IPhone, OnePlus, IPhone, IPhone]
After addLast(): [OnePlus, Honor, IPhone, OnePlus, IPhone, IPhone, Honor20]
*/
}
}
7.5 Iterator
迭代器是一个对象,它在一个序列中移动并选择该序列中的每个对象,而客户端程序员不知道或不关心该序列的底层结构。另外迭代器通常称为轻量级对象(lightweight object):创建它的代价小。Java的Iterator只能单向移动。
Iterator接口源码:
public interface Iterator<E> {
/*检查序列中是否还有元素*/
boolean hasNext();
/*获得序列中的下一个元素*/
E next();
/*将迭代器最近返回的那个元素删除*/
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
Iterator的简单使用
示例一:
public class IteratorTest {
public static void main(String[] args) {
// Iterator遍历元素
List<Phone> phones = Phone.list();
Iterator<Phone> it = phones.iterator();
while (it.hasNext()) {
Phone p = it.next();
System.out.print(p + " ");
}
System.out.println();
// for-each增强for循环,Collection接口扩展了Iterable接口,
// 对于任何实现了Collection接口的类都使用for-each循环
for (Phone p : phones) {
System.out.print(p + " ");
}
System.out.println();
// 利用Iterator删除元素
it = phones.iterator();
for (int i = 0; i < 3; i++) {
it.next();
it.remove();
}
System.out.println(phones);
/*
输出
HuaWei Nova P40 Honor IPhone OnePlus
HuaWei Nova P40 Honor IPhone OnePlus
[Honor, IPhone, OnePlus]
*/
}
}
根据示例一,可得知,有了Iterator,遍历元素时,我们不在关心集合的数量,会由hasNext()和next()帮我们处理。Iterator可以删除next()生成的最后一个元素,需要注意,必须在next之后调用remove(),至于为什么,下面会介绍。
示例二:
public class IteratorTestTwo {
public static void display(Iterator<Phone> it) {
while(it.hasNext()) {
Phone p = it.next();
System.out.print(p + " ");
}
System.out.println();
}
// 更通用的方法
public static void display(Iterable<Phone> iterable) {
iterable.forEach(System.out::print);
}
public static void main(String[] args) {
List<Phone> phones = Phone.list();
LinkedList<Phone> phonesLL = new LinkedList<>(phones);
HashSet<Phone> phonesHS = new HashSet<>(phones);
// 注意这里需要之前的Phone类实现Comparable接口,因为TreeSet需要比较然后按元素顺序排序
TreeSet<Phone> phonesTS = new TreeSet<>(phones);
display(phones.iterator());
display(phonesLL.iterator());
display(phonesHS.iterator());
display(phonesTS.iterator());
/*
输出:
HuaWei Nova P40 Honor IPhone OnePlus
HuaWei Nova P40 Honor IPhone OnePlus
P40 OnePlus IPhone HuaWei Honor Nova
Honor HuaWei IPhone Nova OnePlus P40
*/
display(phones); // List间接继承了Iterable接口,对于其他集合序列也一样
}
}
示例二展示了我们无需知道具体序列的类型,Iterator将遍历序列的操作与该序列的底层结构分离,或者说迭代器统一了对集合的访问方式。另外display是一个重载方法,形参是Iterable类型的,Iterable可以产生Iterator的任何方法,并且它还有一个forEach默认方法。使用它对集合的访问显得更简单,可以直接通过display(phones)就可以访问,因为集合都实现了Collection,而它又扩展了Iterable,间接继承。
Collection类扩展了Iterable接口,而Iterable接口提供了获取一个Iterator对象的方法,所以对于任何集合,都可以获取它的Iterator对象。
7.5.1 ListIterator
ListIterator是一个更强大的Iterator子类型,它只能由各种List类生成。Iterator 只能向前移动,而 ListIterator 可以双向移动。它可以生成迭代器在列表中指向位置的后一个和前一个元素的索引,并且支持修改集合中的元素。可以通过调用集合实现类中的 listIterator() 方法来生成指向 List 开头处的 ListIterator ,还可以通过调用 listIterator(n) 创建一个一开始就指向列表索引号为 n 的元素处的 ListIterator 。
ListIterator源码
public interface ListIterator<E> extends Iterator<E> {
// Query Operations
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
// Modification Operations
void remove();
/*set方法用一个新元素取代调用next或previous方法返回的上一个元素*/
void set(E e);
void add(E e);
}
示例:
public static void main(String[] args) {
List<Phone> phones = Phone.list();
ListIterator<Phone> it = phones.listIterator();
while (it.hasNext()) {
System.out.println(it.next() + ",nextIndex:" + it.nextIndex() + ",previousIndex:" + it.previousIndex()+";");
}
// 从后往前遍历
System.out.print("reverse traverse->" );
while (it.hasPrevious()) {
System.out.print(it.previous() + " ");
}
System.out.println();
System.out.println(phones);
it = phones.listIterator(3);
// 获得从索引3处开始的ListIterator对象
while (it.hasNext()) {
it.next();
// get()会随机得到一个Phone对象
it.set(Phone.get());
}
// 在集合尾部添加一个元素
it.add(Phone.get());
System.out.println(phones);
/*
输出:
HuaWei,nextIndex:1,previousIndex:0;
Nova,nextIndex:2,previousIndex:1;
P40,nextIndex:3,previousIndex:2;
Honor,nextIndex:4,previousIndex:3;
IPhone,nextIndex:5,previousIndex:4;
OnePlus,nextIndex:6,previousIndex:5;
reverse traverse->OnePlus IPhone Honor P40 Nova HuaWei
[HuaWei, Nova, P40, Honor, IPhone, OnePlus]
[HuaWei, Nova, P40, OnePlus, IPhone, P40, Honor]
*/
}
ListIterator是一个接口,ArrayList没有实现却能返回这个接口的对象?
底层发现ArrayList并没有直接实现ListIterator,有点和Arrays类似,也是通过一个私有匿名内部类间接实现ListIterator,所以说就能获得该对象。
看源码!
7.5.2 迭代器注意点
7.5.2.1 迭代器解析
Java迭代器的查找操作和位置变更是紧密相连的。只能顺序next()或者反序previous()依次遍历。不能像get(index)那样随机访问。
因此,应该讲Java迭代器认为是位于两个元素之间。当调用next或者previous,迭代器就越过下一个元素或者上一个元素,并返回刚刚越过的那个元素的引用。
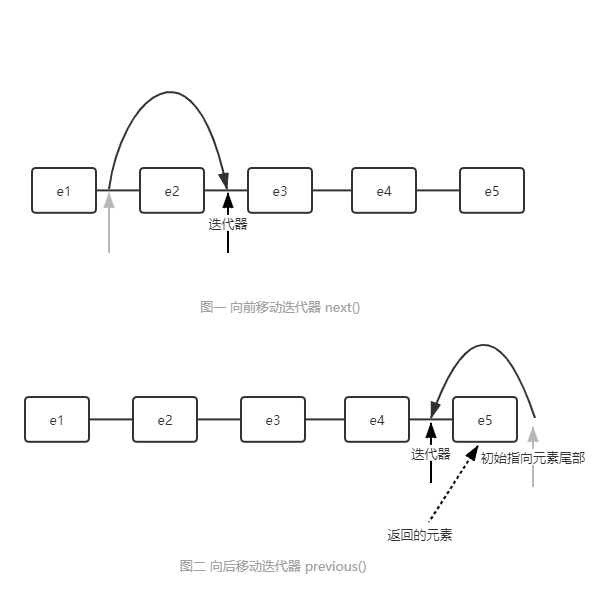
Iterator的next方法和remove方法的调用具有相互依赖性。如果调用remove之前没有调用next将是不合法的。否则就会抛出IllegalStateException。对于previous同样道理。
List<String> strings = new ArrayList<>(Arrays.asList("aaa", "bbb", "ccc"));
ListIterator<String> it = strings.listIterator(3);
while (it.hasPrevious()) {
it.hasPrevious();
it.remove();
// 不可再次调用,只消耗刚刚返回的那个元素
// it.remove();
}
这样做有什么好处,我所理解到的是避免了一定的死循环,比如
List<String> strings = new ArrayList<>(Arrays.asList("aaa", "bbb", "ccc"));
ListIterator<String> it = strings.listIterator();
// [1]没有死循环
while (it.hasNext()) {
it.next();
it.add("11");
}
System.out.println(Arrays.toString(strings.toArray()));
// 输出:[aaa, 11, bbb, 11, ccc, 11]
// [2]下面就会出现死循环
while (it.hasPrevious()) {
it.previous();
it.add("22");
}
System.out.println(Arrays.toString(strings.toArray()));
// 死循环
[1]如果it指针指向了当前索引而不是当前元素和下一个元素的中间位置,那么上面就会造成死循环。因为遍历的总是插入的前一个元素
[2]为什么会死循环?看源码给予了解答:
/*
*Inserts the specified element into the list (optional operation).
* The element is inserted immediately before the element that
* would be returned by {@link #next}, if any, and after the element
* that would be returned by {@link #previous}, if any
*/
插入元素在调用next()方法返回的元素之前(如果有的话),或者调用previous()在返回的元素之后插入(如果有的话)。当调用previous()后,然后add()总是会在光标(指针所在位置)之后插入,所以就会导致插入的元素总是在光标之后,从而导致了死循环。下图解释了这一现象:
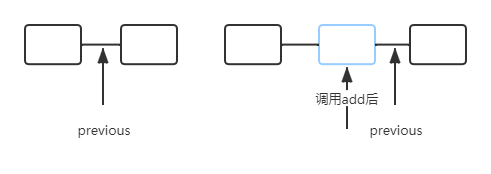
7.5.2.2 多个迭代器修改访问异常
ConcurrentModificationException得益于集合的fail-fast快速失败机制,当使用迭代器对集合进行遍历的时候,会检查expectModcount和modcount这两个变量值是否相等,如果不相等则抛出异常。
List<String> strings = new ArrayList<>(Arrays.asList("aaa", "bbb", "ccc"));
ListIterator<String> it1 = strings.listIterator();
ListIterator<String> it2 = strings.listIterator();
it1.next();
it1.remove();
it2.next();
// Exception in thread "main" java.util.ConcurrentModificationException
1)如果在某个迭代器修改集合时,另一个迭代器对其进行遍历,一定会出现混乱的状态。如上,如果一个迭代器指向另一个迭代器刚刚删除的元素前,现在这个迭代器就是无效的,并且不应该在使用。否则抛出ConcurrentModificationException。
2)在迭代元素的时候不能通过集合List中的方法删除元素, 否则会抛出ConcurrentModificationException 异常. 但是可以通过Iterator接口中的remove()方法进行删除,Iterator接口中的remove()底层是将modCount修改为expectedModCount。
fail-fast&fail-safe
快速失败机制和安全失败机制的区别?
Iterator的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。java.util包下面的所有的集合类都是快速失败的,而java.util.concurrent包下面的所有的类都是安全失败的。快速失败的迭代器会抛出ConcurrentModificationException异常,而安全失败的迭代器永远不会抛出这样的异常。
7.6 集合Set
复习散列表的知识 —数据结构与算法
Set是没有重复元素的元素集合。set的add方法首先在集中查找要添加的对象,如果不存在,就将这个对象添加进去。set没有get方法,因为其元素是无序的,所以说遍历只能用迭代器。
7.6.1 HashSet
Java集合类库提供了一个HashSet类,它实现了基于散列表的集。可以用add方法添加元素。contains方法已经被重新定义,用来快速查看是否某个元素已经出现在集中。
下面是使用存放 Integer 对象的 HashSet 的示例:
public class HashSetTest {
public static void main(String[] args) {
Random random = new Random(47);
Set<Integer> intset = new HashSet<>();
for (int i = 0; i < 10000; i++)
intset.add(random.nextInt(30));
System.out.println(intset);
}
/*
输出:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
*/
}
在 0 到 29 之间的 10000 个随机整数被添加到 Set 中,因此可以想象每个值都重复了很多次。但是从结果中可以看到,每一个数只有一个实例出现在结果中。
7.6.2 TreeSet(树集)
TreeSet是一个有序集合(sorted collection)。可以以任意顺序将元素插入到集合中。在对集合进行遍历时,每个值将自动地按照排序后的顺序呈现。
要使用树集,必须能够比较元素。这些元素必须实现Comparable接口,或者构造集时必须提供一个Comparator。
Set<String> set = new TreeSet<>();
set.add("Moon");
set.add("Mars");
set.add("Earth");
set.add("Jupiter");
System.out.println(set);// [Earth, Jupiter, Mars, Moon]
TODO 还需深入,这里只是介绍了如何使用
7.7 队列Queue
队列是一种先进先出(FIFO)的集合结构,队尾插入,队头删除。有两个端头的队列,即双端队列,可以让人们有效地在头部和尾部同时添加或删除元素。不支持在队列中间添加元素。在JavaSE6中引入了Deque接口,由ArrayDeque和LinkedList类实现。
下面演示了队列的基本使用:
public static void main(String[] args) {
Queue<Integer> queue = new ArrayDeque<>(8);
for (int i = 0; i < 100; i++) {
queue.offer(i);
}
while (queue.peek() != null) {
System.out.println(queue.poll());
}
}
7.7.1 优先级队列
优先级队列(priority queue)中的元素可以按照任意的顺序插入,却总是按照排序的顺序进行检索。也就是说,无论何时调用remove方法,总会获得当前优先级队列中最小的元素。
当在PriorityQueue上调用offer()方法来插入一个对象时,该对象会在队列中被排序。默认的排序使用队列中对象的自然排序自然排序(natural order),但是可以通过提供自己的Comparator来修改这个顺序。PriorityQueue确保在调用 peek() , poll() 或 remove() 方法时,获得的元素将是队列中优先级最高的元素。
习惯上将1设为“最高”优先级,所以数字越小优先级越高。
public class QueueTest {
public static void printQ(Queue queue) {
while(queue.peek() != null)
System.out.print(queue.remove() + " ");
System.out.println();
}
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
Random rand = new Random(47);
for(int i = 0; i < 10; i++)
priorityQueue.offer(rand.nextInt(i + 10));
printQ(priorityQueue);
List<Integer> inst = Arrays.asList(25, 22, 20, 18, 14, 9, 3, 1, 1);
priorityQueue = new PriorityQueue<>(inst);
printQ(priorityQueue);
priorityQueue = new PriorityQueue<>(inst.size(), Collections.reverseOrder());
priorityQueue.addAll(inst);
printQ(priorityQueue);
/*输出:
0 1 1 1 1 1 3 5 8 14
1 1 3 9 14 18 20 22 25
25 22 20 18 14 9 3 1 1
*/
}
}
PriorityQueue 是允许重复的,最小的值具有最高的优先级(如果是 String ,空格也可以算作值,并且比字母的优先级高)。
为了展示如何通过提供自己的 Comparator 对象来改变顺序,第三个对 PriorityQueue 构造器的调用,和第二个对 PriorityQueue 的调用使用了由 Collections.reverseOrder() (Java 5 中新添加的)产生的反序的 Comparator 。
Integer , String 和 Character 可以与 PriorityQueue 一起使用,因为这些类已经内置了自然排序。如果想在 PriorityQueue 中使用自己的类,则必须包含额外的功能以产生自然排序,或者必须提供自己的 Comparator 。
TODO for-each iterable
7.8 映射
映射提供了一种根据键来查找值的方案。映射存放键/值对。如果提供了键,就能够查找到值。
Java类库为映射提供了两个通用的实现:HashMap和TreeMap。
散列映射对键进行散列,树映射用键的整体顺序对元素进行排序,并将其组织成搜索树。散列稍微快一些,如果不需要按照排列顺序访问键,最好选用散列。
7.8.1 基本映射操作
(1)散列中键唯一,键值可以为null,但键值只有一个为null,如果对同一个键两次调用put方法,第二个值就会取代第一个值。put将 返回用这个键参数存储的上一个值。
(2)可以使用forEach迭代遍历映射中的键和值。
下面演示了映射的基本操作:
public class MapTest {
public static void main(String[] args) {
Map<String, Employee> staff = new HashMap<>();
staff.put("1001", new Employee("Tomes"));
staff.put("1002", new Employee("Andrew"));
staff.put("1003", new Employee("Jase"));
// print all entries
System.out.println(staff);
// remove an entry
staff.remove("1002");
// replace
staff.put("1003", new Employee("Jasen"));
System.out.println(staff.get("1003"));
System.out.println(staff.getOrDefault("1002", null));
// iterate
staff.forEach((k, v)-> {
System.out.println("key=" + k + "value" + v);
});
}
}
deafult V getOrDefault(Object key, V defaultValue)获得与键关联的值,如果未在映射中中找到这个键,则返回defaultValue.
containsKey(Object key)
containsValue(Object value)
default void forEach(BiConsumer<? super K, ? super V> action)
7.8.2 更新映射项
现在我们要统计一个单词出现的频度, 当出现一个单词(word)时,我们让计数器增一:
Map<String, Integer> counts = new HashMap<>();
counts.put("eldest", counts.get("eldest") + 1);
考虑运行上面程序会出现上面,java.lang.NullPointerException,当第一次get时,还没有添加该单词,导致获取的为值为空,然后还有一步自动装箱的动作,空指针异常就是发生在装箱时。所以说对于有些空值需要特殊处理,上面可以采用以下几种解决方案:
// 第一种方案
counts.put("eldest", num == null? 1 : num + 1);
// 第二种方案
counts.putIfAbsent("eldest", 0);
counts.put("eldest", num + 1);
// 第三种方案
counts.merge("eldest", 1, Integer::sum);
8. 线程
参考:
[Matrix海子]https://www.cnblogs.com/dolphin0520/p/3923737.html
[codercc]http://www.codercc.com/backend/basic/juc/
hollischuang.com/archives/category/java
---第一篇基础篇---
进程的由来
早期,计算机只能接受一些特定的指令,用户输入一个指令,计算机就做一个操作,当用户在输入数据或者思考问题的时候,计算机就在等待,显然在用户输入数据或者思考的这个过程中,CPU只能等待,浪费了资源。这就是早期的单道处理系统。
如果能把一系列需要的操作指令都预先准备好,然后一次性交给计算机进行运算,这样CPU资源能得到充分利用,批处理系统就诞生了。
但是批处理系统任然存在很大的问题,比如计算机中预执行两个任务A和B,A先得到执行,一段时间后A任务进行IO操作,A任务需要将结果写到其他存储介质上,写的过程(排除写结束和写开始)很少需要CPU的干预,这时候CPU是空闲的,如果让CPU在A写时去执行B,当A写完后通知CPU,再去执行A,CPU的资源就能得到充分的利用。以上存在的问题,计算机是如何知道当前CPU运行的是A还是B,当A写完,挂起B,重新执行A时,CPU怎么知道执行到A的哪个地方了呢?
因此,人们就发明了进程,用进程来对应每一个程序,具体来说,进程都会有自己的数据结构,进程ID可以标识一个程序。当进程(程序)之间切换的时候,当进程暂停时,它会保存当前进程的状态(比如进程标识、进程的使用的资源等),在下一次重新切换回来时,便根据之前保存的状态进行恢复,然后继续执行。
这就是并发的雏形,宏观上有多个任务同时执行,微观上还是交替执行,任意一个时刻只有一个任务占领CPU(单核CPU来说)。
进程然操作系统的并发成为可能。
线程的由来
进程虽然提升了系统的运行效率,但随着计算机的发展,人们对实时性有了要求。因为一个进程可能会有多个子任务,在没有线程时,只能挨个执行各个的子任务。比如用户点击一个按钮进行网络请求获取信息,在后台没有响应之前,用户只能在响应之后才能进行任何操作,用户体验很差。但是如果有多线程将进程分为多个任务,每个线程都可以各司其职。当用户发起一个请求后,网络请求的线程去请求后台信息,当前可以继续进行做其他的操作。
线程让进程内部的并发成为可能。
一个进程可能包括多个线程,这些线程是共享进程占有的资源和地址空间的。进程是操作系统进行资源分配的基本单位,而线程是操作系统进行调度的基本单位。
多线程入门类和接口
Thread类和Runnable接口
1、继承自Thread类
public class Demo {
public static class MyThread extends Thread {
@Override
public void run() {
System.out.println("MyThread");
}
}
public static void main(String[] args) {
Thread myThread = new MyThread();
myThread.start();
}
}
注意点:
- run方法仅是执行里面的任务,并不会开启新线程,只有调用
start()方法之后,线程才算启动成功。 - 线程开启后,不可多次调用
start()方法,否则抛出IllegalThreadStateException异常。 - 在程序里面调用了start()方法后,虚拟机会先为我们创建一个线程,然后等到这个线程第一次得到时间片时再调用run()方法。
2、实现Runnable接口
Runnable接口是一个函数式接口,我们可以使用Java 8的函数式编程简化代码。
public class Demo {
public static class MyThread implements Runnable {
@Override
public void run() {
System.out.println("MyThread");
}
}
public static void main(String[] args) {
new MyThread().start();
// Java 8 函数式编程,可以省略MyThread类
new Thread(() -> {
System.out.println("Java 8 匿名内部类");
}).start();
}
}
3、Thread类
/**
* Thread类实现了Runnable接口,通过在构造函数中调用init初始化线程
*/
public class Thread implements Runnable {
// Thread类源码
// 片段1 - init方法
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals)
// 片段2 - 构造函数调用init方法
public Thread(Runnable target) {
init(null, target, "Thread-" + nextThreadNum(), 0);
}
// 片段3 - 使用在init方法里初始化AccessControlContext类型的私有属性
this.inheritedAccessControlContext =
acc != null ? acc : AccessController.getContext();
// 片段4 - 两个对用于支持ThreadLocal的私有属性
ThreadLocal.ThreadLocalMap threadLocals = null;
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
}
init方法的参数介绍:
- g:线程组,指定这个线程是在哪个线程组下。
- target:指定要执行的任务对象。
- name:线程的名字,多个线程的名字可以重复。如果不指定名字,则会调用
nextThreadNum()返回一个值。
在main方法里,我们开启两个线程,打印这两个线程的对象默认会有以下输出
Thread[Thread-0,5,main]
Thread[Thread-1,5,main]
#Thread-0:就是当前线程的名字,5表示线程的优先级,main表示线程所属组
Thread-num num是递增的,原因就是nextThreadNum每次返回一个递增的值
通常情况下,我们会直接调用下面两个构造方法:
Thread(Runnable target)
Thread(Runnable target, String name)
Thread类的几个常用方法:
-
currentThread():静态方法,返回对当前正在执行的线程对象的引用;
-
start():开始执行线程的方法,java虚拟机会调用线程内的run()方法;
-
yield():yield在英语里有放弃的意思,同样,这里的yield()指的是当前线程愿意让出对当前处理器的占用。这里需要注意的是,就算当前线程调用了yield()方法,程序在调度的时候,也还有可能继续运行这个线程的;
-
sleep():静态方法,使当前线程睡眠一段时间;
-
join():使当前线程等待另一个线程执行完毕之后再继续执行,内部调用的是Object类的wait方法实现的;
Callable、Future与FutureTask
通常来说,我们使用Runnable和Thread来创建一个新的线程。但是它们有一个弊端,就是run方法是没有返回值的。而有时候我们希望开启一个线程去执行一个任务,并且这个任务执行完成后有一个返回值。
JDK提供了Callable接口与Future类为我们解决这个问题,这也是所谓的“异步”模型。
1、Callable接口
Callable一般是配合线程池工具ExecutorService来使用的。这里只介绍ExecutorService可以使用submit方法来让一个Callable接口执行。它会返回一个Future,我们后续的程序可以通过这个Future的get方法得到结果。
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
使用Callable接口:
// 自定义Callable
class Task implements Callable<Integer>{
@Override
public Integer call() throws Exception {
// 模拟计算需要一秒
Thread.sleep(1000);
return 2;
}
public static void main(String args[]){
// 使用
ExecutorService executor = Executors.newCachedThreadPool();
Task task = new Task();
Future<Integer> result = executor.submit(task);
// 注意调用get方法会阻塞当前线程,直到得到结果。
// 所以实际编码中建议使用可以设置超时时间的重载get方法。
System.out.println(result.get());
}
}
2、Future接口
package java.util.concurrent;
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
cancel方法是试图取消一个线程的执行。
注意是试图取消,并不一定能取消成功。因为任务可能已完成、已取消、或者一些其它因素不能取消,存在取消失败的可能。boolean类型的返回值是“是否取消成功”的意思。参数paramBoolean表示是否采用中断的方式取消线程执行。
所以有时候,为了让任务有能够取消的功能,就使用Callable来代替Runnable。如果为了可取消性而使用 Future但又不提供可用的结果,则可以声明 Future形式类型、并返回 null作为底层任务的结果。
3、FutrueTask类
FutureTask是实现的RunnableFuture接口的,而RunnableFuture接口同时继承了Runnable接口和Future接口:
public interface RunnableFuture<V> extends Runnable, Future<V> {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}
那FutureTask类有什么用?为什么要有一个FutureTask类?前面说到了Future只是一个接口,而它里面的cancel,get,isDone等方法要自己实现起来都是非常复杂的。所以JDK提供了一个FutureTask类来供我们使用。
示例:
// 自定义Callable,与上面一样
class Task implements Callable<Integer>{
@Override
public Integer call() throws Exception {
// 模拟计算需要一秒
Thread.sleep(1000);
return 2;
}
public static void main(String args[]){
// 使用
ExecutorService executor = Executors.newCachedThreadPool();
FutureTask<Integer> futureTask = new FutureTask<>(new Task());
executor.submit(futureTask);
System.out.println(futureTask.get());
}
}
使用上与第一个Demo有一点小的区别。首先,调用submit方法是没有返回值的。这里实际上是调用的submit(Runnable task)方法,而上面的Demo,调用的是submit(Callable task)方法。
然后,这里是使用FutureTask直接取get取值,而上面的Demo是通过submit方法返回的Future去取值。
在很多高并发的环境下,有可能Callable和FutureTask会创建多次。FutureTask能够在高并发环境下确保任务只执行一次。
4、FutureTask的几个状态
/**
*
* state可能的状态转变路径如下:
* NEW -> COMPLETING -> NORMAL
* NEW -> COMPLETING -> EXCEPTIONAL
* NEW -> CANCELLED
* NEW -> INTERRUPTING -> INTERRUPTED
*/
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
state表示任务的运行状态,初始状态为NEW。运行状态只会在set、setException、cancel方法中终止。COMPLETING、INTERRUPTING是任务完成后的瞬时状态。
线程的生命周期
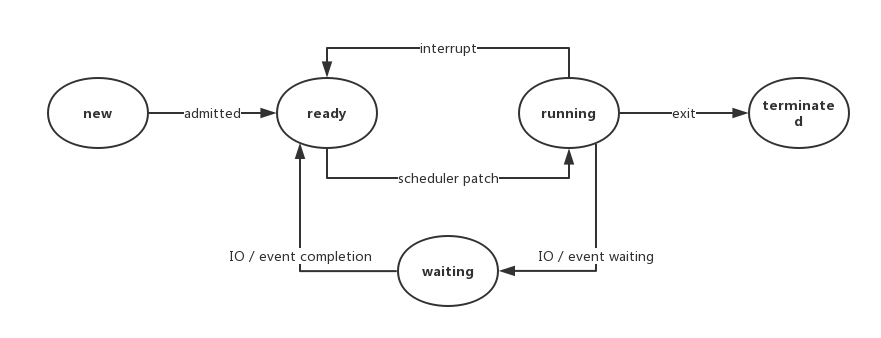
线程的生命周期包含5个阶段:新建、就绪、运行、阻塞、死亡。
新建状态:创建一个线程对象后,线程就处于新建状态,此时该线程和普通的Java对象一样仅仅是分配了内存空间,并没有表现出线程的任何动态特性。
就绪状态:当线程对象调用start()方法后,线程就处于就绪状态,JVM会为其创建方法调用栈和程序计数器。处于就绪状态的线程并不会立即得到执行,此时,它只是具备了运行的条件,至于什么时候运行,则取决于JVM里线程调度器的调度。所以线程的执行是由底层平台控制, 具有一定的随机性。
运行状态:处于就绪状态的线程,得到CPU的使用权,就会执行run()方法,线程就处于运行状态。在单处理器机器上,只能有一个线程运行;在多处理器机器上,每个处理器运行一个线程,可以有多个线程并行运行,如果进程的数目多于处理器的数目,调度器依然采用时间片机制。
阻塞状态:正在执行的线程由于某些原因暂停程序的执行,放弃处理机处于暂停状态。比如调用sleep或者wait方法后,程序就处于阻塞状态了,处于阻塞状态的线程需要唤醒,唤醒后的线程并不会立即运行,需要再经历就绪状态然后获得CPU后执行。
死亡:线程的run方法执行完毕,者线程在执行过程中发生了异常或者错误或者调用了stop()方法,线程就处于死亡状态。
上下文切换
对于单核CPU来说(对于多核CPU,此处就理解为一个核),CPU在一个时刻只能运行一个线程,当在运行一个线程的过程中转去运行另外一个线程,这个叫做线程上下文切换(对于进程也是类似)。
如果当前线程的任务没有执行完毕而将当前线程切出,将另外的线程切入,此时需要保存切出线程的运行时状态信息,以便下次能够再次切入的时候能继续执行上次运行到的地方。
那么需要保存哪些数据呢?因为下次恢复时需要知道在这之前当前线程已经执行到哪条指令了,所以需要记录程序计数器的值,另外比如说线程正在进行某个计算的时候被挂起了,那么下次继续执行的时候需要知道之前挂起时变量的值时多少,因此需要记录CPU寄存器的状态。所以一般来说,线程上下文切换过程中会记录程序计数器、CPU寄存器状态等数据。
线程的上下文切换实际上就是存储和恢复CPU状态的过程,它使得线程执行能够从中断点恢复执行。
中断线程
1、interrupt(),中断这个线程,如果这个线程因调用wait、join、sleep方法而阻塞,在调用该中断方法后会抛出InterruptedException,并且会清除中断状态(具体表现就是调用isInterrupted结果为true),其实这是Java提供了一种委婉的方式用来中断线程,停止线程运行的一种方式。
如果线程在等待锁,对线程对象调用interrupt()只是会设置线程的中断标志位,并不会阻止线程继续等待锁,线程依然会处于BLOCKED状态,也就是说,interrupt()并不能使一个在等待锁的线程真正”中断”。
public void interrupt()
2、interrupted()方法,静态方法,判断当前线程,是否被中断。并且会清除中断状态,连续的两次调用将会返回false,除非当第一次调用后又一次被中断。
public static boolean interrupted() {
return currentThread().isInterrupted(true);//当前线程
}
3、isInterrupted()方法,判断此线程是否被中断,不会清除中断状态。
public boolean isInterrupted() {
return isInterrupted(false);
}
清除中断状态或者重置中断状态位表现就是当调用中断判断函数判断当前线程是否是中断的时候,会返回false表示当前线程没有被中断。
示例:
public static void main(String[] args) {
Thread.currentThread().interrupt();// 中断main-thread
System.out.println(Thread.currentThread().isInterrupted());//true
//第二次调用isInterrupted()结果为true,说明该方法不会清除中断状态位
System.out.println(Thread.currentThread().isInterrupted());//true
}
interrupt()方法会中断线程但不会停止线程的运行,如果遇到InterruptedException异常,则会重置中断状态位。看如下示例:
class ThreadA extends Thread{
@Override
public void run() {
while (true) {
try {
System.out.println("interrupted:" + Thread.currentThread().isInterrupted() + " ThreadA run..."); //[2]
// Thread.sleep(3000); //[3]
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public class ThreadTest {
public static void main(String[] args) {
ThreadA threadA = new ThreadA();
threadA.start();
threadA.interrupt();//[1]
}
}
当在[1]处调用中断函数使线程中断后,[2]处输出结果为true并且线程还在继续运行。
如果放开[3]处的注释语句,当再次运行程序时,刚开始输出为true,但是因为Thread.sleep()会阻塞线程,当调用中断函数时就会抛出异常并且重置中断状态位。
interrupted:true ThreadA run...
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at cn.wjx.corejava1.thread.ThreadA.run(ThreadTest.java:19)
interrupted:false ThreadA run...
interrupted:false ThreadA run...
....false...
interrupted()方法的应用,interrupted判断的是当前线程是否被中断。
ThreadA threadA = new ThreadA();
threadA.start();
threadA.interrupt();
// interrupted判断的是当前线程,对于threadA.interrupted()
// 来说是main线程运行了这一句,所以说判断的是main线程的中断状态位
System.out.println(threadA.interrupted()); //false
// 第一次执行,线程没有执行任何中断操作,返回结果为false
System.out.println(Thread.interrupted());
Thread.currentThread().interrupt();
// 中断main-thread之后执行,返回结果为true,因为中断了main线程
System.out.println(Thread.interrupted());//true
// 因为Thread.interrupted()执行后会清除状态位,所以说
// 第三次执行结果为false
System.out.println(Thread.interrupted());//false
线程安全问题
线程安全问题产生的原因
单线程操作任何时候都是这一个线程对数据资源操作,可以说数据的变化都是与该线程相关,所以不会出现线程安全问题。但是在多线程编程中,两个或两个以上的线程对共享数据的存取,因为线程的随机性,CPU的时间片轮转,抢占式调度算法来获得CPU的执行,可能会导致对共享数据的操作错误等问题。比如成员属性、共享变量、文件、数据库表等,由于每个线程执行的过程是不可控的,所以可能会导致数据可能和自己所预期的不一样或者直接导致程序出错。
这里面所操作的数据资源就被称为临界资源(共享资源)。
1.哪些是共享变量
在java程序中所有实例域,静态域和数组元素都是放在堆内存中(所有线程均可访问到,是可以共享的),而局部变量,方法定义参数和异常处理器参数不会在线程间共享。共享数据会出现线程安全的问题,而非共享数据不会出现线程安全的问题。关于JVM运行时内存区域在后面的文章会讲到。
所以说当多个线程同时访问临界资源是,就可能产生线程安全问题。
当多个线程执行一个方法,方法内部的局部变量并不是临界资源,因为方法是在栈上执行的,而Java栈是线程私有的,因此不会产生线程安全问题。
为了避免多线程引起的对共享数据的讹误,线程的操作必须同步存取。
示例代码:
public class UnsynchBankTest {
//账户数目
public static final int NACCOUNTS = 100;
//初始金额
public static final double INITIAL_BALANCE = 1000;
//最大转出金额
public static final double MAX_AMOUNT = 1000;
public static final int DELAY = 10;
public static void main(String[] args) {
Bank bank = new Bank(NACCOUNTS, INITIAL_BALANCE);
for (int i = 0; i < NACCOUNTS; i++) {
int fromAccount = i;
Runnable r = () -> {
try {
Thread.sleep((int) (DELAY * Math.random()));
while (true) {
int toAccount = (int) (bank.size() * Math.random());
double amount = MAX_AMOUNT * Math.random();
bank.transfer(fromAccount, toAccount, amount);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
};
Thread t = new Thread(r);
t.start();
}
}
}
class Bank {
private final double[] accounts;
public Bank(int n, double initialBalance) {
accounts = new double[n];
Arrays.fill(accounts, initialBalance);
}
/**
* 转账操作
*
* @param from 转出账户
* @param to 转入账户
* @param amount 转账金额
*/
public void transfer(int from, int to, double amount) {
if (accounts[from] < amount)
return;
System.out.println(Thread.currentThread());
accounts[from] -= amount;
System.out.printf("%10.2f from %d to %d", amount, from, to);
accounts[to] += amount;
System.out.printf("Total Balance %10.2f%n", getTotalBalance());
}
public double getTotalBalance() {
double sum = 0;
for (double m : accounts)
sum += m;
return sum;
}
public int size() {
return accounts.length;
}
}
上面多个线程对同一个bank对象内的共享数据进行了存取操作,我们不清楚在某一时刻某一银行账户中有多少钱。但是,所有账户的总金额应该保持不变或者银行下的总金额不变,因为存取不过就是从一个账户转移钱款到另一个账户。
程序的输出:
...
Thread[Thread-76,5,main]
74.44 from 76 to 25Total Balance 100000.00
Thread[Thread-76,5,main]
8.14 from 76 to 6Total Balance 100000.00
Thread[Thread-76,5,main]
3.71 from 76 to 6Total Balance 100000.00
Thread[Thread-76,5,main]
6.38 from 76 to 90Total Balance 100000.00
Thread[Thread-83,5,main]
Thread[Thread-76,5,main]
0.20 from 76 to 87Total Balance 99181.24
Thread[Thread-98,5,main]
28.25 from 98 to 62Total Balance 99181.24
...
不难发现,刚开始银行总金额不变,但是一会,银行里面的钱可能不翼而飞,发什么了变化,这在银行中是绝对不允许的。
当两个线程试图更新同一个账户,两个线程同时执行指令accounts[to] += amount,问题在于这不是原子操作,该指令可能会被处理如下:
(1) 将accounts[to]加载到寄存器
(2) 增加amount
(3) 将结果写会accounts[to]
当一个线程在执行上述三个中的任意一个子操作时,都有可能在运行时被其他线程剥夺CPU的运行权,导致其他线程对数据做了操作(存、取)后,当这个线程再次运行时,数据的状态已经不在是这个线程一开始执行时的那种状态,但是线程并不知道数据的变化,最终会导致数据不一致,导致金额错误。
我们反编译代码来看一下:
account[from] -= amount;
反编译:
ALOAD 0
GETFIELD cn/wjx/corejava1/thread/Bank.accounts : [D
ILOAD 1 [load]
DUP2
DALOAD
DLOAD 3
DSUB [-]
DASTORE [store]
account[to] += amount;
ALOAD 0 [load]
GETFIELD cn/wjx/corejava1/thread/Bank.accounts : [D
ILOAD 2
DUP2
DALOAD
DLOAD 3
DADD [+]
DASTORE [store]
可以看出,账户存入和支出是由多个指令构成的,执行它们的线程可以在任何一条指令点上被中断。下面时序图展示了这一情况:
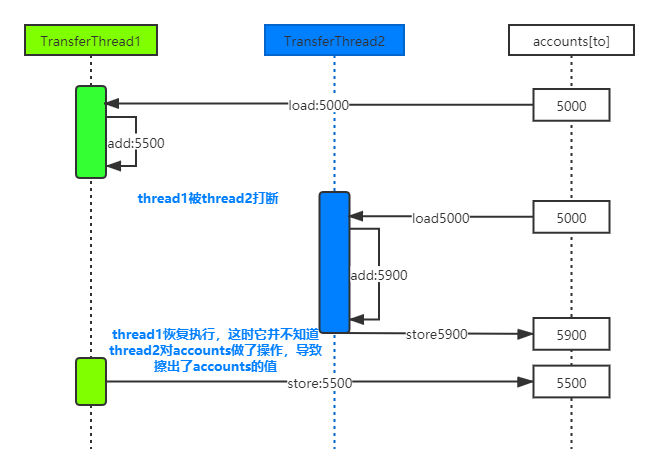
如何解决线程安全
基本上所有的并发模式在解决线程安全问题时,都采用序列化访问临界资源的方案,即在同一时刻,只能有一个线程访问临界资源,也称作同步互斥访问。
通常来说,当一个线程在访问临界资源时,在访问临界资源的代码前面加上一个锁,其他线程就不能访问加锁后的临界资源,只有当访问完临界资源释放锁后,其他线程才可以继续访问。通过锁来解决线程安全问题,实现对资源的互斥访问。
锁是一种抽象的概念,代码层面是如何实现的呢?
在Java中,每个对象都有一个锁(锁标记),存在于对象头中。关于对象结构,会在下文介绍。结合synchronized从而实现对一个临界资源的加锁解锁。
Java语言中提供了两种方式来实现同步互斥访问:synchronized和Lock。
synchronized
在Java中,可以使用synchronized关键字对方法或者代码块进行加锁,当某个线程调用该对象的synchronized方法或者访问synchronized代码块时,这个线程便获得了该对象的锁,其他线程暂时无法访问这个方法,只有等待这个方法执行完毕或者代码块执行完毕,这个线程才会释放该对象的锁,其他线程才能执行这个方法或者代码块。
synchronized方法或者代码块执行的条件,必须获得对象锁
synchronized使用场景:
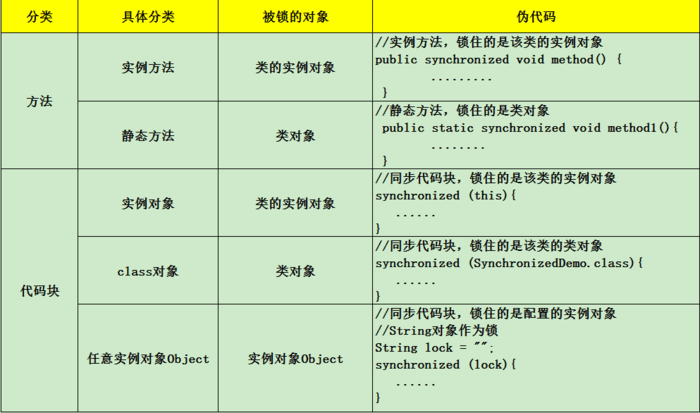
synchronized注意点
1)当一个线程正在访问一个对象的synchronized方法,那么其他线程不能访问该对象的其他synchronized方法。同一个对象锁只能被一个线程所持有。
2)当一个线程正在访问一个对象的synchronized方法,其他线程能访问该对象的synchronized方法。访问非synchronized方法不需要获得该对象的锁。
3)如果一个线程A需要访问对象object1的synchronized方法fun1,另外一个线程B需要访问对象object2的synchronized方法fun1,即使object1和object2是同一类型,也不会产生线程安全问题,因为他们持有的锁对象不是同一个,所以不存在互斥问题。
4)synchronized代码块使用起来比synchronized方法更加灵活,因为一个方法可能只有一部分代码需要同步,如果加方法锁的话,会影响效率。
底层原理
synchronized总是依赖于对象,在Java中,每个对象都有一个锁标记(monitor),也称为监视器或者管程,多线程同时访问某个对象时,线程只有获取了该对象的锁才能访问。synchronized就是依赖于这个监视器来实现资源的同步访问的。
我们通过反编译一个实例来查看:
public class ThreadTest {
public static void main(String[] args) {
int i = 0;
synchronized (ThreadTest.class) {
i++;
}
}
}
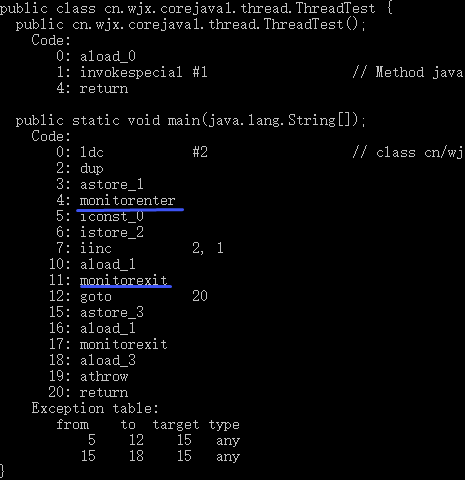
synchronized代码块出现了两个特殊指令monitorenter和monitorexit,monitorenter指令执行时会让对象的锁计数加1,此时其他线程只能等待,而monitorexit指令执行时会让对象的锁计数减1,当锁计数为0时,其他线程才可以获得对象锁。其实这个与操作系统里面的PV操作很像,操作系统里面的PV操作就是用来控制多个线程对临界资源的访问。
monitor
Java对象的monitor保证了临界资源的互斥访问,那么这个monitor对象是个什么东东呢?
前面提到,monitor被叫做一个监视器或者是一个管程。就拿监视器这个含义来说,监视器主要是用来监视某种资源,转到Java多线程并发的含义就是用来管理多个线程互斥访问临界资源,保证每一个时刻只能有一个线程进入临界区。
无论是ACC_SYNCHRONIZED还是monitorenter、monitorexit都是基于Monitor实现的,在Java虚拟机(HotSpot)中,Monitor是基于C++实现的,由ObjectMonitor实现。主要的数据结构如下:
ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL;
_WaitSet = NULL;
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ;
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
关键属性:
_owner:指向持有ObjectMonitor对象的线程
_WaitSet:存放处于wait状态的线程队列
_EntryList:存放处于等待锁block状态的线程队列
_recursions:锁的重入次数
_count:用来记录该线程获取锁的次数
当多个线程同时访问一段同步代码时,首先会进入 _EntryList 队列中,当某个线程获取到对象的 monitor 后进入 _Owner 区域并把 monitor 中的_owner 变量设置为当前线程,同时monitor中的计数器 _count 加1,即获得对象锁。
若持有monitor的线程调用 wait() 方法,将释放当前持有的monitor, _owner 变量恢复为 null, _count减1,同时该线程进入 _WaitSet 集合中等待被唤醒。若当前线程执行完毕也将释放monitor(锁)并复位变量的值,以便其他线程进入获取monitor(锁)。如下图:
对于synchronized方法,执行中的线程识别该方法的 method_info 结构是否有ACC_SYNCHRONIZED标记设置,然后它自动获取对象的锁,调用方法,最后释放锁。如果有异常发生,线程自动释放锁。
总结
方法级的同步是隐式的。同步方法的常量池中会有一个
ACC_SYNCHRONIZED标志。当某个线程要访问某个方法的时候,会检查是否有ACC_SYNCHRONIZED,如果有设置,则需要先获得监视器锁,然后开始执行方法,方法执行之后再释放监视器锁。这时如果其他线程来请求执行方法,会因为无法获得监视器锁而被阻断住。值得注意的是,如果在方法执行过程中,发生了异常,并且方法内部并没有处理该异常,那么在异常被抛到方法外面之前监视器锁会被自动释放。同步代码块使用
monitorenter和monitorexit两个指令实现。可以把执行monitorenter指令理解为加锁,执行monitorexit理解为释放锁。 每个对象维护着一个记录着被锁次数的计数器。未被锁定的对象的该计数器为0,当一个线程获得锁(执行monitorenter)后,该计数器自增变为 1 ,当同一个线程再次获得该对象的锁的时候,计数器再次自增。当同一个线程释放锁(执行monitorexit指令)的时候,计数器再自减。当计数器为0的时候。锁将被释放,其他线程便可以获得锁。每个对象自身维护这一个被加锁次数的计数器,当计数器数字为0时表示可以被任意线程获得锁。当计数器不为0时,只有获得锁的线程才能再次获得锁。即可重入锁。
参考
对于对象锁来说,synchronized通过Monitor来实现线程同步,Monitor是依赖于底层的操作系统的Mutex Lock(互斥锁)来实现的线程同步。。这就会涉及到核态的转化。
Java线程实际上是对操作系统线程的映射,每个线程的挂起和切换,都会涉及到内核态与用户态的切换,而状态的切换是十分耗时且耗费资源的。
如同我们在自旋锁中提到的“阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长”。这种方式就是synchronized最初实现同步的方式,这就是JDK 6之前synchronized效率低的原因。这种依赖于操作系统Mutex Lock所实现的锁我们称之为“重量级锁”,JDK 6中为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”。
所以目前锁一共有4种状态,级别从低到高依次是:无锁、偏向锁、轻量级锁和重量级锁。锁状态只能升级不能降级。
锁标记是存在于对象头中的Markword中,理解这些锁状态的切换,就不得不对Java中的对象结构有所了解。
对象结构
Java对象结构由对象头、实例数据、对齐填充组成。
1、对象头
HotSpot虚拟机的对象头(Object Header)包括两部分信息:MarkWord和类型指针。
MarkWord:用于存储对象自身的运行时数据和锁标志, 如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,这部分数据的长度在32位和64位的虚拟机(暂 不考虑开启压缩指针的场景)中分别为32个和64个Bits。
类型指针:即对象指向它的类的元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。并不是所有的虚拟机实现都必须在对象数据上保留类型指针,换句话说查找对象的元数据信息并不一定要经过对象本身。另外,如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中无法确定数组的大小。
Mark Word被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。Mark Word在不同的锁状态下存储的内容不同,在32位JVM中是这么存的:
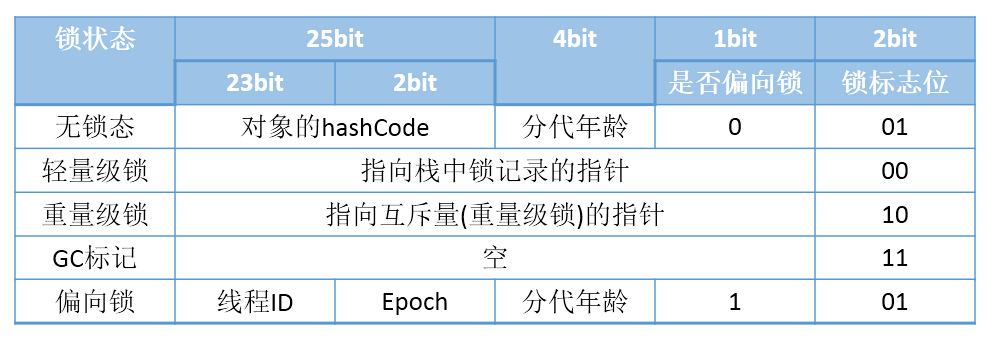
2、实例数据
实例数据保存对象中的属性和方法等信息。
3、对齐填充
由于HotSpot JVM要求对象的大小必须是8字节的整数倍,而对象头部分正好是8字节的倍数(1倍或者2倍),所以为了满足对象的大小是8字节的整数倍,需要对其进行一定字节的填充。它并没有什么特别含义,仅仅起着占位符的作用。
Java虚拟机的锁优化
🔖 🆕
Lock
synchronized缺陷
如果一个代码块被synchronized修饰了,当一个线程获取了对应的锁,并执行该代码块时,其他线程便只能一直等待,等待获取锁的线程释放锁,而这里获取锁的线程释放锁只会有两种情况:
1)获取锁的线程执行完了该代码块,然后线程释放对锁的占有;
2)线程执行发生异常,此时JVM会让线程自动释放锁。
那么如果这个获取锁的线程由于要等待IO或者其他原因(比如调用sleep方法)被阻塞了,但是又没有释放锁,其他线程便只能干巴巴地等待,试想一下,这多么影响程序执行效率。
因此就需要有一种机制可以不让等待的线程无期限地等待下去(比如只等待一定的时间或者能够响应中断),通过Lock就可以办到。
Lock比synchronized关键字提供了更多的功能,但是需要注意:
1)Lock不是Java语言内置的,它是一个类,通过这个类可以实现同步访问,synchronized是Java语言的关键字,是内置特性。
2)Lock和synchronized有一点非常大的不同,采用synchronized不需要用户去手动释放锁,当synchronized方法或者synchronized代码块执行完之后,系统会自动让线程释放对锁的占用;而Lock则必须要用户去手动释放锁,如果没有主动释放锁,就有可能导致出现死锁现象。
locks包下常用类
lock接口
Lock是一个接口,其中lock()、tryLock()、tryLock(long time, TimeUnit unit)和lockInterruptibly()是用来获取锁的。unLock()方法是用来释放锁的,newCondition是与协程相关的,这里不做讲解。
public interface Lock {
/**
*lock is not available then the current thread becomes disabled for thread scheduling *purposes and lies dormant until the lock has been acquired.
*如果锁不可以用,当前线程由于调度的目的将会被禁用和休眠直到锁被获取
*/
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
lock():Lock接口中的常用方法,对代码块进行加锁,未获得锁的线程只能等待。
在前面讲到如果采用Lock,必须主动去释放锁,并且在发生异常时,不会自动释放锁。因此一般来说,使用Lock必须在try{}catch{}块中进行,并且将释放锁的操作放在finally块中进行,以保证锁一定被被释放,防止死锁的发生。
使用Lock锁同步线程的方式如下,
Lock lock = ...;
lock.lock();
try{
//处理任务
}catch(Exception ex){
}finally{
lock.unlock(); //释放锁
}
tryLock()方法是有返回值的,它表示用来尝试获取锁,如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返回false,方法调用会立即得到一个返回值,而不是在那无休止的等待获取锁。
tryLock(long time, TimeUnit unit)方法和tryLock()方法是类似的,区别在于这个方法在拿不到锁时会等待一定的时间,在时间期限之内如果还拿不到锁,就返回false。如果如果一开始拿到锁或者在等待期间内拿到了锁,则返回true。
所以,一般情况下通过tryLock来获取锁时是这样使用的:
Lock lock = ...;
if(lock.tryLock()) {
try{
//处理任务
}catch(Exception ex){
}finally{
lock.unlock(); //释放锁
}
}else {
//如果不能获取锁,则直接做其他事情
}
lockInterruptibly():当通过这个方法去获取锁时,如果线程正在等待获取锁,则这个线程能够响应中断,即中断线程的等待状态。也就使说,当两个线程同时通过lock.lockInterruptibly()想获取某个锁时,假若此时线程A获取到了锁,而线程B只有在等待,那么对线程B调用threadB.interrupt()方法能够中断线程B的等待过程。其实还是通过抛出异常的形式来中断线程的执行。
因为lockInterruptibly()通过抛出异常的形式来中断线程,如果异常被内部捕获,那么最终会走unlock释放锁,对于一个没有获取锁的线程来说去调用释放锁的方法,会抛出IllegalMonitorStateException。所以必须将异常抛出而不是被捕获在内部处理。
使用形式如下:
public void method() throws InterruptedException {
lock.lockInterruptibly();
try {
//.....
}
finally {
lock.unlock();
}
}
当线程调用Thread.interrupt()方法时,lockInterruptibly和synchronized方法响应中断的表现形式是不同的:
当通过lockInterruptibly()方法获取某个锁时,如果不能获取到,只有进行等待的情况下,是可以响应中断的。
synchronized修饰的话,当一个线程处于等待某个锁的状态,是无法被中断的,只有一直等待下去。
ReadWriteLock
public interface ReadWriteLock {
/**
* Returns the lock used for reading.
*
* @return the lock used for reading
*/
Lock readLock();
/**
* Returns the lock used for writing.
*
* @return the lock used for writing
*/
Lock writeLock();
}
读写锁接口,该接口提供了一对锁,能够支持并发读互斥写,在并发读方面,相比synchronized方法,该接口下的readLock()方法更有优势。
示例:使用ReentrantReadWriteLock实现同时读。
public class ThreadTest{
private ReentrantReadWriteLock rw = new ReentrantReadWriteLock();
private void fun(Thread thread) {
rw.readLock().lock();
try {
long start = System.currentTimeMillis();
while(System.currentTimeMillis() - start <= 1) {
System.out.println(thread.getName()+"正在进行读操作");
}
System.out.println(thread.getName()+"读操作完毕");
} finally {
rw.readLock().unlock();
}
}
public static void main(String[] args) throws InterruptedException {
ThreadTest t = new ThreadTest();
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
t.fun(Thread.currentThread());
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
t.fun(Thread.currentThread());
}
});
t1.start();
t2.start();
}
}
Lock和synchronized的选择
总结来说,Lock和synchronized有以下几点不同:
1)Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现;
2)synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用unlock时需要在finally块中释放锁;
3)Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断;
4)通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。
5)Lock可以提高多个线程进行读操作的效率。
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
锁相关概念
1.可重入锁
如果锁具备可重入性,则称作为可重入锁。像synchronized和ReentrantLock都是可重入锁,可重入性在我看来实际上表明了锁的分配机制:基于线程的分配,而不是基于方法调用的分配。举个简单的例子,当一个线程执行到某个synchronized方法时,比如说method1,而在method1中会调用另外一个synchronized方法method2,此时线程不必重新去申请锁,而是可以直接执行方法method2。
看下面这段代码就明白了:
class MyClass {
public synchronized void method1() {
method2();
}
public synchronized void method2() {
}
}
上述代码中的两个方法method1和method2都用synchronized修饰了,假如某一时刻,线程A执行到了method1,此时线程A获取了这个对象的锁,而由于method2也是synchronized方法,假如synchronized不具备可重入性,此时线程A需要重新申请锁。但是这就会造成一个问题,因为线程A已经持有了该对象的锁,而又在申请获取该对象的锁,这样就会线程A一直等待永远不会获取到的锁,死锁。
2.可中断锁
可中断锁:顾名思义,就是可以相应中断的锁。
在Java中,synchronized就不是可中断锁,而Lock是可中断锁。
如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。
3.公平锁
公平锁即尽量以请求锁的顺序来获取锁。比如同是有多个线程在等待一个锁,当这个锁被释放时,等待时间最久的线程(最先请求的线程)会获得该所,这种就是公平锁。
非公平锁即无法保证锁的获取是按照请求锁的顺序进行的。这样就可能导致某个或者一些线程永远获取不到锁。
在Java中,synchronized就是非公平锁,它无法保证等待的线程获取锁的顺序。
而对于ReentrantLock和ReentrantReadWriteLock,它默认情况下是非公平锁,但是可以设置为公平锁。
相关术语
程序进程线程
关于更多进程和线程的知识,最好看下计算机操作系统,里面从单处理系统到批处理,到为什么出现进程有很详细的介绍。
程序:用某种编程语言(java、c等)编写,能够完成一定任务或者功能的代码集合,是指令和数据的有序集合,是一段静态代码。
进程:应用程序获得内存中的空间,执行程序的过程,简单的说,一个进程就是一个在内存中执行的程序。执行中各个进程之间互不干扰。同时进程保存着程序每一个时刻运行的状态。每一个进程执行都有一个执行顺序,该顺序是一个执行单元或者叫一个控制单元。
线程: 是进程中的一个独立控制单元,控制着进程的执行,比进程更小的执行单位。一个进程中至少有一个线程,线程之间数据共享(共享同一块内存空间和系统资源)。
多线程:一个程序(进程)运行时产生了不止一个线程。
并发与并行
并发指的是多个任务交替进行,而并行则是指真正意义上的“同时进行”。实际上,如果系统内只有一个CPU,而使用多线程时,那么真实系统环境下不能并行,只能通过切换时间片的方式交替进行,而成为并发执行任务。真正的并行也只能出现在拥有多个CPU的系统中。
并发执行和并行执行的区别?
并行执行真正意义上的同时执行,并发执行指的是重叠时间段内的执行。下图就很好的解释了这两者
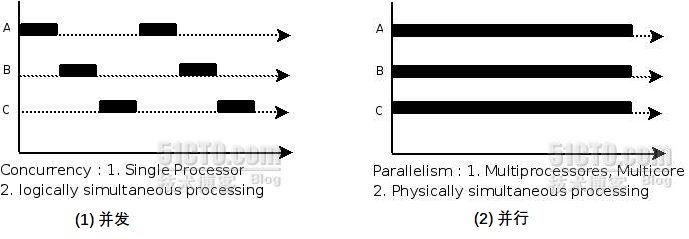
“并行”概念是“并发”概念的一个子集。也就是说,你可以编写一个拥有多个线程或者进程的并发程序,但如果没有多核处理器来执行这个程序,那么就不能以并行方式来运行代码。并行是并发的一种实现方案,另一种实现方案是协程。—知乎
Different concurrent designs enable different ways to parallelize.
并发设计让并发执行成为可能,而并行是并发执行的一种模式。
上下文切换
上下文切换:上下文切换(有时也称做进程切换或任务切换)是指 CPU 从一个进程(或线程)切换到另一个进程(或线程)。上下文是指某一时间点 CPU 寄存器和程序计数器的内容。
寄存器是cpu内部的少量的速度很快的闪存,通常存储和访问计算过程的中间值提高计算机程序的运行速度。
程序计数器是一个专用的寄存器,用于表明指令序列中 CPU 正在执行的位置,存的值为正在执行的指令的位置或者下一个将要被执行的指令的位置,具体实现依赖于特定的系统。
举例说明 线程A - B
1.先挂起线程A,将其在cpu中的状态保存在内存中。
2.在内存中检索下一个线程B的上下文并将其在 CPU 的寄存器中恢复,执行B线程。
3.当B执行完,根据程序计数器中指向的位置恢复线程A。
CPU通过为每个线程分配CPU时间片来实现多线程机制。CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后会切换到下一个任务。
但是,在切换前会保存上一个任务的状态,以便下次切换回这个任务时,可以再加载这个任务的状态。所以任务从保存到再加载的过程就是一次上下文切换。
上下文切换通常是计算密集型的,意味着此操作会消耗大量的 CPU 时间,故线程也不是越多越好。如何减少系统中上下文切换次数,是提升多线程性能的一个重点课题。
临界区
临界区用来表示一种公共资源或者说是共享数据,可以被多个线程同时访问,但是每个线程访问时,临界资源被该线程锁占有,其他线程只能等待。
同步互斥
引入同步互斥机制的原因?
现在的操作系统都是多任务操作系统,系统内存在着大量的任务运行实体,当多任务实体运行时可能会发生:
- 多任务(多线程)同时访问或者使用同一种资源
- 某个任务依赖于另一个任务的运行结果,多个任务之间存在依赖关系。
同步:是指散步在不同任务之间的若干程序片断,它们的运行必须严格按照规定的某种先后次序来运行,这种先后次序依赖于要完成的特定的任务。
异步:任务之间的运行次序并没有严格的要求。比如说网络异步请求、非阻塞式IO、函数的回调都侧面展示了异步的使用。相对于同步,异步对它做了进一步的优化,减少了等待。
互斥:是指散步在不同任务之间的若干程序片断,当某个任务运行其中一个程序片段时,其它任务就不能运行它们之中的任一程序片段,只能等到该任务运行完这个程序片段后才可以运行。
同步是一种更为复杂的互斥,而互斥是一种特殊的同步。互斥是两个任务之间不可以同时运行,他们会相互排斥,必须等待一个线程运行完毕,另一个才能运行,间接地看是一种没有顺序的同步,而同步也是不能同时运行,但他是必须要安照某种次序来运行相应的线程(也是一种互斥)!因此互斥具有唯一性和排它性,但互斥并不限制任务的运行顺序,即任务是无序的,而同步的任务之间则有顺序关系。
8.3 线程组和线程优先级
8.3.1 线程组(ThreadGroup)
Java中用ThreadGroup来表示线程组,我们可以使用线程组对线程进行批量控制。每个Thread必然存在于一个ThreadGroup中,Thread不能独立于ThreadGroup存在。执行main()方法线程的名字是main,如果在new Thread时没有显式指定,那么默认将父线程(当前执行new Thread的线程)线程组设置为自己的线程组。
示例代码:
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread testThread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("testThread当前线程组名字:" + Thread.currentThread().getThreadGroup().getName());
System.out.println("testThread当前线程名字:" + Thread.currentThread().getName());
new Thread(()->{
System.out.println(Thread.currentThread().getThreadGroup().getName());
System.out.println(Thread.currentThread().getName());
}).start();
}
});
testThread.start();
System.out.println("执行main方法线程名字:" + Thread.currentThread().getName());
}
/* 输出
* 执行main方法线程名字:main
* testThread当前线程组名字:main
* testThread当前线程名字:Thread-0
* main
* Thread-1
*/
ThreadGroup管理着它下面的Thread,ThreadGroup是一个标准的向下引用的树状结构,这样设计的原因是防止"上级"线程被"下级"线程引用而无法有效地被GC回收。
8.3.2 线程的优先级
/**
* The minimum priority that a thread can have.
*/
public final static int MIN_PRIORITY = 1;
/**
* The default priority that is assigned to a thread.
*/
public final static int NORM_PRIORITY = 5;
/**
* The maximum priority that a thread can have.
*/
public final static int MAX_PRIORITY = 10;
Java中线程优先级可以指定,范围是1~10。但是并不是所有的操作系统都支持10级优先级的划分(比如有些操作系统只支持3级划分:低,中,高),Java只是给操作系统一个优先级的参考值,线程最终在操作系统的优先级是多少还是由操作系统决定。
Java默认的线程优先级为5,线程的执行顺序由调度程序来决定,线程的优先级会在线程被调用之前设定。
高优先级的线程将会比低优先级的线程有更高的几率得到执行。可以使用方法Thread类的setPriority()实例方法来设定线程的优先级,看下源码
public final void setPriority(int newPriority) {
ThreadGroup g;
checkAccess();
// 判断优先级参数是否合法
if (newPriority > MAX_PRIORITY || newPriority < MIN_PRIORITY) {
throw new IllegalArgumentException();
}
// 得到当前线程组的优先级,如果大于线程组的优先级,则设置为线程组的优先级
if((g = getThreadGroup()) != null) {
if (newPriority > g.getMaxPriority()) {
newPriority = g.getMaxPriority();
}
setPriority0(priority = newPriority);
}
}
上面代码一个关键的地方是:所以,如果某个线程优先级大于线程所在线程组的最大优先级,那么该线程的优先级将会失效,取而代之的是线程组的最大优先级。
我是否可以通过改变线程的优先级来控制线程的执行顺序呢?答案是:No!
Java中的优先级来说不是特别的可靠,Java程序中对线程所设置的优先级只是给操作系统一个建议,操作系统不一定会采纳。而真正的调用顺序,是由操作系统的线程调度算法决定的。
我们来验证一下:
public static class T1 extends Thread {
@Override
public void run() {
super.run();
System.out.printf("当前执行的线程是:%s, 优先级:%d\n", Thread.currentThread().getName(), Thread.currentThread().getPriority());
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
IntStream.range(1, 10).forEach(i -> {
Thread thread = new Thread(new T1());
thread.setPriority(i);
thread.start();
});
}
/** 输出
* 当前执行的线程是:Thread-17, 优先级:9
* 当前执行的线程是:Thread-3, 优先级:2
* 当前执行的线程是:Thread-1, 优先级:1
* 当前执行的线程是:Thread-7, 优先级:4
* 当前执行的线程是:Thread-5, 优先级:3
* 当前执行的线程是:Thread-11, 优先级:6
* 当前执行的线程是:Thread-9, 优先级:5
* 当前执行的线程是:Thread-15, 优先级:8
* 当前执行的线程是:Thread-13, 优先级:7
*/
Java提供一个线程调度器来监视和控制处于RUNNABLE状态的线程。线程的调度策略采用抢占式,优先级高的线程比优先级低的线程会有更大的几率优先执行。在优先级相同的情况下,按照“先到先得”的原则。每个Java程序都有一个默认的主线程,就是通过JVM启动的第一个线程main线程。
还有一种线程称为守护线程(Daemon),守护线程默认的优先级比较低。
如果某线程是守护线程,那如果所以的非守护线程结束,这个守护线程也会自动结束。
应用场景是:当所有非守护线程结束时,结束其余的子线程(守护线程)自动关闭,就免去了还要继续关闭子线程的麻烦。
一个线程默认是非守护线程,可以通过Thread类的setDaemon(boolean on)来设置。
8.3.3 线程组的常用方法及数据结构
1、线程组的常用方法
// 获取当前的线程组名字
Thread.currentThread().getThreadGroup().getName;
// 复制一个线程数组到一个线程组
Thread[] thread = new Thread[threadGroup.activeCount()];
ThreadGroup threadGroup = new ThreadGroup();
threadGroup.enumerate(threads);
2、线程组统一异常处理
package com.func.axc.threadgroup;
public class ThreadGroupDemo {
public static void main(String[] args) {
ThreadGroup threadGroup1 = new ThreadGroup("group1") {
// 继承ThreadGroup并重新定义以下方法
// 在线程成员抛出unchecked exception
// 会执行此方法
public void uncaughtException(Thread t, Throwable e) {
System.out.println(t.getName() + ": " + e.getMessage());
}
};
// 这个线程是threadGroup1的一员
Thread thread1 = new Thread(threadGroup1, new Runnable() {
public void run() {
// 抛出unchecked异常
throw new RuntimeException("测试异常");
}
});
thread1.start();
}
}
上面出现了一个定义类对象并重写方法的新形势,threadGroup1并不是抽象类和接口,却可以这样写,这其实就是一个匿名内部类。
3、线程组的数据结构
线程组还可以包含其他的线程组,不仅仅是线程。
首先看下ThreadGroup源码
public class ThreadGroup implements Thread.UncaughtExceptionHandler {
private final ThreadGroup parent; // 父亲ThreadGroup
String name; // ThreadGroupr 的名称
int maxPriority; // 线程最大优先级
boolean destroyed; // 是否被销毁
boolean daemon; // 是否守护线程
boolean vmAllowSuspension; // 是否可以中断
int nUnstartedThreads = 0; // 还未启动的线程
int nthreads; // ThreadGroup中线程数目
Thread threads[]; // ThreadGroup中的线程
int ngroups; // 线程组数目
ThreadGroup groups[]; // 线程组数组
// 私有构造函数
private ThreadGroup() {
this.name = "system";
this.maxPriority = Thread.MAX_PRIORITY;
this.parent = null;
}
// 默认是以当前ThreadGroup传入作为parent ThreadGroup,新线程组的父线程组是目前正在运行线程的线程组。
public ThreadGroup(String name) {
this(Thread.currentThread().getThreadGroup(), name);
}
// 构造函数
public ThreadGroup(ThreadGroup parent, String name) {
this(checkParentAccess(parent), parent, name);
}
// 私有构造函数,主要的构造函数
private ThreadGroup(Void unused, ThreadGroup parent, String name) {
this.name = name;
this.maxPriority = parent.maxPriority;
this.daemon = parent.daemon;
this.vmAllowSuspension = parent.vmAllowSuspension;
this.parent = parent;
parent.add(this);
}
// 检查parent ThreadGroup
private static Void checkParentAccess(ThreadGroup parent) {
parent.checkAccess();
return null;
}
// 判断当前运行的线程是否具有修改线程组的权限
public final void checkAccess() {
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkAccess(this);
}
}
}
这里涉及到
SecurityManager这个类,它是Java的安全管理器,它允许应用程序在执行一个可能不安全或敏感的操作前确定该操作是什么,以及是否是在允许执行该操作的安全上下文中执行它。应用程序可以允许或不允许该操作。比如引入了第三方类库,但是并不能保证它的安全性。
其实Thread类也有一个checkAccess()方法,不过是用来检查当前运行的线程是否有权限修改被调用的这个线程实例。(Determines if the currently running thread has permission to modify this thread.)
总结来说,线程组是一个树状的结构,每个线程组下面可以有多个线程或者线程组。线程组可以起到统一控制线程的优先级和检查线程的权限的作用。
8.4 线程的状态及主要转化方法
8.4.1 操作系统中的线程状态转换
在现在的操作系统中,线程被视为轻量级进程的,所以操作系统线程的状态其实和操作系统进程的状态是一致的。
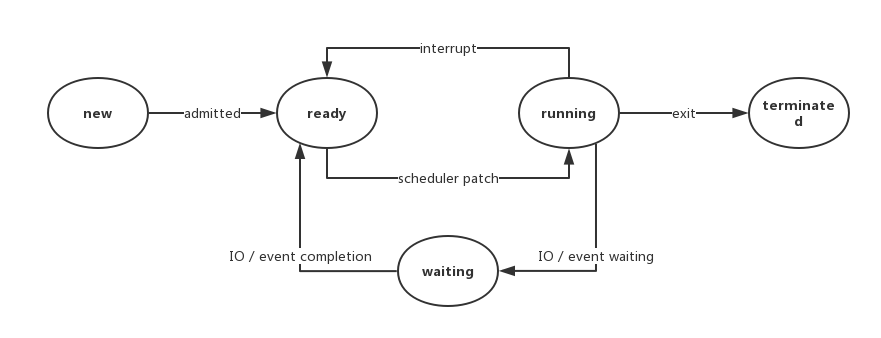
操作系统进程的三种基本状态:
- 就绪状态(ready):当进程已分配到除CPU以外的所有必要资源后,只要再获得CPU,便可立即执行,进程这时的状态就称为就绪状态。在一个系统中处于就绪状态的进程可能有多个,通常将他们排成一个队列,称为就绪队列。
- 执行状态(running):进程已获得CPU,其程序正在执行。在单处理器机器上,只能有一个进程运行;在多处理器机器上,每个处理器运行一个进程,可以有多个进程并行运行,如果进程的数目多于处理器的数目,调度器依然采用时间片机制。
- 阻塞状态(waiting):正在执行的进程由于发生某事件(如I/O、申请缓冲区失败等而)暂时无法继续执行时,便放弃处理机处于暂停状态。亦即程序的执行受到阻塞,把这种暂停状态称为阻塞状态,有时也称为等待状态或封锁状态。
【注】在计算机操作系统书中,进程图如下图:
8.4.2 Java线程的6个状态
// Thread.State 源码
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINALED
}
1、NEW
当用new操作符创建一个新线程时,如new Thread(r),该线程还没有开始运行(未调用start方法),这意味着它的状态是new。
Thread thread = new Thread(() -> {
});
System.out.println(thread.getState());//NEW
thread.start();
System.out.println(thread.getState());//RUNNABLE
前面曾经提到过,一个线程不同反复调用start()方法,这里解释下为什么?
首先看一下start源码
/**
* Causes this thread to begin execution; the Java Virtual Machine
* calls the <code>run</code> method of this thread.
* JVM调用这个线程的run方法
* <p>
* The result is that two threads are running concurrently: the
* current thread (which returns from the call to the
* <code>start</code> method) and the other thread (which executes its
* <code>run</code> method).
* <p>
* 方法的调用结果是调用start方法的线程和run线程同时运行
* It is never legal to start a thread more than once.
* In particular, a thread may not be restarted once it has completed
* execution.
* 一个线程调用多次start方法是从不合法的
*/
public synchronized void start() {
/**
* This method is not invoked for the main method thread or "system"
* group threads created/set up by the VM. Any new functionality added
* to this method in the future may have to also be added to the VM.
*
* A zero status value corresponds to state "NEW".
*/
if (threadStatus != 0)
throw new IllegalThreadStateException();
/* Notify the group that this thread is about to be started
* so that it can be added to the group's list of threads
* and the group's unstarted count can be decremented. */
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}
在start()内部,这里有一个threadStatus的变量。如果它不等于0,调用start()是会直接抛出异常的。
我们接着往下看,有一个native的start0()方法。这个方法里并没有对threadStatus的处理。到了这里我们仿佛就拿这个threadStatus没辙了,我们通过debug的方式再看一下:
Thread.currentThread().start();//Main线程再次尝试start()方法
// 进入start方法,通过打断点可以看到threadStatus值为5
查看当前线程状态的源码:
// Thread.getState方法源码:
public State getState() {
// get current thread state
return sun.misc.VM.toThreadState(threadStatus);
}
// sun.misc.VM 源码:
public static State toThreadState(int var0) {
if ((var0 & 4) != 0) {
return State.RUNNABLE;
} else if ((var0 & 1024) != 0) {
return State.BLOCKED;
} else if ((var0 & 16) != 0) {
return State.WAITING;
} else if ((var0 & 32) != 0) {
return State.TIMED_WAITING;
} else if ((var0 & 2) != 0) {
return State.TERMINATED;
} else {
return (var0 & 1) == 0 ? State.NEW : State.RUNNABLE;
}
}
所以,我们结合上面的源码可以得到引申的两个问题的结果:
两个问题的答案都是不可行,在调用一次start()之后,threadStatus的值会改变(threadStatus !=0),此时再次调用start()方法会抛出IllegalThreadStateException异常。
比如,threadStatus为2代表当前线程状态为TERMINATED。
2、RUNNABLE
/**
* Thread state for a runnable thread. A thread in the runnable
* state is executing in the Java virtual machine but it may
* be waiting for other resources from the operating system
* such as processor.
*/
RUNNABLE,
可运行状态。一旦线程调用start方法,线程处于runnable状态。处于RUNNABLE状态的线程可能正在运行,也有可能在等待其他系统资源(比如I/O)。这就是为什么这个状态称为可运行而不是运行。
Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“可运行状态”。线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。
3、BLOCKED
阻塞状态。当一个线程试图获取一个内部的对象锁,而该锁被其他线程持有,则该线程进入阻塞状态。处于BLOCKED状态的线程正等待锁的释放以进入同步区。阻塞状态是线程阻塞在进入synchronized关键字修饰的方法或代码块(获取锁)时的状态。
4、WAITING
等待状态。可以用操作系统中进程的等待状态来定义,即正在运行中的线程由于某事件而不能继续执行,放弃CPU,处于等待,处于等待状态的线程必须由其他线程所唤醒,否则一直等待下去。
调用如下3个方法会使线程进入等待状态:
- Object.wait():使当前线程处于等待状态直到另一个线程唤醒它;
- Thread.join():等待线程执行完毕,底层调用的是Object实例的wait方法;
- LockSupport.park():除非获得调用许可,否则禁用当前线程进行线程调度。
5、TIMED_WAITING
超时等待状态。线程等待一个具体的时间,时间到后会被自动唤醒。
调用如下方法会使线程进入超时等待状态:
- Thread.sleep(long millis):使当前线程睡眠指定时间;
- Object.wait(long timeout):线程休眠指定时间,等待期间可以通过notify()/notifyAll()唤醒;
- Thread.join(long millis):等待当前线程最多执行millis毫秒,如果millis为0,则会一直执行;
- LockSupport.parkNanos(long nanos): 除非获得调用许可,否则禁用当前线程进行线程调度指定时间;
- LockSupport.parkUntil(long deadline):同上,也是禁止线程进行调度指定时间;
6、TERMINATED
终止状态。此时线程已执行完毕。
8.4.3 线程状态转化
线程状态转化图:
1、BLOCKED与RUNNABLE状态的转换
处于BLOCKED状态的线程是因为在等待锁的释放。假如这里有两个线程a和b,a线程提前获得了锁并且暂未释放锁,此时b就处于BLOCKED状态。我们先来看一个例子:
@Test
public void blockedTest() {
Thread a = new Thread(new Runnable() {
@Override
public void run() {
testMethod();
}
}, "a");
Thread b = new Thread(new Runnable() {
@Override
public void run() {
testMethod();
}
}, "b");
a.start();
b.start();
System.out.println(a.getName() + ":" + a.getState()); // 输出?
System.out.println(b.getName() + ":" + b.getState()); // 输出?
}
// 同步方法争夺锁
private synchronized void testMethod() {
try {
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
初看之下,大家可能会觉得线程a会先调用同步方法,同步方法内又调用Thread.sleep()方法,必然会输出TIMED_WAITING,而线程b因为等待线程a释放锁所以必然会输出BLOCKED。
其实不然,有两点需要值得大家注意,一是在测试方法blockedTest()内还有一个main线程,二是启动线程后执行run方法还是需要消耗一定时间的。不打断点的情况下,上面代码中都应该输出RUNNABLE。
上面在JUnit测试中运行,和在main方法中运行效果也是不同的。在JUnit测试中调用方法不需要对象,而在main方法中,要直接调用方法,要么该方法是静态方法,要就必须使用对象调用方法。如下:
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread t1 = new Thread(Thread01::testMethod);
Thread t2 = new Thread(Thread01::testMethod);
t1.start();
t2.start();
System.out.println(t1.getState());
System.out.println(t2.getState());
}
private static synchronized void testMethod() {
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
在Main方法中调用,程序等到所有线程都结束后才结束运行,而在JUnit中,因为JUnit也是一个main入口,它测试的方法中顺序执行完所有语句后,就会结束,如果还有子进程没有运行完,也会结束。
如果我要打印出BLOCKED状态我该怎么处理?其实就是让测试方法或者main方法的main线程休息一会就可以了,打断点或者调用Thread.sleep。这里一定要注意main线程的休息时间,只要让main线程在打印语句之前稍微停顿一下就可以。
public void blockedTest() throws InterruptedException {
······
a.start();
Thread.sleep(1000L); // 需要注意这里main线程休眠了1000毫秒,而testMethod()里休眠了2000毫秒,放在a.start之后第一个sout之前就可以,但是结果并不是绝对的!
b.start();
System.out.println(a.getName() + ":" + a.getState());
System.out.println(b.getName() + ":" + b.getState());
}
/*
* 输出:结果不定
* a:TIMED_WAITING
* b:BLOCKED
*/
main线程休眠:当对main线程调用Thread.sleep方法,当前线程就会在调用Thread.sleep地方停止,程序不会再往下执行,这不影响已经开始(start)的线程,会影响在停止的代码处后面未start的线程,很好理解,main线程停止了,后面代码块肯定属于main所在线程,所以就因main的停止而不会得到执行。
8.6 锁对象&条件对象&synchronized
Java语言提供一个synchronized关键字和ReentranLock类(可重入锁)防止代码块受并发访问的干扰。
8.6.1 锁对象
ReentrantLock保护代码块的基本结构如下:
myLock.lock();// a ReentrantLock object
try {
critical section// 临界区
} finally {
myLock.unlock; // 确保抛出异常的时候能够解锁
}
使用ReentrantLock的锁对象可以保证任何时刻只有一个线程进入临界区。一旦一个线程封锁了锁对象,其他任何线程都无法通过lock语句。当其他线程调用lock时,它们被阻塞,直到第一个线程释放锁对象。
注意点:
把解锁操作放在 finally内是至关重要的。如果临界区发生异常,这里所说的异常是因为业务逻辑错误而引发的异常,这时候已经lock了,所以确保锁必须被释放。否则,其他线程将永远阻塞。
如果使用锁,就不能使用带资源的try语句。
myLock.lock();必须放在try..finally语句块外?
如果放在try内部,如果lock()上锁发生异常,那么就会执行finally中的unlock,这时并没有获得锁对象,解锁不存在的锁对象抛出
IllegalMonitorStateException;相反放在try外部,当获取锁发生抛出异常时,下面语句则不会执行。
使用锁来保护Bank类的transfer方法
public class Bank {
private ReentrantLock reentrantLock = new ReentrantLock();
public void transfer(int from, int to, double amount) {
reentrantLock.lock();
try {
System.out.print(Thread.currentThread());
if (accounts[from] < amount) {
return;
}
accounts[from] -= amount;
System.out.printf("%10.2f from %d to %d%n", amount, from, to);
accounts[to] += amount;
System.out.printf("Total Balance %10.2f%n", getTotalBalance());
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
reentrantLock.unlock();
}
}
}
假定一个线程调用transfer,在执行结束前被剥夺了运行权。假定第二个线程也调用transfer,由于第二个线程不能获得锁,将在调用lock方法时阻塞。它必须等待第一个线程完成transfer方法的执行之后才能再度被激活。
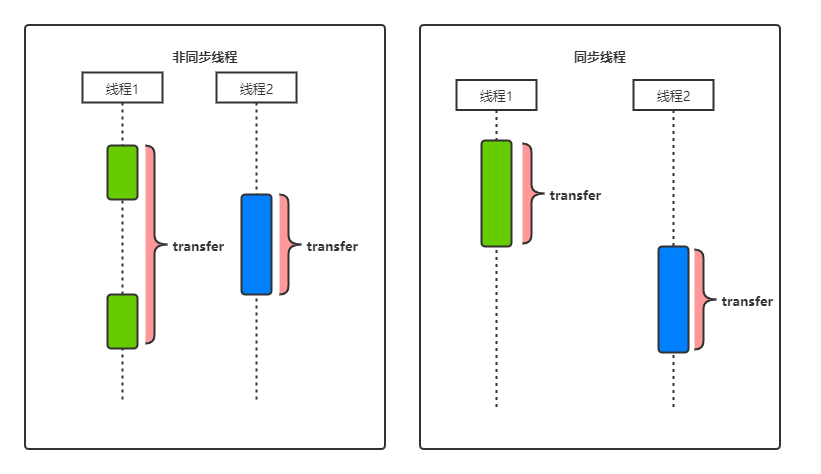
每一个Bank对象有自己的ReentrantLock对象。如果两个线程试图访问同一个Bank对象,那么锁以串行方式提供服务。如果两个线程访问不同的Bank对象,每一个线程得到不同的锁对象,两个线程都不会发生阻塞,也不会存在线程安全问题。
8.6.2 条件对象
条件对象又称为条件变量,线程进入临界区后,发现必须在满足某一条件之后他才能执行,这时我们可以使用条件对象来管理那些已经获得了一个锁但是却不能做有用工作的线程。
现在来细化银行的模拟程序,避免选择没有足够资金的账户作为转出账户。注意不能使用下面的代码:
if (bank.getBalance(from) >= amount)
bank.transfer(from, to, amount);
同样和之前的转出转入也是非原子操作,存在多线程并发的问题。我们应该确保没有其他线程在本检查余额与转账活动之间修改余额。通过锁可以做到这一点:
public void transfer(int from, int to, double amount) {
reentrantLock.lock();
try {
while (accounts[from] < amount) {
// wait
...
}
//transfer funds
...
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
reentrantLock.unlock();
}
}
}
当账户中没有足够余额时,应该做什么?等待直到另一个线程向账户中注入资金。但是,由于这一线程刚刚获得了对reentrantLock的排它性访问,因此别的线程没有进行存款操作的机会。但是我们可以使用条件对象来解决这一问题。
一个锁对象可以有一个或多个相关的条件对象,习惯上给每一个条件对象命名为可以反映它所表达的条件的名字。
class Bank {
private Condition sufficientFunds;
...
public Bank() {
...
sufficientFunds = reentrantLock.newCondition();
}
public void transfer(int from, int to, double amount) {
reentrantLock.lock();
try {
while (accounts[from] < amount) {
// 余额不足,让出CPU执行权
sufficientFunds.await();
}
// transfer funds...
// 转账结束,通知所有等待资源的线程
sufficientFunds.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
reentrantLock.unlock();
}
}
}
当一个线程调用await时,它没有办法重新激活自身。它寄希望于其他线程。如果没有其他线程来重新激活等待的线程,它就永远不再运行了。这将导致死锁现象。一旦激活,并且获得了锁之后,就从被阻塞的地方继续执行。
signalAll不会立即激活一个等待线程。它仅仅解除等待线程的阻塞,要执行方法,还是用通过竞争获得对象锁从而对对象方法进行访问。
当一个线程拥有某个条件的锁时,它仅仅可以在该条件上调用await、signalAll或signal方法。
锁和条件的总结:
- 锁用来保护代码片段,任何时刻只能有一个线程执行被保护的代码。
- 锁可以管理试图进入被保护代码段的线程。
- 锁可以拥有一个或多个相关的条件对象。
- 每个条件对象管理那些已经进入被保护的代码段但还不能运行的线程。
8.6.3 synchronized关键字
1、修饰成员方法和静态方法
(1)Java中的每一个对象都有一个内部锁。如果一个方法用synchronized关键字声明,那么对象的锁将保护整个方法。也就是说,要调用该方法,线程必须获得内部的对象锁。并且,该锁有一个内部条件,由锁来管理那些试图进入synchronized方法的线程,由条件来管理那些调用wait的线程。
(2)将静态方法声明为synchronized也是合法的。如果调用这种方法,该方法获得相关的类对象的内部锁。
public synchronized void method() {
method body
}
//等价于
public void method() {
this.reentrantLock.lock();
try {
method body
} finally {
this.reentrantLock.unlock();
}
}
内部对象锁只有一个相关条件。wait方法添加一个线程到等待集中,notifyAll/notify方法解除等待线程的阻塞状态。
Object.wait()/notifyAll();
//等价于
reentrantLock.await()/signalAll();
wait、notifyAll及notify方法是Object类的final方法。Condition方法必须被命名为await、signalAll和signal以便它们不会与那些方法发生冲突。
可以用内部对象锁来实现银行问题:
public synchronized void transfer(int from, int to, double amount) throws InterruptedException {
while (accounts[from] < amount) {
wait();
}
accounts[from] -= amount;
accounts[to] += amount;
notifyAll();
}
java.lang.Object 线程有关的方法
-
void notifyAll( )
解除那些在该对象上调用wait方法的线程的阻塞状态。
-
void notify( )
随机选择一个在该对象上调用wait方法的线程,解除其阻塞状态。
-
void wait( )
导致线程进入wait等待状态直到它被通知。
-
void wait(long millis) void wait(long millis, int nanos)
导致线程进入wait等待状态直到它被通知或者经过指定的时间。
上述方法只能在同步方法或同步块内部调用(synchronized)。如果当前线程不是对象锁的持有者,该方法抛出一个
IllegalMonitorStateException异常。
如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
当有线程调用了对象的 notifyAll()方法(唤醒所有 wait 线程)或 notify()方法(只随机唤醒一个 wait 线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。
优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用 wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了 synchronized 代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。
2、修饰代码块
被修饰的代码块称为同步代码块,其作用的范围是大括号{ }括起来的代码,作用的对象是调用这个代码块的对象。
(1)一个线程访问一个对象中的synchronized(this)同步代码块时,其他试图访问该对象的线程被阻塞。另一个线程仍可访问该对象中的非同步代码块。
(2)当对某一确定的对象加锁时,其他试图访问该对象的线程将会阻塞,直到该线程访问该对象结束。也就是说谁先拿到访问对象的锁谁就可以运行它所控制的代码。
public void method() {
synchronized(obj) {
// critical section
...
}
}
(3)当没有明确的对象作为锁,只想让一段代码同步时,可以创建一个特殊的对象来充当锁。
public class Bank {
private byte[] lock = new byte[0];
public void method() {
synchronized(lock) {
// critical section
...
}
}
}
说明:零长度的byte数组对象创建起来将比任何对象都经济――查看编译后的字节码:生成零长度的byte[]对象只需3条操作码,而Object lock = new Object()则需要7行操作码。
8.7 volatile域
8.7.1 内存模型的相关概念
计算机中执行程序时,每条指令都是在CPU中执行,执行指令的过程必然会涉及到数据的读取和写入。而程序运行时的数据是存放在主存(物理内存)中,由于CPU的读写速度远远高于内存的速度,如果CPU直接和内存交互,会大大降低指令的执行速度,所以CPU里面就引入了高速缓存。
脑补当初学习OS时的图 CPU->内存 CPU->寄存器->内存
也就是说程序运行时,会将运算所需要的数据从主存中复制一份到高速缓存,CPU进行计算的时候可以直接从高速缓存读取和写入,当运算结束时,在将高速缓存中的数据刷新到主存。
但是如果那样必须要考虑,在多核CPU下数据的一致性问题怎么保证?比如i=i+1,当线程执行这条时,会先从主存中读取i的值,然后复制一份到高速缓存,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。在单线程下这段代码运行不会存在问题,但如果在多线程下多核CPU中,每个CPU都有自己的高速缓存,可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。最终结果i的值是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
为了解决缓存不一致性问题,通常来说有以下2种解决方法:
-
通过在总线加LOCK#锁的方式
-
通过缓存一致性协议
8.7.2 原子性可见性有序性
并发编程中,通常会考虑的三个问题原子性问题、可见性问题、有序性问题。
(1)原子性:程序中的单步操作或多步操作要么全部执行并且执行的过程中不能被打断,要么都不执行。
如果程序中不具备原子性会出现哪些问题?
转账操作就是一个很好的代表,如果转账的过程中被中断,钱转出去了,由于中断,收账方却没有收到。
(2)可见性:内存可见性,指的是线程之间的可见性,当一个线程修改了共享变量时,另一个线程可以读取到这个修改后的值。
//线程1执行的代码
int i = 0;
i = 10;
//线程2执行的代码
j = i;
倘若线程1从主存中读取了i的值并复制到CPU高速缓存,然后对i修改为10,这时CPU高速缓存中的i值为10,在没有将高速缓存中的值刷新到主存中时,线程2读取到的值还是0,它看不到i值的变化,这就是可见性问题。
Java提供了Volatile关键字来保证可见性,当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
(3)有序性:程序执行的顺序按照代码的先后顺序执行。
实际是这样吗?
int i = 0; //[1]
int a,b; //[2]
[2]一定会在[1]之后执行吗?不一定,在JVM中,有可能会发生指令重排序(Instruction Reorder)。如果[1]、[2]中有相互依赖,比如[2]中的数据依赖于[1]的结果,那么则不会发生指令重排序。
什么是指令重排序?
一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
指令重排对于提⾼CPU处理性能⼗分必要。虽然由此带来了乱序的问题,但是这点牺牲是值得的。
指令重排可以保证串⾏语义⼀致,但是没有义务保证多线程间的语义也⼀致。所以在多线程下,指令重排序可能会导致⼀些问题。
8.7.3 Java内存模型的抽象结构
JVM可以看做是一个有OS架构的处理机,他也有自己的内存和处理器,它的内存和之前讨论的没有什么太大的差异。
Java运行时内存的划分如下:

对于每⼀个线程来说,栈都是私有的,而堆是共有的。也就是说在栈中的变量(局部变量、⽅法定义参数、异常处理器参数)不会在线程之间共享,也就不会有内存可⻅性(下⽂会说到)的问题,也不受内存模型的影
响。⽽在堆中的变量是共享的,本⽂称为共享变量。所以内存可见性针对的是共享变量。
1、既然堆是共享的,为什么在堆中会有内存不可⻅问题?
Java内存模型规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
线程之间的共享变量存在主内存中,每个线程都有⼀个私有的本地内存,存储了该线程以读、写共享变量的副本。本地内存是Java内存模型的⼀个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器等。
Java线程之间的通信由Java内存模型(简称JMM)控制,从抽象的⻆度来说,JMM定义了线程和主内存之间的抽象关系。JMM的抽象示意图如图所示:
从图中可以看出:
- 所有共享变量都存在主内存中。
- 每个线程都保存了一份该线程使用到的共享变量的副本。
- 线程A与线程B之间的通信必须通过主存。
2、JMM与Java内存区域划分的区别与联系
-
区别
JMM是抽象的,他是⽤来描述⼀组规则,通过这个规则来控制各个变量的访问⽅式,围绕原⼦性、有序性、可⻅性等展开的。⽽Java运⾏时内存的划分是具体的,是JVM运⾏Java程序时,必要的内存划分。
-
联系
都存在私有数据区域和共享数据区域。⼀般来说,JMM中的主内存属于共享数据区域,他是包含了堆和⽅法区;同样,JMM中的本地内存属于私有数据区域,包含了程序计数器、本地⽅法栈、虚拟机栈。
原子性、可见性、有序性
Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则。如果两个操作的执行次序无法从happens-before原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
在Java虚拟机规范中试图定义一种Java内存模型(Java Memory Model,JMM)来屏蔽各个硬件平台和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果。那么Java内存模型规定了哪些东西呢,它定义了程序中变量的访问规则,往大一点说是定义了程序执行的次序。注意,为了获得较好的执行性能,Java内存模型并没有限制执行引擎使用处理器的寄存器或者高速缓存来提升指令执行速度,也没有限制编译器对指令进行重排序。也就是说,在java内存模型中,也会存在缓存一致性问题和指令重排序的问题。
8.7.4 volatile的内存语义
在Java中,volatile关键字有特殊的内存语义。volatile主要有以下两个功能:
- 保证变量的内存可⻅性
- 禁⽌volatile变量与普通变量重排序(JSR133提出,Java 5 开始才有这个“增强的volatile内存语义“)
内存可见性
所谓内存可见性,指的是当一个线程对volatile修饰的变量进行过写操作时,JMM会立即把线程对应的本地内存中的共享变量的值刷新到主内存;当一个线程对volatile修饰的变量进行读操作时,JMM会立即把该线程对应的本地内存置为无效,从内存中从新读取共享变量的值。
禁止重排序
JMM是通过内存屏障来限制处理器对指令的重排序的。
什么是内存屏障?硬件层面,内存屏障分两种:读屏障(Load Barrier)和写屏障(Store Barrier)。内存屏障有两个作用:
- 阻止屏障两侧的指令重排序
- 强制把写缓冲区/⾼速缓存中的脏数据等写回主内存,或者让缓存中相应的数据 失效。
通俗说,通过内存屏障,可以防止指令重排序时,不会将屏障后面的指令排到之前,也不会将屏障之前的指令排到之后。
8.7.5 Volatile关键字的应用场景
单例模式下的Double-Check(双重锁检查)
public class Singleton {
public static Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) { //[1]
synchronized (Singleton.class) {
instance = new Singleton(); //[2]
}
}
return instance;
}
}
如果这里的变量没有使用volatile关键字,那么有可能就会发生错误。
[2]实例化对象的过程可以分为分配内存、初始化对象、引用赋值。
instance = new Singleton(); // [1]
// 可以分解为以下三个步骤
1 memory=allocate();// 分配内存 相当于c的malloc
2 ctorInstanc(memory) //初始化对象
3 s=memory //设置s指向刚分配的地址
// 上述三个步骤可能会被重排序为 1-3-2,也就是:
1 memory=allocate();// 分配内存 相当于c的malloc
3 s=memory //设置s指向刚分配的地址
2 ctorInstanc(memory) //初始化对象
如果一旦发生了上述的重排序,当程序执行了1和3,这时线程A执行了if判断,判定instance不为空,然后直接返回了一个未初始化的instance。
8.8 阻塞队列
8.8.1 阻塞队列介绍
1、什么是阻塞队列
要想知道什么是阻塞队列,那么就必须了解什么是队列,队列就是一种先进先出的数据结构,阻塞队列就是一种可阻塞的队列。
特性:
- 具有队列的基本特性(先进先出)
- 队列为空时,从队列中获取元素的操作会被阻塞。直到队列非空。
- 队列满时,向队列中添加元素的操作会被阻塞。直至队列存在空闲。
2、阻塞队列应用场景
(1) 生产者-消费者问题,生产者生产数据放入固定大小的缓冲区(队列),消费从缓冲区获取数据。这个过程中存在的问题有,生产者不可能无限制的生产,缓冲区大小固定,消费者也不可能无限制地消费,池中没有数据则不能消费。在单线程环境下,并不会出现上面问题,就有一个生产,一个消费,空了满了都会有具体的判断或者处理逻辑。但是对于多线程来说,同时刻,可能有两个线程进入了只有一个数量的池中,这样都会进行消费,这样就会带来问题。
生产者消费者问题(英语:Producer-consumer problem),也称有限缓冲问题(英语:Bounded-buffer problem),是一个多线程同步问题的经典案例。该问题描述了两个共享固定大小缓冲区的线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。
(2) 阻塞队列在java中的一种典型使用场景是线程池,在线程池中,当提交的任务不能被立即得到执行的时候,线程池就会将提交的任务放到一个阻塞的任务队列中来。
总结:使用阻塞队列,我们不需要关心什么时候需要阻塞线程(池满-生产线程-停止生产,消费者线程-消费),什么时候需要唤醒线程(池空-生产者线程-生产,消费者线程停止消费),这一切BlockingQueue都已经处理好了。
8.8.2 阻塞队列架构
| 队列 | 有界性 | 锁(ReentrantLock) | 数据结构 |
|---|---|---|---|
| ArrayBlockingQueue | bounded(有界) | 加锁 | arrayList |
| LinkedBlockingQueue | optionally-bounded | 加锁 | linkedList |
| PriorityBlockingQueue | unbounded | 加锁 | heap |
| DelayQueue | unbounded | 加锁 | heap |
| SynchronousQueue | bounded | 加锁 | 无 |
| LinkedTransferQueue | unbounded | 加锁 | heap |
| LinkedBlockingDeque | unbounded | 无锁 | heap |
1、BlockQueue方法
根据插入和取出两种类型的操作,具体分为下面一些类型:
| 操作类型 | Throws Exception | Special Value | Blocked | Timed out |
|---|---|---|---|---|
| 插入 | add(o) | offer(o) | put(o) | offer(o, timeout, unit) |
| 取出(删除) | remove(o) | poll() | take() | poll(timeout, unit) |
- 抛出异常:当插入和取出在不能立即被执行的时候就会抛出异常。
- 特殊值:插入和取出在不能立即被执行的情况下会返回一个特殊的值(true或者false)
- 阻塞:插入和取出操作在不能立即被执行时会阻塞线程,直到可以操作的时候会被其他线程唤醒。
- 超时:插入和取出操作在不能立即执行的时候会被阻塞一定的时间,如果在指定的时间内没有被执行,那么会返回一个特殊值。
从阻塞和非阻塞维度划分:
| 阻塞方法 | 非阻塞方法 |
|---|---|
| put(E e) | add(E e) |
| take() | remove() |
| offer(E e, long timeout, TimeUnit unit) | offer(E e) |
| poll(long time, TimeUnit unit) | poll() |
| peek() |
2、阻塞队列浅析
看源码
阻塞队列示例-查找java文件中的类关键字:
生产者线程枚举所有子目录下的文件将其放到阻塞队列中,这个过程很快就会执行完毕。同时启动大量搜索线程,每个搜索线程从队列中取出一个文件,打开它,打印所有包含关键字的行,然后取出下一个文件。这里虚设了一个文件,如果从队列中取出的文件是虚设文件,那么说明此次队列中的文件(10个)都已经执行查找完毕,结束线程运行。
public class BlockingQueenTest {
public static final int FILE_QUEEN_SIZE = 10;
public static final int SEARCH_THREADS = 100;
public static final File DUMMY = new File(""); //虚设文件,判断是否到达队列尾
private static BlockingQueue<File> queue = new ArrayBlockingQueue<>(FILE_QUEEN_SIZE);
public static void main(String[] args) {
try (Scanner in = new Scanner(System.in)) {
System.out.println("Enter base directory (e.g. /jdk1.8/src):");
String baseDir = in.nextLine();
System.out.println("Enter keyword (e.g. volatile):");
String keyword = in.nextLine();
Runnable enumerator = () -> {
enumerate(new File(baseDir));
queue.add(DUMMY);
};
new Thread(enumerator).start();
for (int i = 0; i < SEARCH_THREADS; i++) {
Runnable searcher = () -> {
try {
boolean done = false;
while (!done) {
File file = queue.take();
if (file == DUMMY) {
queue.put(file);//这里要放回虚设对象,因为还要终结其他线程。
done = true;
} else
searchFile(file, keyword);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
};
new Thread(searcher).start();
}
}
}
private static void searchFile(File file, String keyword) {
try (Scanner in = new Scanner(file, "utf8")) {
int lineNumber = 0;
while (in.hasNextLine()) {
lineNumber++;
String line = in.nextLine();
if (line.contains(keyword)) {
System.out.printf("%s:%d%s%n", file.getPath(), lineNumber, line);
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
private static void enumerate(File file) {
if (file.isDirectory()) {
File[] files = file.listFiles();
for (File f : files) {
enumerate(f);
}
} else {
queue.add(file);
}
}
}
GitBookhttps://redspider.gitbook.io/concurrent/di-yi-pian-ji-chu-pian/1
简书https://www.jianshu.com/p/ba068599459e
掘金https://juejin.im/post/5ab116875188255561411b8a
博客园https://www.cnblogs.com/wxd0108/p/5479442.html
CSDNhttps://blog.csdn.net/weixin_44797490/article/details/91006241
文件读写又忘了
java8新特性lambda表达式、函数式接口、流API、默认方法和新的Date以及Time API。
9. I/O
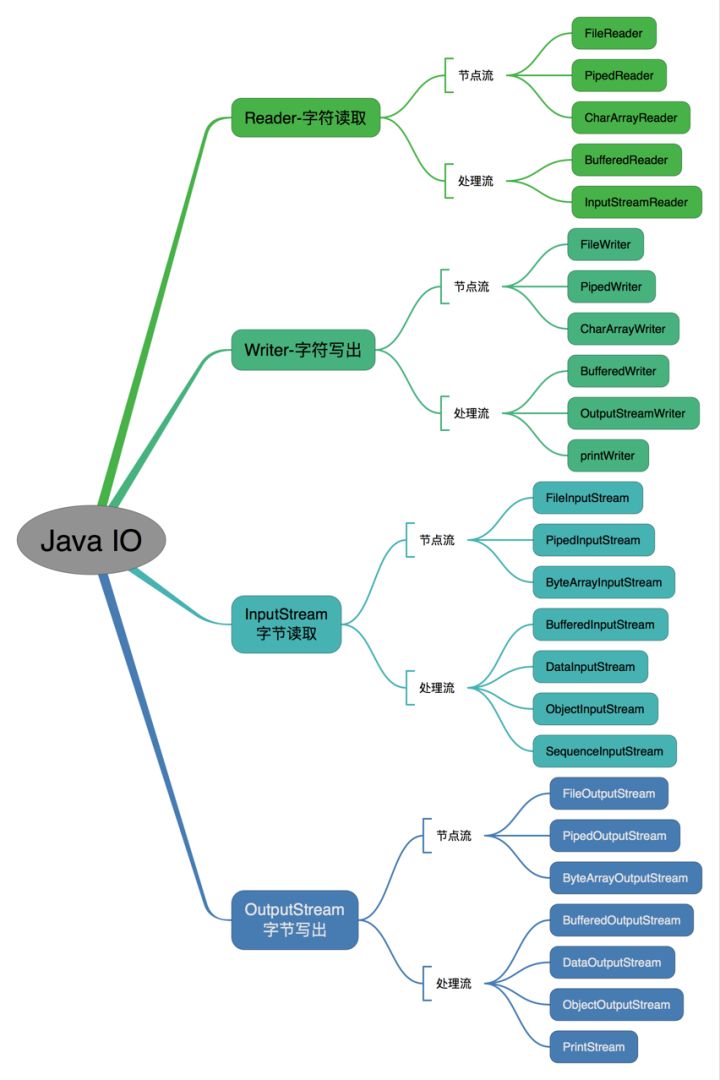
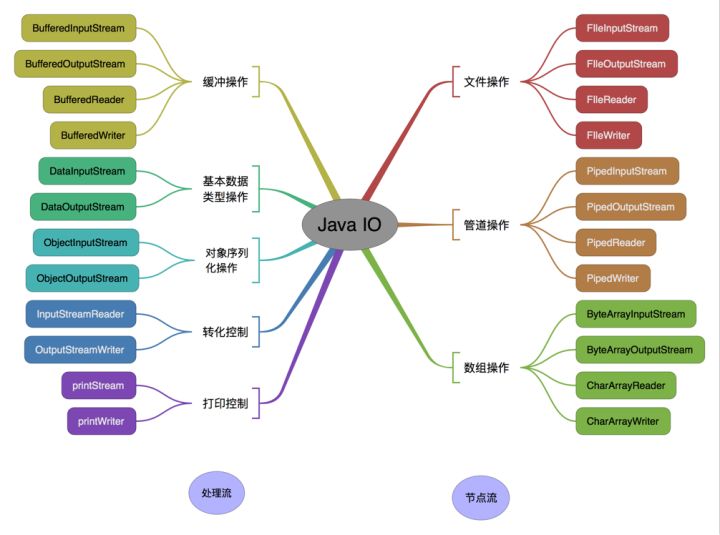
9.1 输入输出
磁盘、网络中读取到内存中的数据,我们一般称为输入,即磁盘、网络->内存。而从应用程序比如java App产生的数据保存到磁盘或者通过网络传输,称为输出,内存->磁盘、网络。
输入流读流,输出流写流
9.2 I/O流的分类
1、流的方向划分
- 输入流(InputStream)
- 输出流(OutputStream)
2、流的数据单位划分
- 字节流:1B
- 字符流:1字符,2B
3、流的功能划分
-
节点流:直接连接数据源的流,可以直接向数据源(硬盘,网络)读写数据。

-
处理流:对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写(装饰者模式)。处理流的构造方法必须依赖一个节点流。

9.3 I/O常用的五类一接口
在Java.io包中最重要的就是5个类和一个接口。5个类指的是File、OutputStream、InputStream、Writer、Reader;一个接口指的是Serializable。
9.4 四大基本抽象流
| 输入流 | 输出流 | |
|---|---|---|
| 字节流 | InputStream | OutputStream |
| 字符流 | Reader | Writer |
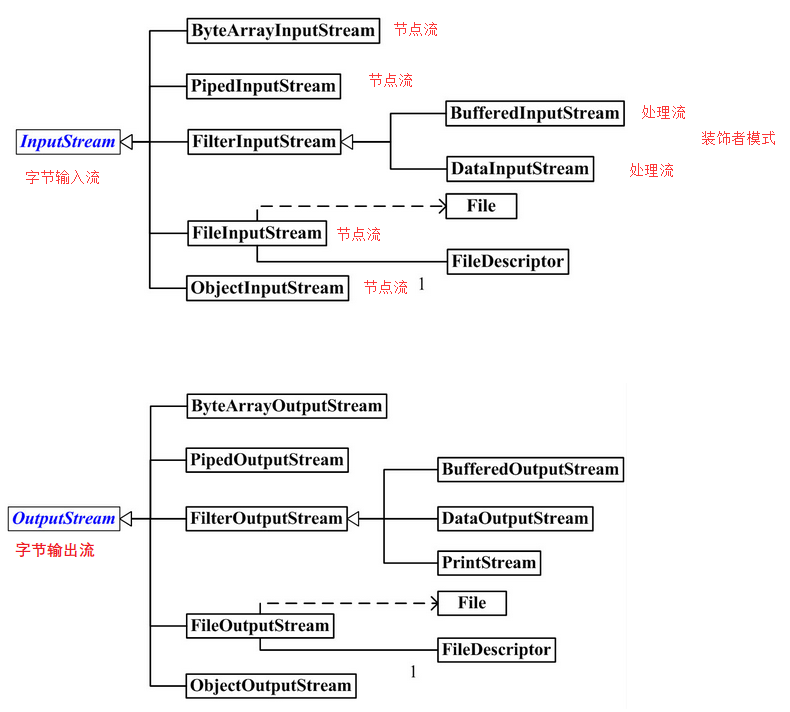
ByteArrayInputStream ByteArrayOutputStream:字节数组输入输出流在内存中创建一个字节数组缓冲区,实际就是将数据写入内存,然后从内存中读取。
- 关闭
ByteArrayInputStream没有任何效果。 在关闭流之后,仍然可以调用此类中的方法,而不生成IOException。
PipedInputStream:管道字节输入流,它和PipedOutputStream一起使用,能实现多线程间的管道通信。
FilterInputStream包含一些其他输入流,它用作其基本的数据源,可能会沿途转换数据或提供附加功能。 FilterInputStream本身简单地覆盖了所有InputStream的方法, InputStream版本将所有请求传递给包含的输入流。
BufferedInputStream BufferedOutputStream:带有缓冲区的输入输出流,构造方法接受一个节点流,内部使用字节数组来充当缓冲区,每次都会等待缓冲区满了之后在发送。
BufferedInputStream为另一个输入流添加了功能,即缓冲输入和支持mark和reset方法的功能。 当创建BufferedInputStream时,将创建一个内部缓冲区数组。 当从流中读取或跳过字节时,内部缓冲区将根据需要从所包含的输入流中重新填充,一次有多个字节。mark操作会记住输入流中的一点,并且reset操作会导致从最近的mark操作之后读取的所有字节在从包含的输入流中取出新的字节之前重新读取。
DataInputStream DataOutputStream:处理流,构造方法接收一个已存在的输入输出流,允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型。
FileInputStream FileOutputStream :可以从文件系统中 读取/写入 诸如图像数据之类的原始字节流。
ObjectInputStream ObjectOutputStream:对象输入输出流,可以从硬盘或者网络将序列化的对象读出,也可以将对象持久化存储到磁盘(对象存储)。
示例一:文件普通读写,BufferedInputStream重复读取。
/**
* 一次读取一字节
*/
public void copyFile1(String src, String des) throws IOException {
InputStream in = new FileInputStream(src);
OutputStream out = new FileOutputStream(des);
int len;
while ((len = in.read()) != -1) {
out.write(len);
}
in.close();
out.close();
// 使用处理流自带的缓冲区
BufferedInputStream bis = new BufferedInputStream(in3);
BufferedOutputStream bos = new BufferedOutputStream(out3);
}
/**
* 使用字节数组充当缓冲区实现缓冲读取
*/
public void copyFile2(String src, String des) throws IOException {
InputStream in = new FileInputStream(src);
OutputStream out = new FileOutputStream(des);
int len;
byte[] buff = new byte[1024];
while ((len = in.read(buff, 0, buff.length)) != -1) {
out.write(buff, 0, buff.length);
}
in.close();
out.close();
}
/**
* 使用BufferedInputStream
* 实现重复读取
* @throws IOException
*/
@Test
public void testCopyFile3(String src, String des) throws IOException {
InputStream in = new FileInputStream(src);
OutputStream out = new FileOutputStream(des);
int len;
BufferedInputStream bis = new BufferedInputStream(in);
BufferedOutputStream bos = new BufferedOutputStream(out);
bis.mark(0);
while ((len = bis.read()) != -1) {
System.out.println("第一次读取...");
bos.write(len);
}
bis.reset();
while ((len = bis.read()) != -1) {
System.out.println("第二次读取...");
bos.write(len);
}
bis.close();
bos.close();
}
示例二:Java基本数据类型的读和写
// 向文件中写入 java基本数据类型
private static void write(String dest) throws IOException {
//1. 创建流对象
DataOutputStream os = new DataOutputStream(new FileOutputStream(dest));
//2. 写入数据
os.writeInt(10);
os.writeChar('a');
os.writeChar('b');
os.writeDouble(12.83);
//3. 关闭流
os.close();
}
// 从文件中读取 java基本数据类型,要和写入的顺序保持一致
private static void read(String src) throws IOException {
//1. 创建数据流对象
DataInputStream in = new DataInputStream(new FileInputStream(src));
//2. 读取数据
int a = in.readInt();
char b = in.readChar();
char c = in.readChar();
double d = in.readDouble();
//3. 关闭流
in.close();
}
示例三:基于内存的数据读写
@Test
public void testByteArrayIO() throws IOException{
ByteArrayOutputStream bos = new ByteArrayOutputStream(1024);
bos.write("hello, world!".getBytes());
// 流关闭之后调用方法不受影响,因为数据保存在内存
bos.close();
byte[] bytes = bos.toByteArray();
ByteArrayInputStream bin = new ByteArrayInputStream(bytes);
BufferedReader br = new BufferedReader(new InputStreamReader(bin));
String s = br.readLine();
bin.close();
br.close();
System.out.println(s);//hello, world!
// 也可以采用下面的方法
// 通过使用命名的charset解码字节,将缓冲区的内容转换为字符串。
// bos.toString("utf-8");
}
示例四:对象序列化和反序列化
序列化:对象转化为字节序列的过程。
- 将对象的字节序列保存到磁盘中,称为持久化。
反序列化:将字节序列恢复为对象的过程称为对象的反序列化。
序列化注意点:
-
静态数据成员和标记了transient的数据成员不会被序列化。
-
serialVersionUID(long类型)
- 不写则java编译器则默认会生成一个UID,如果将对象序列化之后,对类中的代码进行了修改,那么将对象反序列化就会抛出一个异常。原因就是反序列化会比对两者的UID,当对类代码进行改动之后,UID会重新生成,不在和序列化之前的对象UID相同,编号不唯一,抛出异常。
-
子类继承父类,如果父类实现了序列化接口,序列化子类时无需在实现序列化接口;如果子类继承父类,子类实现序列化接口,父类没有实现序列化接口,那么父类必须提供无参构造,才可以序列化成功。否则抛出
java.io.InvalidClassException: full_class_name; no valid constructor。Java反序列化的时候会在实现Serializable所在类中向上查找第一个没有实现该接口的类,然后调用其构造方法。对于无继承关系的类来说,默认会查找到Obejct,然后构造该类对象,逐层往下去设置各个序列化的属性。如果类存在继承关系,子类实现了序列化接口,父类没有实现序列化接口,这时候反序列化的时候,构造对象会查询到父类,如果父类没有实现构造方法,这时候抛出
no valid constructor的异常。
@Test
public void testObjectOut() throws IOException{
String des = "C:\\Users\\lenovo\\Desktop\\new1.txt";
Person person = new Person("勇者", "男");
FileOutputStream fout = new FileOutputStream(des);
ObjectOutputStream objOut = new ObjectOutputStream(fout);
objOut.writeObject(person);
}
@Test
public void testObjectIn() throws IOException, ClassNotFoundException {
String des = "C:\\Users\\lenovo\\Desktop\\new1.txt";
FileInputStream fin = new FileInputStream(des);
ObjectInputStream objIn = new ObjectInputStream(fin);
Person p = (Person) objIn.readObject();
System.out.println(p);
}
serialVersionUID的取值是Java运行时环境根据类的内部细节自动生成的。如果对类的源代码作了修改,再重新编译,新生成的类文件的serialVersionUID的取值有可能也会发生变化。
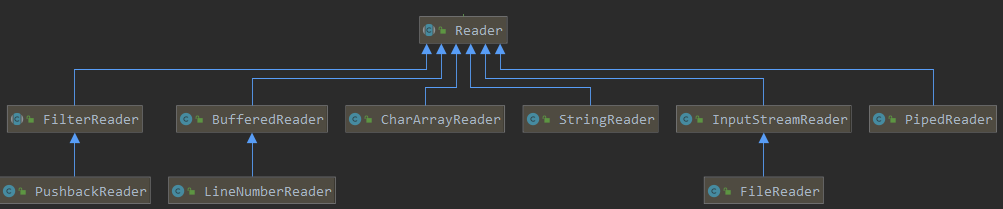

Reader Writer:所有字符输入输出流的抽象父类。
CharArrayReader CharArrayWriter:内部实现了字符缓冲区,可用作字符的输入输出。
StringReader StringWriter:方便快捷的将字符串写入内存,或从内存读取。
BufferedReader BufferedWriter:带有缓冲区的字符输入输出流。
InputStreamReader OutputStreamWriter:字节流与字符流之间转换的桥梁。
示例一:InputStreamReader OutputStreamWriter的读写
/**
* 定义字符数组,充当缓冲区
* @throws IOException
*/
@Test
public void testReaderWriter() throws IOException {
String src = "C:\\Users\\lenovo\\Desktop\\char.txt";
String des = "C:\\Users\\lenovo\\Desktop\\charcopy.txt";
InputStream in = new FileInputStream(src);
OutputStream out = new FileOutputStream(des);
Reader reader = new InputStreamReader(in);
Writer writer = new OutputStreamWriter(out);
char[] cbuf = new char[2048];
int len;
while ((len = reader.read(cbuf, 0, cbuf.length)) != -1) {
writer.write(cbuf, 0, cbuf.length);
}
writer.close();
reader.close();
out.close();
in.close();
}
BufferedReader BufferedWriter
// 一次拷贝一个 字符
private static void copyFile1(String src, String dest) throws IOException {
//1. 创建转换流
Reader reader = new BufferedReader(new FileReader(src));
Writer writer = new BufferedWriter(new FileWriter(dest));
//2. 拷贝数据
int data = reader.read();
while (data != -1) {
writer.write(data);
data = reader.read();
}
//3.关闭流
reader.close();
writer.close();
}
// 一次拷贝一个 字符数组
private static void copyFile2(String src, String dest) throws IOException {
//1. 创建转换流
Reader reader = new BufferedReader(new FileReader(src));
Writer writer = new BufferedWriter(new FileWriter(dest));
//2. 拷贝数据
char[] buffer = new char[2048];
int len = reader.read(buffer);
while (len != -1) {
writer.write(buffer, 0 , len);
len = reader.read(buffer);
}
//3.关闭流
reader.close();
writer.close();
}
// 一次拷贝一个一整行的 字符串
private static void copyFile3(String src, String dest) throws IOException {
//1. 创建转换流
BufferedReader reader = new BufferedReader(new FileReader(src));
BufferedWriter writer = new BufferedWriter(new FileWriter(dest));
//2. 拷贝数据
String data = reader.readLine();
while (data != null) {
writer.write(data);
writer.newLine();
data = reader.readLine();
}
//3.关闭流
reader.close();
writer.close();
}
9.5 Java流的关闭
1、包装流会自动调用被包装流的关闭方法,无需自己关闭
@Test
public void testClose() throws IOException {
String src = "C:\\Users\\lenovo\\Desktop\\char.txt";
String des = "C:\\Users\\lenovo\\Desktop\\charcopy.txt";
InputStream in = new FileInputStream(src);
BufferedInputStream bis = new BufferedInputStream(in);
bis.close(); // 1
in.close(); // 2
}
以上代码编译运行没有任何错误,bis的关闭是会关闭in的关闭,2处再次调用close方法等同于in关闭了两次,关闭多次没有任何异常,源码底层设置了关闭boolean变量,如果已经关闭,就不会再次关闭,所以多次关闭不会有任何异常。我们来看一下源码:为什么bis的关闭会自动关闭in。
//
public class BufferedInputStream extends FilterInputStream {
// 上文中走下面这个构造,之后又走双参构造
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
public BufferedInputStream(InputStream in, int size) {
// 调用FilterInputStream初始化InputStream
super(in);
...
}
...
public void close() throws IOException {
byte[] buffer;
while ( (buffer = buf) != null) {
if (bufUpdater.compareAndSet(this, buffer, null)) {
// 将父类的引用赋值给input,实际最终还是关闭的InputStream的流
InputStream input = in;
in = null;
if (input != null)
input.close();
return;
}
// Else retry in case a new buf was CASed in fill()
}
}
}
可以看到bis底层最终还是会调用到InputStream的close方法,所以说我们只需要关闭包装流,那么被包装流就会也会相应关闭。
流的关闭顺序是否有要求?更改上面1处和2处的代码先后顺序经实验,程序运行没有任何影响。那么是否任何流的关闭顺序都没有要求了吗?
@Test
public void testClose() throws IOException {
String src = "C:\\Users\\lenovo\\Desktop\\char.txt";
FileOutputStream fos = new FileOutputStream(src);
OutputStreamWriter osw = new OutputStreamWriter(fos);
BufferedWriter bw = new BufferedWriter(osw);
bw.write("java IO close test");
osw.close();//1
fos.close();//2
bw.close(); //3
}
// 抛出异常
Exception:
BufferedWriter
at sun.nio.cs.StreamEncoder.ensureOpen(StreamEncoder.java:45)
at sun.nio.cs.StreamEncoder.write(StreamEncoder.java:118)
at java.io.OutputStreamWriter.write(OutputStreamWriter.java:207)
at java.io.BufferedWriter.flushBuffer(BufferedWriter.java:129)
at java.io.BufferedWriter.close(BufferedWriter.java:265)
对于字符缓冲写流来(BufferedWriter)说,对于写入并不是直接写入介质中,而是先将流暂存到缓冲区,当调用close()或者flush()方法才会真正将缓冲区的数据写入,而BufferedWriter类中的close()方法中会将缓冲区的数据写入到介质中,处理流的本质还是靠节点流进行读写的,就上面的程序而言,如果fos关闭,而BufferedWriter会依赖fos将其缓冲区中的数据写出,那么就会导致上述异常。如果把2处的代码移到3后面,运行还是会抛异常,因为osw的关闭会关闭fos。
总结:
-
处理流读写底层还是依赖节点流,关闭包装流就无需关闭被包装流
-
一个流可以关闭多次
-
理论上,流的关闭顺序没有要求,但是如果关闭方法中调用了
write()方法,则会抛出异常,比如BufferedWriter。
如果非要有一种顺序的话,那就是流的关闭先关闭外层流(包装流)在关闭内层流(被包装流)。
这样会存在重复关闭流的问题,但并不会导致异常。
参考
https://blog.csdn.net/maxwell_nc/article/details/49151005
https://blog.csdn.net/sinat_37064286/article/details/86537354
9.6 阻塞式I/O
第一次接触到阻塞式IO是在Socket客户端向服务端发送消息,当在server端调用BufferedReader类中的readLine()方法读取数据时,客户端发送的数据并不会读取到。其原因就是readLine()方法只有当读取到换行符\n或者\r\n时才会将之前读取到的字符以一个字符串返回,否则会一直读取。当读取到文件末尾或者socket流关闭或者IOException则会返回null。
注意:
BufferedReader类中的readLine()读取成功返回时的字符串不包含最后的换行符。
10. Socket编程
未完TODO
Java中的Socket编程,一般指使用TCP协议进行网络数据包的传输。
10.1 单向传输
public class TcpClientOneWay {
public static void main(String[] args) throws IOException {
new Thread(TcpServerOneWay::startTcpServer).start();
//Socket socket = new Socket("172.17.46.123", 5005);
Socket socket = new Socket("127.0.0.1", 5005);
OutputStream out = socket.getOutputStream();
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(out));
writer.write("hello, world!(你好,世界!)");
writer.flush();
socket.close();
writer.close();
}
}
class TcpServerOneWay {
public static void startTcpServer() {
try {
ServerSocket serverSocket = new ServerSocket(5005);
Socket accept = serverSocket.accept();
InputStream in = accept.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
String s = reader.readLine();
System.out.println(s);
accept.close();
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
10.2 双向传输
public class TcpClientTwoWay {
public static void main(String[] args) throws IOException {
new Thread(TcpServerTwoWay::start).start();
Socket socket = new Socket("127.0.0.1", 5005);
OutputStream out = socket.getOutputStream();
InputStream in = socket.getInputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out));
bw.write("hello,world!(你好,世界)");
bw.flush();
// 通知服务器发送完毕,否则服务器会一直等待
// 通知后,只能读不能写
socket.shutdownOutput();
BufferedReader wr = new BufferedReader(new InputStreamReader(in));
String line = wr.readLine();
System.out.println(line);
bw.close();
wr.close();
socket.close();
}
}
class TcpServerTwoWay {
public static void start() {
try {
ServerSocket serverSocket = new ServerSocket(5005);
System.out.println("Tcp server start...");
Socket accept = serverSocket.accept();
InputStream in = accept.getInputStream();
OutputStream out = accept.getOutputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String line = br.readLine();
// 通知客户端已经读取完毕,之后只能向客户端写数据
accept.shutdownInput();
System.out.println("Tcp server receive:" + line);
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out));
bw.write("success!");
bw.flush();
bw.close();
br.close();
accept.close();
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
10.3 ReadBuffer读取socket流阻塞问题
我们有这样一个需求,在Clinet端输入数据,Server端显示Client输入的数据。代码如下:
// Client
public class SocketClient {
public static void main(String[] args) throws IOException, InterruptedException {
Socket socket = new Socket("127.0.0.1", 7777);
Scanner scanner = new Scanner(System.in);
OutputStream out = socket.getOutputStream();
while (true) {
String msg = scanner.next();
out.write(msg.getBytes());
}
}
}
// Server
public class SocketServer {
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(7777);
// blocked until request in
Socket accept = serverSocket.accept();
System.out.println("start accept...");
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
accept.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
首先运行Server端的代码,程序将会在serverSocket.accept()阻塞,直到有客户端连接进来,这时运行Client端代码,阻塞解除,之后server端的代码又会在reader.readLine()中阻塞,因为reader.readLine()底层从流中读取数据直到遇到换行符才会把数据返回或者读到流末尾或是遇到一个异常,否则会一直阻塞其中,有兴趣的可以查看源码,大致是阻塞在fill()方法中的do..while循环。当在client端输入信息的时候,debug模式跟踪到server端的BufferdReader是可以发现数据能发送过来,但是数据并没有返回即程序死在了reader.readLine()中,导致server端不会输出信息。
解决办法:
(1)关闭client端的socket读,这时候服务器就会将缓冲区的流全部flush出,自动读取到流末尾,这种方式不适用于该程序。
(2)调用socket的shutdownOutput通知server端写入完毕,但是该方法也有一个局限,就是一旦调用就不能再次写入,对于循环写入也是不可取的。
(3)采用原生读,即使用节点流InputStream不适用处理流BufferedReader。
(4)根据BufferedReader读的特性,在发送数据的时候发送\n,虽然reader.readLine()不会再阻塞了,但是由于读不到流的末尾(reader.readLine() != null在Socket流没有关闭总是成立),还是会死循环,还需要自定义一个结束符,当server端在处理到结束符的时候,退出while循环。
采用方式(4)更改后的代码如下:
public class SocketServer {
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(7777);
Socket accept = serverSocket.accept();
System.out.println("start accept...");
InputStream in = accept.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
String line;
// 定义输入end结束符结束循环关闭流
while ((line = reader.readLine()) != null && !"end".equals(line)) {
System.out.println(line);
}
accept.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public class SocketClient {
public static void main(String[] args) throws IOException, InterruptedException {
Socket socket = new Socket("127.0.0.1", 7777);
Scanner scanner = new Scanner(System.in);
OutputStream out = socket.getOutputStream();
while (true) {
String msg = scanner.next() + "\n";
out.write(msg.getBytes());
// 定义输入end结束符结束循环关闭流
if (msg.equals("end\n"))
break;
}
socket.close();
}
}
采用方式(3)更改后的代码
public class SocketClient {
public static void main(String[] args) throws IOException, InterruptedException {
Socket socket = new Socket("127.0.0.1", 7777);
Scanner scanner = new Scanner(System.in);
OutputStream out = socket.getOutputStream();
while (true) {
String msg = scanner.next();
out.write(msg.getBytes());
// 定义输入end结束符结束循环关闭流
if (msg.equals("end"))
break;
}
socket.close();
}
}
public class SocketServer {
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(7777);
Socket accept = serverSocket.accept();
System.out.println("start accept...");
InputStream in = accept.getInputStream();
byte[] buf = new byte[1024];
int len;
while ((len = in.read(buf, 0 , buf.length)) != -1) {
System.out.println(new String(buf, 0, len));
}
accept.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
11. JDBC
11.1 什么是JDBC?
JDBC(Java Database Connectivity)Java语言规定的客户端如何与数据库服务器进行通信的应用程序编程接口,Java语言操作各种数据库的程序接口,是一种规范,屏蔽了底层数据库的差异。使调用程序的用户只需要关心如何去掉用操作数据库的连接,而不需要关注底层数据库的具体实现。
11.2 如何使用JDBC
JDBC使用步骤:
连接四大属性值:驱动(driver)、数据库地址(url)、用户名(username)、密码(password)
1.加载驱动
2.建立连接
3.执行SQL语句
4.获得结果集或者其他
5.关闭连接
示例:对department表进行增删改查,四个测试用例,每个建立数据库连接的方式有所不同,testRetireve采用最原始最基本建立数据库连接的方式;testAdd方法采用实例化jdbc驱动的具体实现类来建立数据库连接;testDelete方法采用加载配置文件的形式来建立数据库连接;testUpdate方法采用工具类的形式建立数据库连接,工具类将具体获得数据库连接的操作封装在了类内。
为什么会衍生出这么多种形式?这样做的目的是减少代码冗余和耦合,加速代码重构。
ResultSet获得结果集注意点:在获取结果之前,需要调用rs.next()方法,该方法一般用做判断并且将光标移动到第一行的位置。如果获取到结果集之后,直接取数据,往往会报空指针异常。
@Test
public void testRetrieve() throws ClassNotFoundException, SQLException {
// Driver首字母大写
String driver = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/ncov";
String user = "root";
String pwd = "root";
Class.forName(driver);
Connection connection = DriverManager.getConnection(url, user, pwd);
String sql = "select * from department";
PreparedStatement ps = connection.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
while (rs.next()) {
String deptName = rs.getString("dept_name");
System.out.println(deptName);
}
// 关闭连接,先打开的后关闭
rs.close();
ps.close();
connection.close();
}
@Test
public void testAdd() throws SQLException {
//第一个url中文乱码,添加字符集设置
//String url = "jdbc:mysql://localhost:3306/ncov";
String url = "jdbc:mysql://localhost:3306/ncov?characterEncoding=utf-8&useUnicode=TRUE";
String user = "root";
String pwd = "root";
com.mysql.jdbc.Driver driver = new com.mysql.jdbc.Driver();
DriverManager.registerDriver(driver);
Connection conn = DriverManager.getConnection(url, user, pwd);
String sql = "insert into department(dept_name,headcount,submitted_count) values(?,?,?)";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setString(1, "心科学院");
ps.setInt(2, 30);
ps.setInt(3, 20);
int effectRows = ps.executeUpdate();
System.out.println("effectRows:" + effectRows);
ps.close();
conn.close();
}
@Test
public void testDelete() throws IOException, SQLException, ClassNotFoundException {
InputStream in = JdbcStart.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties prop = new Properties();
prop.load(in);
String driver = prop.getProperty("driver");
String url = prop.getProperty("url");
String username = prop.getProperty("username");
String password = prop.getProperty("password");
assert in != null;
in.close();
Class.forName(driver);
Connection connection = DriverManager.getConnection(url, username, password);
String sql = "delete department from department where dept_id=?";
PreparedStatement ps = connection.prepareStatement(sql);
ps.setInt(1, 5);
ps.executeUpdate();
ps.close();
connection.close();
}
@Test
public void testUpdate() throws SQLException, IOException, ClassNotFoundException {
Connection conn = JdbcUtil.getConnection();
String sql = "update department set headcount=? where dept_id=?";
/*
为什么不把PreparedStatement封装在JdbcUtil里面?
Connection类:
PreparedStatement prepareStatement(String sql)
prepareStatement方法需要一个sql参数,如果要封装prepareStatement
那么也必须将SQL语句封装,并且需要考虑参数设置等问题,有点复杂,
但是如果封装好了,那将是很方便的,这里只是简单的封装。
*/
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, 50);
ps.setInt(2, 6);
int effectedRows = ps.executeUpdate();
System.out.println(effectedRows);
JdbcUtil.release(conn, ps, null);
}
11.3 JDBC工具类的封装
JdbcUtil工具类,该类封装了数据库连接的建立和关闭,为了JavaBean属性和数据库字段能够相互对应,添加了下划线和驼峰之间的互转方法。如果学习了线程池,还可以继续优化。
/**
* Created by WuJiXian on 2020/9/18 15:08
* JDBC CRUD的封装
*/
public class JdbcUtil {
private static String driver;
private static String url;
private static String username;
private static String password;
// 静态代码块,只会编译一次
static {
InputStream in = JdbcUtil.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties prop = new Properties();
try {
prop.load(in);
driver = prop.getProperty("driver");
url = prop.getProperty("url");
username = prop.getProperty("username");
password = prop.getProperty("password");
assert in != null;
in.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection() {
Connection conn = null;
try {
Class.forName(driver);
conn = DriverManager.getConnection(url, username, password);
} catch (Exception e) {
e.printStackTrace();
}
return conn;
}
/**
* 释放连接
* 增加了空值判断,为空无需任何操作
* @param conn
* @param st
* @param rs
*/
public static void release(Connection conn, Statement st, ResultSet rs) {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (st != null) {
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 下划线转驼峰
* @param field
* @return
*/
public static String underscoreToCamelCase(String field) {
if (!field.contains("_")) {
return field;
} else {
char c = field.charAt(field.indexOf("_") + 1);
char upperC = (char)((int) c - 32);
return field.replaceAll("_" + c, String.valueOf(upperC));
}
}
/**
* 驼峰转下划线
* @param field
* @return
*/
public static String CamelCaseToUnderscore(String field) {
Pattern humpPattern = Pattern.compile("[A-Z]");
Matcher matcher = humpPattern.matcher(field);
StringBuffer sb = new StringBuffer();
while (matcher.find()) {
matcher.appendReplacement(sb, "_" + matcher.group(0).toLowerCase());
}
matcher.appendTail(sb);
return sb.toString();
}
}
JdbcTemplate主要是对数据库进行CRUD操作的类,包含了两个方法
executeQuery:结果集的查询,单条结果或者是集合类型- ``executeUpdate`:对数据库进行增删改操作的方法
具体的实现就是依靠反射加泛型和可变参数的应用。
/**
* Created by WuJiXian on 2020/9/18 16:46
*/
public class JdbcTemplate {
/**
* 增、删、改功能函数
* @param sql
* @param params
* @return
*/
public static int executeUpdate(String sql, Object... params) throws SQLException {
Connection connection = JdbcUtil.getConnection();
PreparedStatement ps = connection.prepareStatement(sql);
for (int i = 1; i <= params.length; i++) {
ps.setObject(i, params[i - 1]);
}
int effectedRow = ps.executeUpdate();
JdbcUtil.release(connection, ps, null);
return effectedRow;
}
/**
* 泛型方法实现查询
* 结果集:1)单一 2)集合
* @param sql
* @param handler
* @param params
* @param <T>
* @return
*/
public static <T> T executeQuery(String sql, ResultHandler<T> handler, Object... params) throws Exception {
Connection connection = JdbcUtil.getConnection();
PreparedStatement ps = connection.prepareStatement(sql);
for (int i = 1; i <= params.length; i++) {
ps.setObject(i, params[i - 1]);
}
ResultSet rs = ps.executeQuery();
return handler.handle(rs);
}
}
ResultHandler方法是一个接口,用于对结果集ResutlSet进行处理
public interface ResultHandler<T> {
T handle(ResultSet rs) throws Exception;
}
有两个实现类
1、BeanHandler:单条结果的处理
public class BeanHandler<T> implements ResultHandler<T> {
private Class<T> cls;
public BeanHandler(Class cls) {
this.cls = cls;
}
@Override
public T handle(ResultSet rs) throws Exception {
if (rs.next()) {
// 根据传入的字节码创建传入的指定对象
T t = cls.newInstance();
// 获取Bean信息,关于BeanInfo类可以看源码或者文档
BeanInfo beanInfo = Introspector.getBeanInfo(cls, Object.class);
// 获取所有属性描述符
PropertyDescriptor[] pds = beanInfo.getPropertyDescriptors();
for (PropertyDescriptor pd : pds) {
// 通过属性描述符,可以通过特定的API调用bean的读getXxx或者写setXxx方法
String colLabel = JdbcUtil.CamelCaseToUnderscore(pd.getName());
pd.getWriteMethod().invoke(t, rs.getObject(colLabel));
}
return t;
}
return null;
}
}
2、BeanListHandler:多条结果的处理
/**
* Created by WuJiXian on 2020/9/18 16:57
* 注意参数,一个是T,一个是List<T>,泛型的强大
*/
public class BeanListHandler<T> implements ResultHandler<List<T>> {
private Class<T> cls;
public BeanListHandler(Class<T> cls) {
this.cls = cls;
}
@Override
public List<T> handle(ResultSet rs) throws Exception{
List<T> list = new ArrayList<>();
T t = null;
BeanInfo beanInfo = Introspector.getBeanInfo(cls, Object.class);
PropertyDescriptor[] pds = beanInfo.getPropertyDescriptors();
while (rs.next()) {
t = cls.newInstance();
for (PropertyDescriptor pd : pds) {
String colLabel = JdbcUtil.CamelCaseToUnderscore(pd.getName());
pd.getWriteMethod().invoke(t, rs.getObject(colLabel));
}
list.add(t);
}
return list;
}
}
Introspector和Java的内省机制有关,内省,自我反省的意思,java内省指的是对JavaBean内部状态的检查,可以通过特定的类来获取JavaBean的属性值或者方法等状态信息。Introspector.getBeanInfo(cls, Object.class);因为beanInfo.getPropertyDescriptors()方法会把getXxx作为属性值,每个类中都默认含有一个getClass方法,所以说为了不把getClass也作为属性值返回,通过Introspector.getBeanInfo(cls, Object.class)排除Object.class的getClass()方法。
测试:
@Test
public void testJdbcTemplate() throws Exception {
String sql = "insert into department(dept_name,headcount,submitted_count) values(?,?,?)";
Object[] params = {"机电学院", 2, 2};
// 增加
int effectedRows = JdbcTemplate.executeUpdate(sql, params);
sql = "select * from department where dept_name=?";
// 查询:单一结果
Department department = JdbcTemplate.executeQuery(sql, new BeanHandler<>(Department.class), "机电学院");
System.out.println(department);
sql = "select * from department";
// 查询:结果集
List<Department> departments = JdbcTemplate.executeQuery(sql, new BeanListHandler<>(Department.class));
System.out.println(departments.size());
// 修改
sql = "update department set headcount=22 where dept_name=?";
JdbcTemplate.executeUpdate(sql, "机电学院");
// 删除
sql = "delete from department where dept_name=?";
JdbcTemplate.executeUpdate(sql, "机电学院");
}
11.4 高级操作
1、获取自增主键的方法
-
Statement getGeneratedKeys()
获取自增主键(Statement),对于Statement来说,需要设置
Statement.RETURN_GENERATED_KEYS变量
才可以获取 -
mybatis
useGeneratedKeys -
sql语句
select last_insert_id()
2、模糊查询
/**
* 模糊查询
*/
@Test
public void testAmbiguous() throws SQLException, IOException, ClassNotFoundException {
Connection connection = JdbcUtil.getConnection();
String sql = "select * from student where name like ?";
PreparedStatement ps = connection.prepareStatement(sql);
ps.setString(1, "王%");
ResultSet rs = ps.executeQuery();
while (rs.next()) {
String name = rs.getString("name");
System.out.println(name);
}
JdbcUtil.release(connection, ps, rs);
}
3、批量插入
/**
* 批量插入(PreparedStatement实现)
*/
@Test
public void testAddBatch() throws SQLException, IOException, ClassNotFoundException {
Connection connection = JdbcUtil.getConnection();
String sql1 = "insert into department(dept_name,headcount,submitted_count) values(?,?,?)";
PreparedStatement ps;
ps = connection.prepareStatement(sql1);
ps.setString(1, "城建学院");
ps.setInt(2, 30);
ps.setInt(3, 20);
ps.addBatch();
ps.setString(2, "外国语学院");
ps.setInt(2, 30);
ps.setInt(3, 20);
ps.addBatch();
ps.executeBatch();
JdbcUtil.release(connection, ps, null);
}
11.5 JDBC操作大数据
大数据也称之为LOB(Large Objects),LOB又分为:clob和blob,clob用于存储大文本,blob用于存储二进制数据,例如图像、声音、二进制文等。
在实际开发中,有时是需要用程序把大文本或二进制数据直接保存到数据库中进行储存的。
对MySQL而言只有blob,而没有clob,mysql存储大文本采用的是Text,Text和blob分别又分为:
TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT
TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB
示例:请参考https://www.cnblogs.com/xdp-gacl/p/3982581.html
ResultSet在获取数据之前,必须调用
resultSet.next()方法,否则报空指针异常
11.6 编写数据库连接池
编写连接池需实现java.sql.DataSource接口。DataSource接口中定义了两个重载的getConnection方法:
- Connection getConnection()
- Connection getConnection(String username, String password)
实现DataSource接口,并实现连接池功能的步骤:
- 在DataSource构造函数中批量创建与数据库的连接,并把创建的连接加入LinkedList对象中。
- 实现getConnection方法,让getConnection方法每次调用时,从LinkedList中取一个Connection返回给用户。
- 当用户使用完Connection,调用Connection.close()方法时,Collection对象应保证将自己返回到LinkedList中,而不要把conn还给数据库。Collection保证将自己返回到LinkedList中是此处编程的难点。
数据库连接池核心代码
使用动态代理技术构建连接池中的connection
核心代码:
proxyConn = (Connection) Proxy.newProxyInstance(this.getClass()
.getClassLoader(), conn.getClass().getInterfaces(),
new InvocationHandler() {
//此处为内部类,当close方法被调用时将conn还回池中,其它方法直接执行
public Object invoke(Object proxy, Method method,
Object[] args) throws Throwable {
if (method.getName().equals("close")) {
pool.addLast(conn);
return null;
}
return method.invoke(conn, args);
}
});
/**
* Created by WuJiXian on 2020/10/24 19:47
*/
public class JdbcPool implements DataSource {
private static LinkedList<Connection> connections = new LinkedList<>();
// 静态代码块,只会编译一次
static {
InputStream in = JdbcUtil.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties prop = new Properties();
try {
prop.load(in);
String driver = prop.getProperty("driver");
String url = prop.getProperty("url");
String username = prop.getProperty("username");
String password = prop.getProperty("password");
int initialPoolSize = Integer.parseInt(prop.getProperty("initialPoolSize"));
Class.forName(driver);
for (int i = 0; i < initialPoolSize; i++) {
Connection connection = DriverManager.getConnection(url, username, password);
System.out.println("第" + i + "个连接:" + connection);
connections.add(connection);
}
assert in != null;
in.close();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public Connection getConnection() throws SQLException {
if (connections.size() > 0) {
// 从池中移除一个连接
final Connection connection = connections.removeFirst();
System.out.println("数据库连接池的连接数:" + connections.size());
Connection proxyConn = (Connection) Proxy.newProxyInstance(this.getClass().getClassLoader(), connection.getClass().getInterfaces(), new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (!method.getName().equals("close"))
return method.invoke(connection, args);
else {
// 调用了close方法,将连接归还到池中
System.out.println(connection + "归还到池中,池中连接数:" + connections.size());
connections.add(connection);
return null;
}
}
});
return proxyConn;
} else {
throw new RuntimeException("数据库连接忙!");
}
}
...
}
12. ThreadLocal
12.1 ThreadLocal概述
源码分析:
/**
* This class provides thread-local variables. These variables differ from
* their normal counterparts in that each thread that accesses one (via its
* {@code get} or {@code set} method) has its own, independently initialized
* copy of the variable. {@code ThreadLocal} instances are typically private
* static fields in classes that wish to associate state with a thread (e.g.,
* a user ID or Transaction ID).
* <p>Each thread holds an implicit reference to its copy of a thread-local
* variable as long as the thread is alive and the {@code ThreadLocal}
* instance is accessible; after a thread goes away, all of its copies of
* thread-local instances are subject to garbage collection (unless other
* references to these copies exist).
*
* @author Josh Bloch and Doug Lea
* @since 1.2
*/
ThreadLocal为每个线程创建了共享变量的副本,每个线程保留了唯一一份实例,并且对线程内共享变量的操作是不会影响到其他线程。
ThreadLocal用于解决多线程间数据隔离的问题,并不是解决多线程并发和数据共享的问题。
合理的理解
ThreadLoal 变量,它的基本原理是,同一个 ThreadLocal 所包含的对象(对ThreadLocal< String >而言即为 String 类型变量),在不同的 Thread 中有不同的副本(实际是不同的实例,后文会详细阐述)。这里有几点需要注意
- 因为每个 Thread 内有自己的实例副本,且该副本只能由当前 Thread 使用。这是也是 ThreadLocal 命名的由来
- 既然每个 Thread 有自己的实例副本,且其它 Thread 不可访问,那就不存在多线程间共享的问题
- 既无共享,何来同步问题,又何来解决同步问题一说?
12.2 应用场景
数据库连接:某些场景下,service的操作要聚合多个dao才能完成,在使用最原始JDBC操作的前提下,ThreadLocal保证了多个dao操作使用同一个连接Connection,保证了数据的完整性和一致性。
实例一:Service和dao的原始模型
第一次使用三层架构时,Service持有dao的引用,下面代码是不是很熟悉
public class Service {
private static final Dao1 DAO_1 = new Dao1();
private static final Dao2 DAO_2 = new Dao2();
public void fun() {
DAO_1.fun1();
DAO_2.fun2();
}
}
dao
public class Dao1 {
public void fun1() {
/**
*对于service上层的单步操作来说获取一个新连接还可以,但是
*对于复合dao不能保证事务。
*/
// new Connection [通常的做法]
}
}
...
在上面的原始模型中,如何保证Service的fun方法下,dao对象的fun1和fun2使用的是同一个连接,这里有两种方法:
1)将获取到的数据库连接通过传参的形式传递到dao,这种方法的缺点是耦合度太高,不利于维护。
2)ThreadLocal配合数据库连接池
这里为什么用到数据库连接池,单个Connection放在ThreadLocal中,因为其特性,每个线程都会有这一个Connection的引用,有极大可能性破坏数据完整性和一致性。但是数据库连接池,能分配到,每一个线程一个单独的connection通过ThreadLocal绑定到线程。
下面以c3p0作为数据库连接池,以一个工具类展示本地线程的使用
public class DBUtil {
private static ComboPooledDataSource dataSource;
private static ThreadLocal<Connection> threadLocal;
// 静态代码块,只会编译一次
static {
dataSource = new ComboPooledDataSource();
threadLocal = new ThreadLocal<>();
}
public static Connection getConnection() {
Connection conn = null;
if (threadLocal.get() != null) {
conn = threadLocal.get();
} else {
// 每个线程都绑定到一个Connection确保在Service层数据库的连接是同一个
//System.out.println("current thread:" + Thread.currentThread().getName());
try {
conn = dataSource.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
threadLocal.set(conn);
}
return conn;
}
/**
* 释放连接
* 增加了空值判断,为空无需任何操作
* @param st
* @param rs
*/
public static void release(Statement st, ResultSet rs) {
Connection conn = threadLocal.get();
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (st != null) {
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
threadLocal.remove();
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
其实这里还是有点问题,大家想一下,数据库连接相关的操作(开启,关闭,回滚...)是应该放到service层还是放到dao层?
[下面是个人的见解,如有错误,请不吝指正!]
假如将获取数据库的连接放到dao层,数据库事务可能得不到保证,因为连接的关闭和释放都是在同一个dao下的方法内,不能确保第二次还是同一个数据库连接;使用ThreadLocal解决了同一个连接问题,但是关闭连接呢,该如何去处理,如果第一个dao关闭了连接,对于第二个dao来说,连接根本得不到了。
如果将获取数据库的连接放到service层,以本文这种案例所做的来说,一个是通过DBUtils获取一个连接,传递到dao,耦合度太高。另一个是将连接的操作(开关、事务相关)都放入到service层去处理。
框架基本上就是将连接操作的过程提前到了service上了,
@Transaction注解就能实现事务的完整性和一致性,当然肯定也保证了同一个连接,底层通过AOP的方式,将与业务代码无关的操作切入到方法中,这就是面向切面编程。
下面通过如下代码说明 ThreadLocal 的使用方式
public class ThreadLocalDemo {
public static void main(String[] args) throws InterruptedException {
int threads = 3;
CountDownLatch countDownLatch = new CountDownLatch(threads);
InnerClass innerClass = new InnerClass();
for(int i = 1; i <= threads; i++) {
new Thread(() -> {
for(int j = 0; j < 4; j++) {
innerClass.add(String.valueOf(j));
innerClass.print();
}
innerClass.set("hello world");
countDownLatch.countDown();
}, "thread - " + i).start();
}
countDownLatch.await();
}
private static class InnerClass {
public void add(String newStr) {
StringBuilder str = Counter.counter.get();
Counter.counter.set(str.append(newStr));
}
public void print() {
System.out.printf("Thread name:%s , ThreadLocal hashcode:%s, Instance hashcode:%s, Value:%s\n",
Thread.currentThread().getName(),
Counter.counter.hashCode(),
Counter.counter.get().hashCode(),
Counter.counter.get().toString());
}
public void set(String words) {
Counter.counter.set(new StringBuilder(words));
System.out.printf("Set, Thread name:%s , ThreadLocal hashcode:%s, Instance hashcode:%s, Value:%s\n",
Thread.currentThread().getName(),
Counter.counter.hashCode(),
Counter.counter.get().hashCode(),
Counter.counter.get().toString());
}
}
private static class Counter {
private static ThreadLocal<StringBuilder> counter = new ThreadLocal<StringBuilder>() {
@Override
protected StringBuilder initialValue() {
return new StringBuilder();
}
};
}
}
实例分析
ThreadLocal本身支持范型。该例使用了 StringBuilder 类型的 ThreadLocal 变量。可通过 ThreadLocal 的 get() 方法读取 StringBuidler 实例,也可通过 set(T t) 方法设置 StringBuilder。
上述代码执行结果如下
Thread name:thread - 1 , ThreadLocal hashcode:372282300, Instance hashcode:418873098, Value:0
Thread name:thread - 3 , ThreadLocal hashcode:372282300, Instance hashcode:1609588821, Value:0
Thread name:thread - 2 , ThreadLocal hashcode:372282300, Instance hashcode:1780437710, Value:0
Thread name:thread - 3 , ThreadLocal hashcode:372282300, Instance hashcode:1609588821, Value:01
Thread name:thread - 1 , ThreadLocal hashcode:372282300, Instance hashcode:418873098, Value:01
Thread name:thread - 3 , ThreadLocal hashcode:372282300, Instance hashcode:1609588821, Value:012
Thread name:thread - 3 , ThreadLocal hashcode:372282300, Instance hashcode:1609588821, Value:0123
Set, Thread name:thread - 3 , ThreadLocal hashcode:372282300, Instance hashcode:1362597339, Value:hello world
Thread name:thread - 2 , ThreadLocal hashcode:372282300, Instance hashcode:1780437710, Value:01
Thread name:thread - 1 , ThreadLocal hashcode:372282300, Instance hashcode:418873098, Value:012
Thread name:thread - 2 , ThreadLocal hashcode:372282300, Instance hashcode:1780437710, Value:012
Thread name:thread - 1 , ThreadLocal hashcode:372282300, Instance hashcode:418873098, Value:0123
Thread name:thread - 2 , ThreadLocal hashcode:372282300, Instance hashcode:1780437710, Value:0123
Set, Thread name:thread - 1 , ThreadLocal hashcode:372282300, Instance hashcode:482932940, Value:hello world
Set, Thread name:thread - 2 , ThreadLocal hashcode:372282300, Instance hashcode:1691922941, Value:hello world
从上面的输出可看出
- 从第1-3行输出可见,每个线程通过 ThreadLocal 的 get() 方法拿到的是不同的 StringBuilder 实例
- 第1-3行输出表明,每个线程所访问到的是同一个 ThreadLocal 变量
- 从7、12、13行输出以及第30行代码可见,虽然从代码上都是对 Counter 类的静态 counter 字段进行 get() 得到 StringBuilder 实例并追加字符串,但是这并不会将所有线程追加的字符串都放进同一个 StringBuilder 中,而是每个线程将字符串追加进各自的 StringBuidler 实例内
- 对比第1行与第15行输出并结合第38行代码可知,使用 set(T t) 方法后,ThreadLocal 变量所指向的 StringBuilder 实例被替换
参考:
Java进阶(七)正确理解Thread Local的原理与适用场景
12.3 ThreadLocal原理
ThreadLocal的常用方法
public T get() { }
public void set(T value) { }
public void remove() { }
protected T initialValue() { }
get()方法是用来获取ThreadLocal在当前线程中保存的变量副本
set()用来设置当前线程中变量的副本
remove()用来移除当前线程中变量的副本
initialValue()是一个protected方法,一般是用来在使用时进行重写的,它是一个延迟加载方法,下面会详细说明。
ThreadLocal为每个线程创建了共享变量的副本,要弄清原理,只要弄清楚一个线程是如何关联到一个共享变量的副本。
首先看下get方法的实现
/**
* 返回当前线本地变量的拷贝,如果没有改变量,它会调用initialValue方法进行第一次初始化
*/
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
第一句获得当前线程对象,然后调用getMap()方法,将线程对象以函参的形式传入其中,获取到ThreadLocalMap对象,如果不为空则通过调用map对象的getEntry()方法,将当前ThreadLocal对象传入,返回Entry对象,不为空则返回具体的值;如果map为空,则通过setInitialValue();初始化。
在getMap(Thread t)方法,直接返回了一个Thread对象中的threadLocals属性,在Thread源码中定义着一个这样的属性
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}

它保留了ThreadLocal.ThreadLocalMap类型的一个实例,ThreadLocal.ThreadLocalMap具体是ThreadLocal下的一个静态内部类,其中又定义了Entry这个key-value结构的对象,注意,key是以ThreadLocal为值。
static class ThreadLocalMap {
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
....
/**
* Construct a new map initially containing (firstKey, firstValue).
* ThreadLocalMaps are constructed lazily, so we only create
* one when we have at least one entry to put in it.
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
}
再看一下setInitialValue()方法
private T setInitialValue() {
T value = initialValue();// 默认返回null
Thread t = Thread.currentThread();
// getMap就是上面介绍过的getMap
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
protected T initialValue() {
return null;
}
void createMap(Thread t, T firstValue) {
// 实例化一个ThreadLocalMap对象并将当前threadLocal和值作为参数
// 将引用赋值给当前线程的threadLocals属性
t.threadLocals属性 = new ThreadLocalMap(this, firstValue);
}
// 和setInitialvalue方法内部大致差不多
// 只不过这里的value是真实的值,并不是默认的null
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
运行流程:
首先,在每个线程Thread内部有一个ThreadLocal.ThreadLocalMap类型的成员变量threadLocals,这个threadLocals就是用来存储实际的变量副本的。在调用threadLocal对象的set方法时,将当前ThreadLocal变量作为键值,value为变量副本保存如其中。(即T类型的变量)。
初始时,在Thread里面,threadLocals为空,当通过ThreadLocal变量调用get()方法或者set()方法,就会对Thread类中的threadLocals进行初始化,并且以当前ThreadLocal变量为键值,以ThreadLocal要保存的副本变量为value,存到threadLocals。然后在当前线程里面,如果要使用副本变量,就可以通过get方法在threadLocals里面查找。
get流程:getMap(curThread)->curThread.localMap->getEntry(curThreadLocal)->localVariables
总结一下:
1)实际的通过ThreadLocal创建的副本是存储在每个线程自己的threadLocals中的;
2)为何threadLocals的类型ThreadLocalMap的键值为ThreadLocal对象,因为每个线程中可有多个threadLocal变量;
3)在进行get之前,必须先set,否则会报空指针异常;
如果想在get之前不需要调用set就能正常访问的话,必须重写initialValue()方法。
因为在上面的代码分析过程中,我们发现如果没有先set的话,即在map中查找不到对应的存储,则会通过调用setInitialValue方法返回i,而在setInitialValue方法中,有一个语句是T value = initialValue(), 而默认情况下,initialValue方法返回的是null。
前面我们已经看到在没有set之前调用get返回的对象是null的,虽然其中调用了initialValue(initialValue也是默认返回null),所以下面的代码就会产生空指针异常
public class ThreadLocalDemo {
ThreadLocal<Long> longLocal = new ThreadLocal<Long>();
ThreadLocal<String> stringLocal = new ThreadLocal<String>();
public void set() {
longLocal.set(Thread.currentThread().getId());
stringLocal.set(Thread.currentThread().getName());
}
public long getLong() {
return longLocal.get();
}
public String getString() {
return stringLocal.get();
}
public static void main(String[] args) throws InterruptedException {
final ThreadLocalDemo test = new ThreadLocalDemo();
System.out.println(test.getLong());
System.out.println(test.getString());
Thread thread1 = new Thread(() -> {
test.set();
System.out.println(test.getLong());
System.out.println(test.getString());
});
thread1.start();
thread1.join();
System.out.println(test.getLong());
System.out.println(test.getString());
}
}
更改代码为如下,就可以不用先set而直接调用get了。
ThreadLocal<Long> longLocal = new ThreadLocal<Long>() {
@Override
protected Long initialValue() {
return Thread.currentThread().getId();
}
};
ThreadLocal<String> stringLocal = new ThreadLocal<String>() {
@Override
protected String initialValue() {
return Thread.currentThread().getName();
}
};

 浙公网安备 33010602011771号
浙公网安备 33010602011771号