

利用kubeadm部署Kubernetes v1.22.10高可用集群
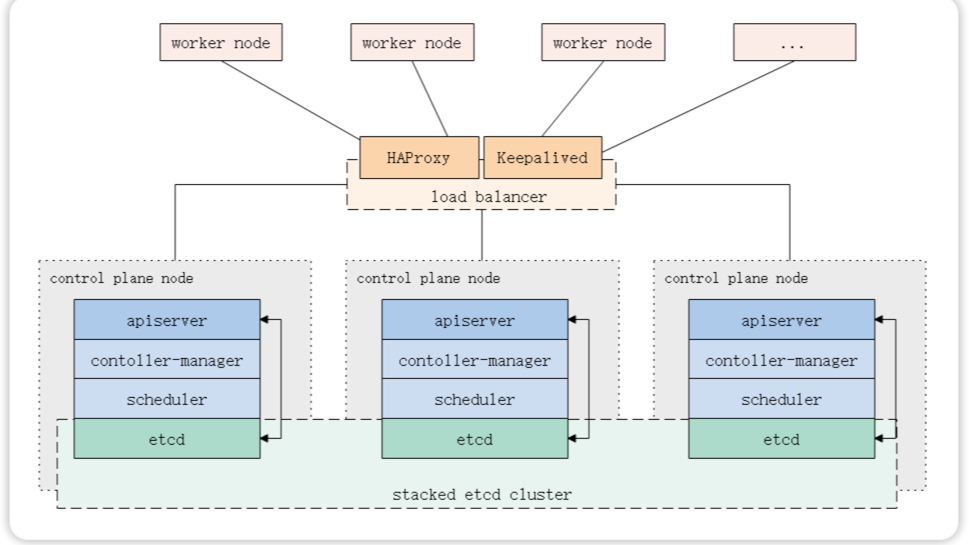 本文讲述如何利用Haproxy+Keepalived将服务作为静态pod运行的方式部署一套高可用的Kubernetes集群。
本文讲述如何利用Haproxy+Keepalived将服务作为静态pod运行的方式部署一套高可用的Kubernetes集群。
一、概述
Kubernetes集群控制平面(Master)节点右数据库服务(Etcd)+其它服务组件(Apiserver、Controller-manager、Scheduler等)组成;整个集群系统运行的交互数据都将存储到数据库服务(Etcd)中,所以Kubernetes集群的高可用性取决于数据库服务(Etcd)在多个控制平面(Master)节点构建的数据同步复制关系。由此搭建Kubernetes的高可用集群可以选择以下两种部署方式:
- 使用堆叠的控制平面(Master)节点,其中etcd与组成控制平面的其他组件在同台机器上;
- 使用外部Etcd节点,其中Etcd与控制平台的其他组件在不同的机器上。
参考文档:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/high-availability/
1.1 堆叠Etcd拓扑(推荐)
Etcd与其他组件共同运行在多台控制平面(Master)机器上,构建Etcd集群关系以形成高可用的Kubernetes集群。
先决条件:
- 最少三个或更多奇数Master节点;
- 最少三个或更多Node节点;
- 集群中所有机器之间的完整网络连接(公共或专用网络);
- 使用超级用户权限;
- 在集群中的任何一个节点上都可以使用SSH远程访问;
- Kubeadm和Kubelet已经安装到机器上。
使用这种方案可以减少要使用机器的数量,降低成本,降低部署复杂度;多组件服务之间竞争主机资源,可能导致性能瓶颈,以及当Master主机发生故障时影响到所有组件正常工作。
在实际应用中,你可以选择部署更多数量>3的Master主机,则该拓扑的劣势将会减弱!
这是kubeadm中的默认拓扑,kubeadm会在Master节点上自动创建本地etcd成员。
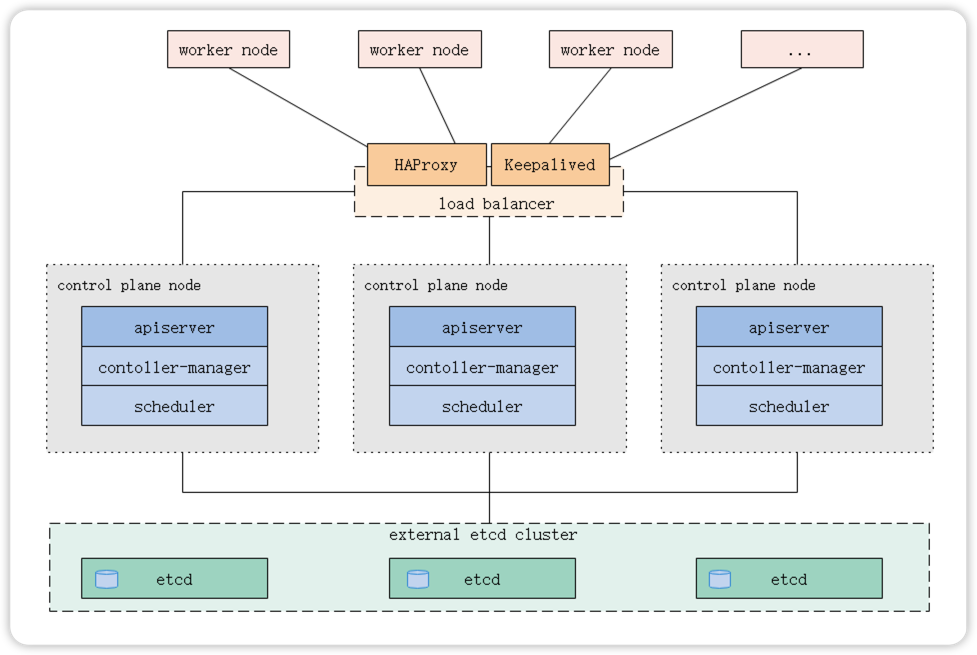
1.2 外部Etcd拓扑
控制平面的Etcd组件运行在外部主机上,其他组件连接到外部的Etcd集群以形成高可用的Kubernetes集群。
先决条件:
- 最少三个或更多奇数Master主机;
- 最少三个或更多Node主机;
- 还需要三台或更多奇数Etcd主机。
- 集群中所有主机之间的完整网络连接(公共或专用网络);
- 使用超级用户权限;
- 在集群中的任何一个节点主机上都可以使用SSH远程访问;
- Kubeadm和Kubelet已经安装到机器上。
使用外部主机搭建起来的Etcd集群,拥有更多的主机资源和可扩展性,以及故障影响范围缩小,但更多的机器将导致增加部署成本。
二、部署规划
主机系统:CentOS Linux release 7.7.1908 (Core)
Kubernetes版本:1.22.10
Docker CE版本:20.10.17
管理节点运行服务:etcd、kube-apiserver、kube-scheduler、kube-controller-manager、docker、kubelet、keepalived、haproxy
管理节点配置:4vCPU / 8GB内存 / 200G存储
|
主机名 |
主机地址 |
VIP地址 |
主机角色 |
|
k8s-master01 |
192.168.0.5 |
192.168.0.10 |
Master(Control Plane) |
|
k8s-master02 |
192.168.0.6 |
Master(Control Plane) |
|
|
k8s-master03 |
192.168.0.7 |
Master(Control Plane) |
注:确保服务器为全新安装的系统,未安装其它软件仅用于Kubernetes运行。
可使用如下命令检查端口是否被占用:
ss -alnupt |grep -E '6443|10250|10259|10257|2379|2380' ss -alnupt |grep -E '10250|3[0-2][0-7][0-6][0-7]'
三、搭建Kubernetes集群
3.1 内核升级(可选)
CentOS 7.x 版本的系统默认内核是3.10,该版本的内核在Kubernetes社区有很多已知的Bug(如:内核内存泄漏错误),建议升级成4.17+版本以上。
官方镜像仓库下载地址:http://mirrors.coreix.net/elrepo-archive-archive/kernel/el7/x86_64/RPMS/
# 安装4.19.9-1版本内核 $ rpm -ivh http://mirrors.coreix.net/elrepo-archive-archive/kernel/el7/x86_64/RPMS/kernel-ml-4.19.9-1.el7.elrepo.x86_64.rpm $ rpm -ivh http://mirrors.coreix.net/elrepo-archive-archive/kernel/el7/x86_64/RPMS/kernel-ml-devel-4.19.9-1.el7.elrepo.x86_64.rpm # 查看内核启动顺序 $ awk -F \' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg 0 : CentOS Linux (3.10.0-1062.12.1.el7.x86_64) 7 (Core) 1 : CentOS Linux (4.19.9-1.el7.elrepo.x86_64) 7 (Core) 2 : CentOS Linux (3.10.0-862.el7.x86_64) 7 (Core) 3 : CentOS Linux (0-rescue-ef219b153e8049718c374985be33c24e) 7 (Core) # 设置系统启动默认内核 $ grub2-set-default "CentOS Linux (4.19.9-1.el7.elrepo.x86_64) 7 (Core)" $ grub2-mkconfig -o /boot/grub2/grub.cfg # 查看默认内核 $ grub2-editenv list CentOS Linux (4.19.9-1.el7.elrepo.x86_64) 7 (Core) # 重启系统使其生效 $ reboot
3.2 系统初始化
3.2.1 设置主机名
### 在master01上执行 $ hostnamectl set-hostname k8s-master01 # 在master02上执行 $ hostnamectl set-hostname k8s-master02 # 在master03上执行 $ hostnamectl set-hostname k8s-master03
3.2.2 添加hosts名称解析
### 在所有主机上执行 $ cat >> /etc/hosts << EOF 192.168.0.5 k8s-master01 192.168.0.6 k8s-master02 192.168.0.7 k8s-master03 EOF
3.2.3 安装常用软件
### 在所有主机上执行 $ yum -y install epel-release.noarch nfs-utils net-tools bridge-utils \ ntpdate vim chrony wget lrzsz
3.2.4 设置主机时间同步
在k8s-master01上设置从公共时间服务器上同步时间
[root@k8s-master01 ~]# systemctl stop ntpd [root@k8s-master01 ~]# timedatectl set-timezone Asia/Shanghai [root@k8s-master01 ~]# ntpdate ntp.aliyun.com && /usr/sbin/hwclock [root@k8s-master01 ~]# vim /etc/ntp.conf # 当该节点丢失网络连接,采用本地时间作为时间服务器为集群中的其他节点提供时间同步 server 127.127.1.0 Fudge 127.127.1.0 stratum 10 # 注释掉默认时间服务器,改为如下地址 server cn.ntp.org.cn prefer iburst minpoll 4 maxpoll 10 server ntp.aliyun.com iburst minpoll 4 maxpoll 10 server time.ustc.edu.cn iburst minpoll 4 maxpoll 10 server ntp.tuna.tsinghua.edu.cn iburst minpoll 4 maxpoll 10 [root@k8s-master01 ~]# systemctl start ntpd [root@k8s-master01 ~]# systemctl enable ntpd [root@k8s-master01 ~]# ntpstat synchronised to NTP server (203.107.6.88) at stratum 3 time correct to within 202 ms polling server every 64 s
配置其它主机从k8s-master01同步时间
### 在除k8s-master01以外的所有主机上执行 $ systemctl stop ntpd $ timedatectl set-timezone Asia/Shanghai $ ntpdate k8s-master01 && /usr/sbin/hwclock $ vim /etc/ntp.conf # 注释掉默认时间服务器,改为如下地址 server k8s-master01 prefer iburst minpoll 4 maxpoll 10 $ systemctl start ntpd $ systemctl enable ntpd $ ntpstat synchronised to NTP server (192.168.0.5) at stratum 4 time correct to within 217 ms polling server every 16 s
3.2.5 关闭防火墙
### 在所有节点上执行 # 关闭SElinux $ sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config $ setenforce 0 # 关闭Fileworld防火墙 $ systemctl stop firewalld.service $ systemctl disable firewalld.service
3.2.6 系统优化
### 在所有节点上执行 # 关闭swap $ swapoff -a $ sed -i "s/^[^#].*swap/#&/g" /etc/fstab # 启用bridge-nf功能 $ cat > /etc/modules-load.d/k8s.conf << EOF overlay br_netfilter EOF $ modprobe overlay && modprobe br_netfilter # 设置内核参数 $ cat > /etc/sysctl.d/k8s.conf << EOF # 配置转发 IPv4 并让 iptables 看到桥接流量 net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 # 加强握手队列能力 net.ipv4.tcp_max_syn_backlog = 10240 net.core.somaxconn = 10240 net.ipv4.tcp_syncookies = 1 # 调整系统级别的能够打开的文件句柄的数量 fs.file-max=1000000 # 配置arp cache 大小 net.ipv4.neigh.default.gc_thresh1 = 1024 net.ipv4.neigh.default.gc_thresh2 = 4096 net.ipv4.neigh.default.gc_thresh3 = 8192 # 令TCP窗口和状态追踪更加宽松 net.netfilter.nf_conntrack_tcp_be_liberal = 1 net.netfilter.nf_conntrack_tcp_loose = 1 # 允许的最大跟踪连接条目,是在内核内存中netfilter可以同时处理的“任务”(连接跟踪条目) net.netfilter.nf_conntrack_max = 10485760 net.netfilter.nf_conntrack_tcp_timeout_established = 300 net.netfilter.nf_conntrack_buckets = 655360 # 每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。 net.core.netdev_max_backlog = 10000 # 默认值: 128 指定了每一个real user ID可创建的inotify instatnces的数量上限 fs.inotify.max_user_instances = 524288 # 默认值: 8192 指定了每个inotify instance相关联的watches的上限 fs.inotify.max_user_watches = 524288 EOF $ sysctl --system # 修改文件打开数 $ ulimit -n 65545 $ cat >> /etc/security/limits.conf << EOF * soft nproc 65535 * hard nproc 65535 * soft nofile 65535 * hard nofile 65535 EOF $ sed -i '/nproc/ s/4096/65535/' /etc/security/limits.d/20-nproc.conf
3.3 安装Docker
### 在所有节点上执行 # 安装Docker $ yum install -y yum-utils device-mapper-persistent-data lvm2 $ yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo $ sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo && yum makecache fast $ yum -y install docker-ce-20.10.17 # 优化docker配置 $ mkdir -p /etc/docker && cat > /etc/docker/daemon.json <<EOF { "registry-mirrors": [ "https://hub-mirror.c.163.coma", "https://docker.mirrors.ustc.edu.cn", "https://p6902cz5.mirror.aliyuncs.com" ], "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2", "storage-opts": [ "overlay2.override_kernel_check=true" ], "bip": "172.38.16.1/24" } EOF # 启动并配置开机自启 $ systemctl enable docker $ systemctl restart docker $ docker version
3.4 安装Kubernetes
### 在所有Master节点执行 # 配置yum源 cat > /etc/yum.repos.d/kubernetes.repo <<EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF # 安装kubeadm、kubelet和kubectl $ yum install -y kubelet-1.22.10 kubeadm-1.22.10 kubectl-1.22.10 --disableexcludes=kubernetes --nogpgcheck $ systemctl enable --now kubelet # 配置kubelet参数 $ cat > /etc/sysconfig/kubelet <<EOF KUBELET_EXTRA_ARGS="--fail-swap-on=false" EOF
可以参考:https://www.yuque.com/wubolive/ops/ugomse 修改kubeadm源码更改证书签发时长。
3.5 配置HA负载均衡
当存在多个控制平面时,kube-apiserver也存在多个,可以使用HAProxy+Keepalived这个组合,因为HAProxy可以提高更高性能的四层负载均衡功能。
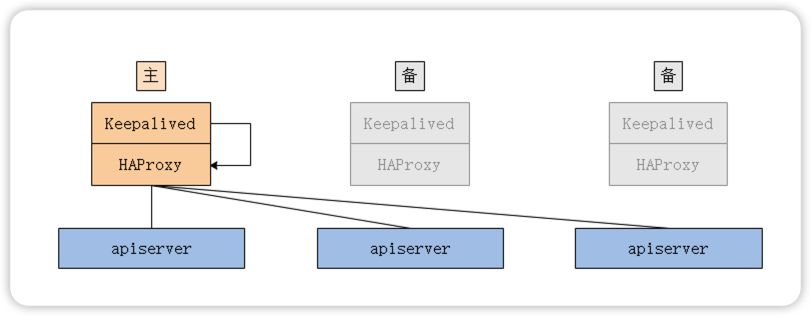
官方文档提供了两种运行方式(此案例使用选项2):
- 选项1:在操作系统上运行服务
- 选项2:将服务作为静态pod运行
3.5.1 配置keepalived
将keepalived作为静态pod运行,在引导过程中,kubelet将启动这些进程,以便集群可以在启动时使用它们。这是一个优雅的解决方案,特别是在堆叠(Stacked)etcd 拓扑下描述的设置。
创建keepalived.conf配置文件
### 在k8s-master01上设置: $ mkdir /etc/keepalived && cat > /etc/keepalived/keepalived.conf <<EOF ! /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id k8s-master01 } vrrp_script check_apiserver { script "/etc/keepalived/check_apiserver.sh" interval 3 weight -2 fall 10 rise 2 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 192.168.0.10 } track_script { check_apiserver } } EOF ### 在k8s-master02上设置: $ mkdir /etc/keepalived && cat > /etc/keepalived/keepalived.conf <<EOF ! /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id k8s-master02 } vrrp_script check_apiserver { script "/etc/keepalived/check_apiserver.sh" interval 3 weight -2 fall 10 rise 2 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 99 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 192.168.0.10 } track_script { check_apiserver } } EOF ### 在k8s-master03上设置: $ mkdir /etc/keepalived && cat > /etc/keepalived/keepalived.conf <<EOF ! /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id k8s-master03 } vrrp_script check_apiserver { script "/etc/keepalived/check_apiserver.sh" interval 3 weight -2 fall 10 rise 2 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 98 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 192.168.0.10 } track_script { check_apiserver } } EOF
创建健康检查脚本
### 在所有Master控制节点上执行 $ cat > /etc/keepalived/check_apiserver.sh << 'EOF' #!/bin/sh errorExit() { echo "*** $*" 1>&2 exit 1 } curl --silent --max-time 2 --insecure https://localhost:9443/ -o /dev/null || errorExit "Error GET https://localhost:9443/" if ip addr | grep -q 192.168.0.10; then curl --silent --max-time 2 --insecure https://192.168.0.10:9443/ -o /dev/null || errorExit "Error GET https://192.168.0.10:9443/" fi EOF
3.5.2 配置haproxy
### 在所有Master管理节点执行 $ mkdir /etc/haproxy && cat > /etc/haproxy/haproxy.cfg << 'EOF' # /etc/haproxy/haproxy.cfg #--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global log /dev/log local0 log /dev/log local1 notice daemon #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 1 timeout http-request 10s timeout queue 20s timeout connect 5s timeout client 20s timeout server 20s timeout http-keep-alive 10s timeout check 10s #--------------------------------------------------------------------- # Haproxy Monitoring panel #--------------------------------------------------------------------- listen admin_status bind 0.0.0.0:8888 mode http log 127.0.0.1 local3 err stats refresh 5s stats uri /admin?stats stats realm itnihao\ welcome stats auth admin:admin stats hide-version stats admin if TRUE #--------------------------------------------------------------------- # apiserver frontend which proxys to the control plane nodes #--------------------------------------------------------------------- frontend apiserver bind *:9443 mode tcp option tcplog default_backend apiserver #--------------------------------------------------------------------- # round robin balancing for apiserver #--------------------------------------------------------------------- backend apiserver option httpchk GET /healthz http-check expect status 200 mode tcp option ssl-hello-chk balance roundrobin server k8s-master01 192.168.0.5:6443 check server k8s-master02 192.168.0.6:6443 check server k8s-master03 192.168.0.7:6443 check EOF
3.5.3 配置静态Pod运行
对于此设置,需要在其中创建两个清单文件/etc/kubernetes/manifests(首先创建目录)。
### 仅在k8s-master01上创建 $ mkdir -p /etc/kubernetes/manifests # 配置keepalived清单 $ cat > /etc/kubernetes/manifests/keepalived.yaml << 'EOF' apiVersion: v1 kind: Pod metadata: creationTimestamp: null name: keepalived namespace: kube-system spec: containers: - image: osixia/keepalived:2.0.17 name: keepalived resources: {} securityContext: capabilities: add: - NET_ADMIN - NET_BROADCAST - NET_RAW volumeMounts: - mountPath: /usr/local/etc/keepalived/keepalived.conf name: config - mountPath: /etc/keepalived/check_apiserver.sh name: check hostNetwork: true volumes: - hostPath: path: /etc/keepalived/keepalived.conf name: config - hostPath: path: /etc/keepalived/check_apiserver.sh name: check status: {} EOF # 配置haproxy清单 cat > /etc/kubernetes/manifests/haproxy.yaml << 'EOF' apiVersion: v1 kind: Pod metadata: name: haproxy namespace: kube-system spec: containers: - image: haproxy:2.1.4 name: haproxy livenessProbe: failureThreshold: 8 httpGet: host: localhost path: /healthz port: 9443 scheme: HTTPS volumeMounts: - mountPath: /usr/local/etc/haproxy/haproxy.cfg name: haproxyconf readOnly: true hostNetwork: true volumes: - hostPath: path: /etc/haproxy/haproxy.cfg type: FileOrCreate name: haproxyconf status: {} EOF
3.6 部署Kubernetes集群
3.6.1 准备镜像
由于国内访问k8s.gcr.io存在某些原因下载不了镜像,所以我们可以在国内的镜像仓库中下载它们(比如使用阿里云镜像仓库。阿里云代理镜像仓库地址:registry.aliyuncs.com/google_containers
### 在所有Master控制节点执行 $ kubeadm config images pull --kubernetes-version=v1.22.10 --image-repository=registry.aliyuncs.com/google_containers
3.6.2 准备ini配置文件
### 在k8s-master01上执行 $ kubeadm config print init-defaults > kubeadm-init.yaml $ vim kubeadm-init.yaml apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168.0.5 bindPort: 6443 nodeRegistration: criSocket: /var/run/dockershim.sock imagePullPolicy: IfNotPresent name: k8s-master01 taints: null --- controlPlaneEndpoint: "192.168.0.10:9443" apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: 1.22.10 networking: dnsDomain: cluster.local serviceSubnet: 10.96.0.0/12 scheduler: {}
配置说明:
localAPIEndpoint.advertiseAddress:本机apiserver监听的IP地址。localAPIEndpoint.bindPort:本机apiserver监听的端口。controlPlaneEndpoint:控制平面入口点地址(负载均衡器VIP地址+负载均衡器端口)。imageRepository:部署集群时要使用的镜像仓库地址。kubernetesVersion:部署集群的kubernetes版本。
3.6.3 初始化控制平面节点
kubeadm在初始化控制平面时会生成部署Kubernetes集群中各个组件所需的相关配置文件在/etc/kubernetes目录下,可以供我们参考。
### 在k8s-master01上执行 # 由于kubeadm命令为源码安装,需要配置一下kubelet服务。 $ kubeadm init phase kubelet-start --config kubeadm-init.yaml # 初始化kubernetes控制平面 $ kubeadm init --config kubeadm-init.yaml --upload-certs Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 192.168.0.10:9443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:b30e986e80423da7b6b1cbf43ece58598074b2a8b86295517438942e9a47ab0d \ --control-plane --certificate-key 57360054608fa9978864124f3195bc632454be4968b5ccb577f7bb9111d96597 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.0.10:9443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:b30e986e80423da7b6b1cbf43ece58598074b2a8b86295517438942e9a47ab0d
3.6.4 将其它节点加入集群
将控制平面节点加入集群
### 在另外两台Master控制节点执行: $ kubeadm join 192.168.0.10:9443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:b30e986e80423da7b6b1cbf43ece58598074b2a8b86295517438942e9a47ab0d \ --control-plane --certificate-key 57360054608fa9978864124f3195bc632454be4968b5ccb577f7bb9111d96597
将工作节点加入集群(可选)
### 如有Node工作节点可使用如下命令 $ kubeadm join 192.168.0.10:9443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:b30e986e80423da7b6b1cbf43ece58598074b2a8b86295517438942e9a47ab0d
将keepalived和haproxy复制到其它Master控制节点
$ scp /etc/kubernetes/manifests/{haproxy.yaml,keepalived.yaml} root@k8s-master02:/etc/kubernetes/manifests/ $ scp /etc/kubernetes/manifests/{haproxy.yaml,keepalived.yaml} root@k8s-master03:/etc/kubernetes/manifests/
去掉master污点(可选)
$ kubectl taint nodes --all node-role.kubernetes.io/master-
3.6.5 验证集群状态
### 可在任意Master控制节点执行 # 配置kubectl认证 $ mkdir -p $HOME/.kube $ cp -i /etc/kubernetes/admin.conf $HOME/.kube/config # 查看节点状态 $ kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master01 NotReady control-plane,master 13m v1.22.10 k8s-master02 NotReady control-plane,master 3m55s v1.22.10 k8s-master03 NotReady control-plane,master 113s v1.22.10 # 查看pod状态 $ kubectl get pod -n kube-system NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-7f6cbbb7b8-96hp9 0/1 Pending 0 18m kube-system coredns-7f6cbbb7b8-kfmnn 0/1 Pending 0 18m kube-system etcd-k8s-master01 1/1 Running 0 18m kube-system etcd-k8s-master02 1/1 Running 0 9m21s kube-system etcd-k8s-master03 1/1 Running 0 7m18s kube-system haproxy-k8s-master01 1/1 Running 0 18m kube-system haproxy-k8s-master02 1/1 Running 0 3m27s kube-system haproxy-k8s-master03 1/1 Running 0 3m16s kube-system keepalived-k8s-master01 1/1 Running 0 18m kube-system keepalived-k8s-master02 1/1 Running 0 3m27s kube-system keepalived-k8s-master03 1/1 Running 0 3m16s kube-system kube-apiserver-k8s-master01 1/1 Running 0 18m kube-system kube-apiserver-k8s-master02 1/1 Running 0 9m24s kube-system kube-apiserver-k8s-master03 1/1 Running 0 7m23s kube-system kube-controller-manager-k8s-master01 1/1 Running 0 18m kube-system kube-controller-manager-k8s-master02 1/1 Running 0 9m24s kube-system kube-controller-manager-k8s-master03 1/1 Running 0 7m22s kube-system kube-proxy-cvdlr 1/1 Running 0 7m23s kube-system kube-proxy-gnl7t 1/1 Running 0 9m25s kube-system kube-proxy-xnrt7 1/1 Running 0 18m kube-system kube-scheduler-k8s-master01 1/1 Running 0 18m kube-system kube-scheduler-k8s-master02 1/1 Running 0 9m24s kube-system kube-scheduler-k8s-master03 1/1 Running 0 7m22s # 查看kubernetes证书有效期 $ kubeadm certs check-expiration CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED admin.conf Oct 25, 2122 07:40 UTC 99y ca no apiserver Oct 25, 2122 07:40 UTC 99y ca no apiserver-etcd-client Oct 25, 2122 07:40 UTC 99y etcd-ca no apiserver-kubelet-client Oct 25, 2122 07:40 UTC 99y ca no controller-manager.conf Oct 25, 2122 07:40 UTC 99y ca no etcd-healthcheck-client Oct 25, 2122 07:40 UTC 99y etcd-ca no etcd-peer Oct 25, 2122 07:40 UTC 99y etcd-ca no etcd-server Oct 25, 2122 07:40 UTC 99y etcd-ca no front-proxy-client Oct 25, 2122 07:40 UTC 99y front-proxy-ca no scheduler.conf Oct 25, 2122 07:40 UTC 99y ca no CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED ca Oct 22, 2032 07:40 UTC 99y no etcd-ca Oct 22, 2032 07:40 UTC 99y no front-proxy-ca Oct 22, 2032 07:40 UTC 99y no
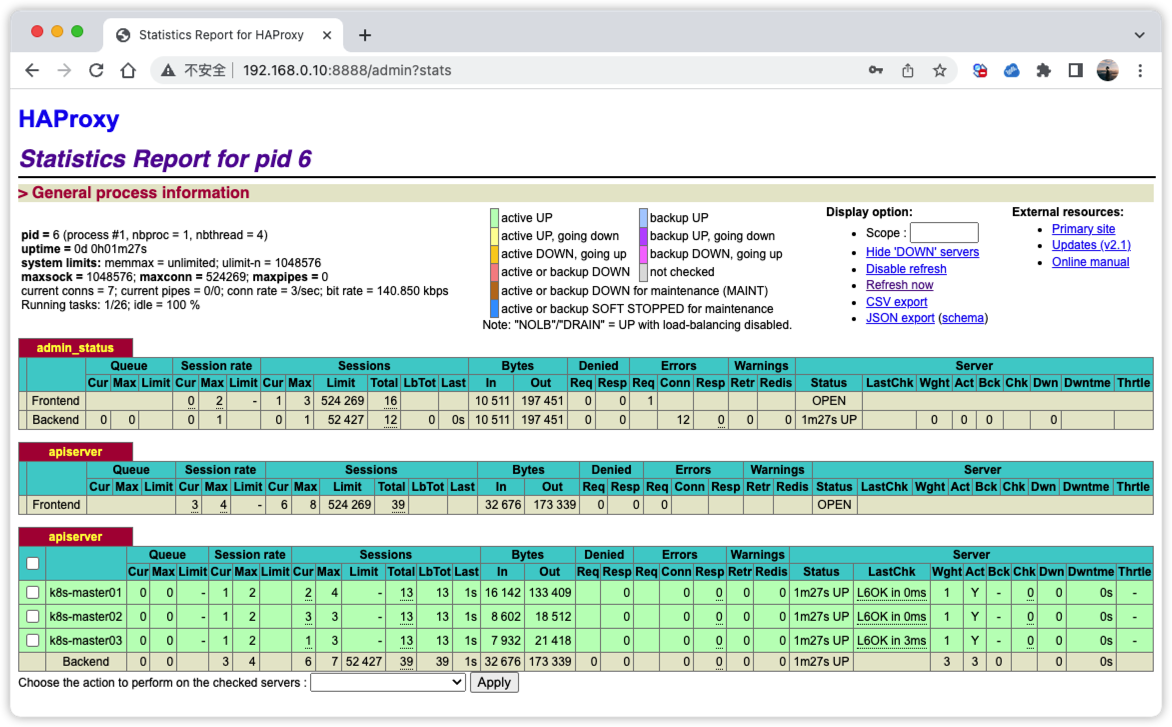
查看HAProxy控制台集群状态
访问:http://192.168.0.10:8888/admin?stats 账号密码都为admin
3.6.6 安装CNA插件(calico)
Calico是一个开源的虚拟化网络方案,支持基础的Pod网络通信和网络策略功能。
官方文档:https://projectcalico.docs.tigera.io/getting-started/kubernetes/quickstart
### 在任意Master控制节点执行 # 下载最新版本编排文件 $ kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml # 下载指定版本编排文件(可选) $ curl https://raw.githubusercontent.com/projectcalico/calico/v3.24.0/manifests/calico.yaml -O # 部署calico $ kubectl apply -f calico.yaml # 验证安装 $ kubectl get pod -n kube-system | grep calico calico-kube-controllers-86c9c65c67-j7pv4 1/1 Running 0 17m calico-node-8mzpk 1/1 Running 0 17m calico-node-tkzs2 1/1 Running 0 17m calico-node-xbwvp 1/1 Running 0 17m
四、集群优化及组件安装
4.1 集群优化
4.1.1 修改NodePort端口范围(可选)
### 在所有Master管理节点执行 $ sed -i '/- --secure-port=6443/a\ - --service-node-port-range=1-32767' /etc/kubernetes/manifests/kube-apiserver.yaml
4.1.2 解决kubectl get cs显示异常问题
### 在所有Master管理节点执行 $ sed -i 's/^[^#].*--port=0$/#&/g' /etc/kubernetes/manifests/{kube-scheduler.yaml,kube-controller-manager.yaml} # 验证 $ kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true","reason":""}
4.1.3 解决调度器监控不显示问题
### 在所有Master管理节点执行 $ sed -i 's#bind-address=127.0.0.1#bind-address=0.0.0.0#g' /etc/kubernetes/manifests/kube-controller-manager.yaml $ sed -i 's#bind-address=127.0.0.1#bind-address=0.0.0.0#g' /etc/kubernetes/manifests/kube-scheduler.yaml
4.2 安装Metric-Server
指标服务Metrices-Server是Kubernetes中的一个常用插件,它类似于Top命令,可以查看Kubernetes中Node和Pod的CPU和内存资源使用情况。Metrices-Server每15秒收集一次指标,它在集群中的每个节点中运行,可扩展支持多达5000个节点的集群。
参考文档:https://github.com/kubernetes-sigs/metrics-server
### 在任意Master管理节点执行 $ wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml -O metrics-server.yaml # 修改配置 $ vim metrics-server.yaml ...... spec: containers: - args: - --cert-dir=/tmp - --secure-port=4443 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port - --metric-resolution=15s - --kubelet-insecure-tls # 不要验证由Kubelets提供的CA或服务证书。 image: bitnami/metrics-server:0.6.1 # 修改成docker.io镜像 imagePullPolicy: IfNotPresent ...... # 部署metrics-server $ kubectl apply -f metrics-server.yaml # 查看启动状态 $ kubectl get pod -n kube-system -l k8s-app=metrics-server -w NAME READY STATUS RESTARTS AGE metrics-server-655d65c95-lvb7z 1/1 Running 0 103s # 查看集群资源状态 $ kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master01 193m 4% 2144Mi 27% k8s-master02 189m 4% 1858Mi 23% k8s-master03 268m 6% 1934Mi 24%
五、附录
5.1 重置节点(危险操作)
当在使用kubeadm init或kubeadm join部署节点出现失败状况时,可以使用以下操作对节点进行重置!
注:重置会将节点恢复到未部署前状态,若集群已正常工作则无需重置,否则将引起不可恢复的集群故障!
$ kubeadm reset -f $ ipvsadm --clear $ iptables -F && iptables -X && iptables -Z
5.2 常用查询命令
# 查看Token列表 $ kubeadm token list TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS abcdef.0123456789abcdef 22h 2022-10-26T07:43:01Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token jgqg88.6mskuadei41o0s2d 40m 2022-10-25T09:43:01Z <none> Proxy for managing TTL for the kubeadm-certs secret <none> # 查询节点运行状态 $ kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master01 Ready control-plane,master 81m v1.22.10 k8s-master02 Ready control-plane,master 71m v1.22.10 k8s-master03 Ready control-plane,master 69m v1.22.10 # 查看证书到期时间 $ kubeadm certs check-expiration CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED admin.conf Oct 25, 2122 07:40 UTC 99y ca no apiserver Oct 25, 2122 07:40 UTC 99y ca no apiserver-etcd-client Oct 25, 2122 07:40 UTC 99y etcd-ca no apiserver-kubelet-client Oct 25, 2122 07:40 UTC 99y ca no controller-manager.conf Oct 25, 2122 07:40 UTC 99y ca no etcd-healthcheck-client Oct 25, 2122 07:40 UTC 99y etcd-ca no etcd-peer Oct 25, 2122 07:40 UTC 99y etcd-ca no etcd-server Oct 25, 2122 07:40 UTC 99y etcd-ca no front-proxy-client Oct 25, 2122 07:40 UTC 99y front-proxy-ca no scheduler.conf Oct 25, 2122 07:40 UTC 99y ca no CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED ca Oct 22, 2032 07:40 UTC 99y no etcd-ca Oct 22, 2032 07:40 UTC 99y no front-proxy-ca Oct 22, 2032 07:40 UTC 99y no # 查看kubeadm初始化控制平面配置信息 $ kubeadm config print init-defaults apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 1.2.3.4 bindPort: 6443 nodeRegistration: criSocket: /var/run/dockershim.sock imagePullPolicy: IfNotPresent name: node taints: null --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: k8s.gcr.io kind: ClusterConfiguration kubernetesVersion: 1.22.0 networking: dnsDomain: cluster.local serviceSubnet: 10.96.0.0/12 scheduler: {} # 查看kube-system空间Pod运行状态 $ kubectl get pod --namespace=kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-86c9c65c67-j7pv4 1/1 Running 0 47m calico-node-8mzpk 1/1 Running 0 47m calico-node-tkzs2 1/1 Running 0 47m calico-node-xbwvp 1/1 Running 0 47m coredns-7f6cbbb7b8-96hp9 1/1 Running 0 82m coredns-7f6cbbb7b8-kfmnn 1/1 Running 0 82m etcd-k8s-master01 1/1 Running 0 82m etcd-k8s-master02 1/1 Running 0 72m etcd-k8s-master03 1/1 Running 0 70m haproxy-k8s-master01 1/1 Running 0 36m haproxy-k8s-master02 1/1 Running 0 67m haproxy-k8s-master03 1/1 Running 0 66m keepalived-k8s-master01 1/1 Running 0 82m keepalived-k8s-master02 1/1 Running 0 67m keepalived-k8s-master03 1/1 Running 0 66m kube-apiserver-k8s-master01 1/1 Running 0 82m kube-apiserver-k8s-master02 1/1 Running 0 72m kube-apiserver-k8s-master03 1/1 Running 0 70m kube-controller-manager-k8s-master01 1/1 Running 0 23m kube-controller-manager-k8s-master02 1/1 Running 0 23m kube-controller-manager-k8s-master03 1/1 Running 0 23m kube-proxy-cvdlr 1/1 Running 0 70m kube-proxy-gnl7t 1/1 Running 0 72m kube-proxy-xnrt7 1/1 Running 0 82m kube-scheduler-k8s-master01 1/1 Running 0 23m kube-scheduler-k8s-master02 1/1 Running 0 23m kube-scheduler-k8s-master03 1/1 Running 0 23m metrics-server-5786d84b7c-5v4rv 1/1 Running 0 8m38s


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!