MySQL的性能优化
索引的存储结构
l B Tree和B+ Tree的特点与区别
* 树的高度一般都是在2-4这个高度,树的高度直接影响IO读写的次数。
* 如果是三层树结构---支撑的数据可以达到20G,如果是四层树结构---支撑的数据可以达到几十T
* B Tree和B+ Tree的最大区别在于非叶子节点是否存储数据的问题。B Tree是非叶子节点和叶子节点都会存储数据。而B+ Tree只有叶子节点才会存储数据,而且存储的数据都是在一行上,而且这些数据都是有指针指向的,也就是由顺序的。
l 非聚集索引
* 叶子节点只会存储数据行的指针,简单来说数据和索引不在一起,就是非聚集索引。
* 主键索引和辅助索引都会存储指针的值
l 聚集索引(InnoDB)
* 主键索引(聚集索引)的叶子节点会存储数据行,也就是说数据和索引是在一起,这就是聚集索引。
* 辅助索引只会存储主键值
* 如果没有没有主键,则使用唯一索引建立聚集索引;如果没有唯一索引,MySQL会按照一定规则创建聚集索引。
使用索引的注意事项
l 尽量创建组合索引(组合索引其实会默认按照最左前缀原则帮我们创建多组索引)
组合索引(id,name,sex)
l 索引最左前缀原则
l 索引覆盖:要查询的列,也要使用索引覆盖住
MySQL性能优化之查看执行计划explain
介绍
l MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化.
l 使用explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。
l 可以通过explain命令深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用。
l EXPLAIN 命令用法十分简单, 在 SELECT 语句前加上 explain 就可以了, 例如:
explain select * from user

参数说明
expain出来的信息有10列,分别是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra,下面对这些字段进行解释:
l id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
l select_type: SELECT 查询的类型.
l table: 查询的是哪个表
l partitions: 匹配的分区
l type: join 类型
l possible_keys: 此次查询中可能选用的索引
l key: 此次查询中确切使用到的索引.
l ref: 哪个字段或常数与 key 一起被使用
l rows: 显示此查询一共扫描了多少行. 这个是一个估计值.
l filtered: 表示此查询条件所过滤的数据的百分比
l extra: 额外的信息
select_type列说明
l SIMPLE, 表示此查询不包含 UNION 查询或子查询
l PRIMARY, 表示此查询是最外层的查询
l UNION, 表示此查询是 UNION 的第二或随后的查询
l DEPENDENT UNION, UNION 中的第二个或后面的查询语句, 取决于外面的查询
l UNION RESULT, UNION 的结果
l SUBQUERY, 子查询中的第一个 SELECT
l DEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果.
1.1 type列说明
通常来说, 不同的 type 类型的性能关系如下:
ALL < index < range ~ index_merge < ref < eq_ref < const < system
|
类型 |
含义 |
|
system |
表只有一行 |
|
const |
表最多只有一行匹配,通用用于主键或者唯一索引比较时 |
|
eq_ref |
每次与之前的表合并行都只在该表读取一行,这是除了system,const之外最好的一种,特点是使用=,而且索引的所有部分都参与join且索引是主键或非空唯一键的索引 |
|
ref |
如果每次只匹配少数行,那就是比较好的一种,使用=或<=>,可以是左覆盖索引或非主键或非唯一键 |
|
fulltext |
全文搜索 |
|
ref_or_null |
与ref类似,但包括NULL |
|
index_merge |
表示出现了索引合并优化(包括交集,并集以及交集之间的并集),但不包括跨表和全文索引。 这个比较复杂,目前的理解是合并单表的范围索引扫描(如果成本估算比普通的range要更优的话 |
|
unique_subquery |
在in子查询中,就是value in (select...)把形如“select unique_key_column”的子查询替换。 PS:所以不一定in子句中使用子查询就是低效的! |
|
index_subquery |
同上,但把形如”select non_unique_key_column“的子查询替换 |
|
range |
常数值的范围 |
|
index |
a.当查询是索引覆盖的,即所有数据均可从索引树获取的时候(Extra中有Using Index); b.以索引顺序从索引中查找数据行的全表扫描(无 Using Index); c.如果Extra中Using Index与Using Where同时出现的话,则是利用索引查找键值的意思; d.如单独出现,则是用读索引来代替读行,但不用于查找 |
|
all |
全表扫描 |
MySQL性能优化之慢查询
性能优化的思路
1.首先需要使用慢查询功能,去获取所有查询时间比较长的SQL语询
2.使用explain去查看该SQL的执行计划。
3.使用show profile 去查看该SQL执行时的性能问题。
介绍
l 数据库查询快慢是影响项目性能的一大因素,对于数据库,我们除了要优化 SQL,更重要的是得先找到需要优化的 SQL。
l MySQL 数据库有一个“慢查询日志”功能,用来记录查询时间超过某个设定值的SQL,这将极大程度帮助我们快速定位到症结所在,以便对症下药。
* 至于查询时间的多少才算慢,每个项目、业务都有不同的要求。
* 传统企业的软件允许查询时间高于某个值,但是把这个标准放在互联网项目或者访问量大的网站上,估计就是一个bug,甚至可能升级为一个功能性缺陷。
l MySQL的慢查询日志功能,默认是关闭的,需要手动开启。
开启慢查询功能
l 查看是否开启慢查询功能
show variables like '%slow_ query% ' ;
SHOW VARIABLES LIKE" long query ti me%
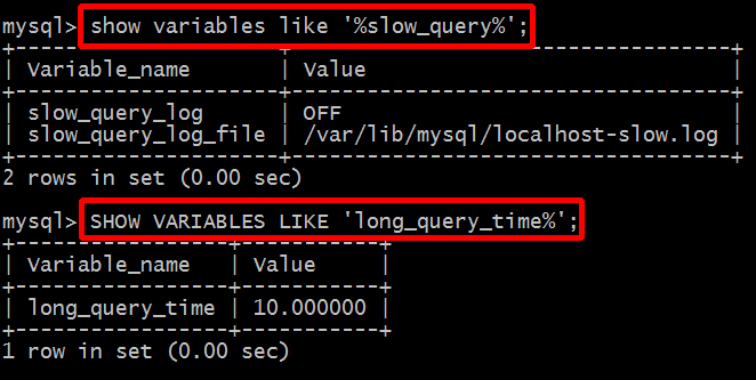
参数说明:
* slow_query_log :是否开启慢查询日志,ON 为开启,OFF 为关闭,如果为关闭可以开启。
* log-slow-queries :旧版(5.6以下版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
* slow-query-log-file:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
* long_query_time :慢查询阈值,当查询时间多于设定的阈值时,记录日志,单位为秒。
l 临时开启慢查询功能
在 MySQL 执行 SQL 语句设置,但是如果重启 MySQL 的话将失效
set global slow_query_log = ON;
set global long_query_time = 1;

l 永久开启慢查询功能
修改/etc/my.cnf配置文件,重启 MySQL, 这种永久生效.
1 [mysqld] 2 slow_query_log = ON 3 slow_query_log_file = /var/log/mysql/slow.log 4 long_query_time = 1
l 慢日志格式
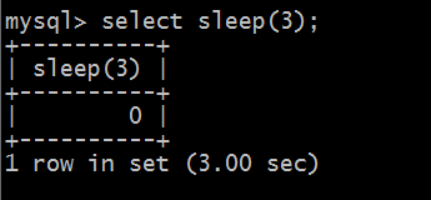
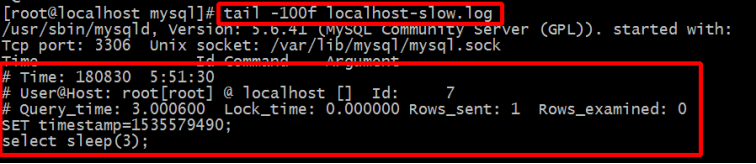
格式说明:
* 第一行,SQL查询执行的时间
* 第二行,执行SQL查询的连接信息,用户和连接IP
* 第三行,记录了一些我们比较有用的信息,如下解析
Query_time,这条SQL执行的时间,越长则越慢
Lock_time,在MySQL服务器阶段(不是在存储引擎阶段)等待表锁时间
Rows_sent,查询返回的行数
Rows_examined,查询检查的行数,越长就当然越费时间
* 第四行,设置时间戳,没有实际意义,只是和第一行对应执行时间。
* 第五行及后面所有行(第二个# Time:之前),执行的sql语句记录信息,因为sql可能会很长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号