
软工实践寒假作业(2/2)
软工实践寒假作业(2/2)by mitwu
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2020SPRINGS?filter=all_members |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2020SPRINGS/homework/10287 |
| 这个作业的目标 | 编写一个疫情统计的程序、学习怎么对所要求编写程序的优化、学习GitHub的使用、PSP的学习使用、编写代码规范以及构建之法的学习 |
| 作业正文 | .... |
| 其他参考文献 | csdn博客 博客园 |
1 github仓库地址
https://github.com/mitwu/InfectStatistic-main
2 构建之法成果与PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 100 | 120 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 30 |
| Design Spec | 生成设计文档 | 20 | 35 |
| Design Review | 设计复审 | 10 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | 具体设计 | 50 | 60 |
| Coding | 具体编码 | 200 | 230 |
| Code Review | 代码复审 | 20 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 50 | 60 |
| Reporting | 报告 | 60 | 60 |
| Test Repor | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 650 | 760 |
3 解题思路
在命令行中输入的参数是对应在Java中的main函数的args数组当中,所以应该先从数组当中取出需要处理的日志以及地址,输出的条件,省份,输出的格式等等参数,得到参数之后,用多个数组进行保存,以便在后面的代码中对日志文件进行特定处理,之后就是对日志文件的读取,用file类将日志文件读取进来,然后对内容按照读取的参数进行处理,之后就可以对所要的内容进行输出,可以使用stream类的输出进行处理,将要输出的内容按照要求的地址和名称输出即可
4 实现过程
分析整个需求说明,在该过程当中需要将命令行的参数先获取,先使用全局变量进行储存,然后在使用IO中的file类的bufferreader和bufferwriter将处理以后的数据输送到所要求存储的位置,在该过程当中还需要对日志文件进行判断是否符合所要求的日期,然后再比较这些日期再对这些符合要求的日志进行读取,还需要对type进行处理,不同的条件下有不同的输出要求,整个过程当中我使用了主函数类,用来执行函数的全部过程,使用了test函数,对输入的参数进行划分,保存,使用了firstgive类将各省市的人数先进行初始化为零,在使用readtxt类和writetxt类对文档进行处理,输入和输出。,在使用out类对输出进行界定,根据要求输出所要求的省市和人数
5 代码说明
public static void test(String[] args)
{
for(int i=0;i<args.length;i++)
{
if(args[i].compareTo("-log")==0)
{
log=args[i+1];
}
else if(args[i].compareTo("-out")==0)
{
out=args[i+1];
}
if(args[i].compareTo("-date")==0)
{
date=args[i+1];
}
if(args[i].compareTo("-type")==0)
{
int a=0;
while(true)
{
if((i+1+a)<args.length)
{
if(args[i+1+a].compareTo("ip")==0)
{
type[a]=args[i+1+a];
a++;
if((i+2+a)<args.length)
{
continue;
}
else
{
break;
}
}
}
if((i+1+a)<args.length)
{
if(args[i+1+a].compareTo("sp")==0)
{
type[a]=args[i+1+a];
a++;
if((i+2+a)<args.length)
{
continue;
}
else
{
break;
}
}
}
if((i+1+a)<args.length)
{
if(args[i+1+a].compareTo("cure")==0)
{
type[a]=args[i+1+a];
a++;
if((i+2+a)<args.length)
{
continue;
}
else
{
break;
}
}
}
if((i+1+a)<args.length)
{
if(args[i+1+a].compareTo("dead")==0)
{
type[a]=args[i+1+a];
a++;
if((i+2+a)<args.length)
{
continue;
}
else
{
break;
}
}
}
break;
}
}
if(args[i].compareTo("-province")==0)
{
for(int j=0;j<province1.length;j++)
{
if((i+1+j)<args.length)
{
if(args[i+1+j].length()!=0)
{
String a=args[i+1+j];
province[j]=a;
}
}
}
}
}
}
先是对输入进来的参数进行归纳和储存,使用全局变量log,date,out,province数组,type数组将参数保存起来,在后续的处理当中可以在整个类当中使用。
public static void read_txt(String path)
{
try
{
File afile=new File(path);
if(afile.isFile() && afile.exists())
{
InputStreamReader read = new InputStreamReader(
new FileInputStream(afile),"UTF-8");
BufferedReader buffered_reader = new BufferedReader(read);
String line_txt = null;
while((line_txt=buffered_reader.readLine())!=null)
{
if(line_txt.contains("//"))//文档结尾,统计全国人数
{
people_count[0][0]=0;people_count[0][1]=0;people_count[0][2]=0;people_count[0][3]=0;
for(int i=1;i<province1.length;i++)
{
for(int j=0;j<4;j++)
{
people_count[0][j]=people_count[0][j]+people_count[i][j];
}
}
break;
}
String[] split=line_txt.split(" ");//分割读进来的字符串
for(int i=1;i<province1.length;i++)
{
if((split[0].compareTo(province1[i]))==0)//判断省份
{
if(split[1].compareTo("新增")==0)
{
if(split[2].compareTo("感染患者")==0)
{
people_count[i][0]=people_count[i][0]+Integer.parseInt(split[3].substring(0,split[3].length()-1));
}
else if(split[2].compareTo("疑似患者")==0)
{
people_count[i][1]=people_count[i][1]+Integer.parseInt(split[3].substring(0,split[3].length()-1));
}
}
else if(split[1].compareTo("死亡")==0)
{
people_count[i][3]=people_count[i][3]+Integer.parseInt(split[2].substring(0,split[2].length()-1));
people_count[i][0]=people_count[i][0]-Integer.parseInt(split[2].substring(0,split[2].length()-1));
}
else if(split[1].compareTo("治愈")==0)
{
people_count[i][2]=people_count[i][2]+Integer.parseInt(split[2].substring(0,split[2].length()-1));
people_count[i][0]=people_count[i][0]-Integer.parseInt(split[2].substring(0,split[2].length()-1));
}
else if(split[1].compareTo("排除")==0)
{
people_count[i][1]=people_count[i][1]-Integer.parseInt(split[3].substring(0,split[3].length()-1));
}
else if(split[1].compareTo("疑似患者")==0)
{
if(split[2].compareTo("流入")==0)
{
for(int j=0;j<province1.length;j++)
{
if(split[3].compareTo(province1[j])==0)
{
people_count[i][1]=people_count[i][1]-Integer.parseInt(split[4].substring(0,split[4].length()-1));
people_count[j][1]=people_count[j][1]+Integer.parseInt(split[4].substring(0,split[4].length()-1));
}
}
}
else if(split[2].compareTo("确诊感染")==0)
{
people_count[i][1]=people_count[i][1]-Integer.parseInt(split[3].substring(0,split[3].length()-1));
people_count[i][0]=people_count[i][0]+Integer.parseInt(split[3].substring(0,split[3].length()-1));
}
}
else if(split[1].compareTo("感染患者")==0)
{
for(int j=0;j<province1.length;j++)
{
if(split[3].compareTo(province1[j])==0)
{
people_count[i][0]=people_count[i][0]-Integer.parseInt(split[4].substring(0,split[4].length()-1));
people_count[j][0]=people_count[j][0]+Integer.parseInt(split[4].substring(0,split[4].length()-1));
}
}
}
}
}
}
read.close();
}
}
catch(Exception e)
{
System.out.print("读取文件出错1");
}
}
接下来读取所在地址的日志文件,并且使用一个二维数组对各省各种类型的人员进行存储
public static void write_txt(String path)//用来将数据输出到txt文件中
{
try
{
people_count=first_give();//将所有省市的的人数初始化
File afile=new File(path);
if(!afile.exists()){ //判断文件是否存在
afile.createNewFile(); //创建文件
}
OutputStreamWriter write1 = new OutputStreamWriter(
new FileOutputStream(afile),"UTF-8");
BufferedWriter write = new BufferedWriter(write1);
File file =new File(log);//日志文件存在的文件夹
File[] names= file.listFiles();
for(File s:names)
{
String filename=s.getName();
int dot = filename.lastIndexOf('.');
filename=filename.substring(0, dot);
if((filename.compareTo(date))<=0||date==null)
{
read_txt(s.getPath());
}
}
//对输出进行限定
if(province[0]==null)//没有输入任何省份只输出全国
{
write.write(province1[0]+" ");
out(write,0);
write.newLine();//换行
String last_line="// 该文档并非真实数据,仅供测试使用";
write.write(last_line);
}
else
{
for(int i=0;i<province.length;i++)
{
int province_number;
for(int j=0;j<province1.length;j++)
{
if(province[i]==province1[j])//判断省份和对应索引
{
write.write(province1[j]+" ");
province_number=j;
out(write,province_number);
write.newLine();//换行
}
}
}
String last_line="// 该文档并非真实数据,仅供测试使用";
write.write(last_line);
}
//关闭输出流
write.flush();
write.close();
}
catch(Exception e)
{
System.out.print("读取文件出错2");
}
}
这部分是对输出进行界定,根据输入的参数,将所处理以后的数据储存到所对应的文档当中
6 单元测试截图及描述
第一个测试样例


第二个测试样例


第三个测试样例


第四个测试样例


第五个测试样例


第六个测试样例


第七个测试样例


第八个测试样例


第九个测试样例


第十个测试样例


第十一个测试样例


第十二个测试样例


7 单元测试覆盖率优化和性能测试以及性能优化截图和描述
这部分在网上查阅资料和观看邹欣老师的博客,要在eclipse中导入一些jar包之后进行单元测四,然后再根据已知的代码在进行优化,在覆盖率和性能方面对代码继续优化。
优化前
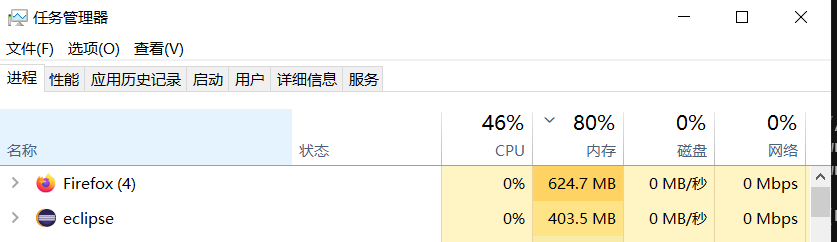
优化后
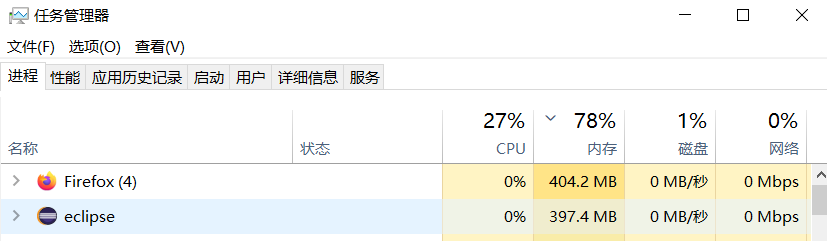
8 代码规范
https://github.com/mitwu/InfectStatistic-main/blob/master/codestyle.md
9 心路历程和收获
在这个过程当中我学习到了怎么使用GitHub,怎么进行commint将修改后的代码写入到github的线上服务器,以及怎么将自己的代码fork到主仓库当中,在github上寻找自己所需要的内容,可以在上面学习到许多的内容,在这个过程当中清楚了怎么对代码进行优化和和对代码的性能进行测试,还有了解了构建之法以及使用psp表格对自己编写项目进行预估和评判,对以后的发展起到了非常大的作用
10 学习相关的仓库
1.关于Java基础训练
链接:https://github.com/azl397985856/leetcode/issues/289
简介:提供不同类型的Java基础的题目,可以训练提高自己的基础能力
2.stringboot
链接:https://github.com/ityouknow/spring-boot-examples
简介:关于springboot的一些相关知识,详细介绍了stringboot的主要内容
3.虚拟机及框架
链接:https://github.com/codecentric/spring-boot-admin
简介:介绍了一些关于jvm的内容以及关于框架的一些知识
4.项目案例及数据库
链接:https://github.com/aalansehaiyang/technology-talk
简介:详细介绍了系统架构、数据库、大公司架构案例、常用三方类库、项目管理的基本知识
5.数据结构及计算机基础知识
链接:https://github.com/frank-lam/fullstack-tutorial
简介:介绍了数据结构的基本算法以及Java的一些基本概念还有一些相关的基础知识

