采集淘宝美人库
爬虫一共就四个主要步骤:
1、明确目标:明确需要抓取那些内容,在哪个网页
2、爬:分析网站结构,将所有的网站的内容全部爬下来
3、取:提取我们所需要的数据
4、处理数据:按照需求存储使用
第一步:
明确目标:
网站url: https://mm.taobao.com/search_tstar_model.htm?spm=5679.126488.640745.2.2dc084317xDoLY
抓取内容:
头像:存储在本地硬盘。
名字,城市,身高,体重,点赞数: 保存在mysql数据库
说明:这里只是用作教程并非真的要将爬取的内容作为其它用途
第二步爬:
使用到的模块:
python 3.6: python环境
requests: 发送请求
pymysql: 操作mysql
queue: 队列
random: 产生随机数
想要看懂这篇文章,还是需要那么一丢丢的python基础知识。
分析网页结构:
1、确定网页数据的请求方式'GET'还是'POST',ajax异步请求还是直接浏览器请求,一般ajax请求的url跟我们在浏览器上的url地址栏看到是不一样的,所以我们需要使用到浏览器的开发者工具抓包查看。
我观察了下淘女郎这个模特库首页是有分页的,这里有个小技巧,来确定请求方式:
我这里使用的是谷歌浏览器,按F12打开浏览器的开发者工具,切换到netrork选项,然后将网页拉到最下面有分页的地方。
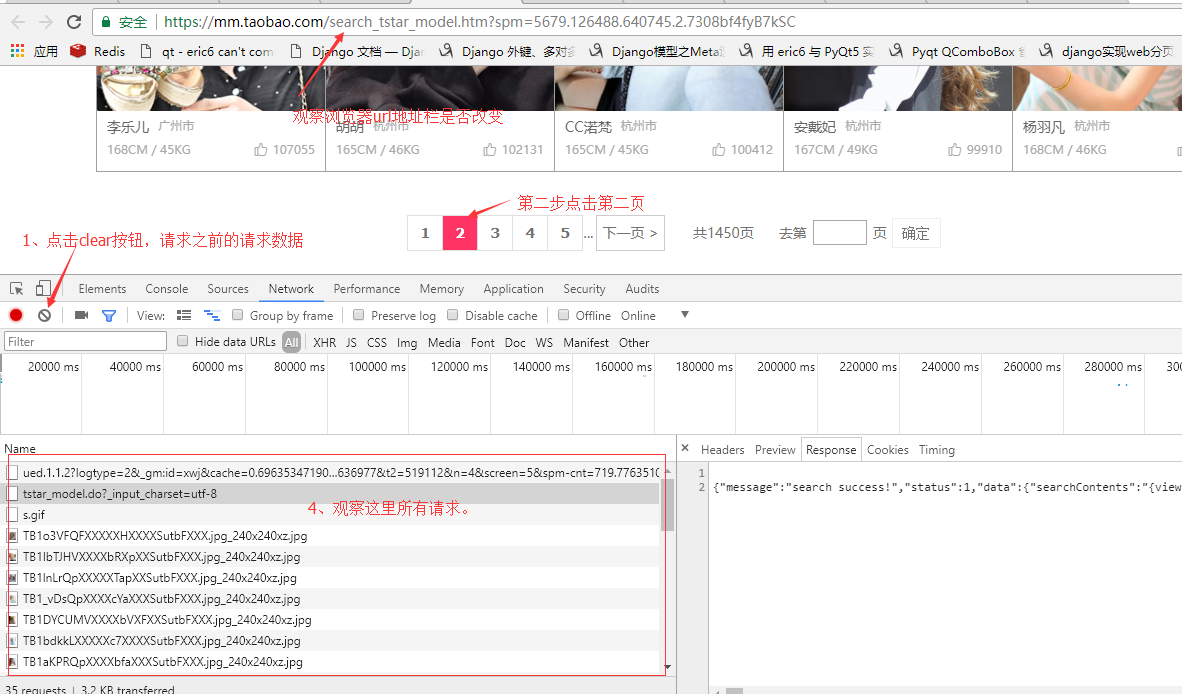
我们观察url地址栏上的地址并没有发生改变,所以地址栏上的url对我们没有帮助!这也说明这个网页的内容是通过ajax加载的。
查看图片上4的位置所有请求的url,发现第一个请求并没有返回任何数据,只有第二个请求有返回数据第三个请求之后的全部都是请求图片的。
选中第二个请求,选中response,查看返回的数据是json数据,可以将json数据复制到json在线解析网站解析看下返回的是什么,解析出来后我们发现,json数据 "searchDOList" 字段就是包含了当前页所有淘宝小姐姐的信息。
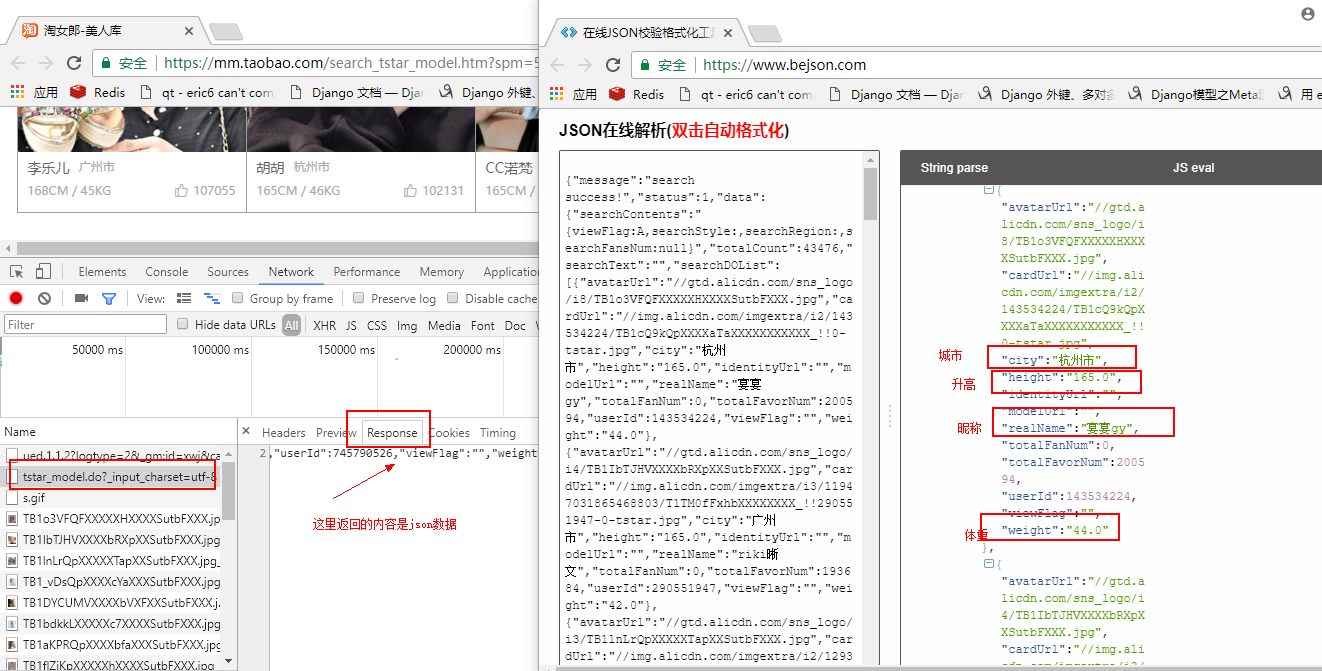
确定我们需要的数据就是在第二请求之后,我们回到开发者管理工具,点击headers查看请求头信息。
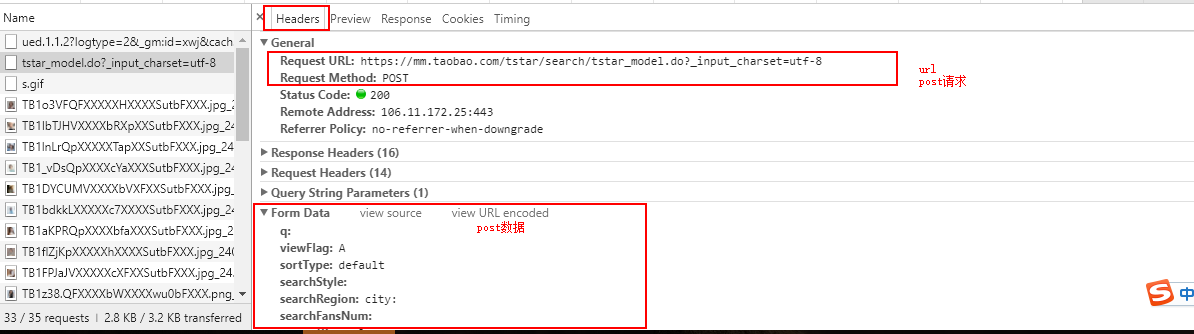
标红框的这几个数据等会写爬虫会用到,分析到这里我们就拿到了等下写爬虫需要的数据:
```
url:https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8 请求方式:post post参数: q: viewFlag:A sortType:default searchStyle: searchRegion:city: searchFansNum: currentPage:2 pageSize:100 ```
测试获取页面内容:

import requests url='https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8' headers={'user-agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36', 'referer':'https://mm.taobao.com/search_tstar_model.htm?spm=5679.126488.640745.2.1b545b81UeJRlv'} data={'viewFlag':'A', 'sortType':'default', 'currentPage':2, 'pageSize':100} res =requests.post(url=url,data=data,headers=headers).json()
完整版代码:
注:程序进行了优化,图片下载本地生成缩略图:
在173行使用用了一个 break。值采集一个模特信息,需要采集所有,将这行屏蔽:


1 ''' 2 程序说明:采集mm.taobao.com模特图片和详细内容。将采集的数据保存到sqlite数据库中 3 保存图片已采集模特的userId为文件名 4 ''' 5 import requests 6 import os 7 import uuid 8 import re 9 import sqlite3 10 from time import sleep 11 from PIL import Image#处理图片 12 #当前项目路径 13 BASE_PATH=os.getcwd() 14 DB ='taobao_mm.db'#数据保存的数据库名 15 TABLE ='mm_table' #数据保存的表名 16 #缩略图尺寸: 17 IMG_W=600 18 IMG_H=600 19 #创建数据sqlite数据库和表 20 def create_db_table(): 21 create_table_sql=''' 22 create table IF NOT EXISTS %s(userid integer, 23 realName varchar(50), 24 city varchar(50), 25 height varchar(10), 26 weight varchar(10), 27 totalFavorNum int(11), 28 img varchar(225), 29 content text 30 ) 31 '''%(TABLE) 32 #链接数据库 33 db=sqlite3.connect(DB) 34 #创建游标 35 cur =db.cursor() 36 #执行sql语句 37 cur.execute(create_table_sql) 38 #提交结果 39 db.commit() 40 #关闭数据库 41 db.close() 42 #插入数据 43 def insert_res(data): 44 #确定数据库已经创建 45 create_db_table() 46 47 sql='''insert into %s(userid,realName,city,height,weight,totalFavorNum,img,content) 48 values('%s','%s','%s','%s','%s','%s','%s','%s') 49 '''%(TABLE,data.get('userid'),data.get('realName'),data.get('city'),data.get('height'),data.get('weight'),data.get('totalFavorNum'),data.get('img'),data.get('content')) 50 #链接数据库 51 db=sqlite3.connect(DB) 52 #创建游标 53 cur =db.cursor() 54 #执行sql语句 55 cur.execute(sql) 56 #提交事务 57 db.commit() 58 #关闭数据库 59 db.close() 60 return True 61 62 63 #处理图片的函数,2个参数:1)图片地址 2)模特id 64 def upload_img(url,userId): 65 #保存图片已采集模特的userId为文件名 66 relative_addr='upload'+'/%d/'%(userId) 67 #判断绝对地址文件夹是否存在:os.path.join(BASE_PATH,relative_addr) 68 absolut_addr=os.path.join(BASE_PATH,relative_addr) 69 #如果不存在。则创建文件夹 70 if not os.path.exists(absolut_addr): 71 os.makedirs(absolut_addr)#创建文件夹 72 #取得当前图片的后缀 73 postfix =url.split('.')[-1]#文件名已.号分割。 74 #已当前userId为当前的图片名 75 file_name=str(userId)+'.'+postfix 76 #文件相对地址: 77 file_url=relative_addr+file_name 78 #请求url图片地址。 79 img_source=requests.get('http:'+url) 80 #将响应的结果保存到文件中file_url中: 81 with open(file_url,'wb') as f: 82 f.write(img_source.content) 83 #生成缩略图 84 img =Image.open(file_url) 85 img.thumbnail((IMG_W,IMG_H)) 86 img.save(file_url,img.format) 87 #返回相对地址: 88 return file_url 89 #爬取用户详细信息 90 def get_content(userId): 91 headers={'user-agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36', 92 'referer':'https://mm.taobao.com/search_tstar_model.htm'} 93 url='https://mm.taobao.com/self/aiShow.htm?userId='+str(userId) 94 img_source=requests.get(url=url,headers=headers) 95 html=img_source.text 96 #正则匹配文章内容 97 content =re.search('<div.*?id="J_ScaleImg">(.*?)</div>',html,re.S).group(1) 98 #正则匹配文章中的所有图片 99 img_list =re.findall('src="(.*?)"',content,re.S) 100 #确定文件的保存路径 101 relative_addr='upload'+'/%d/'%(userId) 102 print(relative_addr) 103 #判断绝对地址文件夹是否存在:os.path.join(BASE_PATH,upload_addr) 104 absolut_addr=os.path.join(BASE_PATH,relative_addr) 105 if not os.path.exists(absolut_addr): 106 os.makedirs(absolut_addr)#创建文件夹 107 #循环处理图片 108 temp_num=0 109 for url_img in img_list: 110 #取得原文件后缀 111 postfix =url_img.split('.')[-1]#文件名已.号分割。 112 #新文件文件名,格式为 : userID_数字.后缀 113 file_name='%s_%s.%s'%(str(userId),str(temp_num),postfix) 114 #temp_num累加1 115 temp_num = temp_num+1 116 #文件相对地址: 117 file_url=relative_addr+file_name 118 #请求url图片地址。 119 img_source=requests.get('http:'+url_img) 120 #将响应的结果保存到文件中: 121 with open(file_url,'wb') as f: 122 f.write(img_source.content) 123 #生成缩略图 124 try: 125 img =Image.open(file_url) 126 img.thumbnail((IMG_W,IMG_H)) 127 img.save(file_url,img.format) 128 except Exception as e: 129 print(file_name,'') 130 else: 131 continue 132 #替换采集内容中的图片地址 133 content =content.replace(url_img,'/'+file_url) 134 return content 135 #请求列表分页数据,url:采集地址,page:页数 136 def main(url,page): 137 headers={'user-agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36', 138 'referer':'https://mm.taobao.com/search_tstar_model.htm?spm=5679.126488.640745.2.1b545b81UeJRlv'} 139 print('开始:') 140 for i in range(1,page+1): 141 data={'viewFlag':'A', 142 'sortType':'default', 143 'currentPage':i, 144 'pageSize':100} 145 r =requests.post(url=url,data=data,headers=headers) 146 #判断请求状态 147 #根据请求状态进行处理,请求次数过多出错,就需要使用代理 148 print('第一页状态:',r.status_code,end='') 149 if r.status_code ==200: 150 res =r.json() #res 保存请求响应的结果 151 res_list=res['data']['searchDOList'] #保存响应的数据列表 152 #循环列表,将数据插入到数据库中 153 for item in res_list: 154 #判断图片文件夹是否存在: 155 relative_addr='upload'+'/%d/'%(item['userId'])#相对地址 156 #判断绝对地址文件夹是否存在:os.path.join(BASE_PATH,upload_addr) 157 absolut_addr=os.path.join(BASE_PATH,relative_addr) 158 if os.path.exists(absolut_addr): 159 #跳出本次循环,进行下次循环 160 continue 161 insert_data={ 'realName':item['realName'], 162 'userid':item['userId'], 163 'city':item['city'], 164 'height':item['height'], 165 'weight':item['weight'], 166 'totalFavorNum':item['totalFavorNum'], 167 'img':upload_img(item['avatarUrl'],item['userId']), 168 'content':get_content(item['userId'])#详细内容图片过多。只做参考 169 } 170 #将数据插入到数据库中 171 print('\r\n',item['realName'],'-',item['userId'],':已采集','\r\n',end='') 172 insert_res(insert_data) 173 break;#注意 ,需要采集所有需要将这句删除。 174 sleep(1)#每次插入操作间隔1秒,方式sqlite被锁 175 else: 176 print('请求是失败,页数:',i) 177 print('结束!',) 178 #print(res_list) 179 #print(res) 180 if __name__ =='__main__': 181 url='https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8' 182 main(url,1)#第一个参数为采集地址。参数2:采集页数
效果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号