Elastic Stack-Elasticsearch使用介绍(一)
一、前言
Elasticsearch对外提供RESTful API,下面的演示我们主要使用Postman,进行一系列的Demo演示,这款工具方便各位前端大大或者对接口调试的神器;
安装过于简单我不做过多介绍,推荐一些文章供大家参考安装:
windows:
Linux:
另外再推荐大家阅读这篇文章:搜索引擎选择: Elasticsearch与Solr
二、简单的一些操作


#创建索引 PUT /test #删除索引 DELETE /test #根据id创建文档 #索引/type/id PUT /test/doc/1 #创建文档 #不带id会自动生成id #索引/type/ PUT /test/doc/ #查询文档 #使用id查询文档 GET /test/doc/1 #使用另外的DSL查询方式等等下次介绍,通过JSON请求完成
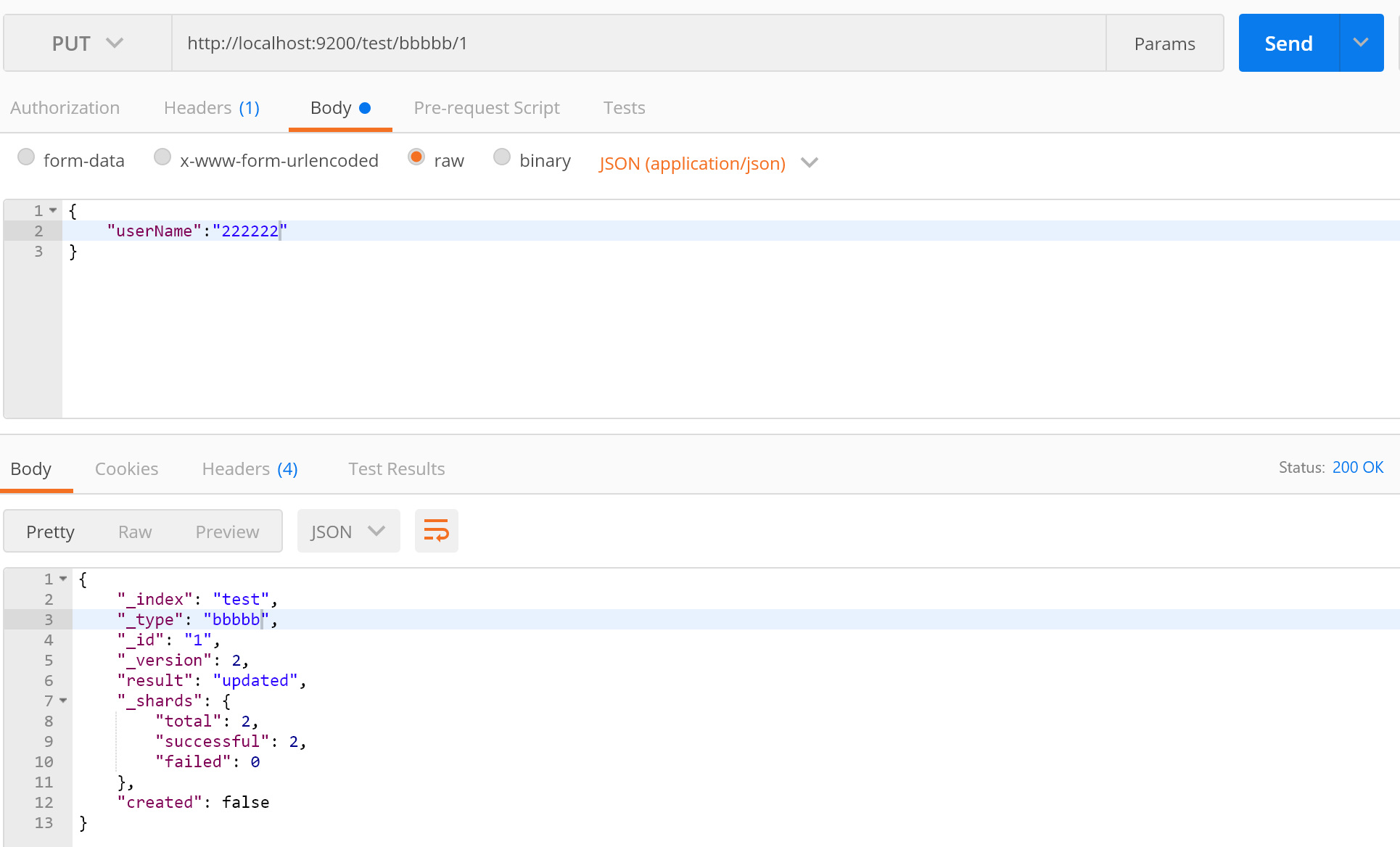
_bulk批量操作:
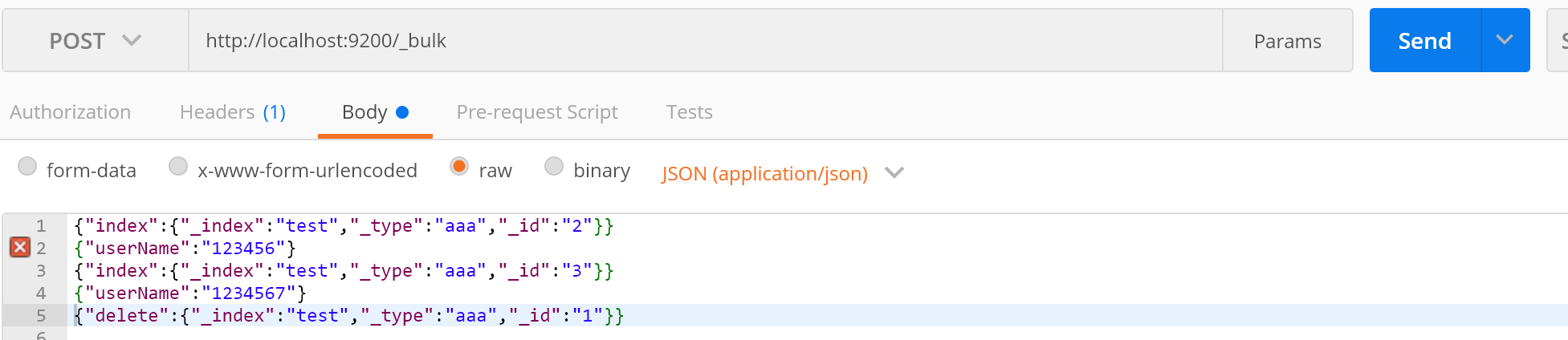
{"index":{"_index":"test","_type":"aaa","_id":"2"}}
{"userName":"123456"}
{"index":{"_index":"test","_type":"aaa","_id":"3"}}
{"userName":"1234567"}
{"delete":{"_index":"test","_type":"aaa","_id":"1"}}
_mget批量查询:
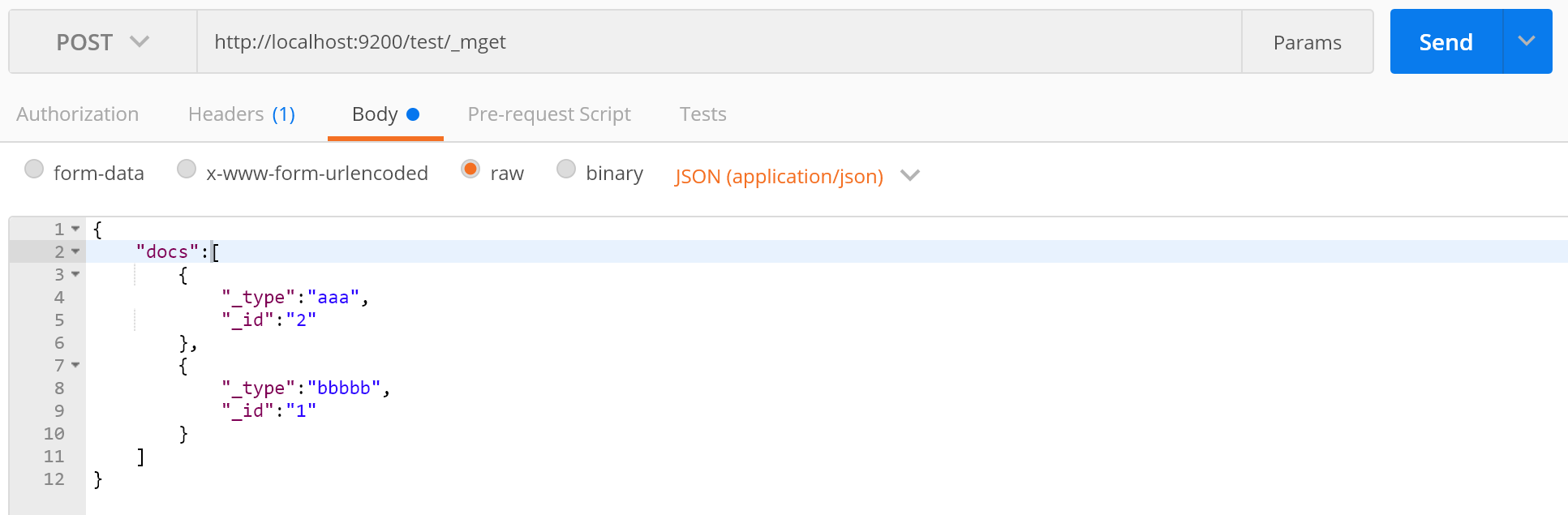
http://localhost:9200/test/_mget { "docs":[ { "_type":"aaa", "_id":"2" }, { "_type":"bbbbb", "_id":"1" } ] }
如果type相同的话,可以使用ids,将id放入数组当中;
批量操作这2个API还是很重要的,如果要一次性操作很多的数据一定要批量操作,尽可能减少网络开销次数,提升系统的性能;
三、倒排索引
之前我写过一篇文章由树到数据库索引,大家可以看下数据库的正排索引,这里我们在举一个例子,大家都知道书是有目录页和页码页的,其实书的目录页就是正排索引,页码页就是倒排索引;
正排索引就是文档Id到文档的内容、单词的关联关系,如下图

倒排索引就是单词到文档id的关系,如下图
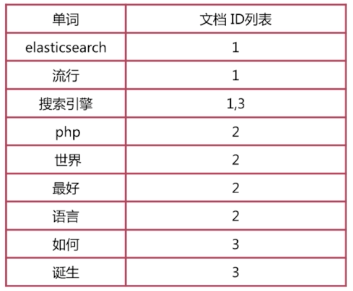
这个时候当我们使用搜索引擎查询包含Elasticsearch文档的,这个时候流程可能是这样的
1.通过倒排索引获取包含Elasticsearch文档id为1;
2.通过正排索引查找id为1的文档内容;
3.拿到正确结果返回;
这个时候我们可以来思考下倒排索引的结构了,当分词以后以我们了解到的数据结构来看的话B+树是一种高效的查询方式,整好符合分词以后的结构,如下图;
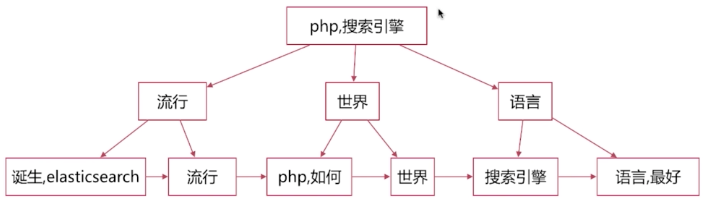
当我们快速拿到我们想要的查询的分词的时候,我们这个时候就需要知道最重要的东西就是文档的id,这样确实可以拿到正确的结果,如下图
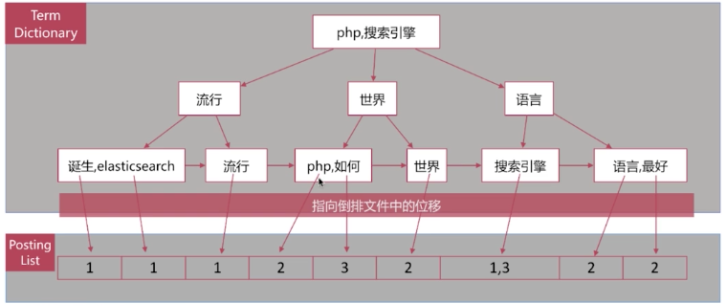
但是这个时候我们再考虑下另外的情况,当我们在淘宝搜索一个物品的时候他有一个高亮显示,这个时候我们上面的情况就满足不了我们了,我们就需要在倒排索引列表中加入分词位置信息和偏移长度,这个时候我们就可以做高亮显示;
后面又来一种情况,随着文档的扩大,我们当用搜索引擎去查询的时候会有很多结果,我们需要优先显示相近的,这个时候有需要另外一个字段就是词频,记录在文档中出现的次数,这个时候就满足可能出现的所有情况了,结构入下图
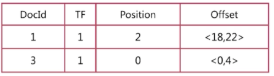
明白整体的结构,你就知道为什么搜索引擎可以快速查询出我们要想要的结果来了,是不是很满足,那就点个关注吧!!哈哈!!当然内部有很多很多优化这个我们暂时就先不要管了!!
四、分词器
分词器组成
分词:按照某种规则将整体变成部分,在Elasticsearch中分词的组件是分词器(Analyzer),组成如下:
1.Character Filters: 针对原始文本进行处理,有点类似正则过滤的意思;
2.Tokenizer:按照指定规则进行分词;
3.Token Filters:将分好的词再次粉装转化;
分词器API
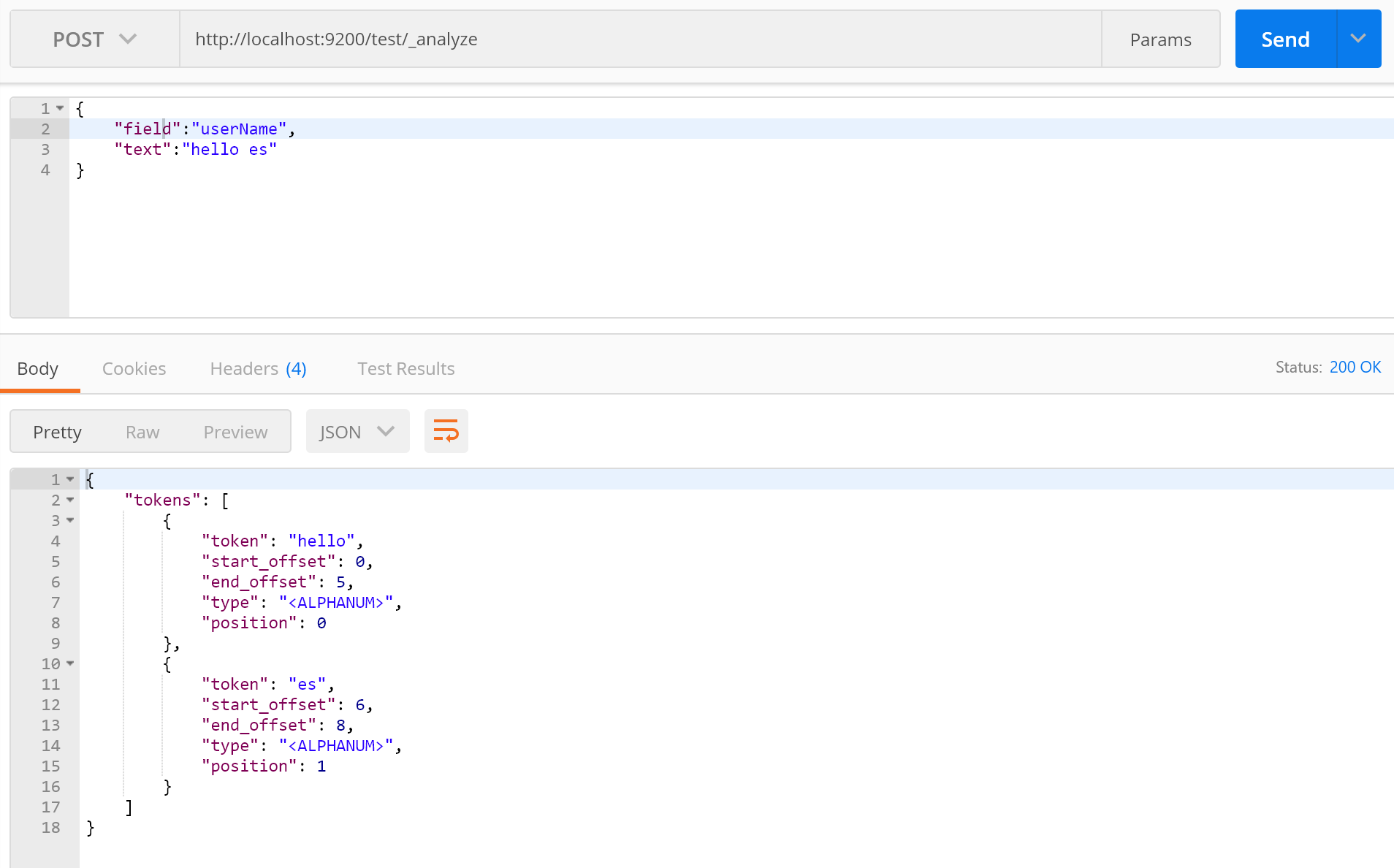
Elasticsearch给我们提供分词API就是_analyze,作用就是为了测试是否能按照我们想要的结果进行分词,简单的演示下怎么使用:
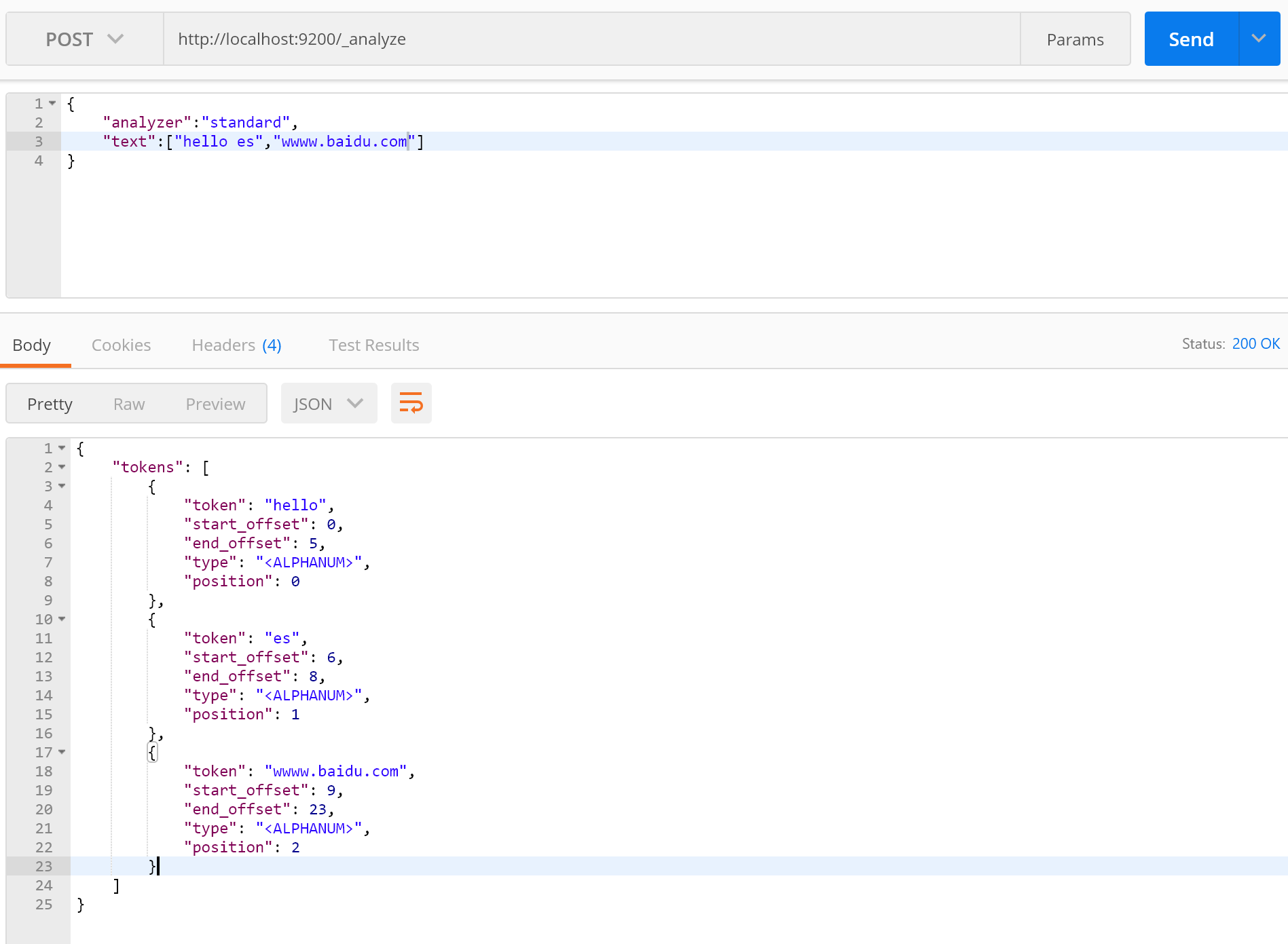
看一下返回结果,每个token里面都包含我们说的倒排索引内所有字段,这个type含义我不是很清楚,但是无伤大雅,另外还可以指定索引进行分词,默认为standard分词器:
分词器类型
1.standard
默认分词器,按词切分,支持多语言,字母转化为小写,分词效果太多JSON返回的过长不方便截图,总体来说对中文支持不是很好,分成一个字一个字,毕竟老外写的;

2.simple
按照非字母切分,字母转化为小写;
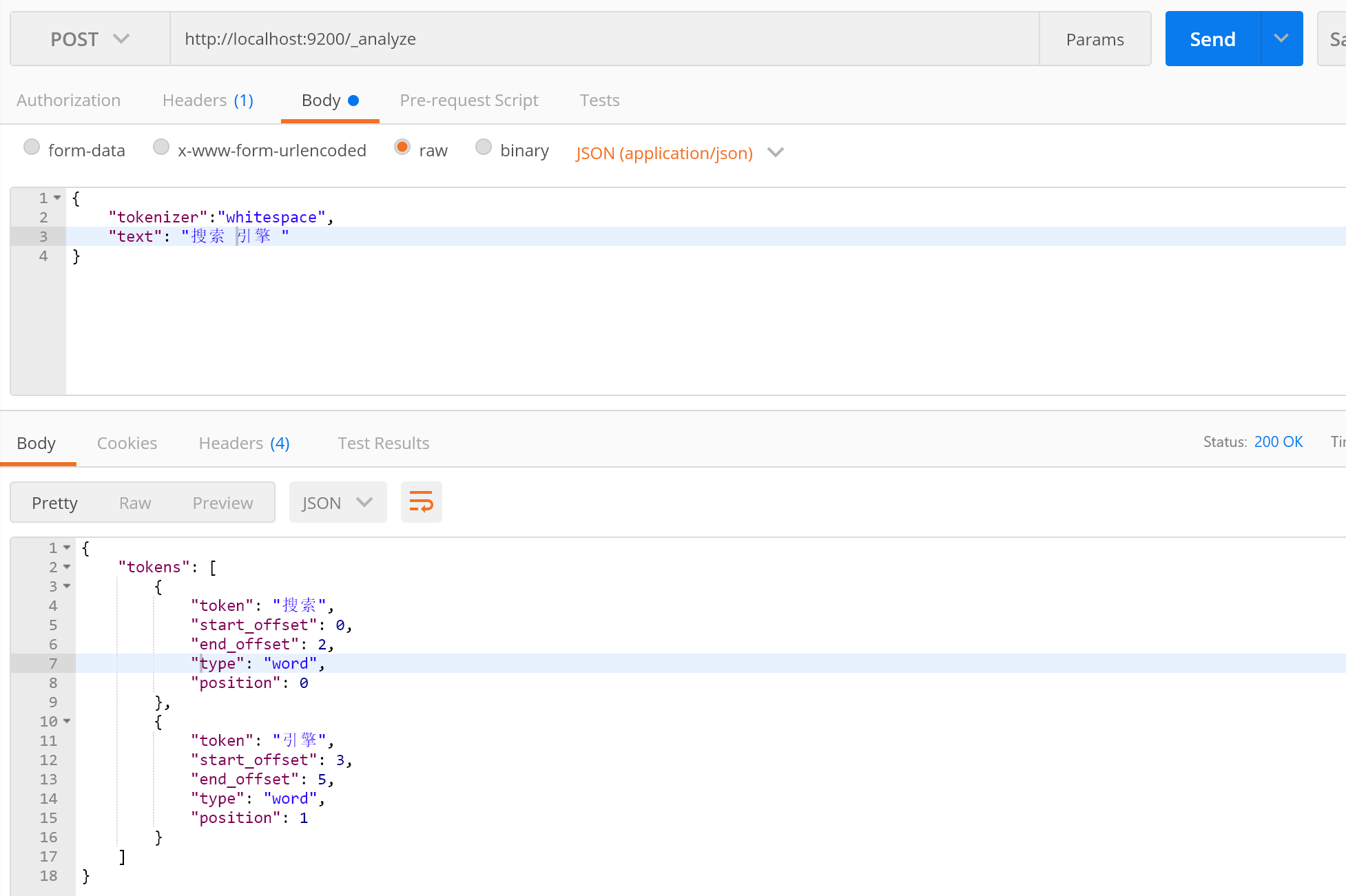
3.whitespace
按照空格切分;
4.stop
与simple相比增加了语气助词区分,例如then、an、的、得等;
5.keyword
不分词;
6.pattern
通过正则表达式自定义分割符,默认\W+,非兹磁的符号作为分隔符;
7.language
语言分词器,内置多种语言;
以上都是自带分词器,对中文的支持都不是很好,接下来我们看下有哪些中文分词器:
1.IK
用法参考下Github,实现中英文分词,支持ik_smart,ik_max_word等,支持自定义词库、更新分词词库;
#url http://localhost:9200/_analyze #json体 { "analyzer":"ik_max_word", "text":"今天是个好天气,我是中国人" } #ik_max_word分词结果 { "tokens": [ { "token": "今天是", "start_offset": 0, "end_offset": 3, "type": "CN_WORD", "position": 0 }, { "token": "今天", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 }, { "token": "是", "start_offset": 2, "end_offset": 3, "type": "CN_CHAR", "position": 2 }, { "token": "个", "start_offset": 3, "end_offset": 4, "type": "CN_CHAR", "position": 3 }, { "token": "好天气", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 4 }, { "token": "好天", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 5 }, { "token": "天气", "start_offset": 5, "end_offset": 7, "type": "CN_WORD", "position": 6 }, { "token": "我", "start_offset": 8, "end_offset": 9, "type": "CN_CHAR", "position": 7 }, { "token": "是", "start_offset": 9, "end_offset": 10, "type": "CN_CHAR", "position": 8 }, { "token": "中国人", "start_offset": 10, "end_offset": 13, "type": "CN_WORD", "position": 9 }, { "token": "中国", "start_offset": 10, "end_offset": 12, "type": "CN_WORD", "position": 10 }, { "token": "国人", "start_offset": 11, "end_offset": 13, "type": "CN_WORD", "position": 11 } ] } #ik_smart分词结果 { "tokens": [ { "token": "今天是", "start_offset": 0, "end_offset": 3, "type": "CN_WORD", "position": 0 }, { "token": "个", "start_offset": 3, "end_offset": 4, "type": "CN_CHAR", "position": 1 }, { "token": "好天气", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 2 }, { "token": "我", "start_offset": 8, "end_offset": 9, "type": "CN_CHAR", "position": 3 }, { "token": "是", "start_offset": 9, "end_offset": 10, "type": "CN_CHAR", "position": 4 }, { "token": "中国人", "start_offset": 10, "end_offset": 13, "type": "CN_WORD", "position": 5 } ] }
2.jieba
python中流行的分词系统,玩Py的朋友看下GitHub;
以上基本满足我们日常开发了,有兴趣的可以查看下HanLP、THULAC等等;
自定义分词器
如果以上这些还满足不了你的需求,那么你可以进行自定义分词,自定义的分词的流程就是上面我们介绍分词器的组成的流程;
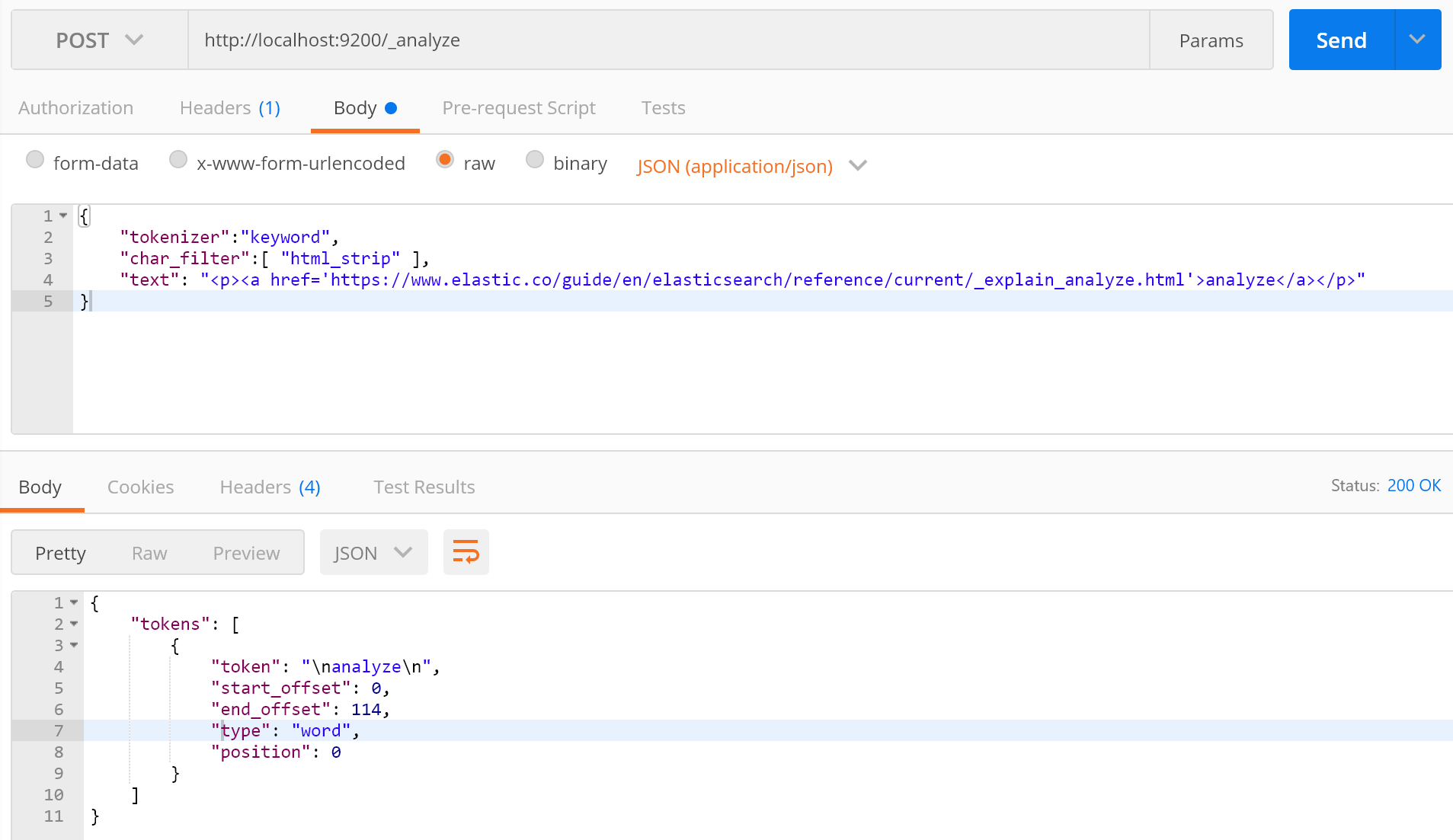
1.Character Filters
在tokenizer之前对原始文本进行处理 ,会影响在Tokenizer解析position和offset的信息,在这个里面我们可以做如下事情:
html_strip 取出html标签中的内容;
mapping进行字符串替换;
pattern_replace进行正则替换;
写了一个简单的demo,剩下大家可以参考下官方文档;
2.Tokenizer
Tokenizer将原始文本按照一定规则切分为单词,大概分成3类:
按照字符为导向分割(Word Oriented Tokenizers):Standard Tokenizer、Letter Tokenizer、Whitespace Tokenizer等等;
部分单词匹配(Partial Word Tokenizers):类似于ik_max_word;
按照某种结构进行分割(Structured Text Tokenizers):Path Tokenizer、Keyword Tokenizer等等;
详细介绍查看官方文档;
3.Token Filter
tokenizer输出的单词进行增加、删除、修改等操作,tokenizer filter是可以有多个的,自带类型有好多大家可以查看官方文档;
#url http://localhost:9200/_analyze #post请求体 { "tokenizer":"standard", "text": "I'm LuFei wo will haizheiwang ", "filter":[ "stop", "lowercase", { "type":"ngram", "min_gram":5, "max_gram":8 } ] } #返回分词结果 { "tokens": [ { "token": "lufei", "start_offset": 4, "end_offset": 9, "type": "<ALPHANUM>", "position": 1 }, { "token": "haizh", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "haizhe", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "haizhei", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "haizheiw", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "aizhe", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "aizhei", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "aizheiw", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "aizheiwa", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "izhei", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "izheiw", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "izheiwa", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "izheiwan", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "zheiw", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "zheiwa", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "zheiwan", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "zheiwang", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "heiwa", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "heiwan", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "heiwang", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "eiwan", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "eiwang", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 }, { "token": "iwang", "start_offset": 18, "end_offset": 29, "type": "<ALPHANUM>", "position": 4 } ] }
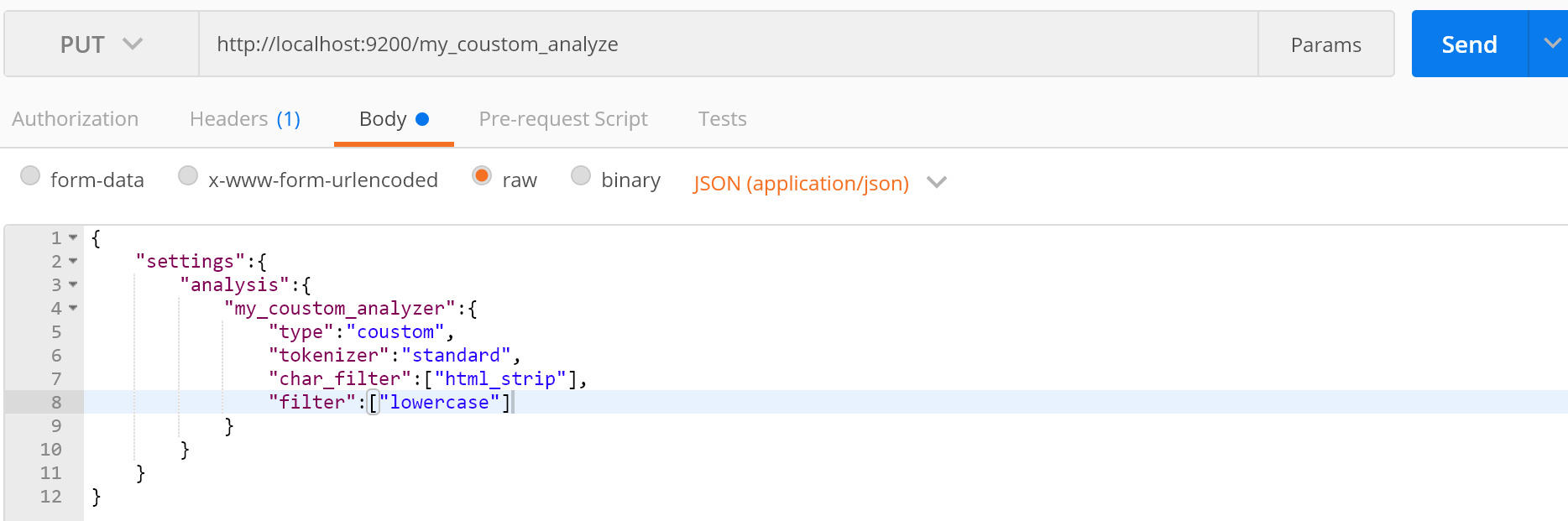
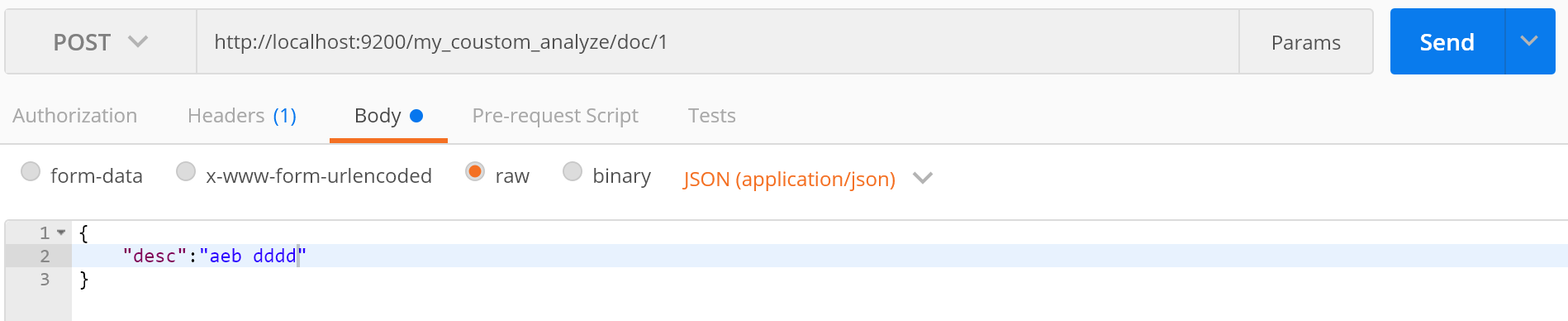
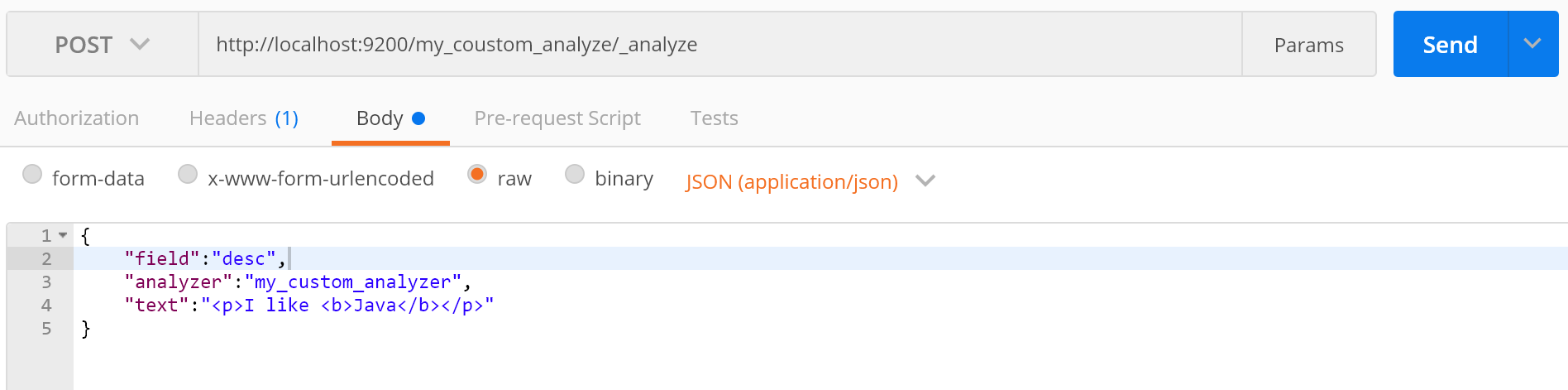
4.在索引中自定义分词器
五、结束
下一篇介绍Mapping、Search Api,欢迎大家点赞,欢迎大家加群438836709,欢迎大家关注公众号


 浙公网安备 33010602011771号
浙公网安备 33010602011771号