数据结构-链表的那些事(下)(二)
一、谈一下博客这一问题?
博客这个我相信已经成为大家了解和学习技术的一个手段,但是真真正正有多少人去按照这个操作了,我看到一条1000+人看的博客,我发现一个简单的小错误,但是我之前的1000多人难道没发现嘛?这个问题值得我们深思?我不是指着作者问题,因为写在作者,看在你,我们无权干涉,当然写就会出现错误,毕竟程序还有BUG,我只是想说有些时候不是只要看一遍就可以我们需要是真实操作,毕竟好记性不然烂笔头,这个问题就讨论学习这个深刻的话题上来了,就远离我们的主题了,我只是将这个问题抛出啦,引发下大家的深思,具体该怎么做,就是大家的事,因为毕竟每个人的特色都不同,当然就有自己的社会主义道路,一切按照自己的来就好,回归正题,不知道为啥我上一篇被移除去了,但是我的群里还是收获了2个小伙伴,这就是我写下的动力。
二、谈一下双链表
双链表的优点:对于链表中一个节点来说,都可以从两个方向操作。当然这个问题自然就带了另外一个缺点,因为前节点的存在导致更多的内存开销,另外在插入和删除的时候会更加的麻烦,需要更多时间,所以说这个世界就是这样有利就有弊,接下来我们看一下双链表的结构,用张图表示:

头部节点首部为空,尾部节点的下一个节点指向为空,中间节点上尾指下头,下头指上尾;
1)增加一个节点,有2种情况在节点之前和节点之后;
2)增加节点的有3种情况首节点,尾节点和中间节点;
3)删除同增加一样;
以下是Java实现的双链表和测试代码,大家可以看一下
这个是定义的节点


1 package com.wtz.dataStruct; 2 3 /** 4 * Created by wangt on 2017/6/29. 5 * 定义一个双链表的节点 6 */ 7 public class Node<T> { 8 public T getItem() { 9 return item; 10 } 11 12 public void setItem(T item) { 13 this.item = item; 14 } 15 16 public Node<T> getPervious() { 17 return pervious; 18 } 19 20 public void setPervious(Node<T> pervious) { 21 this.pervious = pervious; 22 } 23 24 public Node<T> getNext() { 25 return next; 26 } 27 28 public void setNext(Node<T> next) { 29 this.next = next; 30 } 31 32 private T item; 33 private Node<T> pervious; 34 private Node<T> next; 35 public Node(){ 36 37 } 38 public Node(T item){ 39 this.item=item; 40 } 41 42 }
这个是具体实现
package com.wtz.dataStruct; /** * Created by wangt on 2017/6/29. */ public class DoubleLinkList<T> { private Node<T> first;//头节点 private int count;//总节点的个数 public DoubleLinkList() { //初始化为空的链表 this.count=0; this.first=null; } //返回节点的个数 public int size(){ return count; } //根据索引获取节点 public Node<T> getNodeIndex(int index){ if(index<0&&index>=count){ throw new IndexOutOfBoundsException("超出索引"); } Node<T> tempNode=this.first; for (int i=0;i<index;i++){ tempNode=tempNode.getNext(); } return tempNode; } //在未节点之后插入节点 public void addAfter(T value){ Node<T> node=new Node<T>(value); if(this.first==null){ this.first=node; }else { Node<T> lastNode=getNodeIndex(count); lastNode.setNext(node); node.setPervious(lastNode); count++; } } //末节点之前插入 public void addBefore(T value){ Node<T> node=new Node<T>(value); if (this.first==null){ this.first=node; }else { //获取最后一个节点和倒数第二个节点 Node<T> lastNode=getNodeIndex(count); Node<T> lastTwoNode=lastNode.getPervious(); //将倒数第二个节点的下一个节点设置为插入节点 lastTwoNode.setNext(node); node.setPervious(lastTwoNode); //将最后一个节点上一个节点指向插入的节点 lastNode.setPervious(node); node.setNext(lastNode); count++; } } //指定位置之前插入 public void addIndexBefore(T value,int index){ Node<T> node=new Node<T>(value); if(index==0){ if(this.first==null){ this.first=node; }else { node.setNext(first); first.setPervious(node); first=node; count++; } }else { Node<T> nextNode=getNodeIndex(index); Node<T> afterNode=nextNode.getPervious(); afterNode.setNext(node); node.setPervious(afterNode); node.setNext(nextNode); nextNode.setPervious(node); count++; } } //指定位置之后插入 public void addIndexAfter(T value,int index){ Node<T> node=new Node<T>(value); if (index==0){ if (first==null){ first=node; }else { node.setPervious(first); node.setNext(first.getNext()); first.setNext(node); count++; } }else { Node<T> afterNode=getNodeIndex(index); Node<T> nextNode=afterNode.getNext(); afterNode.setNext(node); node.setPervious(afterNode); node.setNext(nextNode); nextNode.setPervious(node); count++; } } //删除指定位置 public void removeIndex(int index){ if(index<0&&index>=count){ throw new IndexOutOfBoundsException("超出范围"); } if(index==0){ first=first.getNext(); }else { Node<T> beforeNode=getNodeIndex(index-1); Node<T> deleteNode=beforeNode.getNext(); Node<T> nextNode=deleteNode.getNext(); beforeNode.setNext(nextNode); nextNode.setPervious(beforeNode); } count--; } }
这个是测试代码
package com.wtz.dataStruct; /** * Created by wangt on 2017/6/30. */ public class TestDemo { public static void main(String[] args) { DoubleLinkList<Integer> doubleLinkList=new DoubleLinkList<Integer>(); //最后一个节点之后 doubleLinkList.addAfter(2); doubleLinkList.addAfter(5); doubleLinkList.addAfter(10); for (int i=0;i<=doubleLinkList.size();i++){ System.out.print(doubleLinkList.getNodeIndex(i).getItem()); } System.out.print("-------------------------------------------------"); doubleLinkList.addBefore(10); doubleLinkList.addBefore(13); doubleLinkList.addBefore(18); doubleLinkList.addBefore(17); doubleLinkList.addBefore(16); for (int i=0;i<=doubleLinkList.size();i++){ System.out.print(doubleLinkList.getNodeIndex(i).getItem()); } System.out.print("-------------------------------------------------"); doubleLinkList.removeIndex(2); for (int i=0;i<=doubleLinkList.size();i++){ System.out.print(doubleLinkList.getNodeIndex(i).getItem()); } System.out.print("-------------------------------------------------"); doubleLinkList.addIndexAfter(111,0); for (int i=0;i<=doubleLinkList.size();i++){ System.out.print(doubleLinkList.getNodeIndex(i).getItem()); } System.out.print("-------------------------------------------------"); doubleLinkList.addIndexBefore(444,0); for (int i=0;i<=doubleLinkList.size();i++){ System.out.print(doubleLinkList.getNodeIndex(i).getItem()); } } }
二、循环链表
循环链表我们这里用单向循环列表来描述这一问题,来述说下循环链表与链表的差距,循环的意思就是从从头到尾,从尾到头连起来,我们已经知道单链表的概念,那么二者差距就很明显了,单向循环链表就是之前的尾部的空节点指向首部节点这。还是用图表示下单向循环链表:
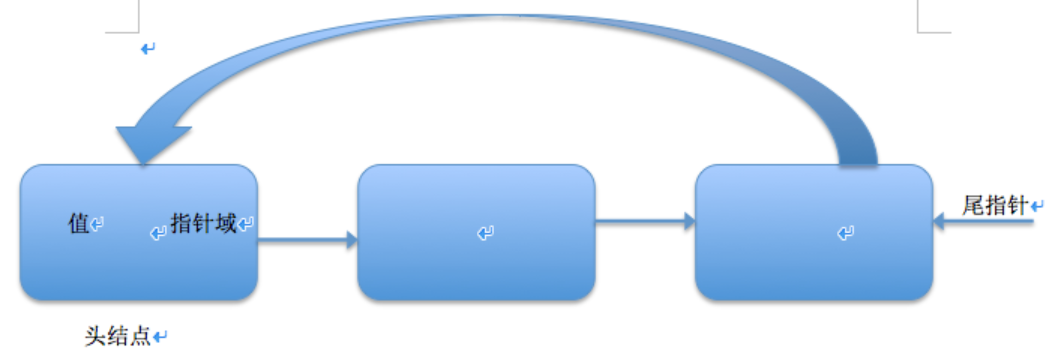
套路还是和之前一样用代码实现单向循环链表,这里需要提醒下注意下循环的时候,如果不消息很容易照成死循环,大家在使用循环链表的时候需要很注意这一点。另外我们当查找最后一个节点的时候就没有必要遍历所有节点,因为尾部的指针的下一个节点是首部,这样就可以将第一个和最后一个节点控制到O(1)访问时间。下面就是代码的实现。
public class CirNode<T> { public T getItem() { return item; } public void setItem(T item) { this.item = item; } public CirNode<T> getNext() { return next; } public void setNext(CirNode<T> next) { this.next = next; } private T item; private CirNode<T> next; public CirNode(T item){ this.item=item; } } package com.wtz.dataStruct; import java.util.Currency; /** * Created by wangt on 2017/6/30. */ public class SingleCircularList<T> { private int count; private CirNode<T> pointer;//尾部节点的指针这里为什么不用节点大家思考一下哈哈 public SingleCircularList() { this.count=0; this.pointer=null; } //返回节点的个数 public int size() { return count+1; } //获取当前的节点 public CirNode<T> getIndexNode(int index) { if(index<0&&index>count){ throw new IndexOutOfBoundsException("超过索引范围"); } CirNode<T> node=pointer; for (int i=0;i<index;i++){ node=node.getNext(); } return node; } //当前节点之前插入 public void addBefore(T value) { CirNode<T> cirNode=new CirNode<T>(value); if(pointer==null){ pointer=cirNode; pointer.setNext(cirNode); }else { cirNode.setNext(pointer.getNext()); pointer=cirNode; count++; } } //当前节点之后插入 public void addAfter(T value) { CirNode<T> cirNode=new CirNode<T>(value); if(pointer==null){ pointer=cirNode; pointer.setNext(cirNode); }else { cirNode.setNext(pointer.getNext().getNext()); pointer.getNext().setNext(cirNode); count++; } } //在某节点之前插入 public void addIndexBefore(T value,int index) { CirNode<T> cirNode=new CirNode<T>(value); if (index==0){ if (pointer==null){ pointer=cirNode; pointer.setNext(cirNode); }else { pointer=cirNode; cirNode.setNext(pointer.getNext()); count++; } }else { CirNode<T> nextNode=getIndexNode(index-1); CirNode<T> afterNode=getIndexNode(index-2); afterNode.setNext(cirNode); cirNode.setNext(nextNode); count++; } } //在某节点之后插入 public void addIndexAfter(T value,int index){ CirNode<T> node=new CirNode<T>(value); if (index==0){ if (pointer==null){ pointer=node; pointer.setNext(node); }else { node.setNext(pointer.getNext().getNext()); pointer.getNext().setNext(node); count++; } }else { CirNode<T> currentNode=getIndexNode(index-1); node.setNext(currentNode.getNext()); currentNode.setNext(node); count++; } } public void deleteIndex(int index){ if(index>0&&index>count){ throw new IndexOutOfBoundsException("超过索引范围"); } if (index==0){ pointer=pointer.getNext().getNext(); }else { CirNode<T> beforeNode=getIndexNode(index-2); CirNode<T> deleteNode=beforeNode.getNext(); CirNode<T> nextNode=deleteNode.getNext(); beforeNode.setNext(nextNode); deleteNode=null; } count--; } } package com.wtz.dataStruct; /** * Created by wangt on 2017/7/4. */ public class TestCirTest { public static void main(String[] args) { SingleCircularList<Integer> singleCircularList = new SingleCircularList<Integer>(); singleCircularList.addBefore(5); singleCircularList.addBefore(2); for (int i=0;i<singleCircularList.size();i++){ System.out.print(singleCircularList.getIndexNode(i).getItem()); } System.out.print("-------------------------------------------------"); singleCircularList.addAfter(9); singleCircularList.addAfter(6); for (int i=0;i<singleCircularList.size();i++){ System.out.print(singleCircularList.getIndexNode(i).getItem()); } System.out.print("-------------------------------------------------"); singleCircularList.addIndexAfter(3,2); for (int i=0;i<singleCircularList.size();i++){ System.out.print(singleCircularList.getIndexNode(i).getItem()); } System.out.print("-------------------------------------------------"); singleCircularList.addIndexBefore(4,2); for (int i=0;i<singleCircularList.size();i++){ System.out.print(singleCircularList.getIndexNode(i).getItem()); } System.out.print("-------------------------------------------------"); singleCircularList.deleteIndex(2); for (int i=0;i<singleCircularList.size();i++){ System.out.print(singleCircularList.getIndexNode(i).getItem()); } System.out.print("-------------------------------------------------"); } }
三、LinkedList源码解读
老套路先看继承结构,
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
AbstractSequentialList这个实现了get,set,add,remove等这些方法,都可以随机访问集合,这些操作允许将链接列表用作堆栈、队列或双端队列。接下来说下List接口这个接口与ArrayList一样实现List接口,只是ArrayList是List接口的大小可变数组的实现,LinkedList是List接口链表的实现。这样的结构使得插入和删除会优于ArryList,但是在读取的时候会比List差,这个在上一篇那个对比的时候相信大家可以看出来。Deque这个接口相当于是对这个扩展,提供先进先出队列操作,以及其他堆栈和双端队列操作。
接下来看构造函数:一个空参构造,一个是集合,这里会调用addAll的方法添加到列表中;
public LinkedList() { } public LinkedList(Collection<? extends E> c) { this(); addAll(c); }
接下来我们看一下内部类:
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
这里我们很快就想起我们那个双链表结构了,不多说。
接下来我们看一下属性:
transient int size = 0;
//元素的个数 transient Node<E> first; //头节点 transient Node<E> last;
//尾节点
接下来的API接口是没有什么好说的都比较简单,只要能看懂我上面双链表的应该看这个不是问题,这里不做过多说明。
四、结束语
最近在搞一些基本Liunx命令和SSH,感觉进度优点缓慢,转还是有点费劲,不过集合写完还会有多线程,这两块还是必须搞定的,还是推荐下QQ群,上次有2个小伙伴加入了,动力呀438836709

 浙公网安备 33010602011771号
浙公网安备 33010602011771号