
[转]拉勾网爬虫破解
原文链接:https://blog.csdn.net/LYouthzzz/article/details/88797527
本博客为分析并解决拉勾网公司详情页的破解
打开网站公司主页,我们的目标数据首页的招聘职位以及校招职位

点击Clear site data, 清空浏览器拉勾网的 cookie
刷新网站,我们会发现数据是正常返回的,所以我们可以从这里开始分析

分析接口可以看出,返回数据的接口为 https://www.lagou.com/gongsi/searchPosition.json 请求方式为form post
form表单参数:
companyId: 拉勾网公司ID
positionFirstType: 职位分类默认全部
city: 城市
salary: 薪资
workyear: 工作年限
schoolJob : True为校招接口 ,False为社招接口
pageNo: 页码
pageSize: 每页的数量
我们发现除了一些正常的请求头以外,还可以看到两个奇怪的参数,就是 X_Anti_Forge_Token,X_Anti_Forge_Code,
以及需要的 cookie 中的JSESSIONID,以上参数缺一不可。不然会被识别为爬虫。
那么我们就需要去解析这些参数的生成原理,那么就开始在chrome中分析接口吧。
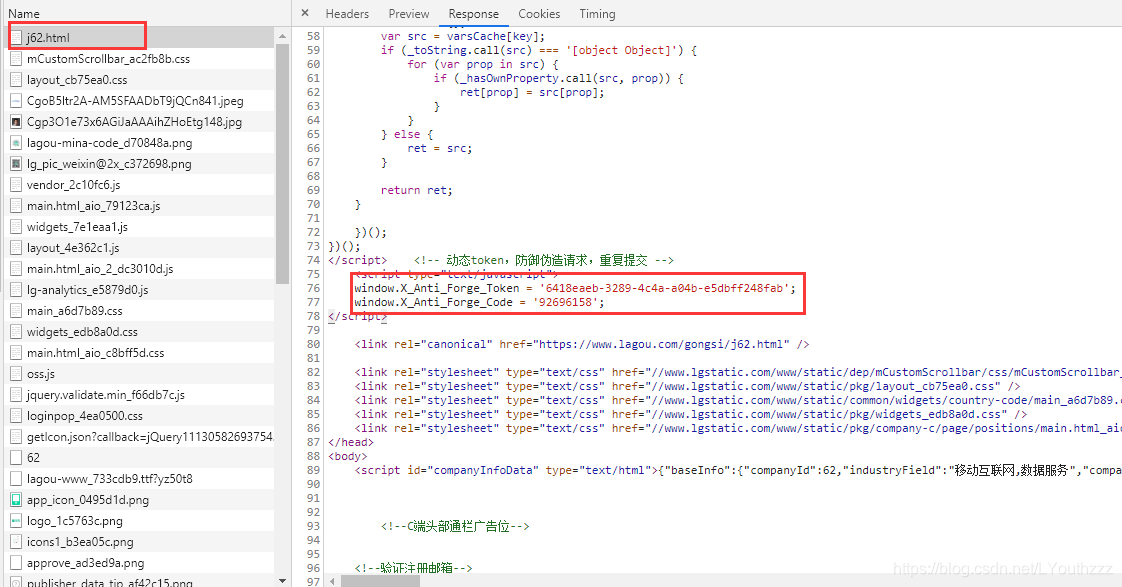

可以发现,cookie以及token参数都是服务器返回的,都藏在了公司主页的请求l中。但是cookie以及token都是动态生成的,当你刷新页面的时候服务器就会返回新的值,而且对IP也是有要求的,请求必须是同一个IP发起的,不然也会被识别为爬虫。
下面我们用python去模拟请求。(本代码为demo代码,没有处理出现的未知异常)
import requests, re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Host': 'www.lagou.com'
}
gongsi_id = 62
home_url = 'https://www.lagou.com/gongsi/j{id}.html'.format(id=gongsi_id)
home_resp = requests.get(home_url, headers=headers)
cookies = home_resp.cookies.get_dict()
headers['X_Anti_Forge_Token'] = re.search(r"window.X_Anti_Forge_Token = '(.*?)'", home_resp.text).group(1)
headers['X_Anti_Forge_Code'] = re.search(r"window.X_Anti_Forge_Code = '(.*?)'", home_resp.text).group(1)
headers['Content-Type'] = 'application/x-www-form-urlencoded; charset=UTF-8'
headers['Referer'] = home_url
postion_ajax = 'https://www.lagou.com/gongsi/searchPosition.json'
data = {
'companyId': gongsi_id,
'positionFirstType': '全部',
'schoolJob': False,
'pageNo': 1,
'pageSize': 10
}
postion_resp = requests.post(postion_ajax, data=data, headers=headers, cookies=cookies)
print(postion_resp.text)
正确的返回了数据

职位信息就藏在了 content.data.page.result 中,就此 拉勾网站的抓取就结束了。
博客小白一个...希望以后可以多多记录足迹,记录生活。加油。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号