
EXCEL 中数据 批量 填充进 word 中
工具:Python3.7
需求描述:将EXCEL中 第二行 数据 填在 word 对应位置上,然后保存为 "姓名+任务.docx"文件。
再将EXCEL中 第三行 数据 填在 word 对应位置上,然后保存为 "姓名+任务.docx"文件。
依此类推。
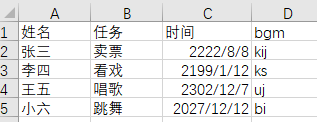
EXCEL数据信息 如下图所示:
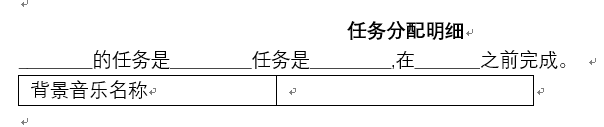
word数据信息 如下图所示:
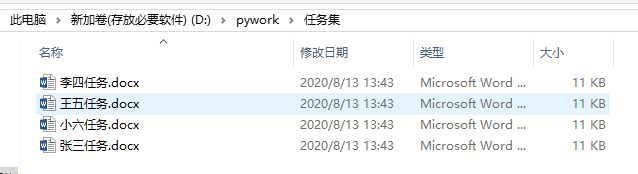
最终需求结果 如下图所示:
开始操作:
第一步:修改成可读模板
使得excel列名称特殊化,例如在名称之前加个符号,如下图:
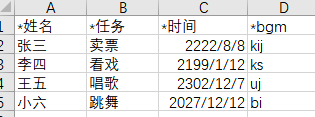
在word对应位置 填写 该 特殊化 名称,例如:

第二步:将 excel信息表 以及 word模板表 放在同一文件夹内,例如:

第二步:运行代码
完整代码如下:
1 from docx import Document 2 from openpyxl import load_workbook 3 import os 4 5 path = r'D:\pywork\12' # EXCEL信息与word信息所在文件夹 6 if not os.path.exists(path + '/' + '任务集'): #如果目标位置 不存在该文件夹 ,则执行下面命令 7 os.mkdir(path + '/' + '任务集') #创建一个新的文件夹, 8 9 excel_1= load_workbook(path + '/' + 'excel信息表.xlsx') #打开excel 10 E1 = excel_1.active #表示当前活跃的表,本案例中 当前活跃表为sheet1 11 #也可以使用 E1 = excel_1.get_sheet_by_name('Sheet1') 来获取工作表1 12 13 for hang in range(2, E1.max_row + 1): # 从第2行开始循环,有几行就循环到几 14 word_1 = Document(path + '/' + 'word模板表.docx') #读取word 15 for lie in range(1, E1.max_column + 1): # 从第一列开始循环,excel有几列就循环到几 16 lieming = str(E1.cell(row=1, column=lie).value) # 在第一行中,记录excel中的列值,也就是列名 17 liezhi = str(E1.cell(row=hang, column=lie).value) #在当前行中,记录excel每列的值 18 19 if '00:00:00' in liezhi: #判断所取的值中 是否 存在 时间,如果excel中涉及日期,都需要加此判断,否则列值返回的是“日期 时间” 20 liezhi=liezhi.split()[0] #按照 空格 进行分割,并返回第一个字符串 21 22 all_duanluo = word_1.paragraphs #读word中 所有 段落 内容 23 for i in all_duanluo: # 在每一个段落里面 操作 24 for j in i.runs: #在每一个 分块中 操作 25 j.text = j.text.replace(lieming, liezhi) # 将分块 里面的 leiming 对应地换成 liezhi,即列名换成列值 26 27 all_biaoge = word_1.tables #读word中 所有 表格 内容 28 for m in all_biaoge: #在每一个 表格 中操作 29 for n in m.rows: #读取某个 表格 的每一行 30 for q in n.cells: #读取 每一行 的每个小单元格 31 q.text = q.text.replace(lieming, liezhi)# 将个小单元格里面的 leiming 对应地换成 liezhi,即列名换成列值 32 33 wenjianming = str(E1.cell(row=hang, column=1).value) #获取文件名 34 word_1.save(path + '/' + f'任务集/{wenjianming}任务.docx') #保存为 ‘姓名+任务.docx’
注意:
1.在word模板表 里面 填写 格式化数据时(本例中 填写的是 *XX),要 从前往后 依次填写,如果 运行程序后 出现 没有被填充的问题。 很可能是 word 填写格式化数据时 出了格式 问题。判断是否为 该问题 的代码如下:(前24行代码与上述代码一致。)
正常的返回结果如下:

不正常返回结果如下:

1 from docx import Document 2 from openpyxl import load_workbook 3 import os 4 5 path = r'D:\pywork\12' # EXCEL信息与word信息所在文件夹 6 if not os.path.exists(path + '/' + '任务集'): #如果目标位置 不存在该文件夹 ,则执行下面命令 7 os.mkdir(path + '/' + '任务集') #创建一个新的文件夹, 8 9 excel_1= load_workbook(path + '/' + 'excel信息表.xlsx') #打开excel 10 E1 = excel_1.active #表示当前活跃的表,本案例中 当前活跃表为sheet1 11 #也可以使用 E1 = excel_1.get_sheet_by_name('Sheet1') 来获取工作表1 12 13 for hang in range(2, E1.max_row + 1): # 从第2行开始循环,有几行就循环到几 14 word_1 = Document(path + '/' + 'word模板表.docx') #读取word 15 for lie in range(1, E1.max_column + 1): # 从第一列开始循环,excel有几列就循环到几 16 lieming = str(E1.cell(row=1, column=lie).value) # 在第一行中,记录excel中的列值,也就是列名 17 liezhi = str(E1.cell(row=hang, column=lie).value) #在当前行中,记录excel每列的值 18 19 if '00:00:00' in liezhi: #判断所取的值中 是否 存在 时间,如果excel中涉及日期,都需要加此判断,否则列值返回的是“日期 时间” 20 liezhi=liezhi.split()[0] #按照 空格 进行分割,并返回第一个字符串 21 22 all_duanluo = word_1.paragraphs #读word中 所有 段落 内容 23 for i in all_duanluo: # 在每一个段落里面 操作 24 for j in i.runs: #在每一个 分块中 操作 25 print(j.text)
===今日我言===========
勇气 让人进步
===================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号