五.docker网络及Libnetwork底层原理
五、docker网络及Libnetwork底层原理
前面介绍了linux的Namespace和Cgroup技术,利用这两项技术可以实现各种资源的隔离和主机资源的限制,让我们的容器只能做一些离线的处理任务,无法通过外部访问。所以今天这一讲,将介绍Docker网络相关知识,使Docekr容器接通网络。
容器网络发展史:
Docker从2013诞生,到后来逐渐成了容器的代名词,然而Docker的野心也不止于此,他还想在更多的领域独占鳌头,比如定制容器的网络和存储标准。于是Docker从1.7版本开始,便把网络和存储从Docker中正式以插件的方式剥离出来,并且分别为其定义了标准,Docker定义的网络模型标准称之为CNM(Container Network Model)。
Docker推出CNM的同时,CentOS提出了CNI(Container Network Model)。起初,以k8s为代表的容器编排阵营考虑过使用CNM作为容器的网络标准。但是后来由于很多的技术等原因,k8s决定支持CentOS推出的容器网络标准CNI。
从此,容器的网络标准便分为两大阵营,一个是以Docker公司为代表的CNM,另一个是以Google、kubernetes、CoreOS为代表的CNI网络标准。
CNM标准****:
CNM(Container Network Model)是Docker发布的容器网络标准,意义在规范和指定容器网络发展标准,CNM抽象了容器的网络接口,使得只要满足CNM接口的网络方案都可以接入到Docker容器网络,更好的满足了用户网络模型多样化的需求。
CNM只是定义了网络的标准,对于底层的具体实现不太关心,这样容器和网络分开工作,使得容器的网络模型更加灵活。
CNM定义的网络标准包括三个重要元素:
- 沙箱(Sandbox):沙箱代表了以系列网络堆栈的配置,其中包括路由的信息、网络接口等网络资源的管理,沙箱的实现通常是Linux的Net Namespace,但也可以是通过其他的技术来实现,例如FreeBSD jail等。
- 接入点(Endpoint):接入点将沙箱连接到网络中,代表容器的网络接口,接入点的实现通常是Linux的veth设备对。
- 网络(Network):网络是一组可以相互通信的接入点,它将多接入点组成一个子网,并且多个接入点之间可以相互通信。
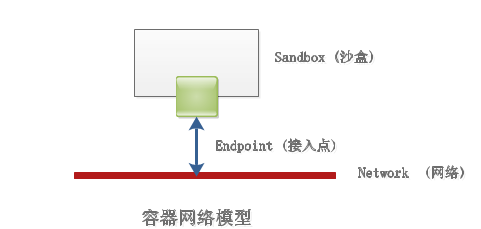
CNM的三要素基本抽象了所有网络模型,使得网络模型的开发更加规范。
为了更好地构建容器网络标准,Docker 团队把网络功能从 Docker 中剥离出来,成为独立的项目 libnetwork,它通过插件的形式为 Docker 提供网络功能。Libnetwork 是开源的,使用 Golang 编写,它完全遵循 CNM 网络规范,是 CNM 的官方实现。Libnetwork 的工作流程也是完全围绕 CNM 的三个要素进行的,下面我们来详细了解一下 Libnetwork 是如何围绕 CNM 的三要素工作的。
Libnetwork的工作流程
Linbnetwork是Docker启动容器时,用来为Docker容器提供网络接入功能的插件,他可以让Docker容器顺利接入网络。实现主机和容器网络的互通。下面,我们来详细了解下Libnetwork是如何为Docker容器通过网络的。
第一步,Docker通过调用libnetwork.New函数来创建NetworkController实例。NetworkController是一个接口类型,提供了各种接口,代码如下:
type NetworkController interface {
// 创建一个新的网络。 options 参数用于指定特性类型的网络选项。
NewNetwork(networkType, name string, id string, options ...NetworkOption) (Network, error)
// ... 此次省略部分接口
}
第二步:通过调用 NewNetwork 函数创建指定名称和类型的 Network,其中 Network 也是接口类型,代码如下:
type Network interface {
// 为该网络创建一个具有唯一指定名称的接入点(Endpoint)
CreateEndpoint(name string, options ...EndpointOption) (Endpoint, error)
// 删除网络
Delete() error
// ... 此次省略部分接口
}
第三步:通过调用 CreateEndpoint 来创建接入点(Endpoint)。在 CreateEndpoint 函数中为容器分配了 IP 和网卡接口。其中 Endpoint 也是接口类型,代码如下:
// Endpoint 表示网络和沙箱之间的逻辑连接。
type Endpoint interface {
// 将沙箱连接到接入点,并将为接入点分配的网络资源填充到沙箱中。
// the network resources allocated for the endpoint.
Join(sandbox Sandbox, options ...EndpointOption) error
// 删除接入点
Delete(force bool) error
// ... 此次省略部分接口
}
第四步:调用 NewSandbox 来创建容器沙箱,主要是初始化 Namespace 相关的资源。
第五步:调用 Endpoint 的 Join 函数将沙箱和网络接入点关联起来,此时容器就加入了 Docker 网络并具备了网络访问能力。
CNM的典型生命周期:
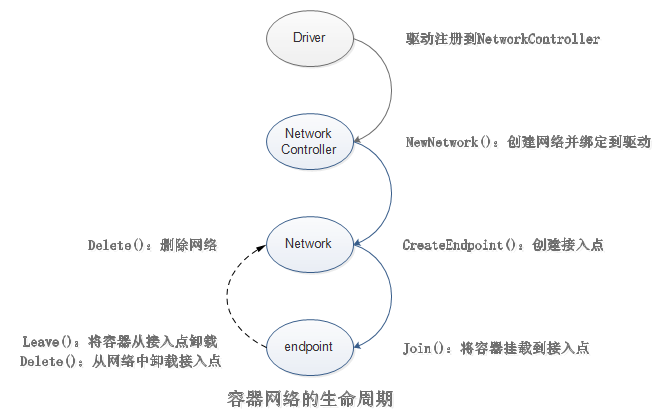
首先,是驱动注册自己到网络控制器,网络驱动器使用驱动类型创建网络,然后在创建的网络上创建接口,最后把容器连接到接口上即可。销毁的过程正好相反,先把容器从接口上卸载,然后删除接口或网络即可。
Libnetwork 基于以上工作流程可以构建出多种网络模式,以满足我们的在不同场景下的需求,下面我们来详细了解一下 Libnetwork 提供的常见的四种网络模式。
Libnetwork常见网络模式
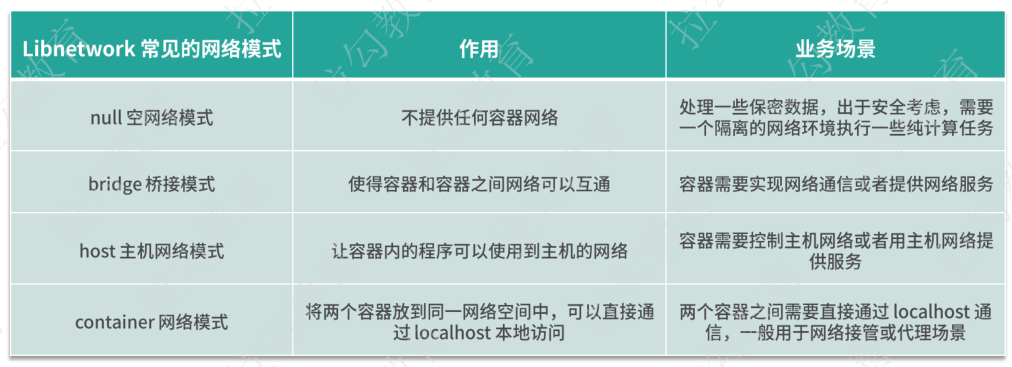
Libnetwork比较典型的网络模式主要有四种,这四种网络模型基本满足了我们单机容器的所有场景。
1.null空网络模式:可以帮助我们构建一个没有网络接入的容器环境,以保障数据安全。
2.bridge桥接模式:可以打通容器和容器之间的通信。
3.host主机网络模式:可以让容器内的进程共享主机网络,从而监听或修改主机网络。
4.container网络模式:可以将两个容器放在同一个容器命名空间内,让两个业务通过localhost即可实现访问。
下面我们对libnetwork的四种模式逐一讲解:
(1)none空网络模式:
有时候,我们需要处理一些保密数据,处于安全考虑,我们需要一个隔离的网络环境执行一些纯计算任务。这时候null网络模式就派上用场了,这时候我们的容器就是一个没有连接网络的电脑,处于一个相对较安全的环境,确保我们的数据不被他人从网络获取。
使用Docker创建null空网络模式的容器时,容器拥有自己独立的Net Namespace,但是此时容器并没有任何网络配置。在这种模式下,Docker除了为容器创建了Net Namespace外,没有创建任何网络接口、IP地址、路由器等网络配置。
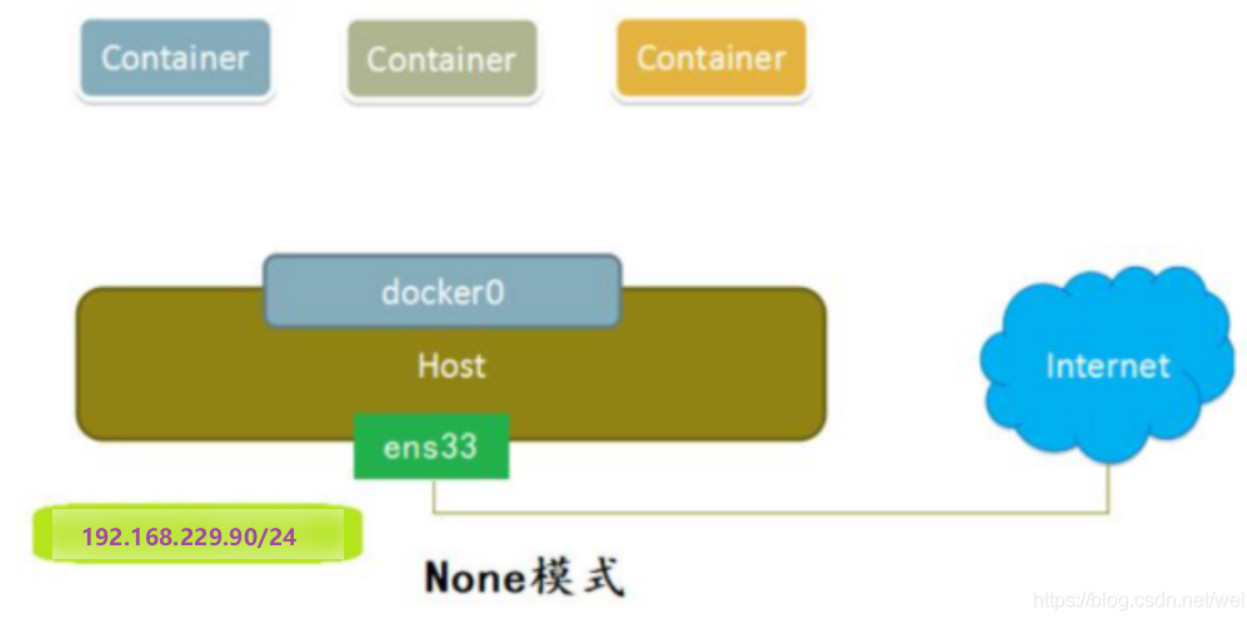
我们使用docker run命令启动时,添加--net=none参数启动一个空网络模式的容器,命令如下:
[root@localhost ~]# docker run -it --net=none busybox
/ #
容器启动后,我们使用ifconfig命令查看下容器内的网络配置信息:
/ # ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
可以看到容器内除了Net Namespace自带的lo网卡并没有创建任何虚拟网卡,然后我们在使用route -n命令查看一下容器内的路由信息:
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
可以看到,容器内也没有配置任何路由信息。
(2)bridge桥接模式(Docker默认的网络模式)
Docker的bridge网络时启动容器时默认的网络模式,使用bridge网络可以实现容器和容器的互通。可以从一个容器直接通过容器IP访问到另外一个容器。同时使用bridge网络可以实现主机与容器的互通。我们在容器内启动的业务,可以在主机直接请求****。
在介绍Docker的bridge桥接模式时,我们先来了解下Linux的veth和bridge相关的技术,因为Docker的bridge模式正是由这两种技术实现的。
linux vet****h
veth是linux种的虚拟设备接口,veth都是成对出现的,它在容器中,通常充当一个桥梁。veth可以用来连接虚拟网络设备,例如veth可以用来连接两个Net Namespace,从而使得两个Net Namespace之间可以互相访问。
Linux bridge
kinux bridge是一个虚拟设备,是用来连接网络的设备,相当于物理网络环境中的交换机。linux bridge可以用来转发两个Net Namespace内的流量。
veth与bridge的关系
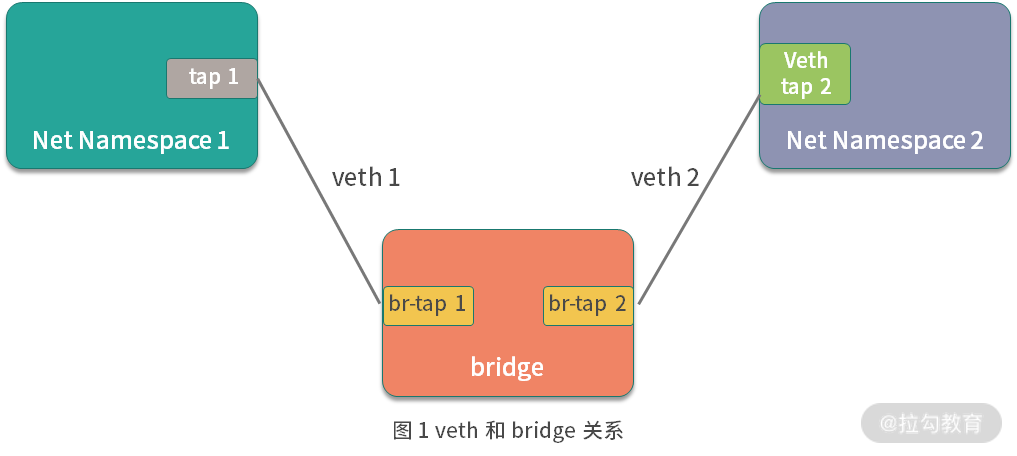
通过上图我们可以看到,bridge就像一台交换机,而veth就像一根网线。通过交换机和网线可以把两个不同Net Namespace的容器连通,使得它们可以互相通信。
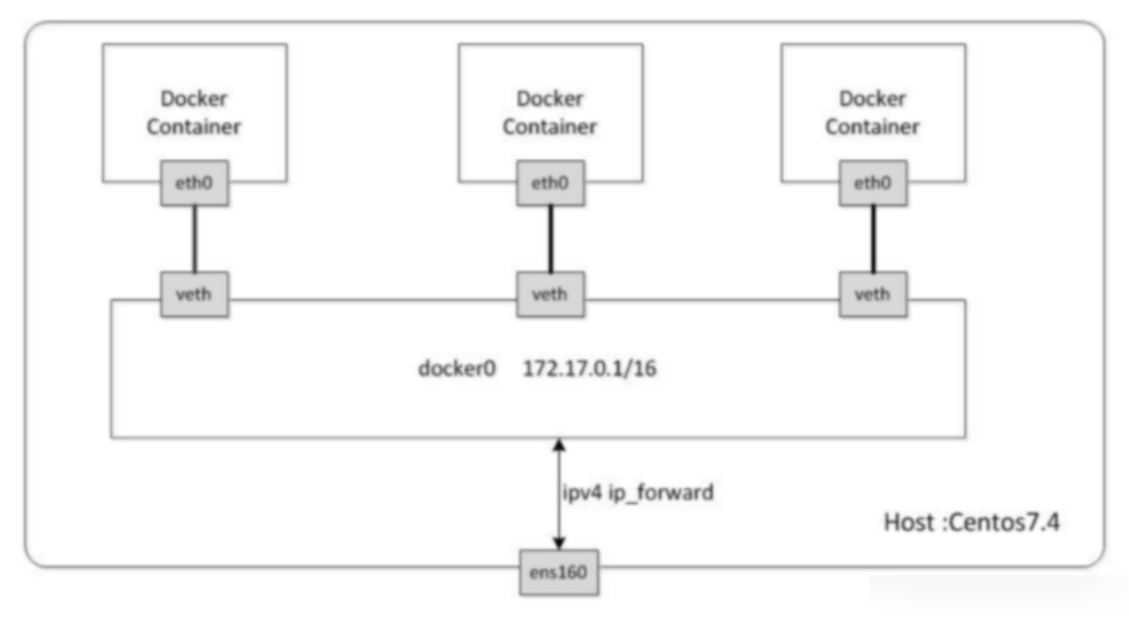
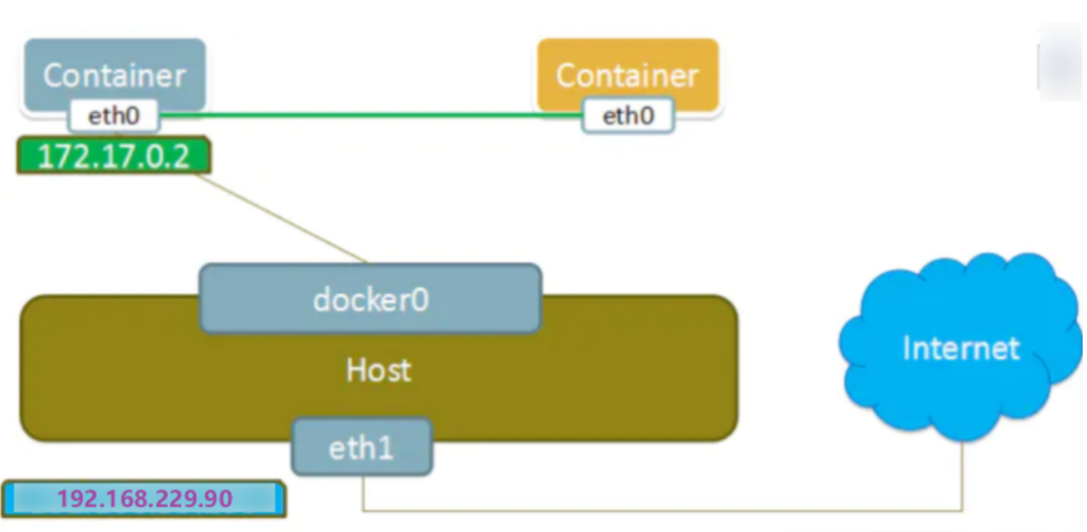
Docker的bridge模式也是这种原理,Docker在启动时,libnetwork会在主机上创建Docker0网桥,docker0网桥就相当于上图中的交换机。而Docker创建出的bridge模式的容器则都会连接docker0上,从而实现网络互通。(使用ipaddr命令可以看到docker0网桥)。bridge桥模式是Docker的默认网络模式,当我们创建容器时不指定任何网络模式,Docker启动容器默认的网络模式为bridge****。
docker的netns在centos下的路径为:/var/run/docker/netns,每创建一个容器会在该路径下生成对应的namespace文件,使用nsenter命令可以看到与容器的网络信息是一样的。测试主机centos ip地址为192.168.72.137
[root@localhost ~]# docker network create -d bridge --subnet 172.1.1.0/24 my_br
[root@localhost ~]# docker run -itd --net=my_br --name=test01 busybox
[root@localhost ~]# docker run -itd --net=my_br --name=test02 busybox
查看my_br情况如下,centos0 IP为172.1.1.2,centos1 IP为172.1.1.3,为my_br的子网内地址
[root@localhost ~]# docker network inspect my_br
[
{
"Name": "my_br",
"Id": "fda02648b090f69b53af5225b6a7eb53bb234a211d3caccdc1648937b80a29db",
"Created": "2022-05-06T17:39:33.406069469+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.1.1.0/24"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"30db12ef0a65d024821be9c31b2b6a976e83baafd1cd8a582aa5404812ceef8b": {
"Name": "test01",
"EndpointID": "e8a295a78c39c14ee1d443d7c05e2d82fb9f08c7be7d89f86fbbecd056a014fa",
"MacAddress": "02:42:ac:01:01:02",
"IPv4Address": "172.1.1.2/24",
"IPv6Address": ""
},
"4e53f2431678f58c317a8bda355ceecfa8a7dad12203929d5766f4588cc7e60a": {
"Name": "test02",
"EndpointID": "e0ad4bc16b79a5f03cf5ea975968236ae2b4aa6c883b76951ecc89b89bb7c074",
"MacAddress": "02:42:ac:01:01:03",
"IPv4Address": "172.1.1.3/24",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
当然容器test01是可以直接ping 网关的
[root@localhost ~]# docker exec -it test01 ping 192.168.72.137
PING 192.168.72.137 (192.168.72.137): 56 data bytes
64 bytes from 192.168.72.137: seq=0 ttl=64 time=0.089 ms
64 bytes from 192.168.72.137: seq=1 ttl=64 time=0.183 ms
查看test01 test02和宿主机网卡信息:
test01:
[root@localhost ~]# docker exec -it test01 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
7: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:01:01:02 brd ff:ff:ff:ff:ff:ff
inet 172.1.1.2/24 brd 172.1.1.255 scope global eth0
valid_lft forever preferred_lft forever
test02:
[root@localhost ~]# docker exec -it test02 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
9: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:01:01:03 brd ff:ff:ff:ff:ff:ff
inet 172.1.1.3/24 brd 172.1.1.255 scope global eth0
valid_lft forever preferred_lft forever
宿主机:
[root@localhost ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:e5:7a:ea brd ff:ff:ff:ff:ff:ff
inet 192.168.72.138/24 brd 192.168.72.255 scope global dynamic ens33
valid_lft 1366sec preferred_lft 1366sec
inet6 fe80::9fe1:a9:34b2:48f5/64 scope link
valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 52:54:00:ea:6a:1f brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN qlen 1000
link/ether 52:54:00:ea:6a:1f brd ff:ff:ff:ff:ff:ff
5: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:be:8f:e4:fb brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
6: br-fda02648b090: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 02:42:1a:17:32:b9 brd ff:ff:ff:ff:ff:ff
inet 172.1.1.1/24 brd 172.1.1.255 scope global br-fda02648b090
valid_lft forever preferred_lft forever
inet6 fe80::42:1aff:fe17:32b9/64 scope link
valid_lft forever preferred_lft forever
8: veth81766c1@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br-fda02648b090 state UP
link/ether b6:95:f3:6a:13:22 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::b495:f3ff:fe6a:1322/64 scope link
valid_lft forever preferred_lft forever
10: vethc54e717@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br-fda02648b090 state UP
link/ether 0e:f7:c5:ae:a4:98 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::cf7:c5ff:feae:a498/64 scope link
valid_lft forever preferred_lft forever
可以看到test01的eth0与宿主机的veth81766c1为veth pair,test02的eth0与宿主机的vethc54e717为另一veth pair。宿主机看到的号是容器的号+1!
我们在创建容器的时候说过在/var/run/docker/netns下生成容器的centns文件,但是我们在执行ip netns命令的时候查出来是空的。因为linux的netns在/var/run/netns,我们需要将两个目录进行关联:
[root@localhost netns]# ln -s /var/run/docker/netns /var/run/netns
[root@localhost netns]# ip netns
52149b3cf0a5 (id: 1)
7b1317310ce3 (id: 0)
[root@localhost netns]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4e53f2431678 busybox "sh" 44 minutes ago Up 44 minutes test02
30db12ef0a65 busybox "sh" 45 minutes ago Up 45 minutes test01
我们发现列出来的ns的id和对应容器的id不是同一个,他两有个映射值,可以通过docker inspect 的结果查到对应关系:
[root@localhost netns]# docker inspect test01
NetworkSettings": {
"Bridge": "",
"SandboxID": "7b1317310ce3deb1e991d0b85c4711ba21476b721d2ab1693d135c11e690097f",
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"Ports": {},
"SandboxKey": "/var/run/docker/netns/7b1317310ce3",
[root@localhost netns]# docker inspect test02
"NetworkSettings": {
"Bridge": "",
"SandboxID": "52149b3cf0a5de75a907f678d0d3b575f6c8bc725caf10d54748bd88e6b346ae",
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"Ports": {},
"SandboxKey": "/var/run/docker/netns/52149b3cf0a5",
查看
nsenter --net=52149b3cf0a5 ip a
[root@localhost netns]# nsenter --net=52149b3cf0a5 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
9: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 02:42:ac:01:01:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.1.1.3/24 brd 172.1.1.255 scope global eth0
valid_lft forever preferred_lft forever
查看test01的路由,可以看到默认网关为172.1.1.1,该地址对应的网卡就是名为my_br的网桥
[root@localhost ~]# docker exec -it test01 ip r
default via 172.1.1.1 dev eth0
172.1.1.0/24 dev eth0 scope link src 172.1.1.2
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
8aae7bf4d4fb bridge bridge local
63d6ab0af472 host host local
fa7031f5e22f my_br bridge local
f1b227aa6dcb none null local
[root@localhost ~]# ip a | grep fa7031f5e22f
6: br-fa7031f5e22f: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
inet 172.1.1.1/24 brd 172.1.1.255 scope global br-fa7031f5e22f
宿主机上的与test01相关的路由如下:
[root@localhost ~]# ip route
default via 192.168.72.2 dev ens33 proto static metric 100
对内test01的路由:
172.1.1.0/24 dev br-fa7031f5e22f proto kernel scope link src 172.1.1.1
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
对外路由:
192.168.72.0/24 dev ens33 proto kernel scope link src 192.168.72.137 metric 100
192.168.122.0/24 dev virbr0 proto kernel scope link src 192.168.122.1
同时查看与172.1.1.0相关的iptables,nat表有如下内容,即对源地址为172.1.1.0/24,出接口非网桥接口的报文进行MASQUERADE,将容器发过来的报文SNAT为宿主机网卡地址
Chain POSTROUTING (policy ACCEPT 332 packets, 21915 bytes)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all -- * !br-f830aee4b13f 172.1.1.0/24 0.0.0.0/0
test01上ping外网网关(192.168.72.2)的处理流程:icmp报文目的地址为192.168.72.2,由于没有对应的路由,直接走默认路由,报文从容器的eth0发出去,进入到默认网关my_br(172.1.1.1),网桥my_br根据host的路由将目的地址为192.168.80.2的报文发送到ens33,同时将源地址使用MASQUERADE SNAT为ens33的地址。这就是docker bridge的报文转发流程。
总结:bridge相当于VMare中的nat模式,容器使用独立network Namespace,并连接到docker0虚拟网卡。通过docker0网桥以及iptables nat表配置与宿主机通信,此模式会为每一个容器分配Network Namespace、设置IP等,并将一个主机上的Docker容器到一个虚拟网桥上。当Docker进程启动时,会在主机上创建一个名为Docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连接在了一个二层网络中。从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备。veth设备总是成对出现的,他们组成了一个数据的通道,数据从一个设备进入,就会从另一个设备出来。所以,veth设备用来连接两个网络设备。
Docker将veth pair 设备的一端放在新创建的·容器中,并命名为eth0(容器的网卡),另一端放在主机中,以veth*这样类似的名字命名,并将这个网络设备加入到docker0网桥中。使用以下命令查看:
[root@localhost ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02423b84cd54 no veth40188da
veth8af945b
我们在使用docker run -p命令的时候,docker实际上在iptables做了DNAT规则,实现了端口转发功能。下面我们来验证一下:
启动nginx容器并映射端口为8080
[root@localhost ~]# docker run -dit --name nginx01 -p 8080:80 nginx
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d6866a874e5b nginx "/docker-entrypoint.…" 12 seconds ago Up 10 seconds 0.0.0.0:8080->80/tcp, :::8080->80/tcp
我们使用以下命令查看iptable:
[root@localhost ~]# iptables -t nat -nL
target prot opt source destination
RETURN all -- 0.0.0.0/0 0.0.0.0/0
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8080 to:172.17.0.4:80
bridge自定义****网络模式
docker network指令:
docker network inspect # 根据网络的ID展示网络的详细信息
[root@localhost ~]# docker inspect bridge
[
{
"Name": "bridge",
"Id": "bd922e154ccf7a8c922b4ab6d5d79f76501e9e268df32772ed81150787c98ada",
"Created": "2022-04-22T14:54:26.544000408+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
.............................以下省略
dockernetwork ls # 展示所有的网络,以列表形式
在安装docker后,会默认常见三种网络:“bridge”,“host”,“null”,通过上述命令查看已存在的网络模式:
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
bd922e154ccf bridge bridge local
ede3b08c2586 host host local
144a242812d9 none null local
docker network create # 创建一个自定义网络
创建一个自定义网络例如:
docker network create --driver bridge --subnet 192.168.0.0/24 --gateway 192.168.0.1 br_bet
其中:docker network create:创建网桥的命令。--driver bridge:前面 --deriver代表的是设备名称,bridge代表是设备模式。--subnet:网段。--gateway:网关。 br_net:表示网桥名称。
练习:创建运行nginx容器,并将网络加入到新创建的网络中:
1.创建一个自定义网络:
[root@localhost ~]# docker network create --driver bridge --subnet 192.168.0.0/24 --gateway 192.168.0.1 mynetwork
84474abb28478a8433dd915551f88b2601da542dd4b858ca8f1ddf2ff46e5a68
2.创建一个名为test01的容器并将容器的网络加入到创建的自定义网络中
[root@localhost ~]# docker run -dit --name test01 --net=mynetwork busybox
9f346d64a16ca73da1a7c9808db5d05edfe4216facd8e9345a7b7ec0ec938288
3.查看容器的IP地址:
[root@localhost ~]# docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' test01
192.168.0.2
docker network connect # 连接一个容器到指定网络上
1.在创建一个新的容器busybox02
[root@localhost ~]# docker run -dit --name test02 busybox
e014e1a5d5e6b27a1b7b74a6332fd5fc2fe000b5710a3071a02622e21908bd81
2.将test的网络加入到新建的自定义网络中
[root@localhost ~]# docker network connect mynetwork test02
3.查看test02的ip地址:
[root@localhost ~]# docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' test02
172.17.0.3192.168.0.4
可以发现到有两个IP地址,因为加入到了两个网络中。同时test01和test02是可以相互ping的
docker network disconnect # 让一个容器从指定网络上断开
[root@localhost ~]# docker network disconnect mynetwork test02
[root@localhost ~]# docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' test02
172.17.0.3
可以看到test02已经在mynetwork上断开。
dockernetwork prune # 命令用于删除所有未使用的网络。未使用的网络是不被任何容器引用****的网络。
[root@localhost ~]# docker network prune
WARNING! This will remove all custom networks not used by at least one container.
Are you sure you want to continue? [y/N] y
docker network rm# 根据网络的ID,删除一个或多个网络, 要删除网络,必须要先断开连接到它的任何容器的网络****。
[root@localhost ~]# docker network inspect mynetwork
以上命令可以查看正在使用此网络模式的容器
删除自定义的网络模式:
[root@localhost ~]# docker network rm mynetwork
mynetwork
练习1:使用bridge实现容器网络通信。两个网段都能与宿主机ping通,且两个网段也能ping通。
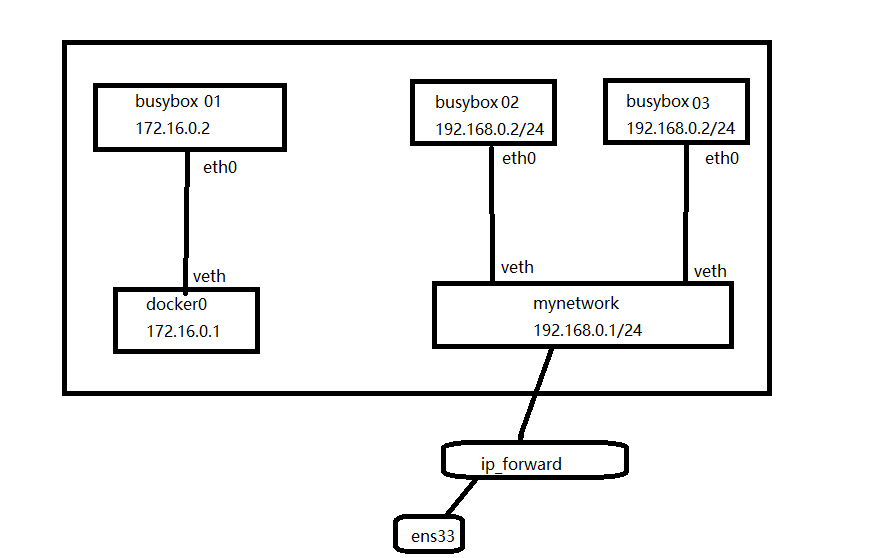
题目分析:首先是ens33(物理机的网卡),docker通过ip_forward将数据转发到ens33网卡。
在docker网络里有两个网络接口,一个为默认的docker0网卡,一个为我们自己创建的网卡。如果想要不同网段进行通信,直接在想要在不同网段的主机加入想要通信的网卡即可。例如busybox02想要和busybox01通信,那么在busybox02在添加一张busybox01的网络。
1.由于busybox01是直接连接到docker0网卡上的,所以默认即可:
[root@localhost ~]# docker run -dit --name busybox01 busybox
fff4146cace414414873dd63b5e8be4797999da62c108c3070d58e770d52d7f1
2.查看busybox01的IP地址
[root@localhost ~]# docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' busybox01
172.17.0.2
3.创建mynetwork自定义网络
[root@localhost ~]# docker network create --driver bridge --subnet 192.168.0.0/24 --gateway=192.168.0.1 mynetwork
3.将两个容器加入到自定义网络中
[root@localhost ~]# docker run -dit --name busybox02 --net=mynetwork busybox
[root@localhost ~]# docker run -dit --name busybox03 --net=mynetwork busybox
此时busybox02和busy03可以互相ping通,也可以ping宿主机,应为网络模式为bridge模式,但是ping不同busybox01
4.使得busybox02可以ping busybox01
[root@localhost ~]# docker network connect bridge busybox02
因为docker0的默认模式为bridge,busybox01的网络模式为bridge,所以可以ping通
4.测试:
busybox02 ping busybox01
[root@localhost ~]# docker exec -it busybox02 sh
/ # ping 172.17.0.2
PING 172.17.0.2 (172.17.0.2): 56 data bytes
64 bytes from 172.17.0.2: seq=0 ttl=64 time=0.324 ms
(3)host主机网络模式
容器内的网络并不是希望永远跟主机时隔离的,有些基础业务需要创建或更新主机的网络配置,我们的程序必须以主机网络模式运行才能够修改主机网络,这时候就需要用到Docker的host主机网络模式。
使用host主机网络模式时:
- libnetwork不会为容器创建新的网络配置和Net Namespace。
- Docker容器中的进程直接共享主机的网络配置,可以直接使用主机的网络信息,此时,在容器内监听的端口,也将直接占用到主机的端口。
- 除了网络共享主机的网络外,其他的包括进程、文件系统、主机名等都是隔离的。
host 主机网络模式通常适用于想要使用主机网络,但又不想把运行环境直接安装到主机上的场景中。例如我想在主机上运行一个 busybox 服务,但又不想直接把 busybox 安装到主机上污染主机环境,此时我可以使用以下命令启动一个主机网络模式的 busybox 镜像:
[root@localhost ~]# docker run -it --net=host busybox
/ #
使用ip addr查看一下容器内的网络环境:
/ # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 00:0c:29:59:2d:20 brd ff:ff:ff:ff:ff:ff
inet 192.168.72.130/24 brd 192.168.72.255 scope global dynamic ens33
valid_lft 1760sec preferred_lft 1760sec
inet6 fe80::3ec9:8ac8:a043:639a/64 scope link
valid_lft forever preferred_lft forever
可以看到容器内的网络环境与主机完全一致。同时,可以使用 ls -l /proc/$$/ns/ 命令验证下:
docker内的Net Namespace的net编号:
/ # ls -l /proc/$$/ns/
total 0
lrwxrwxrwx 1 root root 0 Apr 24 12:59 ipc -> ipc:[4026532847]
lrwxrwxrwx 1 root root 0 Apr 24 12:59 mnt -> mnt:[4026532845]
lrwxrwxrwx 1 root root 0 Apr 24 12:59 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 Apr 24 12:59 pid -> pid:[4026532848]
lrwxrwxrwx 1 root root 0 Apr 24 12:59 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Apr 24 12:59 uts -> uts:[4026532846]
宿主机的Net Namespace的net编号:
[root@localhost ~]# ls -l /proc/$$/ns
总用量 0
lrwxrwxrwx. 1 root root 0 4月 24 21:01 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 4月 24 21:01 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 4月 24 21:01 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 4月 24 21:01 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 4月 24 21:01 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 4月 24 21:01 uts -> uts:[4026531838]
可以发现容器中的 Net Namespace的编号和主机上是一样的。说明容器是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。
(4)container网络模式
container 网络模式允许一个容器共享另一个容器的网络命名空间。当两个容器需要共享网络,但其他资源仍然需要隔离时就可以使用 container 网络模式,例如我们开发了一个 http 服务,但又想使用 nginx 的一些特性,让 nginx 代理外部的请求然后转发给自己的业务,这时我们使用 container 网络模式将自己开发的服务和 nginx 服务部署到同一个网络命名空间中。
下面举例说明,首先我们使用以下命令启动一个busybox01容器并查看IP地址:
[root@localhost ~]# docker run -it --name=busybox01 busybox
/ # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
18: eth0@if19: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
可以看到busybox01的IP地址为172.16.0.2。
然后我们新打开一个命令窗口,在启动一个busybox02容器,通过container网络模式连接到busybox1的网络,命令如下:
[root@localhost ~]# docker run -it --net=container:busybox01 --name busybox02 busybox
/ # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
22: eth0@if23: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
可以看到busybox2容器的网络IP也为172.16.0.2,与busybox01的网络一致
我上面有说到 Libnetwork 的工作流程是完全围绕 CNM 的三个要素进行的,CNM 制定标准之初不仅仅是为了单台主机上的容器互通,更多的是为了定义跨主机之间的容器通信标准。但是后来由于 Kubernetes 逐渐成为了容器编排的标准,而 Kubernetes 最终选择了 CNI 作为容器网络的定义标准(具体原因可以参考这里),很遗憾 CNM 最终没有成为跨主机容器通信的标准,但是CNM 却为推动容器网络标准做出了重大贡献,且 Libnetwork 也是 Docker 的默认网络实现,提供了单独使用 Docker 容器时的多种网络接入功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号