[Go爬虫02]豆瓣读书TOP250
0. 前言
这一篇博客主要涉及到的是:
-
如何处理错误418(网站反爬),无法直接用
http.GET -
查找唯一标签
-
简单的给文本做一个格式
1. 确定要爬取的URL以及内容
简单的一说这一步就可以了。
先看一下链接
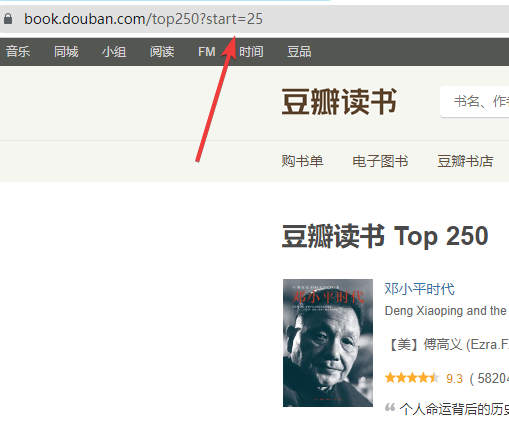
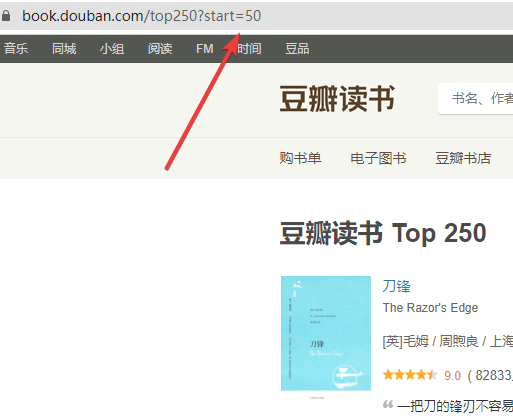
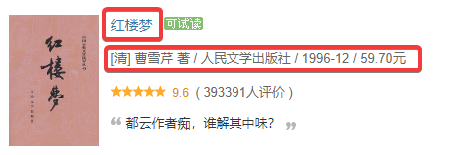
再看一下要提取的内容
可以看得出来链接每一页+25,到时候写个for循环i *25就行了。
2. 获取网站源代码
①处理错误418(网站反爬)
我们实际操作的时候发现,直接用http.GET()是无法获取到网站的源代码的,会返回一个418的错误。这就是网站的一个反爬机制。当然应对起来也不算难。
只要我们模拟浏览器操作就可以顺利获取到源代码了。
先放一段代码:
func SpiderGet(url string) (pageHtml string, err error) {
request, _ := http.NewRequest("GET", url, nil)
request.Header.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36")
client := new(http.Client)
resp, _ := client.Do(request)
defer resp.Body.Close()
buf := make([]byte, 8*1024)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
pageHtml += string(buf[:n])
}
return
}
其中client := new(http.Client)是创建一个客户端,也就是模拟一个浏览器。然后让这个client去发送GET请求。
这里的request, _ := http.NewRequest("GET", url, nil)就是定义了一个对网站的GET请求。
之后我们要给这个请求加一个请求头 request.Header.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36")。
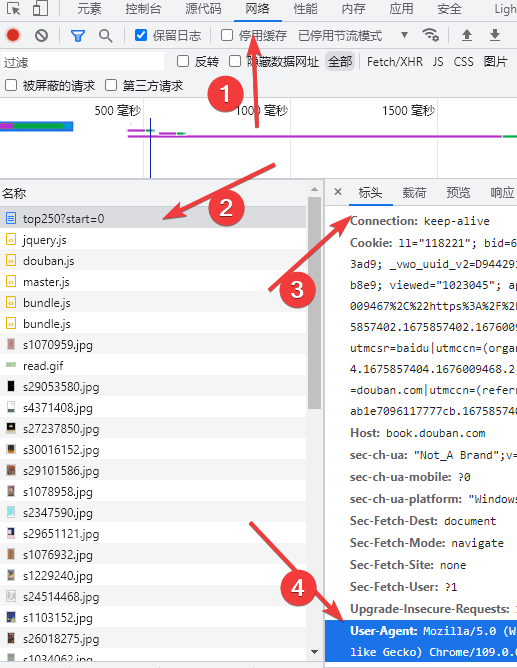
最后只需要用“客户端”去执行请求就可以获得响应resp, _ := client.Do(request)。到这里,就和之前一模一样了。
3. 数据检索加工
首先找标题,我们可以看到<a></a>里面的标题的获取是很麻烦的。
反而是那个title里的标题更容易获取并且内部没有格式,因此我们这选择①而不去选择②。


至于介绍,也就是这样<p class="p1"> </p>就可以确定唯一的目标。

re := regexp.MustCompile(`<a href=".+?" onclick="moreurl.+?" title="(.+?)"`)
re2 := regexp.MustCompile(` <p class="pl">(.+?)</p>`)
① 文本做个格式
no := (page-1)*25 + i + 1
now := fmt.Sprintf("No.%03d %-30s%s \n", no, title[i][1], detail[i][1])
txt += now
no就是编号,fmt.Sprintf是将格式化的输出,作为一个返回值。
%03d是占3位,不足的地方用0来补上
%-30s是占30位,向左对齐。
最终代码
package main
import (
"fmt"
"net/http"
"os"
"regexp"
"strconv"
)
func main() {
SpiderRun()
}
func SpiderRun() {
fmt.Println("正在爬取豆瓣读书TOP250……")
f, err := os.Create("豆瓣读书TOP250.txt")
if err != nil {
return
}
defer f.Close()
for i := 1; i <= 10; i++ {
SpiderPage(i, f)
}
}
func SpiderPage(page int, f *os.File) {
var txt string
url := "https://book.douban.com/top250?start=" + strconv.Itoa((page-1)*25)
pageHtml, err := SpiderGet(url)
if err != nil {
return
}
//fmt.Println(pageHtml)
re := regexp.MustCompile(`<a href=".+?" onclick="moreurl.+?" title="(.+?)"`)
re2 := regexp.MustCompile(` <p class="pl">(.+?)</p>`)
title := re.FindAllStringSubmatch(pageHtml, -1)
detail := re2.FindAllStringSubmatch(pageHtml, -1)
for i := 0; i < 25; i++ {
no := (page-1)*25 + i + 1
now := fmt.Sprintf("No.%03d %-30s%s \n", no, title[i][1], detail[i][1])
txt += now
}
f.Write([]byte(txt))
fmt.Printf("…………已完成 %d %% \n", page*10)
}
func SpiderGet(url string) (pageHtml string, err error) {
request, _ := http.NewRequest("GET", url, nil)
request.Header.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36")
client := new(http.Client)
resp, _ := client.Do(request)
defer resp.Body.Close()
buf := make([]byte, 8*1024)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
pageHtml += string(buf[:n])
}
return
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号