【完整项目】使用Scrapy模拟HTTP POST,获取完美名字
1. 背景
最近有人委托我给小孩起个名字,说名字最好符合周易五行生克理论,然后给了我个网址,说像是这个网站中的八字测名,输入名字和生辰八字等信息,会给出来这个名字的分数和对未来人生的预测。当父母的自然是希望子女一生顺利,远离病痛意外什么的,抱着宁可信其有,不可信其无的想法。
网址如下
https://www.threetong.com/ceming/
2. 思路
现在已有的信息是姓和生辰八字,需要得到的是名字,由于小孩父母是想要两个字的名字,那么可以细化到字1和字2。把这些信息输入到网站,会得到两个具有指标性的分数:姓名理数评分和姓名配合八字评分,如果两个分数是个好分数,比如两个都是100,或者高于95,那么这个名字可以进入到备选的表单中。我可以比如说弄十万个常用名字输入到这个网站,配合生辰八字,每个名字都能有个得分。按分数从高到低排序,形成一个名字列表,最后给小孩父母自己筛选,选择符合眼缘的,喜欢读音和意义的等等,那就是他们主观的选择了。至少这样,无论起哪个名字,都符合周易五行理论,得到一生的平安幸福。
3. 具体步骤
A,获取用于起名字的常用字列表
由于是两个字的名字,那么字1和字2都可以用这个列表,然后用个循环来形成字1和字2的每种可能组合。我选取了一个800个子的列表,这样,最终输入的名字就有800x800,640000个名字。获取的代码是很基础Scrapy获取网站上的信息,如下:
#spider的代码
# -*- coding: utf-8 -*- import scrapy from getName.items import GetnameItem class DownnameSpider(scrapy.Spider): name = 'downName' start_urls = ['http://xh.5156edu.com/xm/nu.html'] #默认的http request
# 默认的http request返回的http response的处理函数,是个回调函数。 def parse(self, response): item = GetnameItem() item['ming'] = response.xpath('//a[@class="fontbox"]/text()').extract() yield item
#定义了一个item来存获取的字
import scrapy class GetnameItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() ming = scrapy.Field()
其余部分就是Scrapy框架自动生成的代码了
B,以两个字组合得到的名字,加以姓和生辰八字,输入到八字测名网站,得到名字的分数列表,过滤掉低分名字,比如低于95分。呈给小孩父母。
4. 难点详解,技巧介绍
A,如何快速地到网页上被抓去对象的xpath路径
如果你对xpath语法很了解,这里就有点多余,直接就可以根据语法规定写出来。如果不是很了解的话,Chrome或者Firefox等浏览器有工具可以帮助你。
以Chrome为例
使用Chrome打开网页,对想获取的对象按右键,选择检查
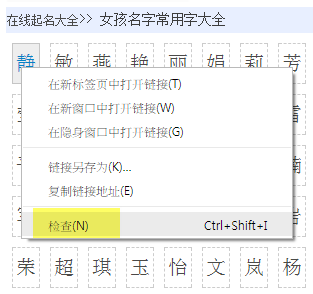
进入Chrome的Developer Tools,找到源码中包含对象的那一列,右键,选择copy,选择copy到XPath
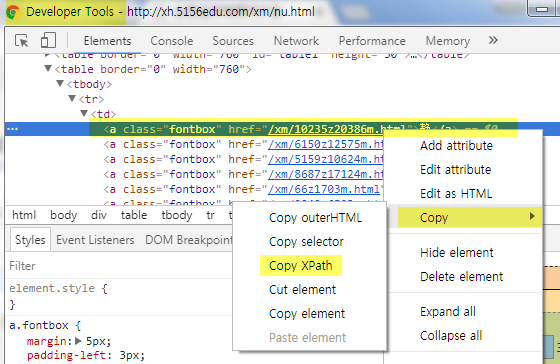
最后在Scrapy中粘贴即可。
这样只能得到这一个标签的内容,即“静”,如果需要获取所有的内容,还是需要对xpath有所了解。如下:
item['ming'] = response.xpath('//a[@class="fontbox"]/text()').extract()
在xpath函数中有个配对字符串,使用了@属性,意思是所有class名字为fontbox的a标签的内容都获取。
如下图所示
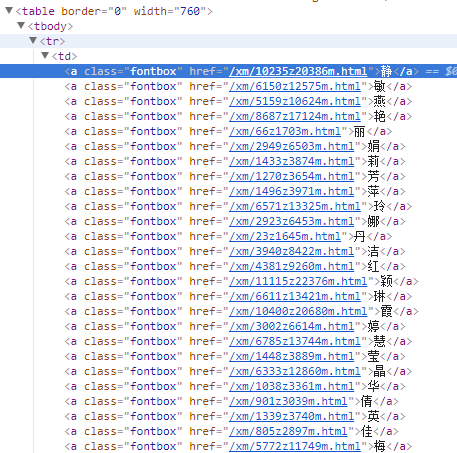
具体参看3.A的代码实现
B,如何在目标网站实现自动输入
自动输入的过程,并不是要找到输入格,往表单里面填写数据,然后模拟去点提交。而是直接模拟HTTP REQUEST向目标WEB PAGE发送数据,比较常见的两种方式,一个是HTTP GET,一个是HTTP POST,通过观察目标网站的链接,我们发现目标网站“https://www.threetong.com/ceming/“是采用了POST,那么是向哪个WEB PAGE发送数据,并且发送的数据表单格式是什么呢,这里就又可以用我们的好朋友,Chrome的Developer Tools了。
首先模拟操作,在”https://www.threetong.com/ceming/”中输入数据
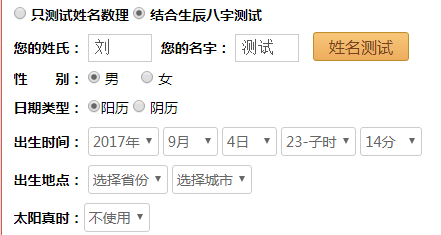
然后可以打开Chrome Developer Tools,查看源码(Elements选项)
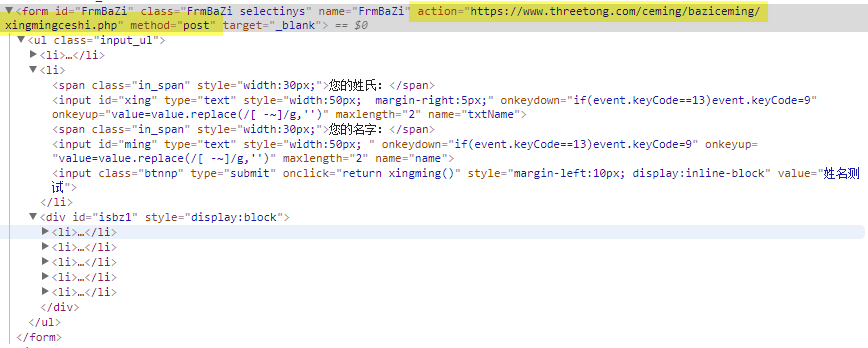
我们可以看到这个form的是采用post的发送方式,发送的目的地是action之后带的页面。
接着点击姓名测试,这样,就会像目标网页发送数据,然后跳转到这个网页

在这个页面,我们点击Chrome的Developer Tool,进入到Network,选择xingmingceshi.php这个网页,点击右侧的Headers,就可以看到这个页面的详细信息了。
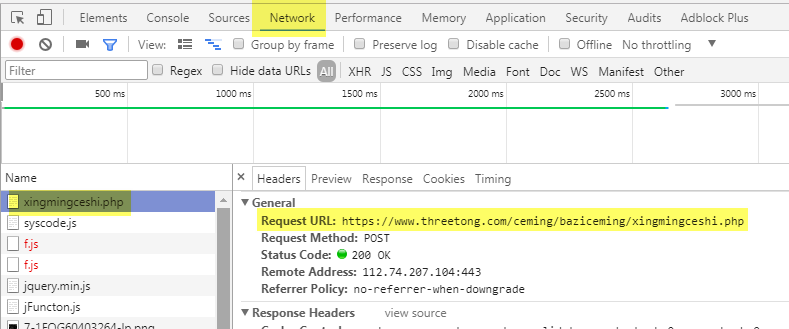
可以看到怎么进入到这个网页的过程,包括Request URL,Request Method是POST,往下面拉,可以看到提交的表单信息
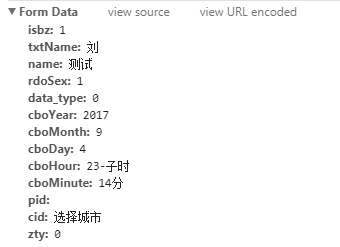
那么,我们只要模拟HTTP POST REQUEST往Request URL发送表单信息就可以了
C,具体代码实现
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html
# 定义item来保存最终生成的数据
import scrapy class DaxiangnameItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() score1 = scrapy.Field() score2 = scrapy.Field() name = scrapy.Field()
# -*- coding: utf-8 -*- import scrapy import csv
# 引进上面定义的item from daxiangName.items import DaxiangnameItem class CemingSpider(scrapy.Spider): name = 'ceming' # 这是scrapy的一个默认入口函数,程序会从这里开始运行 def start_requests(self):
# 使用一个双循环,打开两个csv文件,每次读取一个字,注意文件的编码,为了防止汉字乱码,使用UTF-8 with open(getattr(self,'file','./ming1.csv'),encoding='UTF-8') as f: reader = csv.DictReader(f) for line in reader: #print(line['\ufeffmingzi']) with open(getattr(self,'file2','./ming2.csv'),encoding='UTF-8') as f2: reader2 = csv.DictReader(f2) for line2 in reader2: #print(line) #print(line2)#注意下面的编码,因为从csv读出来,前面多了一个符号,是使用print函数测试出来的 mingzi = line['\ufeffming1']+line2['\ufeffming2'] #print(mingzi)#下面这个函数是核心函数,scrapy定义的模拟发送http post request的函数 FormRequest = scrapy.http.FormRequest( url='https://www.threetong.com/ceming/baziceming/xingmingceshi.php', formdata={'isbz':'1', 'txtName':u'刘', 'name':mingzi, 'rdoSex':'0', 'data_type':'0', 'cboYear':'2017', 'cboMonth':'7', 'cboDay':'30', 'cboHour':u'20-戌时', 'cboMinute':u'39分', }, callback=self.after_login #这是指定回调函数,就是发送request之后返回的结果到哪个函数来处理。 ) yield FormRequest #这里很重要,在scrapy中,所有要搜索网页的http request会有一个池子,通过yield函数形成一个iterator generator,往发送池里面积累 def after_login(self, response): '''#save response body into a file filename = 'source.html' with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename) '''
# 这里就是从返回的数据中获取分数,下面有个正则表达式的小技巧来获取整数和带有小数点的数字 score1 = response.xpath('/html/body/div[6]/div/div[2]/div[3]/div[1]/span[1]/text()').re('[\d.]+') score2 = response.xpath('/html/body/div[6]/div/div[2]/div[3]/div[1]/span[2]/text()').re('[\d.]+') name = response.xpath('/html/body/div[6]/div/div[2]/div[3]/ul[1]/li[1]/text()').extract() #print(score1) #print(score2) print(name)
# 只保留所谓好的分数 if float(score1[0]) >= 90 and float(score2[0]) >= 90: item = DaxiangnameItem() item['score1'] = score1 item['score2'] = score2 item['name'] = name yield item # 这里是输出的池子,形成一个输出的iterator generator,在运行的时候使用-0参数输出所有的items
5. 后记
最后出乎意料返回了4千多个名字,对于最后的人工筛选造成了很大的困难。最后通过对两个输入csv文件的字的删减,得到几十个从各方面都不错的名字。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号