大话设计模式-嵌入式
嵌入式的环境一般是低配,偏硬件,底层,资源紧张,代码多以C语言,汇编为主,代码应用逻辑简单。但随着AIOT时代的到来,局面组件改变。芯片的性能资源逐渐提升,业务逻辑也逐渐变得复杂,相对于代码的效率而言,代码的复用可移植性要求越来越高,以获得更短的项目周期 和更高的可维护性。下面是AIOT时代嵌入式设备的常见的软件框架。
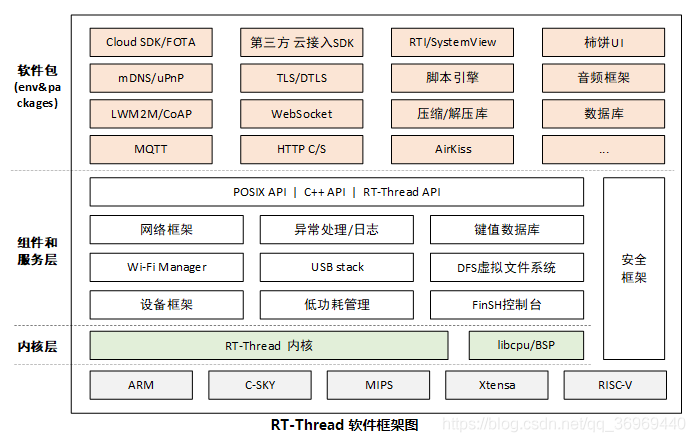
设计模式:高级语言 ,高端,架构等。在AIOT时代,设计模式与嵌入式能擦出怎样的火花?设计模式可描述为: 对于某类相似的问题,经过前人的不断尝试,总结出了处理此类问题的公认的有效解决办法。
嵌入式主要以C语言开发,且面向过程,而设计模式常见于高级语言(面向对象),目前市面上描述设计模式的书籍多数使用JAVA 语言,C语言能实现设计模式吗?设计模式与语言无关,它是解决问题的方法,JAVA可以实现,C语言同样可以实现。同样的,JAVA程序员会遇到需要用模式来处理的问题,C程序员也可能遇见,因此设计模式是很有必要学习的。
模式陷阱:设计模式是针对具体的某些类问题的有效解决办法,不是所有的问题都能匹配到对应的设计模式。因此,不能一味的追求设计模式,有时候简单直接的处理反而更有效。有的问题没有合适的模式,可以尽量满足一些设计原则,如开闭原则(对扩展开放,对修改关闭)
1.观察者模式:在对象之间定义一个一对多的依赖,当一个对象状态改变的时候,所有依赖的对象都会自动收到通知。
主题对象提供统一的注册接口,以及注册函数 。由观察者本身实例化observer_intf 接口,然后使用注册函数,添加到对应的主题列表中,主题状态发生改变,依次通知列表中的所有对象。
struct observer_ops { void*(handle)(uint8_t evt); }; struct observer_intf { struct observer_intf* next; const char* name; void* condition; const struct observer_ops *ops; } int observer_register(struct topical* top , struct observer_intf* observer);
当主题状态发生改变,将通知到所有观察者,观察者本身也可以设置条件,是否选择接收通知
struct observer_intf observer_list; void XXXX_topical_evt(uint8_t evt) { struct observer_intf* cur_observer = observer_list.next; uint8_t* condition = NULL; while(cur_observer != NULL) { condition = (uint8_t*)cur_observer->condition; if(NULL == condition || (condition && *condition)) { if(cur_observer->ops->handle){ cur_observer->ops->handle(evt); } } cur_observer = cur_observer->next; } }
实例:嵌入式裸机低功耗框架
设备功耗分布
其中线路损耗,电源电路等软件无法控制,故不讨论。板载外设,如传感器可能通过某条命令配置进入低功耗模式,又或者硬件上支持控制外设电源来控制功耗。片内外设,及芯片内部的外设,通过卸载相关驱动,关闭时钟配置工作模式来控制功耗。
设备唤醒方式
主动唤醒
当系统某个定时事件到来时,系统被主动唤醒处理事件
被动唤醒
系统处于睡眠,被外部事件唤醒,如串口接收到一包数据,传感器检测到变化,通过引脚通知芯片
系统允许睡眠的条件
外设无正在收发的数据
缓存无需要处理的数据
应用层状态处于空闲(无需要处理的事件)
基于观察者模式的PM框架实现
PM组件提供的接口
struct pm { struct pm* next; const char* name; void(*init)(void); void(*deinit(void); void* condition; }; static struct pm pm_list; static uint8_t pm_num; static uint8_t pm_status; int pm_register(const struct pm* pm , const char* name) { struct pm* cur_pm = &pm_list; while(cur_pm->next) { cur_pm = cur_pm->next; } cur_pm->next = pm; pm->next = NULL; pm->name = name; pm_num++; } void pm_loop(void) { uint32_t pm_condition = 0; struct pm* cur_pm = pm_list.next; static uint8_t cnt; /*check all condition*/ while(cur_pm) { if(cur_pm->condition){ pm_condition |= *((uint32_t*)(cur_pm->condition)); } cur_pm = cur_pm->next; } if(pm_condition == 0) { cnt++; if(cnt>=5) { pm_status = READY_SLEEP; } } else { cnt = 0; } if( pm_status == READY_SLEEP) { cur_pm = pm_list.next; while(cur_pm) { if(cur_pm->deinit){ cur_pm->deinit(); } cur_pm = cur_pm->next; } pm_status = SLEEP; ENTER_SLEEP_MODE(); } /*sleep--->wakeup*/ if(pm_status == SLEEP) { pm_status = NORMAL; cur_pm = pm_list.next; while(cur_pm) { if(cur_pm->init){ cur_pm->init(); } cur_pm = cur_pm->next; } } }
struct uart_dev { ... struct pm pm; uint32_t pm_condition; }; struct uart_dev uart1; void hal_uart1_init(void); void hal_uart1_deinit(void); void uart_init(void) { uart1.pm.init = hal_uart1_init; uart1.pm.deinit = hal_uart1_deinit; uart1.pm.condition = &uart1.pm_condition; pm_register(&uart1.pm , "uart1"); }
结论
PM 电源管理可以单独形成模块,当功耗外设增加时,只需实现接口,注册即可
通过定义段导出操作,可以更加简化应用层或外设的注册逻辑
方便调试,可以很方便打印出系统当前为满足睡眠条件的模块
通过条件字段划分,应该可以实现系统部分睡眠
职责链模式
情景
在现实生活中,一个事件(任务)需要经过多个对象处理是很常见的场景。如报销流程,公司员工报销, 首先员工整理报销单,核对报销金额,有误则继续核对整理,直到无误,将报销单递交到财务,财务部门进行核对,核对无误后,判断金额数量,若小于一定金额,则财务部门可直接审批,若金额超过范围,则报销单流传到总经理,得到批准后,整个任务才算结束。类似的情景还有很多,如配置一个WIFI模块,通过AT指令,要想模块正确连入WIFI , 需要按一定的顺序依次发送配置指令 , 如设置设置模式 ,设置 需要连接的WIFI名,密码,每发送一条配置指令,模块都将返回配置结果,而发送者需要判断结果的正确性,再选择是否发送下一条指令或者进行重传。
总结起来是,一系列任务需要严格按照时间线依次处理的顺序逻辑,如下图所示 。
在存在系统的情况下,此类逻辑可以很容易的用阻塞延时来实现,实现如下:
void process_task(void) { task1_process(); msleep(1000); task2_process(); mq_recv(¶m , 1000); task3_process(); while(mq_recv(¶m , 1000) != OK) { if(retry) { task3_process(); --try; } } }
在裸机的情况下,为了保证系统的实时性,无法使用阻塞延时,一般使用定时事件配合状态机来实现:
/*任务的应答回调*/
void task_ans_cb(void* param)
{
if(task==task2)
{
task_state = task3;
process_task();
}
}
和系统实现相比,裸机的实现更加复杂,为了避免阻塞,只能通过状态和定时器来实现顺序延时的逻辑,可以看到,实现过程相当分散,对于单个任务的处理分散到了3个函数中处理,这样导致的后果是:修改,移植的不便。而实际的应用中,类似的逻辑相当多,如果按照上面的方法去实现,将会导致应用程序的强耦合。
实现
可以发现,上面的情景有以下特点:
任务按顺序执行,只有当前任务执行完了(有结论,成功或者失败)才允许执行下一个任务
前一个任务的执行结果会影响到下一个任务的执行情况
任务有一些特性,如超时时间,延时时间,重试次数
通过以上信息,我们可以抽象出这样一个模型:任务作为节点, 每一个任务节点有其属性:如超时,延时,重试,参数,处理方法,执行结果。当需要按照顺序执行一系列任务时,依次将任务节点串成一条链,启动链运行,则从任务链的第一个节点开始运行,运行的结果可以是 OK , BUSY ,ERROR 。 若是OK, 表示节点已处理,从任务链中删除,ERROR 表示运行出错,任务链将停止运行,进行错误回调,可以有用户决定是否继续运行下去。BUSY表示任务链处于等待应答,或者等待延时的情况。当整条任务链上的节点都执行完,进行成功回调。
void process_task(void) { switch(task_state) { case task1: task1_process(); set_timeout(1000);break; case task2: task1_process(); set_timeout(1000);break; case task3: task1_process(); set_timeout(1000)break; default:break; } } /*定时器超时回调*/ void timeout_cb(void) { if(task_state == task1) { task_state = task2; process_task(); } else //task2 and task3 { if(retry) { retry--; process_task(); } } } /*任务的应答回调*/ void task_ans_cb(void* param) { if(task==task2) { task_state = task3; process_task(); } }
/*shadow node api type for req_chain src*/ typedef struct shadow_resp_chain_node { uint16_t timeout; uint16_t duration; uint8_t init_retry; uint8_t param_type; uint16_t retry; /*used in mpool*/ struct shadow_resp_chain_node* mp_prev; struct shadow_resp_chain_node* mp_next; /*used resp_chain*/ struct shadow_resp_chain_node* next; node_resp_handle_fp handle; void* param; }shadow_resp_chain_node_t;
使用内存池的必要性:实际情况下,同一时间,责任链的条数,以及单条链的节点数比较有限,但种类是相当多的。比如一个支持AT指令的模块,可能支持几十条AT指令,但执行一个配置操作,可能就只会使用3-5条指令,若全部静态定义节点,将会消耗大量内存资源。因此动态分配是必要的。
初始化node内存池,内存池内所有节点都将添加到free_list。当申请节点时,会取出第一个空闲节点,加入到used_list , 并且接入到责任链。当责任链某一个节点执行完,将会被自动回收(从责任链中删除,并从used_list中删除,然后添加到free_list)
职责链数据结构定义
typedef struct resp_chain { bool enable; //enble == true 责任链启动 bool is_ans; //收到应答,与void* param 共同组成应答信号 uint8_t state; const char* name; void* param; TimerEvent_t timer; bool timer_is_running; shadow_resp_chain_node_t node; //节点链 void(*resp_done)(void* result); //执行结果回调 }resp_chain_t;
职责链初始化
void resp_chain_init(resp_chain_t* chain , const char* name , void(*callback)(void* result)) { RESP_ASSERT(chain); /*only init one time*/ resp_chain_mpool_init(); chain->enable = false; chain->is_ans = false; chain->resp_done = callback; chain->name = name; chain->state = RESP_STATUS_IDLE; chain->node.next = NULL; chain->param = NULL; TimerInit(&chain->timer,NULL); }
职责链添加节点
int resp_chain_node_add(resp_chain_t* chain , node_resp_handle_fp handle , void* param) { RESP_ASSERT(chain); BoardDisableIrq(); shadow_resp_chain_node_t* node = chain_node_malloc(); if(node == NULL) { BoardEnableIrq(); RESP_LOG("node malloc error ,no free node"); return -2; } /*初始化节点,并加入责任链*/ shadow_resp_chain_node_t* l = &chain->node; while(l->next != NULL) { l = l->next; } l->next = node; node->next = NULL; node->handle = handle; node->param = param; node->timeout = RESP_CHIAN_NODE_DEFAULT_TIMEOUT; node->duration = RESP_CHIAN_NODE_DEFAULT_DURATION; node->init_retry = RESP_CHIAN_NODE_DEFAULT_RETRY; node->retry = (node->init_retry == 0)? 0 :(node->init_retry-1); BoardEnableIrq(); return 0; }
职责链的启动
void resp_chain_start(resp_chain_t* chain) { RESP_ASSERT(chain); chain->enable = true; }
职责链的应答
void resp_chain_set_ans(resp_chain_t* chain , void* param) { RESP_ASSERT(chain); if(chain->enable) { chain->is_ans = true; if(param != NULL) chain->param = param; else { chain->param = "NO PARAM"; } } }
职责链的运行
int resp_chain_run(resp_chain_t* chain) { RESP_ASSERT(chain); if(chain->enable) { shadow_resp_chain_node_t* cur_node = chain->node.next; /*maybe ans occur in handle,so cannot change state direct when ans comming*/ if(chain->is_ans) { chain->is_ans = false; chain->state = RESP_STATUS_ANS; } switch(chain->state) { case RESP_STATUS_IDLE: { if(cur_node) { uint16_t retry = cur_node->init_retry; if(cur_node->handle) { cur_node->param_type = RESP_PARAM_INPUT; chain->state = cur_node->handle((resp_chain_node_t*)cur_node ,cur_node->param); } else { RESP_LOG("node handle is null ,goto next node"); chain->state = RESP_STATUS_OK; } if(retry != cur_node->init_retry) { cur_node->retry = cur_node->init_retry>0?(cur_node- >init_retry-1):0; } } else { if(chain->resp_done) { chain->resp_done((void*)RESP_RESULT_OK); } chain->enable = 0; chain->state = RESP_STATUS_IDLE; TimerStop(&chain->timer); chain->timer_is_running = false; } break; } case RESP_STATUS_DELAY: { if(chain->timer_is_running == false) { chain->timer_is_running = true; TimerSetValueStart(&chain->timer , cur_node->duration); } if(TimerGetFlag(&chain->timer) == true) { chain->state = RESP_STATUS_OK; chain->timer_is_running = false; } break; } case RESP_STATUS_BUSY: { /*waiting for ans or timeout*/ if(chain->timer_is_running == false) { chain->timer_is_running = true; TimerSetValueStart(&chain->timer , cur_node->timeout); } if(TimerGetFlag(&chain->timer) == true) { chain->state = RESP_STATUS_TIMEOUT; chain->timer_is_running = false; } break; } case RESP_STATUS_ANS: { /*already got the ans,put the param back to the request handle*/ TimerStop(&chain->timer); chain->timer_is_running = false; if(cur_node->handle) { cur_node->param_type = RESP_PARAM_ANS; chain->state = cur_node->handle((resp_chain_node_t*)cur_node , chain->param); } else { RESP_LOG("node handle is null ,goto next node"); chain->state = RESP_STATUS_OK; } break; } case RESP_STATUS_TIMEOUT: { if(cur_node->retry) { cur_node->retry--; /*retry to request until cnt is 0*/ chain->state = RESP_STATUS_IDLE; } else { chain->state = RESP_STATUS_ERROR; } break; } case RESP_STATUS_ERROR: { if(chain->resp_done) { chain->resp_done((void*)RESP_RESULT_ERROR); } chain->enable = 0; chain->state = RESP_STATUS_IDLE; TimerStop(&chain->timer); chain->timer_is_running = false; cur_node->retry = cur_node->init_retry>0?(cur_node->init_retry-1):0; chain_node_free_all(chain); break; } case RESP_STATUS_OK: { /*get the next node*/ cur_node->retry = cur_node->init_retry>0?(cur_node->init_retry-1):0; chain_node_free(cur_node); chain->node.next = chain->node.next->next; chain->state = RESP_STATUS_IDLE; break; } default: break; } } return chain->enable; }
测试用例
定义并初始化责任链
void chain_test_init(void) { resp_chain_init(&test_req_chain , "test request" , test_req_callback); }
定义运行函数,在主循环中调用
void chain_test_run(void) { resp_chain_run(&test_req_chain); }
测试节点添加并启动触发函数
void chain_test_tigger(void) { resp_chain_node_add(&test_req_chain , node1_req ,NULL); resp_chain_node_add(&test_req_chain , node2_req,NULL); resp_chain_node_add(&test_req_chain , node3_req,NULL); resp_chain_start(&test_req_chain); }
分别实现节点请求函数
/*延时1s 后执行下一个节点*/ int node1_req(resp_chain_node_t* cfg, void* param) { cfg->duration = 1000; RESP_LOG("node1 send direct request: delay :%d ms" , cfg->duration); return RESP_STATUS_DELAY; } /*超时时间1S , 重传次数5次*/ int node2_req(resp_chain_node_t* cfg , void* param) { static uint8_t cnt; if(param == NULL) { cfg->init_retry = 5; cfg->timeout = 1000; RESP_LOG("node2 send request max retry:%d , waiting for ans..."); return RESP_STATUS_BUSY; } RESP_LOG("node2 get ans: %d",(int)param); return RESP_STATUS_OK; } /*非异步请求*/ int node3_req(resp_chain_node_t* cfg , void* param) { RESP_LOG("node4 send direct request"); return RESP_STATUS_OK; } void ans_callback(void* param) { resp_chain_set_ans(&test_req_chain , param); }
结论
实现了裸机处理 顺序延时任务
较大程度的简化了应用程的实现,用户只需要实现响应的处理函数 , 调用接口添加,即可按时间要求执行
参数为空,表明为请求 ,否则为应答。(在某些场合,请求可能也带参数,如接下来所说的LAP协议,此时需要通过判断参数的类型)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号