


机器学习,数据挖掘,统计学,云计算,众包(crowdsourcing),人工智能,降维(Dimension reduction)
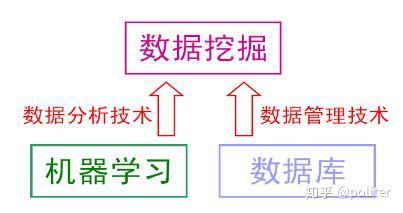
数据挖掘 Data mining:数据挖掘是从海量数据中发掘只是,这就比然涉及对海量数据的管理和分析。大体来说,数据库领域的研究为数据挖掘提供数据管理技术,而机器学习和统计学的研究为数据挖掘提供数据分析技术。
机器学习 Machine Learning:提供数据分析的能力,机器学习是大数据时代必不可少的核心技术,道理很简单:收集、存储、传输、管理大数据的目的,是为了“利用”大数据,而如果没有机器学习技术分析数据,则“利用”就无从谈起。在重合部分的分类、聚类和回归上,机器学习有高层次的理论分析,有高效的训练方法;在非重合部分,机器学习有很多数据挖掘没有的东西,比如学习理论和强化学习。
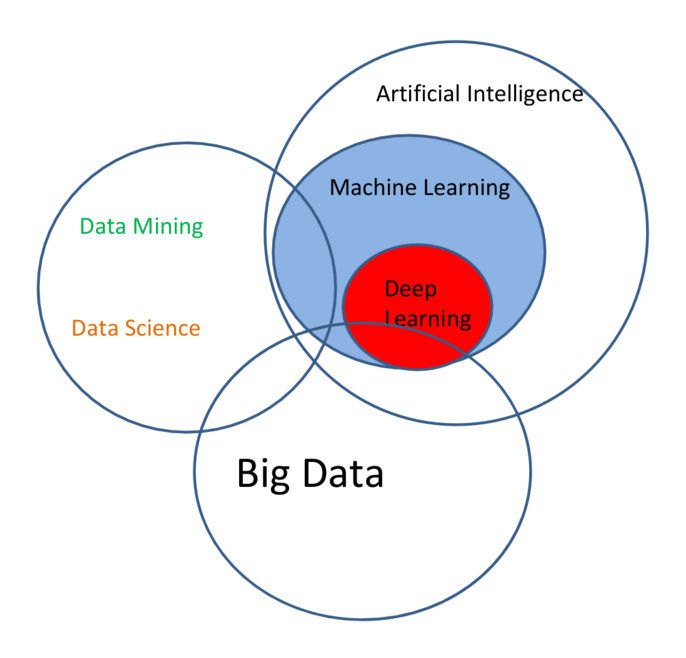
参考:THE DATA SCIENCE PUZZLE, EXPLAINED http://innovaleur.com/the-data-science-puzzle-explained/
统计学:由于统计学的研究成果通常需要经由机器学习研究来形成有效的学习算法,之后再进入数据挖掘领域,因此从这个意义上说,统计学主要是通过机器学习对数据挖掘发挥影响,而机器学习领域和数据库领域则是数据挖掘的两大支撑。
云计算 Cloud Computing:提供数据处理的能力。
众包(Crowdsourcing Data):提供数据标记能力。Crowdsourcing is a type of participative online activity in which an individual, an institution, a nonprofit organization, or company proposes to a group of individuals of varying knowledge, heterogeneity, and number, via a flexible open call, the voluntary undertaking of a task. The undertaking of the task; of variable complexity and modularity, and; in which the crowd should participate, bringing their work, money, knowledge **[and/or]** experience, always entails mutual benefit. The user will receive the satisfaction of a given type of need, be it economic, social recognition, self-esteem, or the development of individual skills, while the crowdsourcer will obtain and use to their advantage that which the user has brought to the venture, whose form will depend on the type of activity undertaken。
降维:Dimension reduction models find a projection from the original sample space to a low-dimensional space, which preserves the most useful information for further machine learning. 将原始的高维数据投影到低维空间中的同时,尽可能的保护最大量的有用信息,以进行后续的机器学习。

