
Scrapy设置代理
设置代理的位置:下载中间件
一、内置代理(优点:简单,缺点:只能代理一个ip)
1、源码分析
process_request(self, request, spider)在下载器执行前执行
if scheme in self.proxies: self._set_proxy(request, scheme)
_set_proxy方法(设置代理)->self.proxies[scheme]->self.proxies = {} (__init__)->getproxies()->getproxies_environment->return proxies
环境变量
os.environ = {
"HTTP_PROXY": "192.169.1.1",
"HTTPS_PROXY": "1.1.1.1",
"HTTPS": '10.10.10.10'
}
通过getproxies_environmen方法的处理
proxies = {
'http': "192.169.1.1",
'https': "1.1.1.1",
}
加()执行
getproxies() = proxies
for type_, url in getproxies().items(): self.proxies[type_] = self._get_proxy(url, type_)
_get_proxy(url, type_) 处理代理用用户密码的情况,如下->return creds, proxy_url
getproxies() = {
'http': "http://用户名:密码@192.169.1.1:端口",
'https': "1.1.1.1",
}
self.proxies = {
'http': ("basic 用户名密码加密后的值", 192.168.1.1:端口),
'https': (None, ip:端口)
}
2、方法一,内置代理
在start_requests(定制起始请求)设置环境变量即可
def start_requests(self): import os os.environ["HTTP_PROXY"] = "http://用户名:密码@192.169.1.1:端口" os.environ["HTTPS_PROXY"] = "http://用户名:密码@114.110.1.1:端口" for url in self.start_urls: yield Request(url=url, callback=self.parse)
3、方法二,内置代理
根据源码分析
if 'proxy' in request.meta: if request.meta['proxy'] is None: return # extract credentials if present creds, proxy_url = self._get_proxy(request.meta['proxy'], '') request.meta['proxy'] = proxy_url if creds and not request.headers.get('Proxy-Authorization'): request.headers['Proxy-Authorization'] = b'Basic ' + creds return elif not self.proxies: return
格式,使用meta
def start_requests(self): # import os # os.environ["HTTP_PROXY"] = "http://用户名:密码@192.169.1.1:端口" # os.environ["HTTPS_PROXY"] = "http://用户名:密码@114.110.1.1:端口" for url in self.start_urls: yield Request(url=url, callback=self.parse, meta={'proxy': "http://用户名:密码@192.169.1.1:端口"})
注意:优先执行meta
二、自定义代理(自定义中间件)
import base64 import random from six.moves.urllib.parse import unquote try: from urllib2 import _parse_proxy except ImportError: from urllib.request import _parse_proxy from six.moves.urllib.parse import urlunparse from scrapy.utils.python import to_bytes class MYHTTPProxyMiddleware(object): def _basic_auth_header(self, username, password): user_pass = to_bytes( '%s:%s' % (unquote(username), unquote(password)), encoding='latin-1') return base64.b64encode(user_pass).strip() def process_request(self, request, spider): PROXIES = [ "http://root:@WSX3edc@192.168.1.1:8000/", "http://root:@WSX3edc@192.168.1.2:8000/", "http://root:@WSX3edc@192.168.1.3:8000/", "http://root:@WSX3edc@192.168.1.4:8000/", "http://root:@WSX3edc@192.168.1.5:8000/", ] url = random.choice(PROXIES) orig_type = "" proxy_type, user, password, hostport = _parse_proxy(url) proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', '')) if user: creds = self._basic_auth_header(user, password) else: creds = None request.meta['proxy'] = proxy_url if creds: request.headers['Proxy-Authorization'] = b'Basic ' + creds
修改配置文件(56行)
DOWNLOADER_MIDDLEWARES = { # 'toscrapy.middlewares.ToscrapyDownloaderMiddleware': 543, 'toscrapy.proxy.MYHTTPProxyMiddleware': 543, }
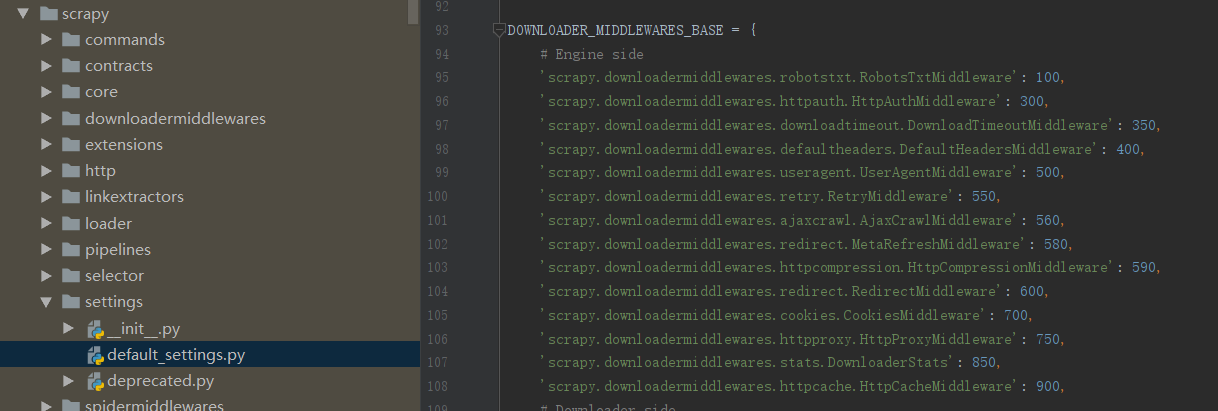
查看默认的下载中间件和中间件的权重值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号