MySQL中的 SQL 是如何执行的
首先 MySQL 是典型的 C/S 架构,即 Client/Server 架构,服务器端程序使用的 mysqld。整体的 MySQL 流程如下图所示:
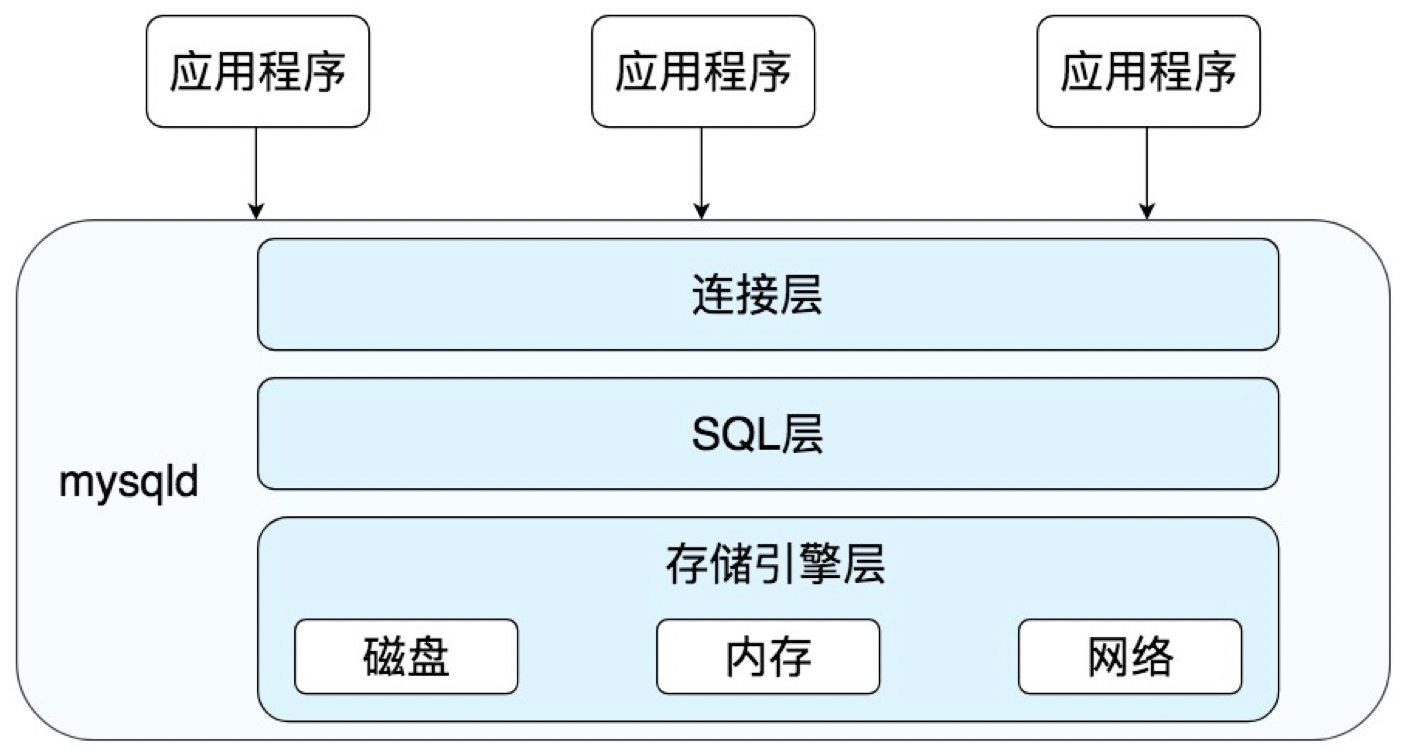
你能看到 MySQL 由三层组成:
- 连接层:客户端和服务器端建立连接,客户端发送 SQL 至服务器端;
- SQL 层:对 SQL 语句进行查询处理;
- 存储引擎层:与数据库文件打交道,负责数据的存储和读取。
其中 SQL 层与数据库文件的存储方式无关,我们来看下 SQL 层的结构:
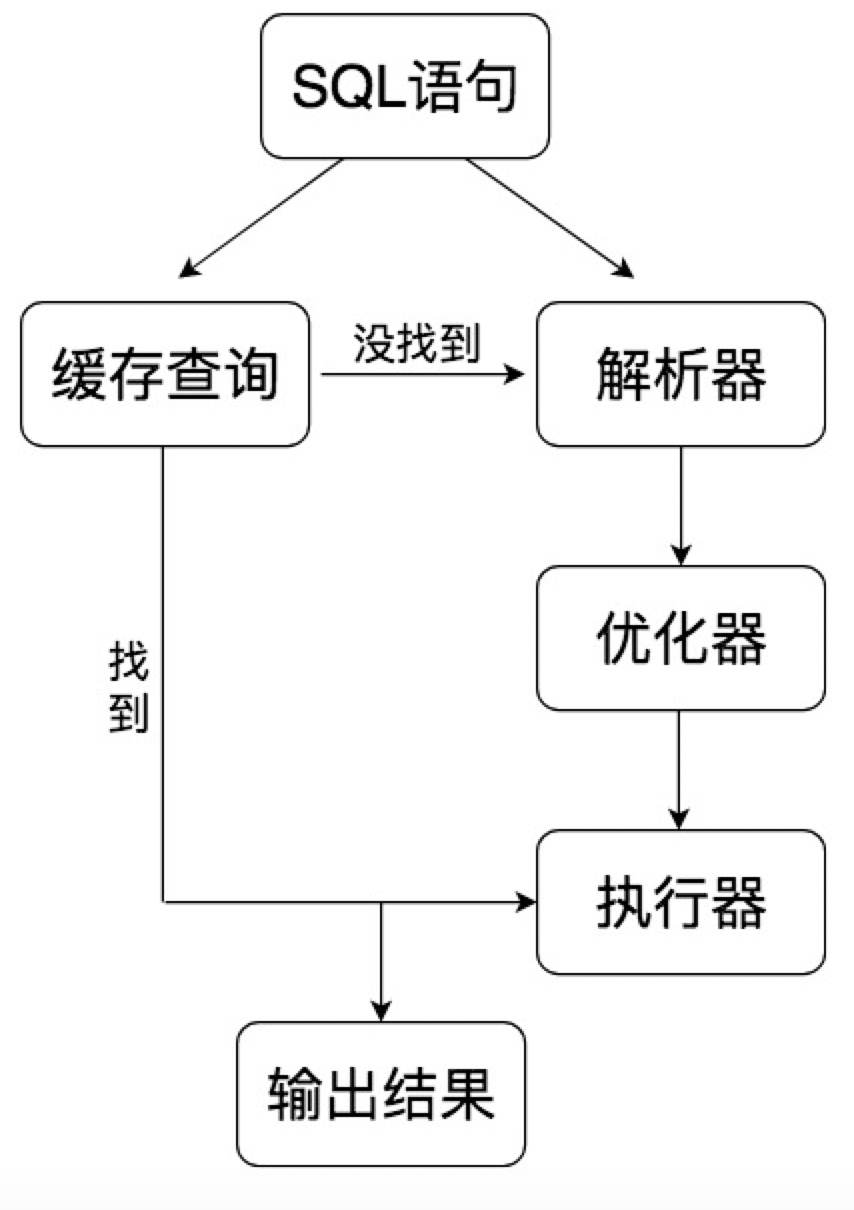
- 查询缓存:Server 如果在查询缓存中发现了这条 SQL 语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在 MySQL8.0 之后就抛弃了这个功能。
- 解析器:在解析器中对 SQL 语句进行语法分析、语义分析。
- 优化器:在优化器中会确定 SQL 语句的执行路径,比如是根据全表检索,还是根据索引来检索等。
- 执行器:在执行之前需要判断该用户是否具备权限,如果具备权限就执行 SQL 查询并返回结果。在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
你能看到 SQL 语句在 MySQL 中的流程是:SQL 语句→缓存查询→解析器→优化器→执行器。
MySQL 的存储引擎采用了插件的形式,每个存储引擎都面向一种特定的数据库应用环境。同时开源的 MySQL 还允许开发人员设置自己的存储引擎,下面是一些常见的存储引擎:
InnoDB 存储引擎:它是 MySQL 5.5.8 版本之后默认的存储引擎,最大的特点是支持事务、行级锁定、外键约束等。
MyISAM 存储引擎:在 MySQL 5.5.8 版本之前是默认的存储引擎,不支持事务,也不支持外键,最大的特点是速度快,占用资源少。
Memory 存储引擎:使用系统内存作为存储介质,以便得到更快的响应速度。不过如果 mysqld 进程崩溃,则会导致所有的数据丢失,因此我们只有当数据是临时的情况下才使用 Memory 存储引擎。
NDB 存储引擎:也叫做 NDB Cluster 存储引擎,主要用于 MySQL Cluster 分布式集群环境,类似于 Oracle 的 RAC 集群。
Archive 存储引擎:它有很好的压缩机制,用于文件归档,在请求写入时会进行压缩,所以也经常用来做仓库。
需要注意的是,数据库的设计在于表的设计,而在 MySQL 中每个表的设计都可以采用不同的存储引擎,我们可以根据实际的数据处理需要来选择存储引擎,这也是 MySQL 的强大之处。
再简单一点:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号