

Redis 如何保持和MySQL数据一致【二】加额外补充重温
需求起因
在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库。
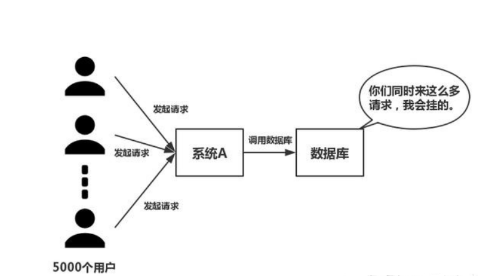
这个业务场景,主要是解决读数据从Redis缓存,一般都是按照下图的流程来进行业务
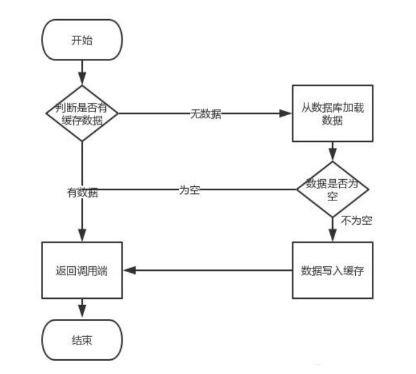
读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存(Redis)和数据库(MySQL)间的数据一致性问题。
不管是先写MySQL数据库,再删除Redis缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。举一个例子:
1.如果删除了缓存Redis,还没有来得及写库MySQL,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。
2.如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。
如来解决?这里给出两个解决方案,先易后难,结合业务和技术代价选择使用。
缓存和数据库一致性解决方案
1.第一种方案:采用延时双删策略
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。
伪代码如下

public void write( String key, Object data )
{
redis.delKey( key );
db.updateData( data );
Thread.sleep( 500 );
redis.delKey( key );
}
2.具体的步骤就是:
- 先删除缓存
- 再写数据库
- 休眠500毫秒
- 再次删除缓存
那么,这个500毫秒怎么确定的,具体该休眠多久呢?
需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
当然这种策略还要考虑redis和数据库主从同步的耗时。最后的的写数据的休眠时间:则在读数据业务逻辑的耗时基础上,加几百ms即可。比如:休眠1秒。
3.设置缓存过期时间
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
4.该方案的弊端
结合双删策略+缓存超时设置,这样最差的情况就是在超时时间内数据存在不一致,而且又增加了写请求的耗时。
2、第二种方案:异步更新缓存(基于订阅binlog的同步机制)
1.技术整体思路:
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis
- 读Redis:热数据基本都在Redis
- 写MySQL:增删改都是操作MySQL
- 更新Redis数据:MySQ的数据操作binlog,来更新到Redis
2.Redis更新
(1)数据操作主要分为两大块:
- 一个是全量(将全部数据一次写入到redis)
- 一个是增量(实时更新)
这里说的是增量,指的是mysql的update、insert、delate变更数据。
(2)读取binlog后分析 ,利用消息队列,推送更新各台的redis缓存数据。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
这里可以结合使用canal(阿里的一款开源框架),通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。
当然,这里的消息推送工具你也可以采用别的第三方:kafka、rabbitMQ等来实现推送更新Redis!
摘自:https://juejin.im/post/5c96fb795188252d5f0fdff2
--------------------------额外补充重温---------------------------------
在业务场景中使用到了缓存,就要保证缓存的双写一致性! 何为mysql和redis双写一致性?
- 如果redis中有数据,需要和数据库中的值相同
- 如果redis中无数据,数据库中的值要是最新值
既然如此,对于读写缓存来说,分为异步和同步。一般而言大部分是同步操作。
什么时候同步直写?
小数据、某条、小热数据等,要求立刻变更,可以前台服务降级一下,后台马上同步直写。
什么时候异步缓写?
- 正常业务,马上更新了mysql,可以在业务上允许出现一个小时甚至更长时后redis起效。
- 出现异常后,不得不将失败的动作重新修补,不得不借助kafka或者rabbitmq等消息中间件,实现解耦后的重试重写。
同步直写策略:写缓存时也同步写数据库,缓存和数据库中的数据一致。对于读写缓存来说,要想保证缓存和数据库中的数据一致性,就要采用同步直写策略。
在这里提一下阿里的开源组件,canal。
canal能干嘛?
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排序索引等)
- 业务cache刷新
- 贷业务逻辑的增量数据处理。
https://github.com/alibaba/canal,主要用途是基于 MySQL 数据库增量日志解析。这块我就不做实践了,暂时用不到,自己大概了解就行了,如果遇到一些场景,希望还是能考虑到canal。
数据库和缓存一致性的几种更新策略
挂牌报错,凌晨升级(就类似半夜修路,加绕路标识),假如是重量级的数据操作最好不要用多线程,最好单线程,目的最终是达到数据一致性。
给缓存设置过期时间,是保证最终数据一致性的解决方案。
我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功了,缓存更新失败,那么只要达到过期时间,则后面的请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记以mysql的数据库写入为准。
分析以下几种策略(绝对不可以先更新缓存,再更新数据库!)
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
一、先更新数据库,再更新缓存
如:
- 先更新mysql的某商品库存,当前商品的库存是100,更新为99个。
- 更新mysql为99后成功,然后更新redis。
- 此时假设异常出现,或者更新redis时高并发卡一下(单机版小系统没问题),更新redis失败了,这导致mysql里面的库存是99而redis里还是100。
- 上述发生,会让数据库和缓存redis不一致,读脏数据。
二、先删除缓存,再更新数据库
- A线程先成功删除了redis里面的数据,然后去更新mysql,此时mysql正在更新中,还没有结束(比如网络延时),B突然出现要读取缓存数据。
- 此时redis里面的数据是空的,B线程来读取,先去读redis里面的数据(已经被A线程delete掉了),此处出来2个问题。①B从mysql获得了旧值,B线程发现redis里没有缓存,去mysql读,从数据里面读到旧值②然后B又把获得的旧值写会redis
A线程更新完 mysql后,发现redis里面的数据是脏数据,A线程直接蒙了。
两个并发操作,一个是更新操作,另一个是查询操作,A更新操作删除缓存后,B查询操作没有命中缓存,B先把老数据读取出来后放到缓存,然后A更新操作更新了数据库。于是,在缓存中的数据还是老数据,导致缓存中的数据是脏数据,而且一直脏下去。 如果低并发系统就是访问旧值,高并发就是缓存击穿,也会导致数据不一致问题。
如何解决上面的问题?
延时双删
加上sleep的这段时间,就是为了让线程B能够先从数据库读取数据,再把缺失的数据写入缓存,然后,线程A再进行删除。所以,线程A sleep的时间,就需要大于线程B读取数据再写入缓存的时间。
这样一来,其他线程读取数据的时候,会发现缓存缺失,所以会从数据库中读取最新值。因为这个方案会在第一次删除缓存之后,延迟一段时间再进行删除,所以称之为“延迟双删”。
延迟双删相关问题
1、这个删除该休眠多久呢?
线程A sleep 的时间,就需要大于线程B读取数据再写入缓存的时间。
在业务程序运行的时候,统计一下线程读取和写缓存的操作时间,自行评估自己的项目读取数据业务逻辑的耗时,以此为基础来进行估算。然后写数据的休眠时间则在读取数据业务逻辑的耗时基础上加百毫秒即可。这么做的目的就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
2、如果是mysql主从读写分离架构如何?
- 请求A进行写操作,删除缓存
- 请求A将数据写入数据库
- 请求B查询缓存发现缓存没有值
- 请求B去从库查询,这个时候还没完成主从同步,因此查询到的是旧值。
- 请求B将旧值写入缓存。
数据库完成主从同步,从库变为新值,上述情形,就是数据不一致的原因。还是使用双删延迟策略,只是睡眠时间修改为在主从同步的延迟时间基础上再加几百ms。
3、这种同步淘汰策略,吞吐量降低怎么办?
来一个异步操作,或者加一个线程专门做删除缓存,就类似于go的defer机制
三、先更新数据库,再删除缓存
线程A删除数据库中的值,线程B缓存命中,此时B读取的是缓存旧值。会出现的问题是:线程A没来得及删除缓存的值,导致B缓存命中旧值。
解决方式
重试机制+引入MQ。其思想类似cannal,订阅binlog程序再mysql中的中间件。
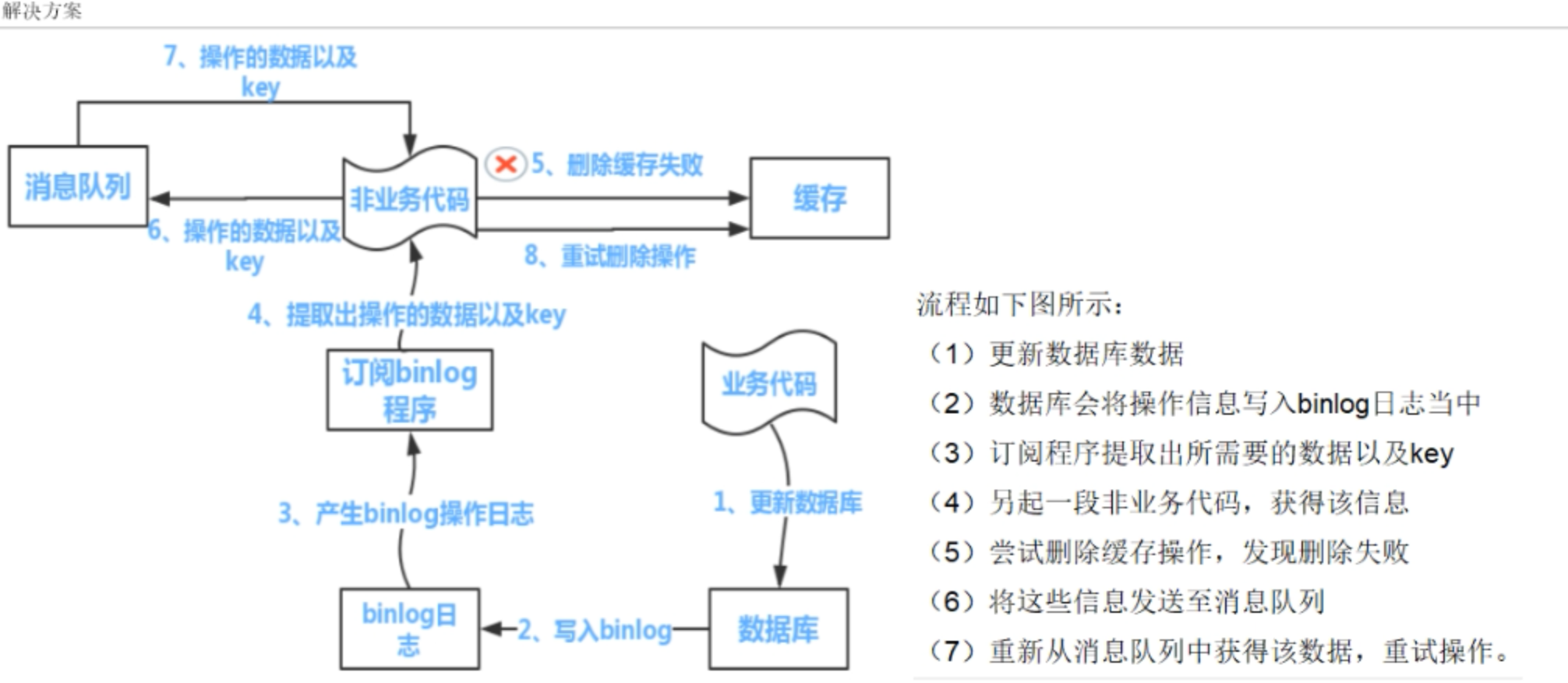
- 可以把要删除的缓存值或者要更新的数据库值暂存消息队列(例如kafka、rabbitmq等)
- 当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或者更新。
- 如果能够成功地删除或者更新,我们就要把这些值从消息队列中取出,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要重试机制再次操作更新。
- 如果重试超过了一定次数还是没成功,就需要向业务层发送报错信息了,通知运维人员。
第三种方案是主流+成熟的做法,但是考虑不同公司业务系统的差距,不是100%正确,不保证绝对适配所有情况,选择最合适的!
方案二和方案三的比较,利弊如何?
在大多数业务场景下,会把redis作为只读缓存使用。假如定位是只读缓存来说。
理论上既可以先删除缓存值再更新数据库,也可以先更新数据库再删除缓存,但是没有完美方案,选择一个最好的当然还是第三种方案。理由如下:
- 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力,导致mysql打满。
- 如果业务应用中读取数据库和写缓存的时间不好估算,那么延迟双删中的等待时间就不好设置。
多补充一句:如果使用先更新数据库,再删除缓存的方案,如果业务层要求必须读取一致性的数据,那么就需要在更新数据库时,先在redis缓存客户端暂存并发读请求,等数据库完成更新、缓存值删除后,再读取数据,从而保证数据一致性。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!