

Kafka学习之(一)了解一下Kafka及关键概念和处理机制
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模小打的网站中所有动作流数据。
优势
- 高吞吐量:非常普通的硬件Kafka也可以支持每秒100W的消息,即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持通过Kafka服务器和消费机集群来区分消息,也就是可以对消息进行分类,然后使用不同分类的服务器消费机去消费不同分类的消息。
- 支持Hadoop并行数据加载。
- 以时间复杂度为O(1)的方式提供消息持久化能力,并保证即使对TB级以上数据也能保证常数时间的访问性能
- 支持Kafka Server间的消息分区,及分布式消息消费,同时保证每个partition内的消息顺序传输;producter、broker、consumer均支持水平扩展
- 同时支持离线数据处理和实时数据处理
- 消息持久化,所有的消息均被持久化到磁盘,无消息丢失,支持消息重放
Kafka和其他主流分布式消息系统的对比
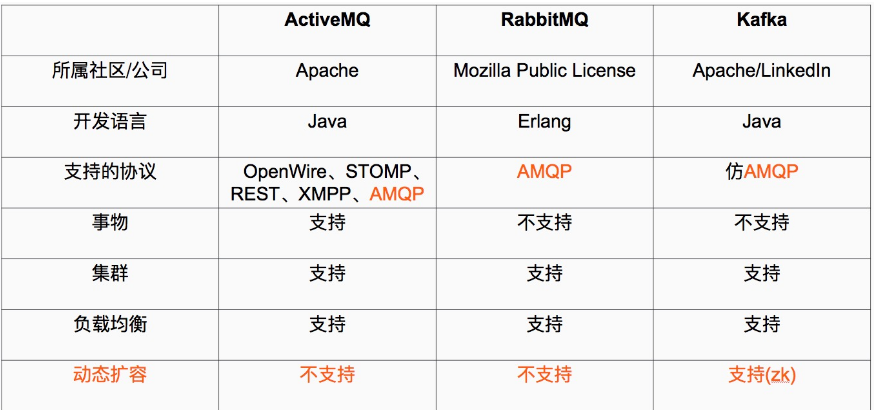
阿里巴巴的Metal,RocketMQ都有Kafka的影子,他们要么改造了Kafka或者借鉴了Kafka,最后Kafka的动态扩容是通过Zookeeper来实现的。
关键概念:
Broker:kafka集群中的一台或者多台服务器统称为broker。
Topic:Kafka处理的消息源(feeds of messages)的不同分类,可以理解为消息分类。
Partition:Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。也就是可以理解为一个群的群名称或者群号,因为大家都在这个群里面消费,成为分类,然后消费topic的时候进行物理分组,比如一个partition不够用,可以分配给多个partition。
Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
Producers:消息和数据的生产者,向Kafka的一个topic发布消息的过程叫做producers。
Consumers:消息和数据消费者,订阅topics并处理其发布的消息过程叫做consumers。
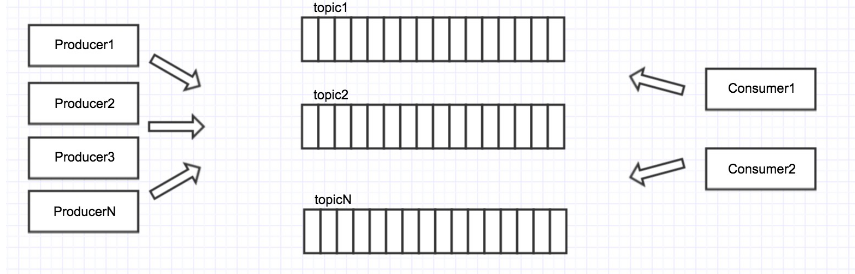
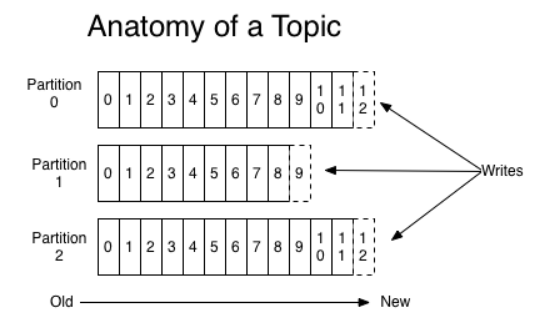
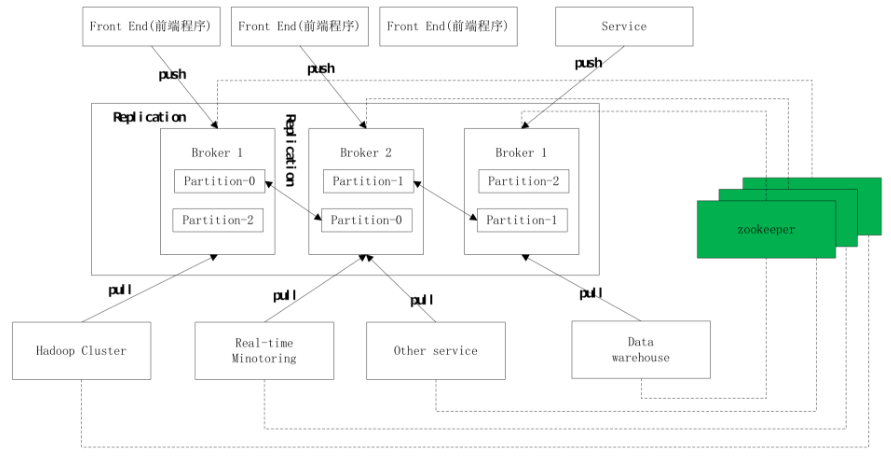
图示说明
最上面的是Producer,也就是消费的生产者,生产好数据之后push到Broker中,也就是Kafka的服务器,push好之后下面有Consumer去消费Kafka的队列,可以看到图中是Consumer去拽Kafka中的消息,然后消费。整体是通过Zookeeper管理。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!