

高并发系统设计(十二):【缓存的正确使用姿势】缓存穿透了怎么办?如何最大程度避免缓存穿透
缓存穿透其实是指从缓存中没有查到数据,而不得不从后端系统(比如数据库)中查询的情况。
缓存穿透的解决方案
举例:如果要读取一个用户表中未注册的用户,按照旁路缓存策略,我们会先读缓存,再穿透读数据库。由于用户并不存在,所以缓存和数据库中都没有查询到数据,因此也就不会向缓存中回种数据(也就是向缓存中设置值的意思),这样当再次请求这个用户数据的时候还是会再次穿透到数据库。
解决缓存穿透会有两种解决方案:回种空值以及使用布隆过滤器。
一、回种空值
回种空值虽然能够阻挡大量穿透的请求,但如果有大量获取未注册用户信息的请求,缓存内就会有有大量的空值缓存,也就会浪费缓存的存储空间,如果缓存空间被占满了,还会剔除掉一些已经被缓存的用户信息反而会造成缓存命中率的下降。不建议使用。
二、布隆过滤器
布隆过滤器的算法,用来判断一个元素是否在一个集合中。这种算法由一个二进制数组和一个Hash算法组成。它的基本思路如下:
把集合中的每一个值按照提供的Hash算法算出对应的Hash值,然后将Hash值对数组长度取模后得到需要计入数组的索引值,并且将数组这个位置的值从0改成1。在判断一个元素是否存在于这个集合中时,你只需要将这个元素按照相同的算法计算出索引值,如果这个位置的值为1就认为这个元素在集合中,否则则认为不在集合中。
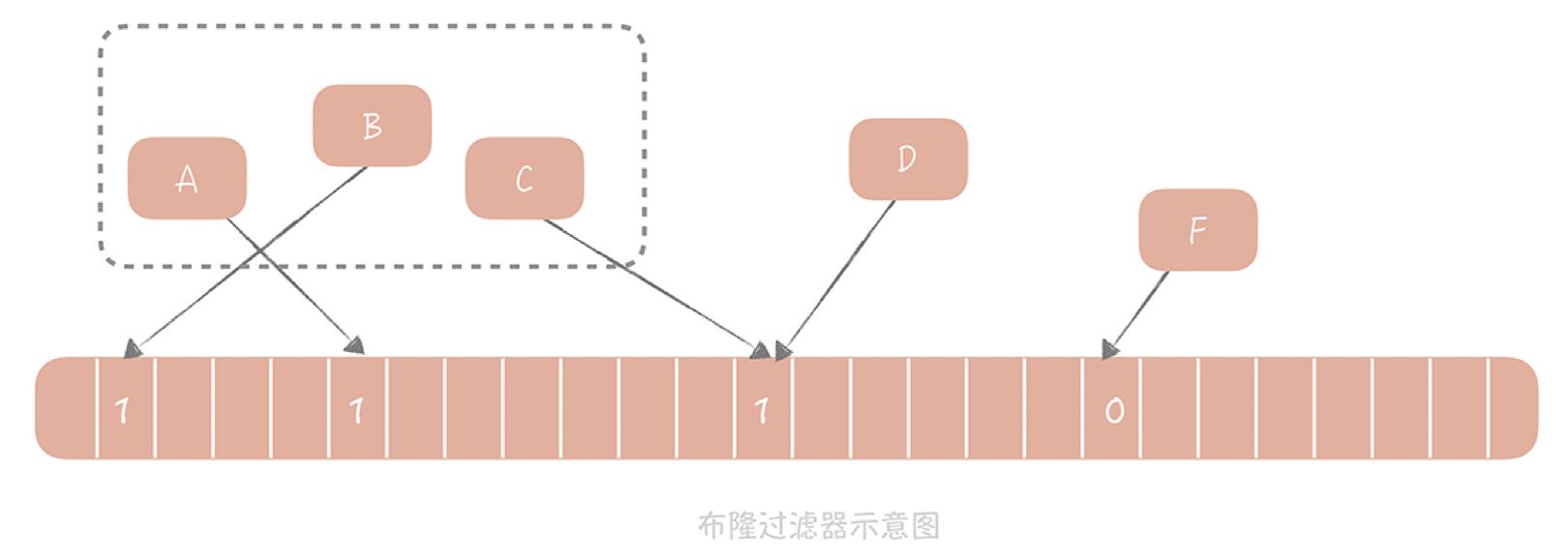
A、B、C等元素组成了一个集合,元素D计算出的Hash值所对应的的数组中值是1,所以可以认为D也在集合中。而F在数组中的值是0,所以F不在数组中。
那么我们如何使用布隆过滤器来解决缓存穿透的问题呢?
还是以存储用户信息的表为例进行讲解。首先,我们初始化一个很大的数组,比方说长度为20亿的数组,接下来我们选择一个Hash算法,然后我们将目前现有的所有用户的ID计算出Hash值并且映射到这个大数组中,映射位置的值设置为1,其它值设置为0。
新注册的用户除了需要写入到数据库中之外,它也需要依照同样的算法更新布隆过滤器的数组中,相应位置的值。那么当我们需要查询某一个用户的信息时,我们首先查询这个ID在布隆过滤器中是否存在,如果不存在就直接返回空值,而不需要继续查询数据库和缓存,这样就可以极大地减少异常查询带来的缓存穿透。
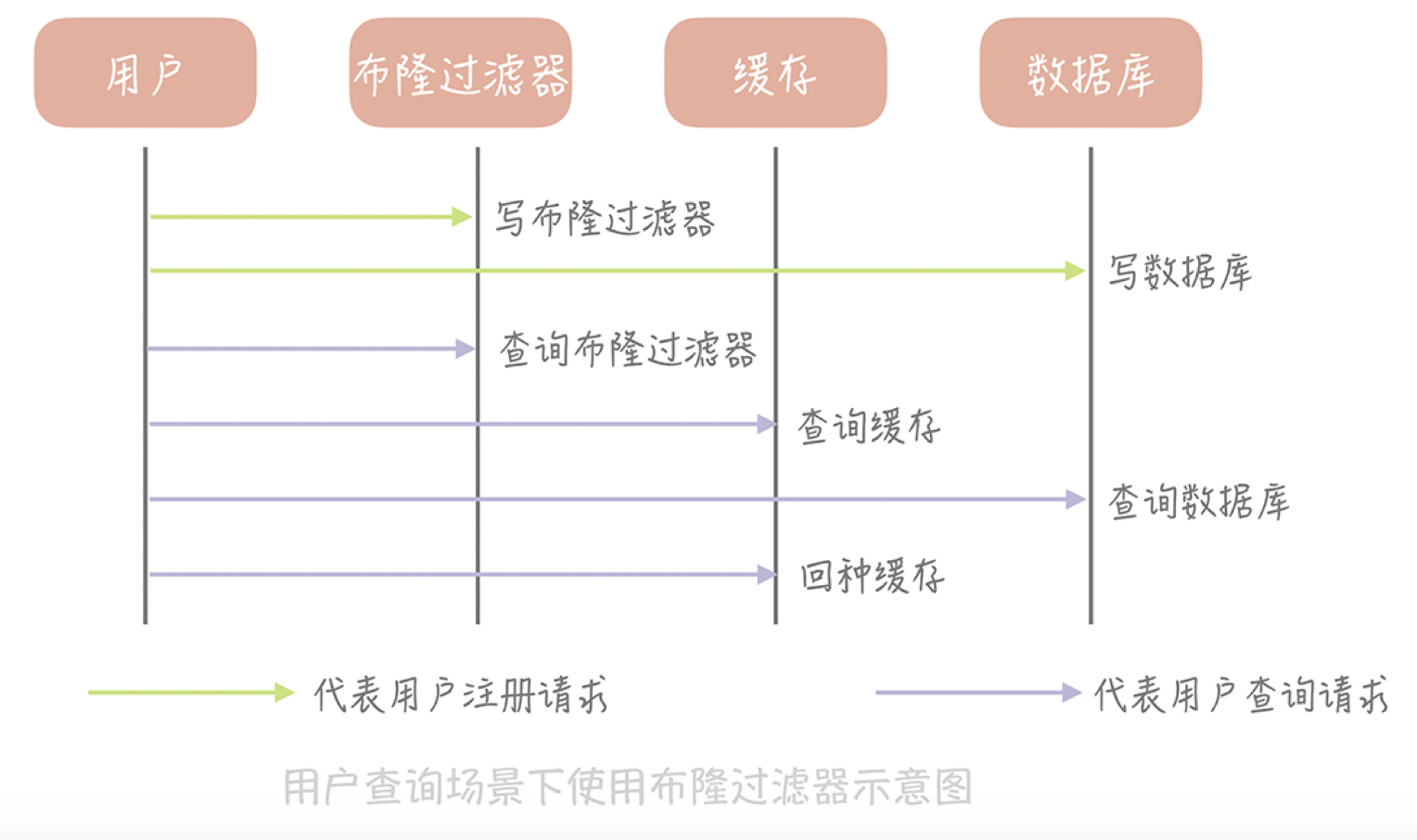
布隆过滤器拥有极高的性能,无论是写入操作还是读取操作,时间复杂度都是O(1),是常量值。在空间上,相对于其他数据结构它也有很大的优势,比如,20亿的数组需要2000000000/8/1024/1024 = 238M的空间,而如果使用数组来存储,假设每个用户ID占用4个字节的空间,那么存储20亿用户需要2000000000 * 4 / 1024 / 1024 = 7600M的空间,是布隆过滤器的32倍。
布隆过滤器缺点:
1.它在判断元素是否在集合中时是有一定错误几率的(哈希碰撞),比如它会把不是集合中的元素判断为处在集合中;
2.不支持删除元素。
布隆过滤器为什么适合解决缓存穿透?
当布隆过滤器判断元素在集合中时,这个元素可能不在集合中。但是一旦布隆过滤器判断这个元素不在集合中时,它一定不在集合中。
如果布隆过滤器会将集合中的元素判定为不在集合中,那么我们就不确定,被布隆过滤器判定为不在集合中的元素,是不是在集合中。假设在刚才的场景中,如果有大量查询未注册的用户信息的请求存在,那么这些请求到达布隆过滤器之后,即使布隆过滤器判断为不是注册用户,那么我们也不确定它是不是真的不是注册用户,那么就还是需要去数据库和缓存中查询,这就使布隆过滤器失去了价值。
所以你看,布隆过滤器虽然存在误判的情况,但是还是会减少缓存穿透的情况发生,只是我们需要尽量减少误判的几率,这样布隆过滤器的判断正确的几率更高,对缓存的穿透也更少。
一个解决方案是:
使用多个Hash算法为元素计算出多个Hash值,只有所有Hash值对应的数组中的值都为1时,才会认为这个元素在集合中。
布隆过滤器不支持删除元素的缺陷也和Hash碰撞有关。给你举一个例子,假如两个元素A和B都是集合中的元素,它们有相同的Hash值,它们就会映射到数组的同一个位置。这时我们删除了A,数组中对应位置的值也从1变成0,那么在判断B的时候发现值是0,也会判断B是不在集合中的元素,就会得到错误的结论。
怎么解决这个问题的呢?我会让数组中不再只有0和1两个值,而是存储一个计数。比如如果A和B同时命中了一个数组的索引,那么这个位置的值就是2,如果A被删除了就把这个值从2改为1。这个方案中的数组不再存储bit位,而是存储数值,也就会增加空间的消耗。所以,你要依据业务场景来选择是否能够使用布隆过滤器,比如像是注册用户的场景下,因为用户删除的情况基本不存在,所以还是可以使用布隆过滤器来解决缓存穿透的问题的。
关于布隆过滤器的使用上的建议:
1.选择多个Hash函数计算多个Hash值,这样可以减少误判的几率;
2.布隆过滤器会消耗一定的内存空间,所以在使用时需要评估你的业务场景下需要多大的内存,存储的成本是否可以接受。
补充:
缓存穿透后的并发,方案也比较简单:
1.在代码中,控制在某一个热点缓存项失效之后启动一个后台线程,穿透到数据库,将数据加载到缓存中,在缓存未加载之前,所有访问这个缓存的请求都不再穿透而直接返回。
2.通过在Memcached或者Redis中设置分布式锁,只有获取到锁的请求才能够穿透到数据库。
分布式锁的方式也比较简单,比方说ID为1的用户是一个热点用户,当他的用户信息缓存失效后,我们需要从数据库中重新加载数据时,先向Memcached中写入一个Key为"lock.1"的缓存项,然后去数据库里面加载数据,当数据加载完成后再把这个Key删掉。这时,如果另外一个线程也要请求这个用户的数据,它发现缓存中有Key为“lock.1”的缓存,就认为目前已经有线程在加载数据库中的值到缓存中了,它就可以重新去缓存中查询数据,不再穿透数据库了。
https://www.cnblogs.com/wt645631686/p/15942320.html 此文是布隆过滤器详解


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2017-06-27 PHP基于ThinkPHP5的砍价活动相关设计