
高并发系统设计(七):【Mysql数据库的优化】主从读写分离、分库分表
主从读写分离
其实,大部分系统的访问模型是读多写少,读写请求量的差距可能达到几个数量级,那么这就是我们所说的主从读写分离。
主从复制的原理这里不再阐述,本人博客里有关于Mysql主从的配置文章,当然里面也介绍了原理。
做了主从复制之后,就可以在写入时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响到读请求的执行。同时呢,在读流量比较大的情况下,可以部署多个从库共同承担读流量,这就是所说的“一主多从”部署方式,另外,从库也可以当成一个备库来使用,以避免主库故障导致数据丢失。但随着从库数量增加,从库连接上来的IO线程比较多,主库也需要创建同样多的log dump线程来处理复制的请求,对于主库资源消耗比较高,同时受限于主库的网络带宽,所以在实际使用中,一般一个主库最多挂3~5个从库。
当然也会出现主从同步延迟的情况,那么也可以有响应的办法解决此类问题,或者根据不同的业务场景来设计代码,哪怕出现数据冗余,或者适当的从主库拿数据。如主库发不完信息把信息同时写入缓存,读的时候直接从缓存取数据;比如关键数据的信息不仅仅把ID写入队列或者缓存,也可以避免查库;再比如直接主库拿;
分库分表
系统正在持续不断地的发展,注册的用户越来越多,产生的订单越来越多,数据库中存储的数据也越来越多,单个表的数据量超过了千万甚至到了亿级别。这时即使你使用了索引,索引占用的空间也随着数据量的增长而增大,数据库就无法缓存全量的索引信息,那么就需要从磁盘上读取索引数据,就会影响到查询的性能了。那么这时可以分库分表。
数据库分库分表的方式有两种:一种是垂直拆分,另一种是水平拆分。这两种方式,在我看来,掌握拆分方式是关键,理解拆分原理是内核。所以、最好可以结合自身业务来思考。
如何对数据库做水平拆分
和垂直拆分的关注点不同,垂直拆分的关注点在于业务相关性,而水平拆分指的是将单一数据表按照某一种规则拆分到多个数据库和多个数据表中,关注点在数据的特点。
拆分的规则有下面这两种:
1.按照某一个字段的哈希值做拆分,这种拆分规则比较适用于实体表,比如说用户表,内容表,我们一般按照这些实体表的ID字段来拆分。比如说我们想把用户表拆分成16个库,64张表,那么可以先对用户ID做哈希,哈希的目的是将ID尽量打散,然后再对16取余,这样就得到了分库后的索引值;对64取余,就得到了分表后的索引值。

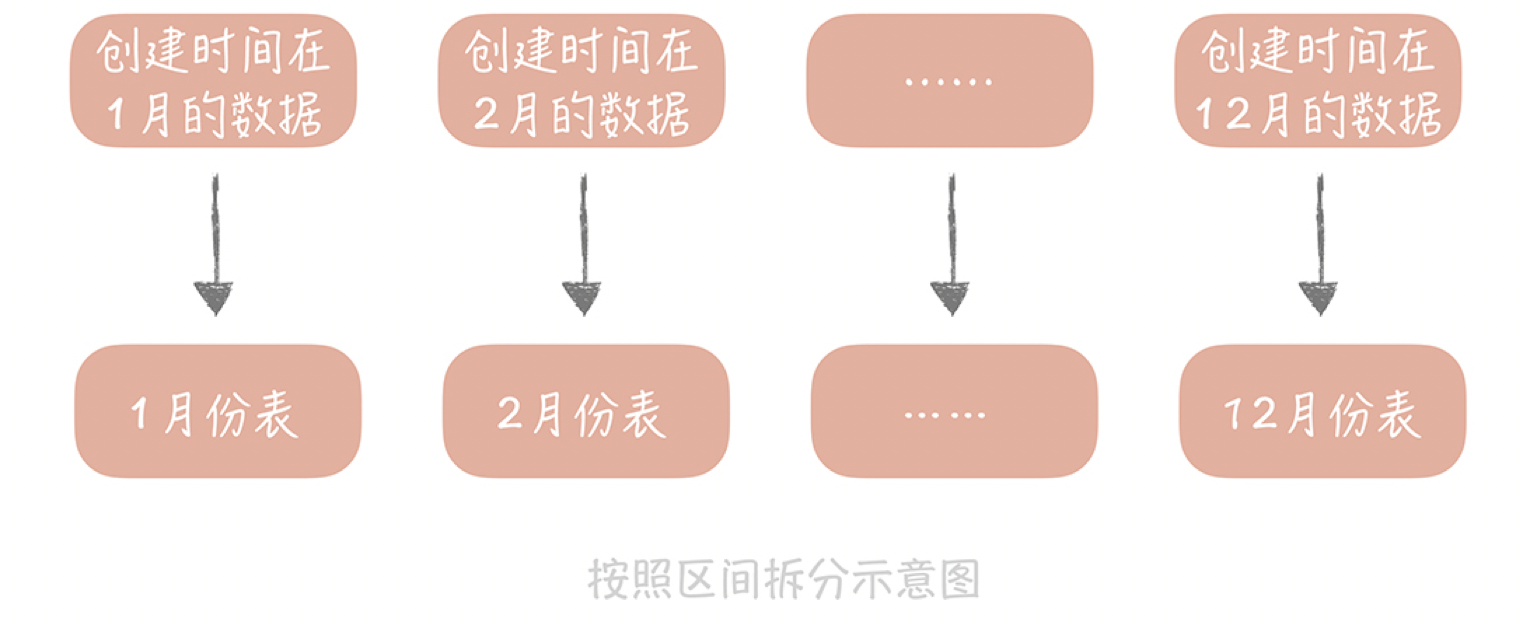
2.另一种比较常用的是按照某一个字段的区间来拆分,比较常用的是时间字段。你知道在内容表里面有“创建时间”的字段,而我们也是按照时间来查看一个人发布的内容。我们可能会要看昨天的内容,也可能会看一个月前发布的内容,这时就可以按照创建时间的区间来分库分表,比如说可以把一个月的数据放入一张表中,这样在查询时就可以根据创建时间先定位数据存储在哪个表里面,再按照查询条件来查询。
一般来说,列表数据可以使用这种拆分方式,比如一个人一段时间的订单,一段时间发布的内容。但是这种方式可能会存在明显的热点,这很好理解嘛,你当然会更关注最近我买了什么,发了什么,所以查询的QPS也会更多一些,对性能有一定的影响。另外,使用这种拆分规则后,数据表要提前建立好,否则如果时间到了2020年元旦,DBA(Database Administrator,数据库管理员)却忘记了建表,那么2020年的数据就没有库表可写了,就会发生故障了。
数据库在分库分表之后,数据的访问方式也有了极大的改变,原先只需要根据查询条件到从库中查询数据即可,现在则需要先确认数据在哪一个库表中,再到那个库表中查询数据。提示:需要对所使用数据库中间件的原理有足够的了解和足够强的运维上的把控能力。

