

复合数据类型,英文词频统计
这个作业主要来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753
1.列表,元组,字典,集合分别如何增删改查及遍历。
列表增加元素:
- append()方法:在列表的末尾增加一个元素
- insert()方法:在列表指定的位置上增加一个元素
- extend()方法:可迭代,分解成元素添加在末尾
列表删除元素:
- pop()方法: 按照下标索引删除指定的值
- remove()方法:按元素删除指定的值
- clear()方法:清空列表内数据
- del:删除列表、也可以进行切片删除
修改列表中的元素:
- s[ ] = ' ' #元素赋值
- s[0:2] = ‘ ’ #分片赋值
查找列表中的元素:
-
names = ['mike','mark','candice','laular'] print(names[2])
-
names = ['mike','mark','candice','laular'] print(names[1:3]) #通过切片方式取值,切片是顾头不顾尾,打印结果:['mark', 'candice'] print(names[1:]) #取下标后面所有的值,打印结果:['mark', 'candice', 'laular'] print(names[:3]) #取下标前面所有的值,打印结果:['mike', 'mark', 'candice'] print(names[:]) #取所有的值,打印结果:['mike', 'mark', 'candice', 'laular'] print(names[-1]) #取最后一个值,打印结果:laular print(names[:1:2])#隔几位取一次,默认不写步长为1,即隔一位取一次;结果为取下标为1之前的值,隔2位取一个['mike']
元组的增删改差:
- tup=tup1+tup2
元组不支持修改,但可以通过连接组合的方式进行增加 - del tup
元组不支持单个元素删除,但可以删除整个元组 - tup=tup[index1],tup1[index2], ...
tup=tup[index1:index2]
元组是不可变类型,不能修改元组的元素。可通过现有的字符串拼接构造一个新元组 - tup[index]
通过下标索引,从0开始tup[a:b]
切片,顾头不顾尾
字典增加元素:
- dict[key]=value
通过赋值的方法增加元素 - dict.update(dict_i)
把新的字典dict_i的键/值对更新到dict里(适用dict_i中包含与dict不同的key)
字典删除元素:
- del dict[key]
删除单一元素,通过key来指定删除
del dict
删除字典 - dict.pop(key)
删除单一元素,通过key来指定删除 - dict.clear()
清空全部内容
字典修改元素:
- dict[key]=value
通过对已有的key重新赋值的方法修改 - dict.update(dict_i)
把字典dict_i的键/值对更新到dict里(适用dict_i中包含与dict相同的key)
查询字典元素:
- dict[key]
通过key访问value值 - dict.items()
以列表返回可遍历的(键, 值) 元组数组 - dict.keys()
以列表返回一个字典所有键值
dict.values()
以列表返回一个字典所有值 - dict.get(key)
返回指定key的对应字典值,没有返回none
集合:
- add()方法:增加一个元素
- remove()和pop()方法:删除集合中一个元素
- clear()方法:清空集合中的元素
- del:删除集合
- & | - :集合的交并差
2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 列表、集合、元组中的元素不包含(),但字典中的每个元素都有()。
- 列表、字典、元组中的元素可以排序。
- 列表、字典、元组中的元素可以重复。
- 集合中的set()返回一个无重复元素且排序任意的可变集合。
- 元组只读,不能修改
3.词频统计
主要思路:先将小说中的标点符号和换行符替换成空格,然后按照空格划分为一个个的单词,保存在list1列表里面,然后利用set函数去重生存一个并单词不重复集合list2,然后自定义一个列表,将无意义的语法型词汇,代词、冠词、连词排除(这里只排除一部分),将筛选好的集合存入字典dict{},key为单词,value为在单词在list1列表中出现的次数,利用sort()方法对字典中每个元素的value进行排序,最后输出。在排除无意义的单词列表时原本这样的写法:for s in list2: if s in str: list2.remove(s)但老是报错的原因是,对于一个列表的遍历,不适合用remove()方法。所以后面新增一个list3 用于遍历整篇小说的单词,而删除操作则在list2列表里。
代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#!/usr/bin/python# -*- coding: UTF-8 -*-f = open('小说.txt', 'r', encoding='utf-8')text = f.read()f.close()text.lower()text = text.replace('\n', '')text = text.replace(',', '')text = text.replace('。', '')list1 = text.split(" ")str={'a', 'of', 'in', 'an', 'was','are','on','in','to','this','that','for', 'by','from','but','with','and','the','his','their','they','had','as', 'were','could','not','The','at','be','after'}list2 = set(list1)list3 = set(list1)for s in list3: if s in str: list2.remove(s)dict = {}for word in list2: dict[word] = list1.count(word)word = list(dict.items())word.sort(key=lambda x: x[1], reverse=(True))print("单词计数字典按词频排序",word) |
import pandas as pd
pd.DataFrame(data=word).to_csv("F:\\xiaoshuo.csv",encoding='utf-8')
运行效果如下图:
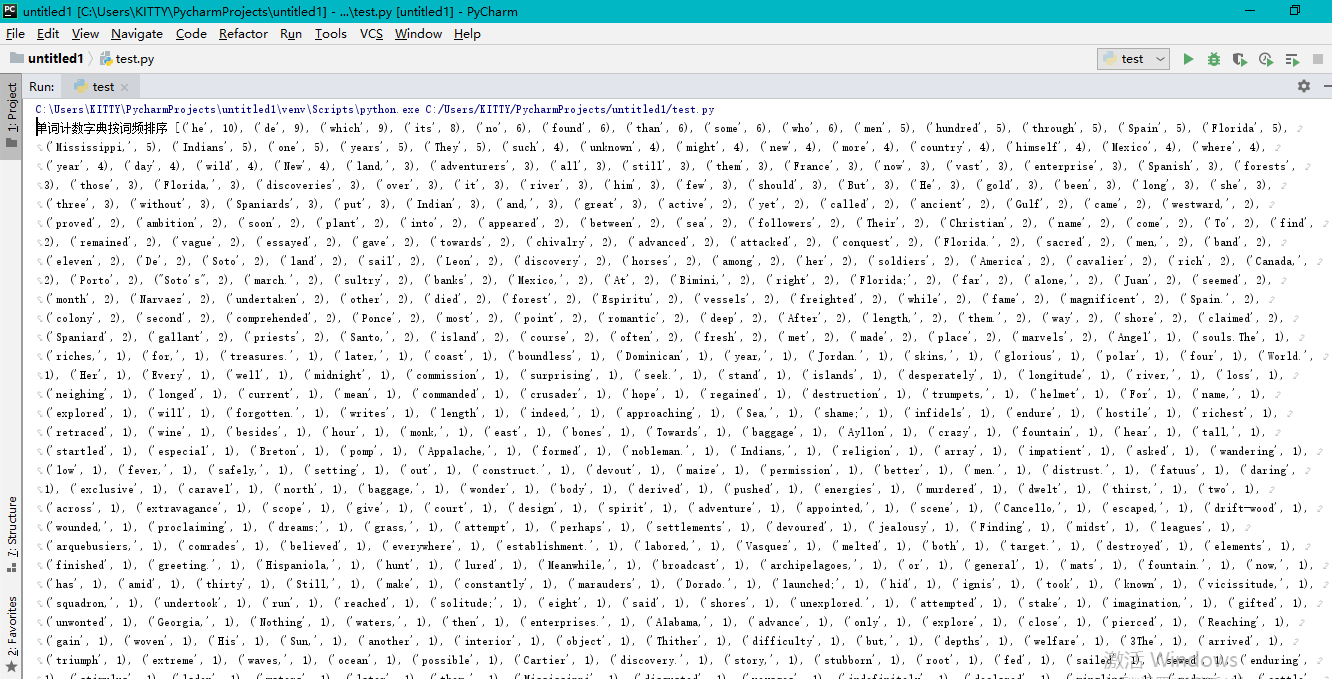
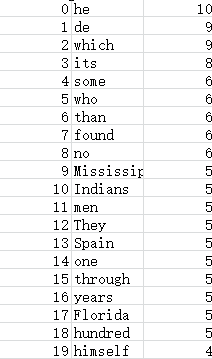
可视化CSV文件:
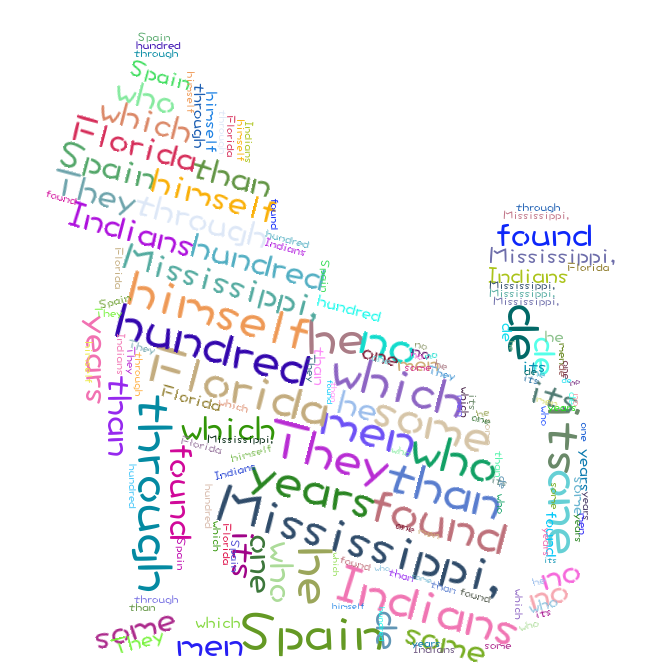
可视化词云:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号