prophet翻译(七)--- 不确定性间隔
不确定性间隔
默认情况下,Prophet将为预测的yhat返回不确定性区间。这些不确定性区间背后有几个重要的假设。
预测中存在三种不确定性来源:趋势的不确定性、季节性估计的不确定性以及额外的观测噪声。
趋势的不确定性
预测中最大的不确定性源是未来趋势变化的潜在性。在本文档中已经看到的时间序列显示了历史上明显的趋势变化。Prophet能够检测和拟合这些趋势变化,但是在未来,我们应该预期什么样的趋势变化呢?由于无法确定,我们采取最合理的做法,假设未来的趋势变化与历史上相似。特别是,我们假设未来的趋势变化的平均频率和幅度与历史观察到的相同。我们将这些趋势变化向前投射,并通过计算它们的分布来获得不确定性区间。
这种假设意味着我们假定未来的趋势变化与历史上的趋势变化类似,并且通过计算这些变化的分布,可以得到对未来的不确定性区间。这种方法是在当前信息下对未来进行最合理的估计,但仍需要谨慎解释和使用预测结果,因为未来的实际趋势变化可能与历史上的变化有所不同。
这种测量不确定性的方式的一个特点是,通过增加 changepoint_prior_scale(变化点先验规模),可以增加速率的灵活性,从而增加预测的不确定性。这是因为如果我们在历史上建模更多的速率变化,那么我们也会预期未来会有更多的变化,这使得不确定性区间成为过拟合的有用指标。
通过增加 changepoint_prior_scale,我们允许模型更容易地拟合历史数据中的速率变化,这可能导致模型在历史数据中出现过多的变化点。这种过度拟合会增加模型对历史数据的过度敏感性,进而增加预测的不确定性。因此,不确定性区间的扩大可以作为判断模型是否出现过拟合的指标之一。
在使用 Prophet 进行建模时,适当选择 changepoint_prior_scale 的值非常重要。较高的值可以提供更大的灵活性,但也可能导致过度拟合和不确定性的增加。因此,在选择 changepoint_prior_scale 时,需要权衡模型的复杂性和过拟合的风险,以获得合适的预测不确定性水平。
不确定性区间的宽度(默认为80%)可以使用参数interval_width进行设置:
# Python
forecast = Prophet(interval_width=0.95).fit(df).predict(future)
再次强调,这些区间假设未来的速率变化频率和幅度与过去相同。然而,这个假设很可能是不成立的,因此您不应该期望这些不确定性区间能够准确覆盖实际情况。
尽管Prophet的不确定性区间提供了一种衡量预测的不确定性的方法,但由于未来的情况可能与历史不同,因此这些区间可能无法准确预测未来的变化。在使用不确定性区间时,应该谨慎解释和使用,并意识到其有限的准确性。
为了更准确地了解未来的变化和不确定性,除了使用Prophet的不确定性区间外,还应考虑其他因素、观察额外的数据,以及使用其他方法和模型进行分析和预测。
季节性不确定性
默认情况下,Prophet仅返回趋势和观测噪声的不确定性。要获取季节性的不确定性,您需要进行完整的贝叶斯抽样。可以使用参数mcmc.samples(默认为0)来实现这一点。下面是在Quickstart中的Peyton Manning数据的前六个月中执行此操作的示例代码:
# Python
m = Prophet(mcmc_samples=300)
forecast = m.fit(df, show_progress=False).predict(future)
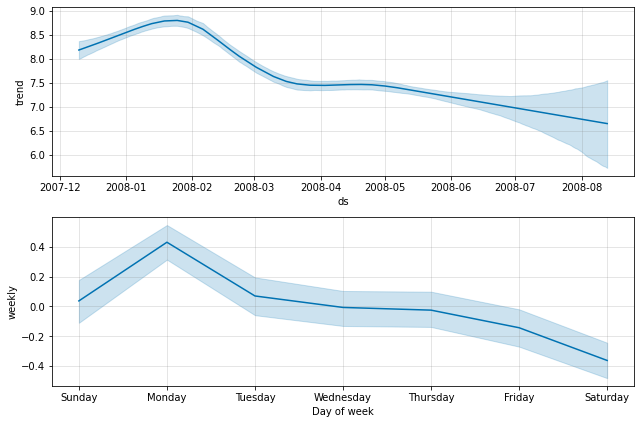
在Python中,您可以使用m.predictive_samples(future)方法访问原始的后验预测样本。在R中,您可以使用predictive_samples(m, future)函数进行访问。
这些函数可以用于获取贝叶斯后验预测的原始样本。m是已经拟合的Prophet模型,future是用于预测的未来时间点的数据框。调用这些函数将返回包含后验预测样本的数据结构,您可以进一步处理和分析这些样本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号