AHB和APB总线基础
AHB
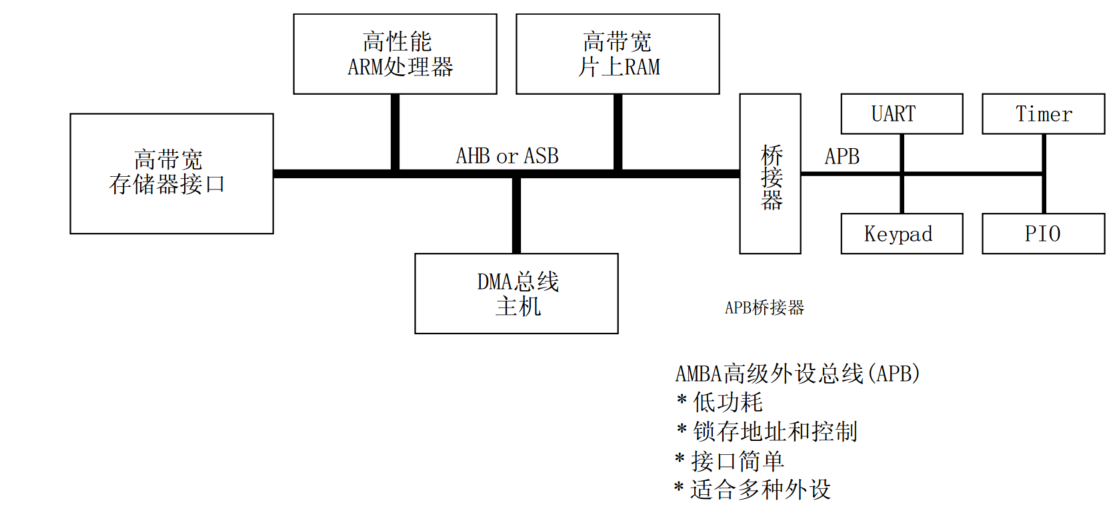
典型AMBA系统中的AHB
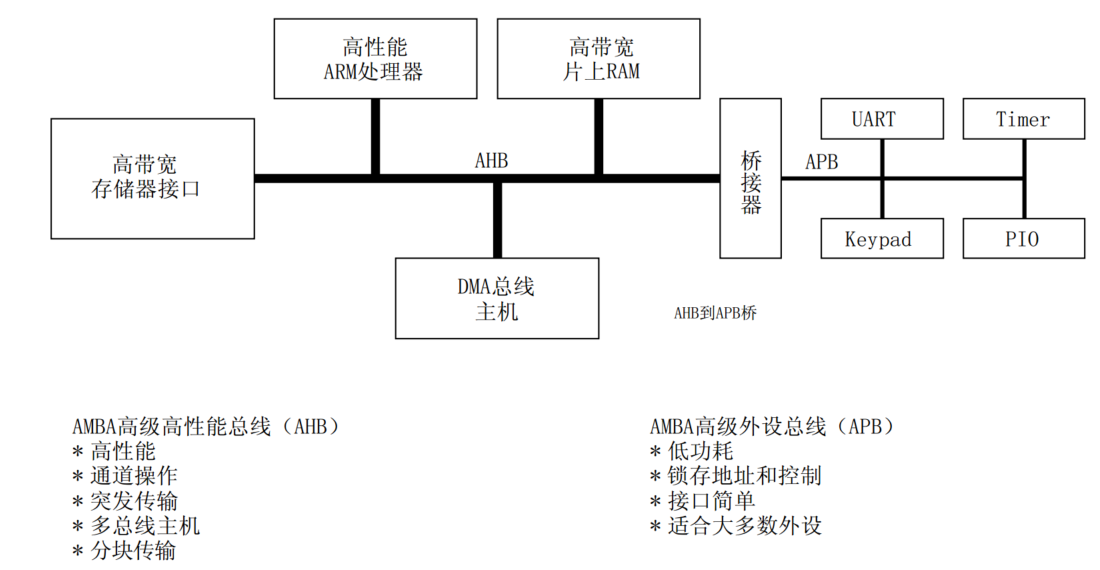
特点
1、高性能
2、通道操作
3、突发传输
4、多总线主机
5、分块传输
AHB基本信号
Master
(1)HADDR[31:0]:32位系统地址总线
(2)HWDATA:写数据总线,从Mastre指向Slave
(3)HWRITE:传输方向,1-写,0-读
(4)HTRANS[1:0]:指示传输类型,00-空闲,01-忙,10-非连续,11-连续
空闲:表示没有数据传输的要求。
忙:允许总线主机在突发传输中间插入空闲周期。这种传输类型表示总线主机正在连续执行一个突发传输,但是下一次传输不能立即发生。
非连续:表示一次突发的第一个传输或者一个单一传输。
连续:表示突发中剩下的传输,其地址是和上一次传输有关的,控制信息和前一次传输一样,地址等于前一次传输的地址加上传输大小(字节)。
(5)HSIZE[2:0]:传输单位,000-字节,001-半字,010-字,011-双字,…… 111-1024位
(6)HBURST[2:0]:表示突发类型,支持四个、八个或者 16 个节拍的突发传输并且突发传输可以是增量或者是回环。
增量突发:访问连续地址并且突发中的每次传输地址仅是前一次地址的一个增量,如0x38, 0x3C, 0x40, 0x44;
回环突发:如果传输的起始地址并未和突发(x 拍)中字节总数对齐那么突发传输地址将在达到边界处回环。例如,一个四拍回环突发的字
(4 字节)访问将在16 字节边界回环。因此,如果传输的起始地址是 0x38,那么它将包含四个到地址0x38, 0x3C, 0x30, 0x34;
一些突发规则:
1、突发禁止超过1KB的地址边界,1k边界是指低10bit为0的地址,例如32'h00000400,32'h00000800...;
ARM对AHB burst这样设计的目的是在于,SLAVE的地址访问空间基本都是以1KB为单位的,当AHB以burst方式传输时,
为了避免错误的访问到其他的Slave空间而造成系统致命错误,因此在burst传输时限制1KB,若需要跨1KB边界时,
需要重新initial一个新的传输。在AHB划分系统时,最小的地址空间为1KB,即slave至少地址空间是1k,或者2K,或者1M等。
这样,当AHB访问地址空间时,因为地址空间对其的原因,就不会恶意的访问到其他的地址空间。https://blog.csdn.net/hit_shaoqi/article/details/53245521
2、一个增量突发可以是任何长度,但是上限由地址不能超过1KB边界这个事实限定。
3、突发大小表示突发的节拍数量,而每拍字节数由HSIZE[1:0]指示。
4、所有突发传输必须将地址边界和传输大小对齐。即:字传输-A[1:0]=00,半字传输-A[0]=0
5、判断突发结束:监控HTRANS,如果产生一个非连续或者空闲传输那么表明一个新的突发已经开始那么前一次突发一定已经终止。
| HBURST[2:0] | 类型 | 描述 |
|---|---|---|
| 000 | SINGLE | 单一传输 |
| 001 | INCR | 未指定长度的增量突发 |
| 010 | WRAP4 | 4拍回环突发 |
| 011 | INCR4 | 4拍增量突发 |
| 100 | WRAP8 | 8拍回环突发 |
| 101 | INCR8 | 8拍增量突发 |
| 110 | WRAP16 | 16拍回环突发 |
| 111 | INCR16 | 16拍增量突发 |
Slave
(1)HRDATA[31:0]:读数据总线,从Slave指向Master
(2)HREADY:为高时表示传输完成,在扩展传输时可能被拉低
(3)HRESP[1:0]:传输响应,00-OKAY,01-ERROR,10-RETRY,11-SPLIT
AHB-Lite总线时序

无等待基本读传输
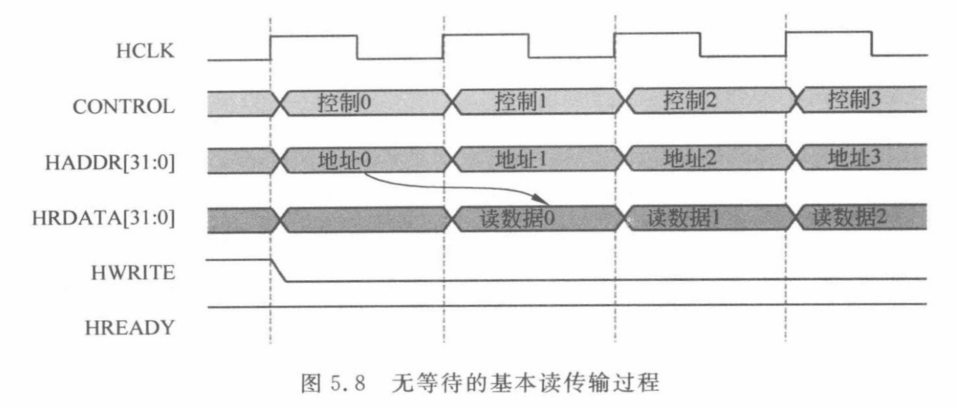
有等待基本读传输
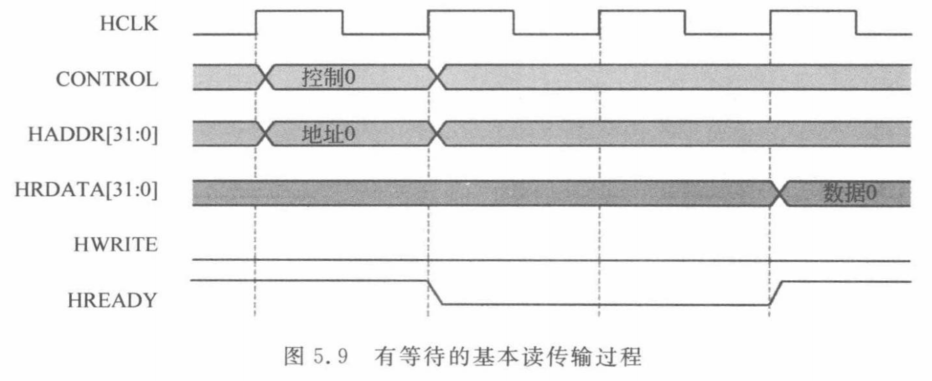
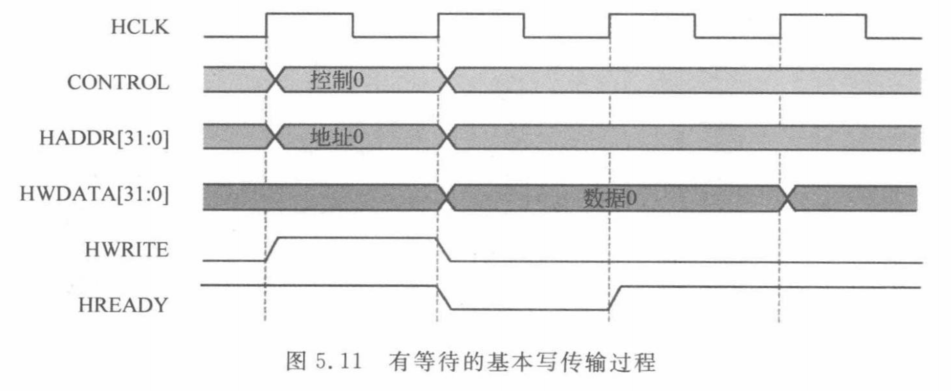
无等待基本写传输
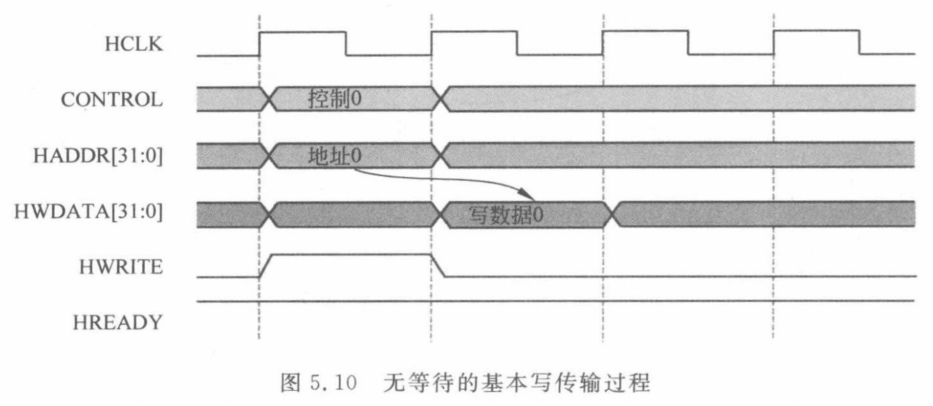
有等待基本写传输
AHB上挂载LED模块示例
module AHB2LED(
//AHBLITE INTERFACE
//Slave Select Signals
input wire HSEL,
//Global Signal
input wire HCLK,
input wire HRESETn,
//Address, Control & Write Data
input wire HREADY,
input wire [31:0] HADDR,
input wire [1:0] HTRANS,
input wire HWRITE,
input wire [2:0] HSIZE,
input wire [31:0] HWDATA,
// Transfer Response & Read Data
output wire HREADYOUT,
output wire [31:0] HRDATA,
//LED Output
output wire [7:0] LED
);
//Address Phase Sampling Registers
reg rHSEL;
reg [31:0] rHADDR;
reg [1:0] rHTRANS;
reg rHWRITE;
reg [2:0] rHSIZE;
reg [7:0] rLED;
//Address Phase Sampling
always @(posedge HCLK or negedge HRESETn)
begin
if(!HRESETn)
begin
rHSEL <= 1'b0;
rHADDR <= 32'h0;
rHTRANS <= 2'b00;
rHWRITE <= 1'b0;
rHSIZE <= 3'b000;
end
else if(HREADY)
begin
rHSEL <= HSEL;
rHADDR <= HADDR;
rHTRANS <= HTRANS;
rHWRITE <= HWRITE;
rHSIZE <= HSIZE;
end
end
//Data Phase data transfer
always @(posedge HCLK or negedge HRESETn)
begin
if(!HRESETn)
rLED <= 8'hFF;
else if(rHSEL & rHWRITE & rHTRANS[1])
rLED <= HWDATA[7:0];
end
//Transfer Response
assign HREADYOUT = 1'b1; //Single cycle Write & Read. Zero Wait state operations
//Read Data
assign HRDATA = {24'h0000_00,rLED};
assign LED = rLED;
endmodule
AHB上挂载存储模块示例
359 module AHB2MEM
360 #(parameter MEMWIDTH = 15) // Size = 32KB
361 (
362 input wire HSEL,
363 input wire HCLK,
364 input wire HRESETn,
365 input wire HREADY,
366 input wire [31:0] HADDR,
367 input wire [1:0] HTRANS,
368 input wire HWRITE,
369 input wire [2:0] HSIZE,
370 input wire [31:0] HWDATA,
371 output wire HREADYOUT,
372 output reg [31:0] HRDATA
373 );
374
375 assign HREADYOUT = 1'b1; // Always ready
376
377 // Memory Array
378 reg [31:0] memory[0:(2**(MEMWIDTH-2)-1)];
379
380 // Registers to store Adress Phase Signals
381 reg [31:0] hwdata_mask;
382 reg we;
383 reg [31:0] buf_hwaddr;
384
385 // Sample the Address Phase
386 always @(posedge HCLK or negedge HRESETn)
387 begin
388 if(!HRESETn)
389 begin
390 we <= 1'b0;
391 buf_hwaddr <= 32'h0;
392 end
393 else
394 if(HREADY)
395 begin
396 we <= HSEL & HWRITE & HTRANS[1];
397 buf_hwaddr <= HADDR;
398
399 casez (HSIZE[1:0])
400 2'b1?: hwdata_mask <= 32'hFFFFFFFF; // Word write
401 2'b01: hwdata_mask <= (32'h0000FFFF << (16 * HADDR[1])); // Halfword write
402 2'b00: hwdata_mask <= (32'h000000FF << (8 * HADDR[1:0])); // Byte write
403 endcase
404 end
405 end
406
407 // Read and Write Memory
408 always @ (posedge HCLK)
409 begin
410 if(we)
411 memory[buf_hwaddr[MEMWIDTH:2]] <= (HWDATA & hwdata_mask) | (HRDATA & ~hwdata_mask);
412 HRDATA = memory[HADDR[MEMWIDTH:2]];
413 end
414
415 endmodule
APB
典型AMBA系统中的APB
主要特点
1、一种优化的,低功耗的,精简接口总线,可以技术多种不同慢速外设;
2、主要应用在低带宽的外设上,如UART、 I2C,它的架构不像AHB总线是多主设备的架构,APB总线的唯一主设备是APB桥(与AXI或APB相连),因此不需要仲裁一些Request/grant信号
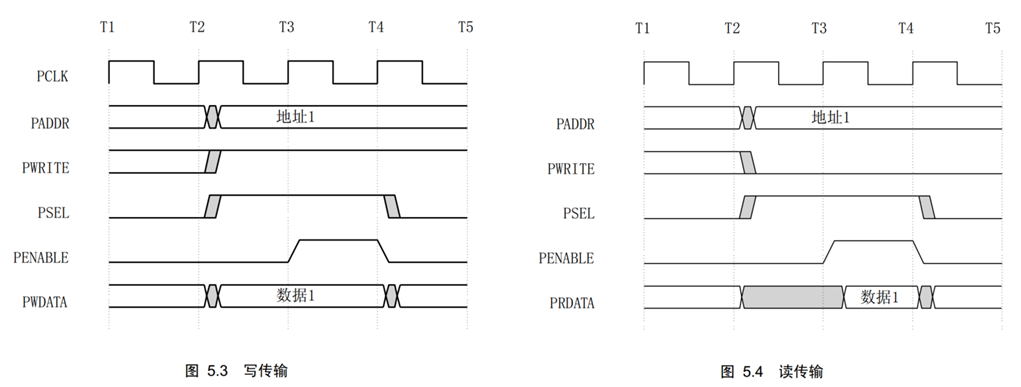
3、固定两个时钟周期完成一次读或写的操作。其特性包括:两个时钟周期传输,无需等待周期和回应信号,控制逻辑简单,只有四个控制信号(PSEL, PENABLE, PADDR, PWRITE)。
状态图

基本写传输和读传输
APB桥
接口框图
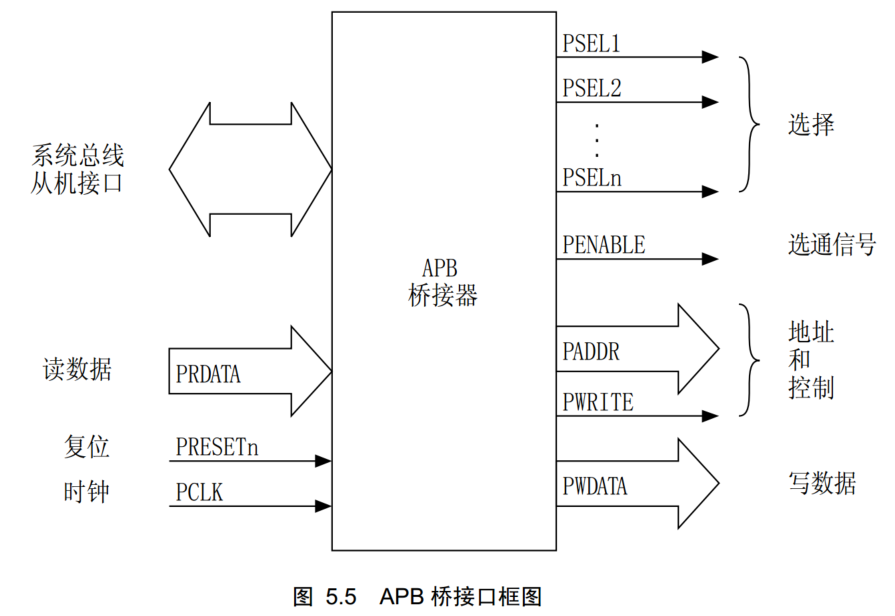
主要功能

仲裁器
仲裁算法
1、仲裁算法有固定优先级的仲裁(Fixed priority),循环式优先级仲裁(Round Robin),或是随机性的仲裁(Random)和竞争仲裁优先级(Tournament)
2、固定优先级算法,就是指总线中各主设备的优先级是事先确定好的,在仲裁器仲裁过程中固定不变。
3、而循环优先级算法则不同,各主设备的优先级在仲裁器的仲裁过程中不是一成不变,而是根据一定规律发生变化的。
4、两者各有利弊,采用固定优先级算法,可以对那些有重要数据传输或有大量实时数据传输以及经常需要占用总线的主设备赋予较高的优先权,以便有效地利用AHB总线。固定优先级算法的缺点是可能会出现总线主设备“撑死”和“饿死”的现象,即优先级高的主设备总是优于优先级低的主设备获得总线的访问权,从而导致优先级低的设备不能及时获得总线的访问权而造成数据发送堵塞。相反,采用循环优先级算法则可以克服这种“饱饿”不均的弊端,在循环优先级算法中,由于其优先级随着每个总线周期动态地改变,各个设备在总线上的身份平等,获得总线占用权的机会均等。所以,在一定意义上来说,优先级循环是最公平的算法。循环优先级的缺点是当处理某些设备的大批量实时数据时会造成效率下降。
verilog实现(循环优先级)
`timescale 1ns / 1ps
module bus_arbiter(
input clk,
input rstn,
input valid_a,
input valid_b,
input valid_c,
input [31:0] data_a,
input [31:0] data_b,
input [31:0] data_c,
output grant_a,
output grant_b,
output grant_c,
output valid,
output [31:0] data
);
reg valid_reg;
reg [31:0] data_reg;
reg [2:0] grant;
assign {grant_a,grant_b,grant_c} = grant;
assign data = data_reg;
assign valid = valid_reg;
// 只要有一路valid则最终valid
always @(posedge clk or negedge rstn) begin
if(!rstn) valid_reg <= 1'b0;
else valid_reg <= valid_a | valid_b | valid_c;
end
// 循环优先级
always @(posedge clk or negedge rstn) begin
if(!rstn) begin
grant <= 3'b100; // 初始化a获得总线
end
else begin
case(grant)
3'b100: // a
begin
case({valid_a,valid_b,valid_c})
3'b000:
begin
grant <= 3'b100;
data_reg <= data_a;
end
3'b001:
begin
grant <= 3'b001;
data_reg <= data_c;
end
3'b010:
begin
grant <= 3'b010;
data_reg <= data_b;
end
3'b011:
begin
grant <= 3'b010;
data_reg <= data_b;
end
3'b100:
begin
grant <= 3'b100;
data_reg <= data_a;
end
3'b101:
begin
grant <= 3'b001;
data_reg <= data_c;
end
3'b110:
begin
grant <= 3'b010;
data_reg <= data_b;
end
3'b111:
begin
grant <= 3'b010;
data_reg <= data_b;
end
endcase
end
3'b010: // b
begin
case({valid_a,valid_b,valid_c})
3'b000:
begin
grant <= 3'b010;
data_reg <= data_b;
end
3'b001:
begin
grant <= 3'b001;
data_reg <= data_c;
end
3'b010:
begin
grant <= 3'b010;
data_reg <= data_b;
end
3'b011:
begin
grant <= 3'b001;
data_reg <= data_c;
end
3'b100:
begin
grant <= 3'b100;
data_reg <= data_a;
end
3'b101:
begin
grant <= 3'b001;
data_reg <= data_c;
end
3'b110:
begin
grant <= 3'b100;
data_reg <= data_a;
end
3'b111:
begin
grant <= 3'b001;
data_reg <= data_c;
end
endcase
end
3'b001: // c
begin
case({valid_a,valid_b,valid_c})
3'b000:
begin
grant <= 3'b001;
data_reg <= data_c;
end
3'b001:
begin
grant <= 3'b001;
data_reg <= data_c;
end
3'b010:
begin
grant <= 3'b010;
data_reg <= data_b;
end
3'b011:
begin
grant <= 3'b010;
data_reg <= data_b;
end
3'b100:
begin
grant <= 3'b100;
data_reg <= data_a;
end
3'b101:
begin
grant <= 3'b100;
data_reg <= data_a;
end
3'b110:
begin
grant <= 3'b100;
data_reg <= data_a;
end
3'b111:
begin
grant <= 3'b100;
data_reg <= data_a;
end
endcase
end
default: grant <= 3'b100;
endcase
end
end
endmodule

 浙公网安备 33010602011771号
浙公网安备 33010602011771号